
Abstract
Objectives
Large language models (LLMs) have shown potential in radiology, but their ability to aid radiologists in interpreting imaging studies remains unexplored. We investigated the effects of a state-of-the-art LLM (GPT-4) on the radiologists’ diagnostic workflow.
Materials and methods
In this retrospective study, six radiologists of different experience levels read 40 selected radiographic [n = 10], CT [n = 10], MRI [n = 10], and angiographic [n = 10] studies unassisted (session one) and assisted by GPT-4 (session two). Each imaging study was presented with demographic data, the chief complaint, and associated symptoms, and diagnoses were registered using an online survey tool. The impact of Artificial Intelligence (AI) on diagnostic accuracy, confidence, user experience, input prompts, and generated responses was assessed. False information was registered. Linear mixed-effect models were used to quantify the factors (fixed: experience, modality, AI assistance; random: radiologist) influencing diagnostic accuracy and confidence.
Results
When assessing if the correct diagnosis was among the top-3 differential diagnoses, diagnostic accuracy improved slightly from 181/240 (75.4%, unassisted) to 188/240 (78.3%, AI-assisted). Similar improvements were found when only the top differential diagnosis was considered. AI assistance was used in 77.5% of the readings. Three hundred nine prompts were generated, primarily involving differential diagnoses (59.1%) and imaging features of specific conditions (27.5%). Diagnostic confidence was significantly higher when readings were AI-assisted (p > 0.001). Twenty-three responses (7.4%) were classified as hallucinations, while two (0.6%) were misinterpretations.
Conclusion
Integrating GPT-4 in the diagnostic process improved diagnostic accuracy slightly and diagnostic confidence significantly. Potentially harmful hallucinations and misinterpretations call for caution and highlight the need for further safeguarding measures.
Clinical relevance statement
Using GPT-4 as a virtual assistant when reading images made six radiologists of different experience levels feel more confident and provide more accurate diagnoses; yet, GPT-4 gave factually incorrect and potentially harmful information in 7.4% of its responses.
Key Points
-
The benefits and dangers of GPT-4 for textual assistance in radiologic image interpretation are unclear.
-
GPT-4’s textual assistance improved radiologists’ diagnostic accuracy from 75 to 78%.
-
Less experienced radiologists used GPT-4 for guidance on differential diagnoses and imaging findings.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Large language models (LLMs) are steadily advancing in various sectors, including healthcare. As the first mainstream dialogue-based artificial intelligence (AI) model, chatGPT has gained immense popularity [1]. Even though prior LLMs, such as BERT (Bidirectional Encoder Representations from Transformers), gained popularity in the past [2], attention transformer-based LLMs, such as chatGPT, have largely replaced them.
Potential use cases involve radiologic reporting [3, 4] and guidance on utilizing imaging services [5]. ChatGPT passed the United States Medical Licensing Exam [6] and nearly passed a radiology board-style examination without images [7]. Recent studies have summarized LLMs’ evolving role and impact in radiology. Bajaj et al highlighted the potential of LLMs to improve image interpretation efficiency and streamline radiologists’ workflows [8]. D’Antonoli et al emphasized the need for radiologists to understand their technical basics, ethical considerations, and potential risks [9]. Bera et al analyzed the available literature on ChatGPT (as of August 2023) and found 51 studies that detailed the model’s multifaceted applications in radiology and the -by and large- “impressive performance” [10]. Specifically, ChatGPT’s capability to evaluate patient studies and provide radiologic diagnoses has been studied in well-presented literature case series such as the American Journal of Neuroradiology’s “Case of the Month” [11] and Radiology’s “Diagnosis Please” series [12]. ChatGPT was also fed appropriateness criteria (by the American College of Radiology) to create a context-aware chatbot for improved decision-making for clinical imaging [13]. Yet, the tool’s potential to provide “reading room assistance” to the radiologist when reading and interpreting imaging studies has not been evaluated. Our objectives were (i) to investigate chatGPT’s effects on diagnostic accuracy and confidence, (ii) to study user interactions with chatGPT, and (iii) to assess the quality of chatGPT’s responses in terms of accuracy, up-to-dateness, and reliability. Our hypothesis was that radiologists would benefit from chatGPT’s assistance, particularly when inexperienced. Here, we implicitly operated under the null hypothesis (H0) of no difference in diagnostic accuracy and confidence with and without AI assistance. Conversely, the alternative hypothesis (H1) assumed that AI assistance provides a measurable difference.
