
Abstract
We propose a new method, that we call an allocation perturbation, to derive the optimal nonlinear income tax schedules with multidimensional individual characteristics on which taxes cannot be conditioned. It is well established that, when individuals differ in terms of preferences on top of their skills, optimal marginal tax rates can be negative. In contrast, we show that with heterogeneous behavioral responses and skills, one has optimal positive marginal tax rates, under utilitarian preferences and maximin.



Similar content being viewed by others

Notes
Our paper studies the optimal tax system when individual characteristics, despite being observable by the tax authority, cannot be used as tags (Akerlof 1978), due to legal and/or horizontal equity reasons.
Our definition of “group” is identical to the one in Werning (2007), p. 13.
A smoothly increasing (decreasing) function is also called an increasing (decreasing) diffeomorphism for which the derivative maps the positive real line onto itself.
In (Jacquet and Lehmann 2021, Proposition 5), we show that the assumption of a smoothly-increasing-in-types allocation amounts to assuming: (i) twice differentiability of the tax function \(T(\cdot )\), that (ii) for all \((w,\theta )\in \mathbb {R}_+^*\times \Theta\), the second-order condition associated to the individual maximization program holds strictly and that (iii) for all \((w,\theta )\in \mathbb {R}_+^*\times \Theta\), the function \(y\mapsto \mathscr {U}\left( y-T(y),y;w,\theta \right)\) admits a unique global maximum over \(\mathbb {R}_+\).
For instance, we never found cases where the second-order incentive-compatibility constraints were violated in the large set of simulations we run on US data with taxpayers differing in terms of gender and labor supply elasticities, see Jacquet and Lehmann (2021).
More precisely, in the left-hand side of Eq. (14a), the term \(-\frac{v_{y}\left[ w,\theta \right] }{w\cdot v_{yw}\left[ w,\theta \right] }\) which is equal to the ratio of \(\varepsilon (w,\theta )\) and \(\alpha (w,\theta )\) [see Eq. (35) in the Appendix], is weighted by the conditional density times the skill, \(W(w,\theta )\ f(W(y,\theta )|\theta )\). And, in the right-hand side of (14a), which encapsulates the mechanical and income effects, the weights are the conditional skill densities.
In Hellwig (2007), under a utilitarian criterion, positive optimal tax rates are obtained with more general preferences.
If the utility function \(u(\cdot )\) in (1) were parameterized by type w and \(\theta\) while \(v(\cdot )\) were simply parameterized by w, individuals who earn the same income would have distinct social marginal welfare weights. This could drive negative marginal tax rates. Similarly, if both \(u(\cdot )\) and \(v(\cdot )\) were parameterized by w and \(\theta\), one would also expect negative marginal tax rates. Let us stress that our method could not be used in this framework since the pooling function (10) cannot depend simultaneously on Y and C.
Hence function \({\underline{W}}(\cdot ,\theta )\) coincides with the pooling function \(W(\cdot ,\theta )\).
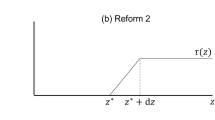
Indeed, at \(m=0\), \(\mathscr {Y}^R_y\) does no longer depend on the direction R of the tax reform.
