
Abstract
Purpose
To investigate and implement semiautomated screening for meta-analyses (MA) in urology under consideration of class imbalance.
Methods
Machine learning algorithms were trained on data from three MA with detailed information of the screening process. Different methods to account for class imbalance (Sampling (up- and downsampling, weighting and cost-sensitive learning), thresholding) were implemented in different machine learning (ML) algorithms (Random Forest, Logistic Regression with Elastic Net Regularization, Support Vector Machines). Models were optimized for sensitivity. Besides metrics such as specificity, receiver operating curves, total missed studies, and work saved over sampling were calculated.
Results
During training, models trained after downsampling achieved the best results consistently among all algorithms. Computing time ranged between 251 and 5834 s. However, when evaluated on the final test data set, the weighting approach performed best. In addition, thresholding helped to improve results as compared to the standard of 0.5. However, due to heterogeneity of results no clear recommendation can be made for a universal sample size. Misses of relevant studies were 0 for the optimized models except for one review.
Conclusion
It will be necessary to design a holistic methodology that implements the presented methods in a practical manner, but also takes into account other algorithms and the most sophisticated methods for text preprocessing. In addition, the different methods of a cost-sensitive learning approach can be the subject of further investigations.
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
Introduction
Evidence-based medicine is the standard approach in modern patient care, incorporating clinical experience, patient will and current research findings. Systematic reviews (SRs) aim to collect and critically evaluate the complete evidence on a given topic in order to gain a better overview of the large amount of available data.
The different steps of SR and MA are highly standardized and defined according to the guidelines of the Cochrane Handbook for Systematic Reviews of Interventions [1] and by the Preferred Reporting Items for Systematic Reviews and Meta-Analysis (PRISMA) [2]. Overall, performing SR with or without MA is a time-consuming process that can involve more than 1,000 h [3]. In an analysis of 195 SR/MAs, Borah et al. showed that the average time to publication was more than one year (62 weeks), while some reviews took more than three years to be published [4].
Furthermore, during conduction of a SR/MA, only a fraction of all studies that are initially identified in the systematic literature search will be included in the final analysis. This is because the initial search is usually very broad to maximize sensitivity, as the costs of missing a relevant study might be worse than the higher workload during screening. This results in a classification problem, since the two classes (“included” and “excluded”) differ massively in number. This is also known as class imbalance. The use of machine learning (ML) algorithms has the potential to reduce the workload for research teams. However, ML algorithms tend to perform worse when class imbalance is present. To overcome this challenge, different measures to account for class imbalance such as sampling, cost-sensitive learning and weighting can be applied.
Sampling involves a modification of the training dataset. As such, upsampling can involve the random duplication or the synthetic generation of undersampled instances. Downsampling on the other side involves the random removal of the oversampled instances. As both methods result in a different dataset, the subsequently trained model will show a difference. Furthermore, cost-sensitive learning involves changing the cost of the model based on the errors made. As such, the cost of falsely excluding a study would be higher than the cost of falsely including a study. Weighting again involves a modification of the algorithm in which classes that are underrepresented are assigned higher weights in an attempt to address the present real-world considerations. In addition, classification thresholds can be shifted in either direction in order to obtain better results [5, 6]. Lange et al. provided a detailed comparison of methods in updating MA of diagnostic studies with respect to different ML or deep learning algorithms and also investigated the influence of initial text processing in detail [5]. However, a comprehensive analysis for an automated screening for SR/MA in urology, incorporating randomized and non-randomized trials with particular consideration of class imbalance does not exist.
Therefore, this study aimed to investigate the feasibility of an automated ML-based screening for meta-analysis comparing different algorithms and approaches to account for class-imbalance.
Materials and methods
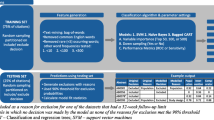
In the presented study, previously published MAs from our group were used to train the algorithms, as detailed information of the screening process (decision of two independent reviewers at each screening step) were available. The first review focused on the perioperative administration of blood transfusions during radical cystectomy [7]. The second review explored Radiomics for the classification of kidney tumors [8]. The third review, currently under publication, focuses on a critical analysis of the quality of evidence from randomized controlled trials (RCTs) in bladder cancer (PROSPERO: CRD42021247145) [9]. In the following, the three MAs are referred to as “Transfusion,” “Radiomics,” and “Urobase.”
Machine learning algorithms
The systematic comparison of different ML algorithms is not the primary aim of the presented project work. However, to ensure that some adjustments for class imbalance are not dependent on the applied ML algorithm, three algorithms were examined. These algorithms were:
-
1.
Random forest (RF)
-
2.
Logistic regression with elastic net regularization (LogReg)
-
3.
Support vector machines (SVM)
Parameters and evaluation metrics
As input data for the models, different scenarios (see supplementary file 1, Table 1) were created, consisting of different combinations of available parameters (size of training dataset (200, 400, 600, 800 studies), consideration of the assessment of one human reviewer (include/exclude) and choice of text variables (abstract only, title + abstract, title + abstract + keywords). The data handling process is also described in the supplementary material.