Materials & methods
Study design and dataset characteristics
Approval was granted by the local ethical committee (reference number 028/19), and the requirement to obtain individual informed consent was waived.
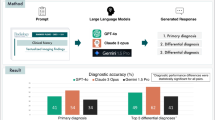
This study was designed as a retrospective intra-individual comparative reader study on existing imaging studies that were prospectively read with and without assistance by GPT-4, the latest version of ChatGPT, to evaluate its effects on the radiologic workflow. Figure 1 details the study workflow.

Study workflow. Six radiology residents of variable experience levels read 40 imaging studies comprising clinical information and images under unassisted and AI-assisted clinical conditions. Their differential diagnoses were evaluated regarding diagnostic accuracy and confidence. Stars indicate years of experience
Selection of imaging studies
By screening the local PACS (Picture Archiving and Communication System, iSite, Philips Healthcare, Best, Netherlands) of our tertiary academic medical center (University Hospital Aachen, Aachen, Germany), two resident radiologists with three years of experience (R.S. and M.H.) and two board-certified clinical radiologists (D.T. and S.N. [with 10 and 8 years of experience]) selected ten radiographic, CT, MRI, and angiographic studies each (Table 1). The imaging studies reflected various demographic characteristics, i.e., patient age and sex, and conditions of variable severity and complexity. Only studies with unequivocal findings were selected, and the reference diagnoses were established based on the synopsis of the original radiologic reports, associated clinical and nonimaging findings, and follow-up studies. Imaging studies were disregarded in the case of inconsistent or contradictory findings. After anonymization, patients’ age, sex, and other details, such as the reason for the exam, were removed from the studies, and only the study to be assessed was included. Angiographic studies, for example, were prepared so that the postdiagnostic therapeutic and post-therapeutic image series were removed. The studies were fed back to the research section of the PACS individually, where they could be accessed on clinical workstations. Standardized case descriptions were framed for each study, indicating the relevant clinical context and allowing radiologists to put their findings into the appropriate clinical perspective.
Experimental setup and data collection
Six clinical resident radiologists with varying experience levels were recruited. Because the radiology residency in Germany usually takes five years, their experience level was trichotomized as limited (up to 1 year of clinical experience), moderate (between 1 and 4 years of clinical experience), and advanced (more than 4 years of clinical experience but not yet board certified). Two radiologists of each experience level were recruited.
The radiologists were asked to diagnose each patient based on the imaging study and case description in two sessions: (i) unassisted and (ii) AI-assisted. “Unassisted” meant that external references, e.g., online searches or textbooks, were prohibited. “AI-assisted” meant that GPT-4 could be prompted without restrictions. Additional external references were similarly prohibited from singling out the effect of GPT-4. We did not use any additional GPT-4 add-ons, meaning GPT-4 had to resort to its internal knowledge. The radiologists were introduced to the setup and adequately trained to interact with GPT-4. They were also instructed that prompts could query any aspect of diagnostic decision-making, from clinical diagnoses and associated imaging findings to radiologic signs of diseases and gradings to classifications. To assess the natural interaction with the tool, no guidance on optimizing the interaction or identifying “hallucinations” was provided.
The imaging studies were read on in-house radiology workstations. Per case, radiologists provided up to three diagnoses, ranked in descending order of probability, and the confidence level using a five-point Likert scale ranging from “very unsure” (score 1) to “very sure” (score 5). After completing the questionnaires unassisted (session one), the radiologists re-read the same studies using AI assistance (session two). Time restrictions or a minimum washout period were not instituted, and the radiologists could re-read the imaging studies at their chosen time. However, they were instructed not to collect additional information or seek assistance on the patients, studies, or differential diagnoses between the readings. Further details on the experimental setup are provided in the Supplementary Text and Supplementary Fig. 1.