References
Akerlof GA (1978) The economics of tagging as applied to the optimal income tax, welfare programs, and manpower planning. Am Econ Rev 68(1):8–19
Blumkin T, Sadka E, Shem-Tov Y (2015) International tax competition: zero tax rate at the top re-established. Int Tax Public Finance 22(5):760–776
Boadway R, Marchand M, Pestieau P, del Mar Racionero M (2002) Optimal redistribution with heterogeneous preferences for leisure. J Public Econ Theory 4(4):475–498
Brett C, Weymark JA (2003) Financing education using optimal redistributive taxation. J Public Econ 87(11):2549–2569
Brett C, Weymark JA (2011) How optimal nonlinear income taxes change when the distribution of the population changes. J Public Econ 95(11):1239–1247
Choné P, Laroque G (2010) Negative marginal tax rates and heterogeneity. Am Econ Rev 100(5):2532–47
Cremer H, Lozachmeur J-M, Pestieau P (2012) Income taxation of couples and the tax unit choice. J Popul Econ 25(2):763–778
Cuff K (2000) Optimality of workfare with heterogeneous preferences. Can J Econ 33(1):149–174
Diamond P (1998) Optimal income taxation: an example with U-shaped pattern of optimal marginal tax rates. Am Econ Rev 88(1):83–95
Gomes R, Lozachmeur J-M, Pavan A (2018) Differential taxation and occupational choice. Rev Econ Stud 85(1):511–557
Guesnerie R (1995) A contribution to the pure theory of taxation. Cambridge University Press, Cambridge
Hammond P (1979) Straightforward individual incentive compatibility in large economies. Rev Econ Stud 46(2):263–282
Hellwig MF (2007) A contribution to the theory of optimal utilitarian income taxation. J Public Econ 91(7):1449–1477
Hendren N (2020) Measuring economic efficiency using inverse-optimum weights. J Public Econ 2020:187
Jacquet L, Lehmann E (2013) Optimal redistributive taxation with both extensive and intensive responses. J Econ Theory 148(5):1770–1805
Jacquet L, Lehmann E (2021) Optimal income taxation with composition effects. J Eur Econ Assoc 19(2):1299–1341
Kleven HJ, Kreiner CT, Saez E (2009) The optimal income taxation of couples. Econometrica 77(2):537–560
Lehmann E, Simula L, Trannoy A (2014) Tax me if you can! Otimal nonlinear income tax between competing governments. Q J Econ 129(4):1995–2030
Lockwood BB, Weinzierl M (2015) De Gustibus non est Taxandum: heterogeneity in preferences and optimal redistribution. J Public Econ 124:74–80
Mirrlees J (1971) An exploration in the theory of optimum income taxation. Rev Econ Stud 38(2):175–208
Piketty T (1997) La Redistribution fiscale contre le chômage. Revue française d’économie 12(1):157–203
Ramsey FP (1927) A contribution to the theory of taxation. Econ J 37(145):47–61
Rochet J (1985) The taxation principle and multi-time Hamilton-Jacobi equations. J Math Econ 14(2):113–128
Rochet J-C, Stole LA (2002) Nonlinear pricing with random participation. Rev Econ Stud 69(1):277–311
Rochet J-C, Stole LA (1998) Ironing, sweeping, and multidimensional screening. Econometrica 66(4):783–826
Rothschild C, Scheuer F (2013) Redistributive taxation in the Roy model. Q J Econ 128(2):623–668
Rothschild C, Scheuer F (2016) Optimal taxation with rent-seeking. Rev Econ Stud 83(3):1225–1262
Sachs D, Tsyvinski A, Werquin N (2020) Nonlinear tax incidence and optimal taxation in general equilibrium. Econometrica 88(2):469–493
Saez E (2001) Using elasticities to derive optimal income tax rates. Rev Econ Stud 68(1):205–229
Saez E (2002) Optimal income transfer programs: intensive versus extensive labor supply responses. Q J Econ 117:1039–1073
Salanié B (2011) The economics of taxation, 2nd edn. MIT Press
Scheuer F (2013) Adverse selection in credit markets and regressive profit taxation. J Econ Theory 148(4):1333–1360
Scheuer F (2014) Entrepreneurial taxation with endogenous entry. Am Econ J Econ Policy 6(2):126–63
Scheuer F, Werning I (2016) Mirrlees meets Diamond-Mirrlees. Working Paper 22076, National Bureau of Economic Research, March
Werning I (2007) Pareto efficient income taxation. MIT Working Paper 2007
Weymark JA (1986) A reduced-form optimal nonlinear income tax problem. J Public Econ 30(2):199–217
Weymark JA (1987) Comparative static properties of optimal nonlinear income taxes. Econometrica 55(5):1165–1185
Wilson RB (1993) Nonlinear pricing. Oxford University Press, Oxford
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We thank Craig Brett and two anonymous refererees, Pierre Boyer, Vidar Christiansen, Guy Laroque, Emmanuel Saez, Laurent Simula, Stefanie Stantcheva, Kevin Spiritus, Alain Trannoy and Nicolas Werquin. This research was partly realized while Laurence Jacquet was research associate at Oslo Fiscal Studies. She gratefully acknowledges support by Labex MME-DII. The usual disclaimer applies.