The study aimed to solve a binary classification project, namely the decision (include / exclude) during the screening process of SR/Mas. Therefore, we assessed misses and work saved over sampling (WSS) as outcome parameters. WSS was introduced by Cohen et al. and is dedicated to be used for SRs [10]. For visualization purposes we created box-plots and violin plots as well as histograms. As performance parameters we used sensitivity, specificity and receiver operating characteristic (ROC)-curves with the area under the curve (AUC). Accuracy was not deemed adequate since due to the class imbalance problem, classifying all studies as “exclude” would result in high accuracy while still missing all relevant studies.
Results
The characteristics of the three included reviews “Transfusion,” “Radiomics,” and “Urobase“ can be found in Table 1. While “Transfusion” and “Radiomics” are quite similar in the number of hits as well as the total number of hits found by the literature search, the systematic literature search for “Urobase” yielded significantly more hits. As another unique characteristic, only RCTs were considered for Urobase according to the study protocol. Additionally, the severe class imbalance becomes apparent (only 2–11% of all studies are included).
Training process (on training data set)
As first step, ML algorithms were trained using the defined set of hyperparameters and input variables to define the optimal scenario (see supplementary file). The best model for each ML algorithm and sampling method was then used on the validation and test data set. This process was repeated for each of the three available SRs. As expected, for all reviews, integration of the choice of reviewer 1 (include/exclude), title + abstract + keywords, and larger size of the training data set yielded better results.
Impact of different sampling methods on sensitivity
During model training, downsampling showed the best performance measured by the sensitivity. While there were no obvious differences between weighting and upsampling, the original data set had the worst sensitivity. In addition, downsampling showed the lowest dispersion which was consistent among all ML algorithms (see Fig. 1).

Performance comparison of different sampling methods based on sensitivity on training data set among the different MA/SRs
Thresholding (on validation data set)
The selected models from the training data set, that performed best, were used on the validation data set. In a first step, ROCs with the respective AUCs were calculated (supplementary). The optimal threshold was then extracted as the threshold with a sensitivity of 1 with the best possible specificity. In addition further potential thresholds such as median and mean were extracted (see supplementary file).
Final analysis (on test data set)
For the sensitivity as a decisive parameter for the given question, very good results were shown for the two SRs “Transfusion” and “Radiomics” as a sensitivity of 100% was achieved when the 1st quartile of all class probabilities from the test data set was selected as the threshold. For the “Urobase” SR, however, a worse performance was shown, with the 1st quartile of class probabilities as threshold again yielding the best sensitivity. Furthermore, the importance of thresholding is evident across all SRs examined, as the default threshold of 0.5 resulted in a decline in sensitivity. This was shown to be independent from the sampling approach. With regard to the sampling methods, the weighting approach proved superior to the other methods, with upsampling and downsampling yielding the worst performance in terms of sensitivity in the final test dataset (Fig. 2).

Final evaluation for sensitivity on test data set based on different thresholds and sampling methods
Misses
As already evident from the sensitivity, some studies were missed by the models. Accordingly, the number of misses in the transfusion and radiomics SRs was low, whereas the number of misses in Urobase was significantly higher (Fig. 3). Similarly, it was confirmed that the weighting approach had the fewest misses. It is also clear that there is a need for thresholding, as many more studies would be missed with the standard threshold of 0.5. It must be noted that the misses shown in Fig. 5 refer to the title and abstract screening. Therefore, it was checked whether these misses were excluded in the full text screening anyway or whether they were finally also considered in the final SR. The number of misses of the respective final SR is shown in the supplementary material.

Overview of missed studies after title/abstract screening in relation to sampling method and threshold
Discussion
The aim of this work was to implement a method for a semi-automated title/abstract screening for SR/MAs in Urology with a focus on different measures to account for class imbalance. Overall the methods examined performed well in identifying relevant studies.
Regarding the different approaches, thresholding showed a positive impact on sensitivity, independent from sampling method or underlying review compared to the standard threshold of 0.5. Using diagnostic studies as an example, Ewald et al. were able to show that the choice of a data-driven threshold can lead to an increase in bias toward better test performance, especially when the prevalence is below 50% [11]. Accordingly, the definition of the optimal threshold depends on the evaluation metric under consideration [12].
Concerning the sampling methods, weighting was consistently shown to be superior to the other methods on the test dataset, across all reviews and the different thresholds. In contrast, during model training, there was a clear advantage of downsampling across all reviews as measured by the sensitivity. This underlines the importance of independent data sets for model training and testing. In previous works, van Hulse et al. showed that the performance of different sampling methods is sometimes dependent on the ML algorithm used [13]. Japkowicz et al. also compared different sampling methods in their study and concluded that both random upsampling and downsampling are effective methods for adjusting class imbalance [14]. In a recent study, Nishant et al. reported a hybrid method combining upsampling and downsampling. This method was shown to be superior to the other upsampling methods investigated in this study [15]. However, as our study suggests a weighting should be implemented based on the presented results.