Outcome metrics and evaluation
Different aspects of the diagnostic workflow were evaluated as performance, interaction, and user experience metrics.
Performance
Diagnostic accuracy was assessed based on the radiologist-provided diagnoses and counted as correct if the correct diagnosis was (i) among the three differential diagnoses (‘top-3 performance’) and (ii) the first differential diagnosis (‘top-1 performance’). Superordinate diagnoses (e.g., ‘peripheral artery disease’) instead of the more specific diagnosis (e.g., ‘superficial femoral artery stenosis’) were considered correct if the clinical presentation and imaging findings did not differ considerably. Overly vague diagnoses (like ‘vasculopathy’) or considerably different clinical presentations and imaging findings (like ‘tuberculosis’ instead of ‘miliary tuberculosis’) were rejected. Ambiguous diagnoses were discussed by the four radiologists above and considered against the case description and imaging findings.
Interaction
The radiologist-GPT-4 interactions were parameterized and quantified as the number and type of prompts per study. Prompts were categorized based on their purpose as (i) asking for differential diagnoses, (ii) seeking clarification on gradings and classifications, (iii) requesting pathology-related information, (iv) requesting anatomy-related information, (v) enquiring about imaging features of a condition, or (vi) asking for basic guidance on how to interpret a particular imaging study. Prompts could be assigned to different prompt types. Response quality was assessed qualitatively, and four radiologists (M.H., R.S., D.T., S.N.) evaluated whether the information provided by GPT-4 was verified, up-to-date, and reliable. They analyzed all prompts and responses independently and noted possibly incorrect or inconsistent responses that were subsequently discussed until a consensus was reached. ‘hallucinations’ were defined as seemingly correct responses that (i) were nonsensical when considered against common knowledge in radiology or (ii) inconsistent with framework information or conditions stated in the radiologist’s request. ‘Misinterpretations’ were defined as GPT-4 misunderstanding a question or providing contextually misleading or irrelevant responses. ‘Clarifications’ were defined as GPT-4 lacking understanding of a prompt that necessitated its rephrasing. Notably, the training of GPT-4 was concluded in 2021, which was considered when evaluating the response quality.
User experience
Diagnostic confidence (with and without AI assistance) was registered as above. Additionally, the radiologists were asked to provide general feedback on satisfaction, utility, ease of use, and trust on five-point Likert scales, ranging from ‘very poor’ (score 1) to ‘very good’ (score 5).
Statistical analysis and power analysis
Statistical analyses were performed using GraphPad Prism software (v9.5, San Diego, CA, USA) and Python (v3.11) and its library statsmodel by R.S., M.H., D.T., and S.N. Diagnostic accuracy was calculated as the number of correct diagnoses divided by the number of correct and incorrect diagnoses for the ‘top-3 performance’ and ‘top-1 performance’ approaches. We used a generalized linear mixed-effects model within a logistic regression framework to account for the binary outcome, i.e., correct and incorrect. Experience, modality, and AI assistance were treated as fixed effects and the radiologists as random effects. After yielding inflated coefficients, likely due to overfitting and multicollinearity, we used a simplified model that focused exclusively on the main predictors of diagnostic accuracy. An analogous model was used to study the predictors’ impact on diagnostic confidence. For the top-3 and the top-1 performance approaches, a two-proportion z-test was used to determine whether differences in diagnostic accuracy were significant between AI-assisted and unassisted radiologists. Post hoc, the effect size was quantified using Cohen’s h as a measure of the difference between two proportions. Means and 95% confidence intervals are given, and the significance level was set at α ≤ 0.05.