Etienne Lehmann is also research fellow at IZA, CESifo and CEPR.
A Appendix
A Appendix
1.1 A.1 Proof of Lemma 4
Proof
The proof consists of two steps. In step (i), we show that there exists at most one incentive-compatible allocation \((w,\theta )\mapsto ({\underline{C}}(w,\theta ),{\underline{Y}}(w,\theta ))\) that verifies Assumption 3 and such that \(({\underline{C}}(w,\theta _0),{\underline{Y}}(w,\theta _0))=(C(w,\theta _0),Y(w,\theta _0))\). In step (ii), we show that this allocation verifies the whole set of incentive constraints (6).
Step (i). To build up the entire incentive-compatible allocation \((w,\theta )\mapsto ({\underline{C}}(w,\theta ),{\underline{Y}}(w,\theta ))\), we must choose \(({\underline{C}}(w,\theta _0),{\underline{Y}}(w,\theta _0))=(C(w,\theta _0),Y(w,\theta _0))\) at any skill level. For each group \(\theta\), \({\underline{Y}}(\cdot ,\theta )\) verifies Assumption 3 if and only if its reciprocal \({\underline{Y}}^{-1}(\cdot ;\theta )\) is smoothly increasing. Let \(y\in \mathbb {R}_+\) be an income level. As \(Y(\cdot ,\theta _0)\) is smoothly increasing from Assumption 3, there exists a unique skill level w such that \(y=Y(w,\theta _0)\). Then according to Lemma 3, among individuals of group \(\theta\), only those of skill \({\underline{W}}(w,\theta )\) must be assigned to the income level \(y=Y(w,\theta _0)\) to verify incentive-compatibility.Footnote 10 Therefore, \({\underline{Y}}^{-1}(\cdot ,\theta )\) must be defined by:
\({\underline{Y}}^{-1}(\cdot ,\theta )\) is then smoothly increasing as a combination of two smoothly increasing functions. Moreover, since for each type \((\omega ,\theta )\), there exists a single skill level \(\omega\) such that \({\underline{Y}}(\omega ,\theta )=\textit{Y}(w,\theta _0)\), incentive compatibility requires that \({\underline{C}}(\omega ,\theta )\) also needs to be equal to \({\underline{C}}(w,\theta _0)\). This ends the proof of step (i).
Step (ii). Note that the allocation \((w,\theta )\mapsto ({\underline{Y}}(w,\theta ),{\underline{C}}(w,\theta ))\) is built in such a way that one has \({\underline{Y}}(\omega ,\theta )=\textit{Y}(w,\theta _0)\text { and } {\underline{C}}(\omega ,\theta )=\textit{C}(w,\theta _0)\) if and only if \(\omega ={\underline{W}}(w,\theta )\) and (10) holds. Differentiating in w both sides of these two equations and rearranging terms, we obtain
As \(w\mapsto (C(w,\theta _0),Y(w,\theta _0))\) is assumed to verify the within-group incentive constraints in Eq. (8b), we know that the left-hand side of the above equation is equal to
Using the definition of \({\underline{W}}(\cdot ,\theta )\), we have that \(w\mapsto ({\underline{C}}(w,\theta ),{\underline{Y}}(w,\theta ))\) also verifies Eq. (8b). From Lemma 2, it thus verifies the within-group incentive constraints (7). We now check whether the inequality (6) is verified for any \((w,w',\theta ,\theta ')\in \mathbb {R}_+^2\times \Theta ^2\). We know there exists \(\omega \in \mathbb {R}_+\) such that \({\underline{Y}}(\omega ,\theta )={\underline{Y}}(w',\theta ')\text { and } {\underline{C}}(\omega ,\theta )={\underline{C}}(w',\theta ')\). The incentive constraints in (6) are therefore equivalent to:
The latter inequality is verified as \(w\mapsto ({\underline{C}}(w,\theta ),{\underline{Y}}(w,\theta ))\) satisfies Eq. (8b). \(\square\)
1.2 A.2 Derivation of Eq. (17)
Proof
To derive (17), we must compute the various Gâteaux derivatives at \(t=0\). For \(A=C,Y,U\) and a given \(\delta\), the Gâteaux derivative of A in the direction \(\Delta _Y(\cdot ,\cdot ;\delta )\) at \(t=0\) is denoted \(\hat{{\hat{A}}}(x,\theta ;\delta )\). Let us remind its definition:
By definition we get: \(\hat{{\hat{Y}}}(x,\theta _0;\delta )=\Delta _Y(x;\delta )\), and from (15b) we obtain:
Equation (15c) imply that the Gâteaux derivatives of utilities are nil for skill below \(W(w-\delta ,\theta )\). For skills x between \(W(w-\delta ,\theta )\) and \(W(w,\theta )\), Eq. (15e) implies:
For skill x above \(W(w,\theta )\), according to (15f), we have:
Moreover, Eq. (15h) implies that the Gâteaux derivatives of income must verify:
Using Eqs. (12), (24a) and (24c), the Gâteaux derivative of the Lagrangian (16) is:
Dividing the first-order condition \(\frac{\partial \hat{\mathscr {L}}}{\partial t}(0;\delta )=0\) by \(\int _{w-\delta }^{w} \upsilon _{yw}\left( Y(x,\theta _0);x,\theta _0\right) \ \hat{{\hat{Y}}}(x,\theta _0;\delta )\ dx\) implies, using (24b) and (24d), that:
We finally take the limit of the latter equality when \(\delta\) tends to 0. Let us consider the first term in the right-hand side of (26). Since
we get that:
As the right hand-side of the latter inequality tends to 0 when \(\delta\) tends to 0, the limit of (26) when \(\delta\) tends to zero leads to:
By continuity, the variations of \(f(x|\theta )\), \(\upsilon _y(Y(x,\theta );x,\theta )\), \(\upsilon _{yw}(Y(x,\theta );x,\theta )\) and \(u^\prime (c(x,\theta ))\) within the skill intervals \([W(w-\delta ,\theta ),W(w,\theta )]\) are of second-order when \(\delta\) tends to 0. As \(\Theta\) and intervals \([W(w-\delta ,\theta ),W(w,\theta )]\) are compact, for any small \(e>0\), there always exists \({\tilde{\delta }}(e)\) such that for all \((x,\theta )\in [W(w-{\tilde{\delta }}(e),\theta ),W(w,\theta )]\times \Theta\), one has:
and
so that for all \(\delta <{\tilde{\delta }}(e)\):
and therefore, for all \(\delta <{\tilde{\delta }}(e)\):
Hence, the left-hand side of (27) is equal to the left-hand side of (17). \(\square\)
1.3 A.3 Proof of Lemma 5
With one-dimensional heterogeneity, we only consider within-group incentive constraints. Adopting a first-order approach, only (8a) is considered when building up the Hamiltonian:
where \(Y(w,\theta )\) and \(U(w,\theta )\) are the control and state variables respectively. Using (12), the necessary conditions are:
Combining (28b) with (28d) leads to
Combining (3), (2), (28a) and (28e) leads to (18a). Combining (28c) with (28e) leads to (18b).