The different methods to account for class imbalance are different mechanisms during model building, thus a combination of the methods is possible as presented in our study. Thresholding, as a post-hoc procedure, does not lead to any improvement of the algorithm or the model itself, but only the shifting of the threshold [16]. In contrast, sampling methods primarily belong to the preprocessing methods [17], since here the model training is based on a modified data set. Unlike thresholding, a cost-sensitive learning approach has the potential to result in an actual improvement at the level of the algorithm itself. Lopez et al. compared sampling methods, cost-sensitive learning, and a combination of both [18].
Recently, Large Language Models (LLMs) are being increasingly explored for various applications within the context of SR and MA. Gou et al. test ChatGPT-4 against human reviewers for an automated paper screening. They found that LLMs should be used as an adjunct rather then a replacement for human reviewers [19]. This is in line with the findings by Khraisha et al. who also emphasized that the results of LLMs should be interpreted with caution while they might be helpful certain review tasks [20].
As a further limitation it must be mentioned that for text preprocessing only a small selection of text procession measures were applied. However, the importance of text preprocessing has already been examined previously and was not the aim of the current study.
Conclusions
We were able to show that weighting in combination with thresholding yielded the greatest improvements. In the future, it will be necessary to design a holistic methodology that implements the methods presented here in a practical manner, but also takes into account other algorithms and a wide variety of methods for text preprocessing.
References
Higgins JP, Green S (2011) Cochrane handbook for systematic reviews of interventions, vol 4. Wiley
Moher D et al (2009) Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. BMJ, 339
Pham B et al (2021) Text mining to support abstract screening for knowledge syntheses: a semi-automated workflow. Syst Reviews 10(1):156
Borah R et al (2017) Analysis of the time and workers needed to conduct systematic reviews of medical interventions using data from the PROSPERO registry. BMJ open 7(2):e012545
Lange T et al (2021) Machine learning for identifying relevant publications in updates of systematic reviews of diagnostic test studies. Res Synth Methods
López V et al (2013) An insight into classification with imbalanced data: empirical results and current trends on using data intrinsic characteristics. Inf Sci 250:113–141
Uysal D et al (2021) Impact of perioperative blood transfusions on oncologic outcomes after radical cystectomy: a systematic review and meta-analysis of comparative studies. Surg Oncol 38:101592
Mühlbauer J et al (2021) Radiomics in Renal Cell Carcinoma-A systematic review and Meta-analysis. Cancers (Basel), 13(6)
Wieland VL et al (2023) Framework for a living systematic review and meta-analysis for the surgical treatment of bladder cancer: introducing EVIglance to urology. Int J Surg Protocols 27(2):97–103
Cohen AM et al (2006) Reducing workload in systematic review preparation using automated citation classification. J Am Med Inf Association: JAMIA 13(2):206–219
Ewald B (2006) Post hoc choice of cut points introduced bias to diagnostic research. J Clin Epidemiol 59(8):798–801
Luque A et al (2019) The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recogn 91:216–231
Van Hulse J, Khoshgoftaar TM, Napolitano A (2007) Experimental perspectives on learning from imbalanced data. in Proceedings of the 24th international conference on Machine learning
Japkowicz N (2000) The class imbalance problem: Significance and strategies. in Proc. of the Int’l Conf. on Artificial Intelligence. Citeseer
Nishant PS et al (2021) HOUSEN: Hybrid over–Undersampling and Ensemble Approach for Imbalance classification, in Inventive systems and Control. Springer, pp 93–108
Kuhn M, Johnson K (2013) Applied predictive modeling, vol 26. Springer
Ganganwar V (2012) An overview of classification algorithms for imbalanced datasets. Int J Emerg Technol Adv Eng 2(4):42–47
López V et al (2012) Analysis of preprocessing vs. cost-sensitive learning for imbalanced classification. Open problems on intrinsic data characteristics. Expert Syst Appl 39(7):6585–6608
Guo E et al (2024) Automated Paper Screening for clinical reviews using large Language models: Data Analysis Study. J Med Internet Res 26:e48996
Khraisha Q et al (2024) Can large language models replace humans in systematic reviews? Evaluating GPT-4’s efficacy in screening and extracting data from peer-reviewed and grey literature in multiple languages. Res Synth Methods
Acknowledgements
This study was part of Dr. Kowalewski’s Master’s thesis at Heidelberg University for the Master of Science in “Medcial Biometry/Biostatistics”.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
Protocol/project development: Seide, Kowalewski, Michel. Data collection and management: Menold, Wieland, Uysal. Data analysis: Haney, Kowalewski, Wessels, Wieland. Manuscript writing/editing: Menold, Kowalewski, Haney, Cacciamani, Uysal. Critical Revision: Michel, Wessels, Cacciamani. Authors whose names appear on the submission have contributed sufficiently to the scientific work and therefore share collective responsibility and accountability for the results.
Corresponding author
Ethics declarations
Ethical approval
This study did not involve human or animal resources. Ethical approval was not indicated.
Research involving human participants
Not applicable.
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Menold , H., Wieland , V., Haney , C. et al. Machine learning enables automated screening for systematic reviews and meta-analysis in urology. World J Urol 42, 396 (2024). https://doi.org/10.1007/s00345-024-05078-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00345-024-05078-y