Given the scarce availability of literature evidence on diagnostic accuracy as a function of AI assistance, a rudimentary sample size estimation was conducted. Informed by related literature evidence [14], we assumed a small effect size of 0.2. Consequently, the minimum sample size was determined a priori as 208 using the power of 0.8, the probability of an α error of 0.05, a t-test and Wilcoxon signed-rank test (matched pairs), and a two-tailed procedure (G*Power, v3.1.9.7; Heinrich-Heine-University; [15]). Supplementary Figure 2 provides a screenshot of the sample size estimation.
Results
The study was conducted between May 10th and June 5th, 2023. Our study involved a sample size of 240 studies, which exceeded the calculated minimum sample size required for adequate power, as determined by our prior power analysis. All radiologists completed the unassisted (session one) and AI-assisted (session two) readings during this period. The time delay between the reading sessions was 6.3 ± 6.3 days (range, 0–18 days).
‘Top-3 performance’: we found moderately improved diagnostic accuracy when considering the three radiologist-provided diagnoses. Specifically, accuracy improved from 181/240 (75.4%, unassisted) to 188/240 studies (78.3%, AI-assisted), which aligns with the expected effect direction and magnitude. Yet, the hypothesis that radiologists’ diagnostic accuracy would benefit from using AI assistance cannot be accepted based on the current study, as the calculated effect size for diagnostic accuracy improvement was small (Cohen’s h: 0.069 [top-3] and 0.079 [top-1]) and not statistically significant (p = 0.130 [top-3] and p = 0.083 [top-1]; z-test). The greatest increases in correct diagnoses were found for radiologists with low experience and CT and MRI (Fig. 2), which supports our hypothesis (i). Supplementary Table 1 details the total counts of correct and incorrect diagnoses and diagnostic accuracy.

Diagnostic accuracy as a function of modality, experience level, and AI assistance. Detailed breakdown of the correct and incorrect readings per imaging study when considering the correct diagnosis among the top three radiologist-provided diagnoses (‘top-3 performance’). Green circles indicate correct diagnoses, and red circles incorrect diagnoses. Bold circles indicate diagnoses that changed using AI
Most initial differential diagnoses remained unchanged despite AI assistance. However, in 12/240 re-read studies, initially incorrect differential diagnoses were revised after interaction with GPT-4 and rendered correct (Fig. 3). Conversely, in 4/240 re-read studies (two radiographic, one MRI, and one angiographic study), initially correct differential diagnoses (unassisted) were rendered incorrect (AI-assisted) (Fig. 4).

Positive effects of AI consultation—example case. In this patient with intralobar pulmonary sequestration (CT, sagittal reconstruction, lung window), the consultation of GPT-4 changed the initially incorrect differential diagnosis to the correct differential diagnosis

Negative effects of AI consultation—example case. In this patient with focal nodular hyperplasia (MRI, T1-weighted fat-suppressed gradient echo-sequence [Dixon]), axial image, 20 min after injection of gadoxetic acid), the consultation of GPT-4 changed the list and order of differential diagnoses. While focal nodular hyperplasia was the first differential diagnosis without AI assistance, it was only the second diagnosis with AI assistance, most likely because of adherence to the response
Statistically significant predictors of diagnostic accuracy were the experience levels. Radiologists with low and moderate experience were significantly less likely to provide correct diagnoses than radiologists with advanced experience (p ≤ 0.017). For modality and AI assistance, the effects were less clear. For AI assistance, the coefficient was -0.18 (p = 0.428), indicating a slightly yet nonsignificantly decreased likelihood of a correct diagnosis without AI assistance. Supplementary Table 2 details the coefficients and p values of the principal predictors that influenced diagnostic accuracy.
‘Top-1 performance’: when considering only the first radiologist-provided diagnoses, diagnostic accuracy improved slightly from 154/240 (64.2%, unassisted) to 163/240 studies (67.9%, AI-assisted) read correctly. Once again, the most pronounced improvements were found among radiologists with less experience (Fig. 2), which aligns with our hypothesized benefit of AI assistance for those radiologists. Supplementary Tables 2 and 3 detail the counts of correct and incorrect diagnoses and associated predictors for the ‘top-1’ performance.