1.4 A.4 Proof of Proposition 2
Define a reform of a tax schedule \(y\mapsto T(y)\) with its direction, which is a differentiable function \(y\mapsto R(y)\) defined on \({\mathbb {R}}_+\), and with its algebraic magnitude \(m\in {\mathbb {R}}\). After a reform, the tax schedule becomes \(y\mapsto T(y)-m \ R(y)\) and the utility of an individuals of type \((w,\theta )\) is:
We denote by \(Y^R(m;w,\theta )\) the income of workers of types \((w,\theta )\) after the reform and her consumption becomes \(C^R(m;w,\theta )=Y^R(m;w,\theta )-T(Y^R(m;w,\theta ))+m\ R(Y^R(m;w,\theta ))\). When \(m=0\), we have \(Y^R(0;w,\theta )=Y(w,\theta )\) and \(C^R(0;w,\theta )=C(w,\theta )\). Applying the envelope theorem to (29), we get:
Using (3), the first-order condition associated to (29) equalizes to zero the following expression:
For simplicity, we drop the superscript R and write \(\mathscr {Y}_y(Y(w,\theta );w,\theta )\) for \(\mathscr {Y}_y^R(Y(w,\theta ),0;w,\theta )\).Footnote 11 We define behavioral responses to tax reforms of direction R by applying the implicit function theorem to \(\mathscr {Y}^R(y,m;w,\theta )=0\) at \(m=0\), which yields:
where:
Using (2) and plugging \(R(Y(w,\theta ))=0\) and \(R^\prime (Y(w,\theta ))=0\) into (33b), the compensated elasticity of earnings (19a) can be rewritten as:
which is positive since \(\mathscr {Y}_y\left( Y(w,\theta );w,\theta \right) <0\). Plugging \(R(Y(w,\theta ))=1\) and \(R^\prime (Y(w,\theta ))=0\) into (33b), the income effect (19b) can be rewritten as:
which is negative if leisure is a normal good, since then \(\mathscr {M}_c>0\). The elasticity \(\alpha (w;\theta )\) of earnings with respect to the skill level can be expressed as:
Dividing (34a) by (34c) we get:
Plugging (34a) into (34b) leads to:
It is then straightforward to obtain:
Let \(y\in \mathbb {R}_+\). Since \(\mathscr {Y}_y\left( Y(w,\theta );w,\theta \right) <0\), there exists a single skill level w such that \(y=Y(w,\theta _0)\). From (2), we know that:
The term in the left-hand side integral of (14a) can be rewritten as:
The first equality is obtained using Eq. (35). The second equality uses (21). It implies with (22b) that Eq. (14a) can be rewritten as:
where J(w) is defined by the right-hand side of (14a). \(J(\cdot )\) admits for derivative \({\dot{J}}(w)\) where:
where (20) has been used. Deriving with respect to the skill w both sides of (9) and of \(C(w,\theta _0)=Y(w,\theta _0)-T\left( Y(w,\theta _0)\right)\), we obtain:
We thus obtain:
Using (21) and (38), \({\dot{J}}(w)\) can be rewritten as:
As \(J(w)=\int _{x\ge w} (-{\dot{J}}(x))dx\), we get
Changing variables by posing \(z=Y(x,\theta _0)\), we get
Plugging (39) into (38) gives (23a). Combining (14b) and (39) leads to (23b).
1.5 A.5 Proof of Proposition 3
Let us denote
the ratio of the right-hand side of (14a) at the skill level w divided by \(u^\prime \left( Y(w,\theta _0)-T(Y(w,\theta _0))\right)\). According to Proposition 1, Eq. (14a) and \(\upsilon _y>0>\upsilon _{yw}\), the sign of \(T^\prime (Y(w,\theta _0))\) is the sign of K(w).
Under utilitarian preferences, \(\Phi _{u}=1\). Changing variable in (40) from x to t such that \(x=W(t,\theta )\), (i.e. \(Y(x,\theta )\equiv Y(t,\theta _0)\) and \(C(x,\theta )\equiv C(t,\theta _0)\) according to (9)), we get:
The derivative of K(w) has the sign of \(1/\lambda -1/u^{\prime }(C(w,\theta _0))\), which is decreasing in w because of the concavity of \(u(\cdot )\). Moreover, \(\underset{w\mapsto \infty }{\lim }K(w)=0\) and Eq. (14b) implies that \(K(0)=0\). Therefore, \(K(\cdot )\) first increases and then decreases. It is thus positive for all (interior) skill levels. So, optimal marginal tax rates are positive.
Under maximin, one has \(U(x,\theta )>U(0,\theta )\) for all \(x>0\) from (8a). Therefore, within each group, the most deserving individuals are those whose skill \(w=0\). The maximin objective implies \(\Phi _{U}\left[ x,\theta \right] =0\) for all \(x>0\). Hence, Eq. (40) simplifies to:
for all \(w>0\), which is always positive, thereby leading to positive optimal marginal tax rates.
Rights and permissions
About this article

Cite this article
Jacquet, L., Lehmann, E. Optimal tax problems with multidimensional heterogeneity: a mechanism design approach. Soc Choice Welf 60, 135–164 (2023). https://doi.org/10.1007/s00355-021-01349-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00355-021-01349-4