Prompt characteristics
Radiologists used GPT-4 in 77.5% of the studies, generating 309 prompts. Most prompts involved differential diagnoses (59.1% [n = 217]) and imaging features of specific conditions (27.5% [n = 101]). Less frequently, pathology- and anatomy-related information were requested (9.3% [n = 34] and 2.7% [n = 10]). Four prompts (1.3%) were related to gradings and classifications, and one prompt (0.3%) demanded general guidance (Fig. 5a). Prompts were evenly distributed among the modalities (Fig. 5b). Mainly, one prompt was used per patient (42.5% of prompts), while two (22.5%) or three prompts (10.0%) were used frequently, too (Fig. 5c). Fourty-two percentage of the prompts were provided by radiologists with limited experience, 34.3% by radiologists with moderate experience, and 23.6% by radiologists with advanced experience (Fig. 5d). Overall, the ample and variable interaction patterns of radiologists with GPT-4 reflect the expected natural engagement and confirm hypothesis (ii). Diagnostic confidence: radiologists were significantly more confident in their diagnoses when performing readings AI-assisted, regardless of the modality (p < 0.001) (Table 2). However, when considering experience levels, diagnostic confidence was significantly greater in radiologists of moderate experience only (versus advanced experience) (Supplementary Table 4).

Prompt quantities and characteristics. During the AI-assisted readings of the imaging studies, the six radiologists provided n = 309 prompts altogether. Detailed are the prompt numbers (a, b, d) and percentages (c) regarding the prompt type (a), the imaging modality (b), the number of prompts per imaging study (c), and the radiologist’s experience level (d). Because prompts could be assigned to different type categories, the prompt sums differed between a versus c and d
Hallucinations
Twenty-three responses of GPT-4 were classified as ‘hallucinations’ (7.4%), and two as ‘misinterpretations’ (0.6%), while no ‘clarifications’ were necessary. Hallucinations involved all modalities and various aspects of imaging findings and their interpretation. Often, the hallucinations involved incorrect information on conditions and their imaging and nonimaging findings, e.g., opacity versus lucency of bone lesions (radiography), features of aortic dissection (CT), signal intensities and enhancement features of liver lesions (MRI), and vascular anatomy (angiography). GPT-4 occasionally disregarded the information provided in the prompt. Hallucinations did not detrimentally affect the list of differential diagnoses provided. Table 3 details and comments on the hallucinations found. Supplementary Table 5 details the ‘misinterpretations’. Even though the responses were largely consistent with current medical knowledge, the noted instances of hallucinations partially refute hypothesis (iii).
User experience
GPT-4’s utility was rated as fair (2.8 ± 0.4), satisfaction and trust as good (4.0 ± 0.6, 3.6 ± 0.8), and ease of use as excellent (4.5 ± 0.5).
Discussion
Earlier studies investigating the potential value of GPT-4 in the clinic demonstrated excellent performance across various tasks and disciplines, particularly standardized medical examinations [6, 7, 16]. Recently, Kanjee et al used challenging clinicopathologic case conferences and found evidence of GPT-4’s ability to perform complex diagnostic reasoning [17]. These studies, however, relied on study settings not reflective of clinical reality, so little is known about GPT-4’s actual clinical value as an adjunct tool to the radiologist. Our study evaluated GPT-4’s utility for assisted image reading and interpretation and found modest improvements in diagnostic accuracy. Clinical experience was the preeminent factor determining diagnostic accuracy, while the modality and AI assistance had a more nuanced influence. AI assistance was beneficial by trend, yet its influence on diagnostic accuracy was statistically nonsignificant.
Our primary finding of improved diagnostic accuracy was valid for the ‘top-3 performance’. This finding is plausible given GPT-4’s broad, detailed knowledge of radiology. Notably, for radiography, we found a decline in diagnostic accuracy when radiographs were read with AI assistance. In modality-centered curricula (as in our hospital), radiography is the basic modality taught first. Our radiologists likely have broad radiographic knowledge, yet their performance was mixed. The adverse effects of AI interaction for radiography may be explained by overreliance and automation bias, which is the propensity to favor suggestions from automated systems. Sporadically, our radiologists cast wider nets of broader differentials under AI assistance instead of relying on their specific expertise. In contrast, greater improvements in CT, MRI, and angiography may be secondary to partially limited knowledge of these modalities, usually part of more advanced residency stages.
In several re-read imaging studies, the radiologists altered their interpretations. In 12 re-read studies, these conversions proved beneficial (i.e., incorrect to correct), while in 4 of 240 studies, the conversions were detrimental (i.e., correct to incorrect). For the former, differential diagnoses previously not mentioned were considered due to GPT-4’s response and involved primarily rare diagnoses with specific imaging features, such as pulmonary sequestration. For the latter, radiologists sporadically followed GPT-4’s guidance and agreed to the suggested and frequently generic differentials. This finding may be a potential sign of overreliance and automation bias. Regardless of their experience level, radiologists are prone to automation bias, and inexperienced radiologists are significantly more likely to follow the suggestions, even when blatantly false [18]. Undoubtedly, knowledgeable, skilled, and confident radiologists are key to mitigating these issues. AI may cover the width of potential diagnoses excellently, but it (still) requires trained radiologists to check consistency and reasoning.
Diagnostic accuracy dropped when defined more strictly as the ‘top-1 performance’. While the first diagnosis remained unchanged in most patients after interaction with GPT-4, we observed modality-specific effects on diagnostic accuracy that mirrored the ‘top-3 performance’ findings.
Our radiologists embraced AI assistance and used it in 78% of their readings. Prompt quantities indicate that our radiologists had conversational dialogues with GPT-4 when needed, as two or more prompts were used in a third of AI interactions. Prompts were primarily centered on possible differential diagnoses, which aligns well with a radiologist’s objective to keep rare differential diagnoses in mind when reading images. Prompting also focused on imaging features and information on pathology and anatomy. However, interactions with GPT-4 could not compensate for overlooked, ill-evaluated, and ill-described findings and provided valuable assistance only when specifically prompted. The complexity of describing specific findings can hardly be overcome for radiologists unfamiliar with a particular modality.
Diagnostic confidence was greater with AI assistance, yet this finding is only partially reflected by user experience ratings. While GPT-4’s ease of use was rated ‘excellent’, its utility was only ‘fair’, likely due to GPT-4’s inability to process images directly or provide an image search function for online repositories.
In line with previous reports [19], we found hallucinations that extended from disregarding diagnostically relevant information to providing false information. Undoubtedly, hallucinations are potentially harmful and even more so when considered against GPT-4’s purported trustworthiness, as our radiologists rated trust in GPT-4 as ‘good’. The clinical introduction of LLMs must be accompanied by appropriate safeguarding measures to ensure their accuracy and reliability and to prevent patient harm. Increasing user awareness, instituting quality checks by medical professionals, enhancing the LLM’s robustness against hallucinations, e.g., by process supervision instead of outcome supervision [20], and auditing adherence to regulatory standards may be parts of a strategy to counteract hallucinations effectively.
Our study has limitations. First, ten imaging studies were included per modality, which precludes clinical inference for particular modalities or pathologies and limits generalizability. Instead of assessing GPT-4’s value in every radiologic subdiscipline, we aimed to provide a preliminary and orientational evaluation across various preeminent imaging scenarios. Second, books or radiology-focused online references were prohibited per the study design to single out the effects of GPT-4. This restriction created a study setup unreflective of real-world radiologic practice. Future studies should compare established online resources, such as Radiopaedia and StatDx, with GPT-4 to determine their value in the reading room. Third, we did not institute a washout period between the reading sessions, which resulted in some studies being read on the same day and others more than 2 weeks apart. While performance metrics quantifying the impact of additional AI assistance on the benchmarked (unassisted) performance could be affected, we consider this approach acceptable nonetheless because (i) interpreting the studies unaided and then, if necessary, accessing assistance reflects the clinical practice and (ii) memory retention was likely high anyway given the select (and, in parts, memorable) patients and particular study conditions. Fourth, we refrained from assessing reporting times because our radiologists likely remembered the studies when re-reading them. Fifth, our evaluation used the May 2023 version of ChatGPT, which may only be partially reproduced by future versions, given the rapid evolution and undulating performance of different chatGPT versions [21]. Sixth, the GPT-4 utilization rates and patterns of general and subspecialty radiologists remain to be studied. Seventh, the LLM’s response is closely related to how it is prompted [22]. If and how the quality of GPT-4’s responses and the frequency of its hallucinations are affected by different prompting strategies must be studied in the future. Eighth, our sample size estimation must be, at best, considered a tentative approximation and should not be regarded as a precise measurement. Although the relatively small effect size of 0.2 was deliberate and informed by pertinent literature [14], it is important to acknowledge that the framework conditions in emerging research areas like AI-assisted diagnostics must be refined in the future. Ninth, streamlining the linear mixed-effect model improved the model’s interpretability, yet at the cost of reduced complexity. In prioritizing the reduction of variables to mitigate the risk of multicollinearity, we aimed to improve clarity and comprehensibility; yet, this approach may have oversimplified the complex interplay of factors affecting diagnostic accuracy and confidence.
Conclusion
In conclusion, our study suggests that GPT-4 is a clinically useful adjunct tool that improves diagnostic accuracy slightly and diagnostic confidence significantly, and may partially mitigate the experience gap in radiologists. GPT-4 may facilitate more efficient and accurate diagnostic processes, yet it cannot replace a trained radiologist’s nuanced perception and critical thinking. Should GPT-4 or its successors be used in the clinical routine, safeguarding measures must be implemented to reduce hallucinations and their potential harm.
Change history
19 April 2024
Source Line layout was corrected.
Abbreviations
- AI:
-
Artificial intelligence
- LLM:
-
Large language model
- PACS:
-
Picture Archiving and Communication System
References
Nav N (2023) 97+ ChatGPT Statistics & User Numbers in May 2023 (New Data). Available via https://nerdynav.com/chatgpt-statistics/. Accessed 25 May 2023
De Angelis L, Baglivo F, Arzilli G et al (2023) ChatGPT and the rise of large language models: the new AI-driven infodemic threat in public health. Front Public Health 11:1567
Elkassem AA, Smith AD (2023) Potential use cases for ChatGPT in radiology reporting. AJR Am J Roentgenol 221:373–376
Adams LC, Truhn D, Busch F et al (2023) Leveraging GPT-4 for post hoc transformation of free-text radiology reports into structured reporting: a multilingual feasibility study. Radiology 307:e230725
Rao A, Kim J, Kamineni M, Pang M, Lie W, Succi MD (2023) Evaluating ChatGPT as an adjunct for radiologic decision-making. medRxiv:2023.2002. 2002.23285399
Nori H, King N, McKinney SM, Carignan D, Horvitz E (2023) Capabilities of gpt-4 on medical challenge problems. arXiv preprint arXiv:230313375
Bhayana R, Krishna S, Bleakney RR (2023) Performance of ChatGPT on a radiology board-style examination: Insights into current strengths and limitations. Radiology 307:e230582
Bajaj S, Gandhi D, Nayar D (2023) Potential applications and impact of ChatGPT in radiology. Acad Radiol S1076-6332(23)00460-9. https://doi.org/10.1016/j.acra.2023.08.039
Akinci D’Antonoli T, Stanzione A, Bluethgen C et al (2023) Large language models in radiology: fundamentals, applications, ethical considerations, risks, and future directions. Diagn Interv Radiol 30:80–90
Bera K, O’Connor G, Jiang S, Tirumani SH, Ramaiya N (2023) Analysis of ChatGPT publications in radiology: literature so far. Curr Probl Diagn Radiol 53:215–225
Suthar PP, Kounsal A, Chhetri L, Saini D, Dua SG (2023) Artificial Intelligence (AI) in Radiology: A Deep Dive Into ChatGPT 4.0’s Accuracy with the American Journal of Neuroradiology’s (AJNR) “Case of the Month”. Cureus 15(8):e43958
Ueda D, Mitsuyama Y, Takita H et al (2023) Diagnostic Performance of ChatGPT from Patient History and Imaging Findings on the Diagnosis Please Quizzes. Radiology 308:e231040
Rau A, Rau S, Zoeller D et al (2023) A Context-based Chatbot Surpasses Trained Radiologists and Generic ChatGPT in Following the ACR Appropriateness Guidelines. Radiology 308:e230970
Finck T, Moosbauer J, Probst M et al (2022) Faster and Better: How Anomaly Detection Can Accelerate and Improve Reporting of Head Computed Tomography. Diagnostics 12:452
Faul F, Erdfelder E, Lang AG, Buchner A (2007) G*Power 3: a flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav Res Methods 39:175–191
Kung TH, Cheatham M, Medenilla A et al (2023) Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLoS Digital Health 2:e0000198
Kanjee Z, Crowe B, Rodman A (2023) Accuracy of a generative artificial intelligence model in a complex diagnostic challenge. JAMA 330:78–80
Dratsch T, Chen X, Rezazade Mehrizi M et al (2023) Automation bias in mammography: The impact of artificial intelligence BI-RADS suggestions on reader performance. Radiology 307:e222176
Lee P, Bubeck S, Petro J (2023) Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. N Engl J Med 388:1233–1239
Lightman H, Kosaraju V, Burda Y et al (2023) Let’s Verify Step by Step. arXiv:230520050 https://doi.org/10.48550/arXiv.2305.20050
Chen L, Zaharia M, Zou J (2023) How is ChatGPT’s behavior changing over time? arXiv:230709009 https://doi.org/10.48550/arXiv.2307.09009
White J, Fu Q, Hays S et al (2023) A prompt pattern catalog to enhance prompt engineering with chatgpt. arXiv:230211382 https://doi.org/10.48550/arXiv.2302.11382
Acknowledgements
Following the COPE (Committee on Publication Ethics) position statement of February 13th, 2023 (https://publicationethics.org/cope-position-statements/ai-author), the authors hereby disclose the use of the following artificial intelligence models during the writing of this article. GPT-4 (OpenAI) for checking spelling and grammar.
Funding
This study has received funding as follows: DT is supported by the European Union’s Horizon Europe programme (ODELIA, 101057091), by grants from the Deutsche Forschungsgemeinschaft (DFG) (TR 1700/7-1), and the German Federal Ministry of Education and Research (SWAG, 01KD2215A; TRANSFORM LIVER, 031L0312A). SN is funded by grants from the Deutsche Forschungsgemeinschaft (DFG) (NE 2136/3-1). Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Guarantor
The scientific guarantor of this publication is Sven Nebelung.
Conflict of interest
The authors of this manuscript declare no relationships with any companies, whose products or services may be related to the subject matter of the article.
Statistics and biometry
One of the authors has significant statistical expertise.
Informed consent
Only if the study is on human subjects: Written informed consent was waived by the Institutional Review Board.
Ethical approval
Institutional Review Board approval was obtained.
Study subjects or cohorts overlap
None of the study subjects or cohorts have been previously reported.
Methodology
-
Retrospective
-
Diagnostic or prognostic study
-
Performed at one institution
Additional information
Publisher’s Note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Siepmann, R., Huppertz, M., Rastkhiz, A. et al. The virtual reference radiologist: comprehensive AI assistance for clinical image reading and interpretation. Eur Radiol (2024). https://doi.org/10.1007/s00330-024-10727-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00330-024-10727-2