
Abstract
Objectives
To assess the performance of an artificial intelligence (AI) algorithm in the Australian mammography screening program which routinely uses two independent readers with arbitration of discordant results.
Methods
A total of 7533 prevalent round mammograms from 2017 were available for analysis. The AI program classified mammograms into deciles on the basis of breast cancer (BC) risk. BC diagnoses, including invasive BC (IBC) and ductal carcinoma in situ (DCIS), included those from the prevalent round, interval cancers, and cancers identified in the subsequent screening round two years later. Performance was assessed by sensitivity, specificity, positive and negative predictive values, and the proportion of women recalled by the radiologists and identified as higher risk by AI.
Results
Radiologists identified 54 women with IBC and 13 with DCIS with a recall rate of 9.7%. In contrast, 51 of 54 of the IBCs and 12/13 cases of DCIS were within the higher AI score group (score 10), a recall equivalent of 10.6% (a difference of 0.9% (CI −0.03 to 1.89%, p = 0.06). When IBCs were identified in the 2017 round, interval cancers classified as false negatives or with minimal signs in 2017, and cancers from the 2019 round were combined, the radiologists identified 54/67 and 59/67 were in the highest risk AI category (sensitivity 80.6% and 88.06 % respectively, a difference that was not different statistically).
Conclusions
As the performance of AI was comparable to that of expert radiologists, future AI roles in screening could include replacing one reader and supporting arbitration, reducing workload and false positive results.
Clinical relevance statement
AI analysis of consecutive prevalent screening mammograms from the Australian BreastScreen program demonstrated the algorithm’s ability to match the cancer detection of experienced radiologists, additionally identifying five interval cancers (false negatives), and the majority of the false positive recalls.
Key Points
• The AI program was almost as sensitive as the radiologists in terms of identifying prevalent lesions (51/54 for invasive breast cancer, 63/67 when including ductal carcinoma in situ).
• If selected interval cancers and cancers identified in the subsequent screening round were included, the AI program identified more cancers than the radiologists (59/67 compared with 54/67, sensitivity 88.06 % and 80.6% respectively p = 0.24).
• The high negative predictive value of a score of 1–9 would indicate a role for AI as a triage tool to reduce the recall rate (specifically false positives).
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Desirable innovations in mammographic screening include reducing false positive recalls while maintaining sensitivity, as well as minimising interval cancers. An innovation involving AI could have the added advantage of reducing workload for radiologists, who are in short supply [1, 2].
Evaluation of AI in screening mammography is fraught for a number of reasons. A recent systematic review [3] indicated that only 5 of 36 AI systems performed better than a single radiologist reader, and that none exceeded the performance of a dual reader system with arbitration. However, few studies have data on interval cancers following the index screening round or data on cancers detected at the subsequent screening round. Assessment of AI has also frequently occurred in a “research environment” using highly enriched data sets as opposed to in a “work as usual” environment using an unselected population where the prevalence of true positives is typically < 1.2% [4].
The aims of our study were to investigate the performance of an established AI product in women undergoing their prevalent full-field digital screening mammogram during one calendar year at one BreastScreen Australia (BSA) service, including lesions identified during the prevalent screen, interval cancers, and next round (verified 3-year follow-up). The sensitivity of the BSA program for prevalent round cases is 85% (age-adjusted) [5]. The potential impact of the incorporation of AI into practice was also investigated.
Materials and methods
This was a retrospective analysis of consecutive prevalent round screening mammograms conducted in 2017 from the Monash BreastScreen service in the state of Victoria.
Participants
The BSA program is a national population-based program, commenced in 1991, that sets, and annually reviews, performance standards for individual screening services and is responsible for the oversight of service audits every 4 years. Women in the target age group (50–74 years), identified from the electoral roll, are routinely invited for a screening mammogram every two years. Although women aged 40–49 years are not invited, they are eligible for screening. For prevalent screens, BSA has a performance benchmark for recall in the target age group of less than 10% [6].
The study participants were women attending for their prevalent mammogram through Monash BreastScreen, a BSA-accredited service in metropolitan Melbourne, screening up to 60,000 women annually. The service operates through eight separate screening clinics and the images are transmitted to a central facility where they are read by members of a team of 16 radiologists. Monash BreastScreen serves a major city and inner regional population. As false positive screens are recognised as a bigger issue for prevalent than incident screening rounds [5], this study focussed on first-round attendances.
Standard practice
All two-view digital screening mammograms are read independently by two breast specialist radiologists (readers) and each decides to either clear or recall the case. If recalled, the radiologist scores the case as 3 (equivocal), 4 (suspicious), or 5 (malignant) [7]. Discordant results between the two readers are arbitrated by a third highly-experienced reader. Women with a score of ≥ 3 after arbitration are recalled to a single assessment clinic and those cleared return to routine screening.
Pathology specimens from the assessment clinic are analysed by Monash Health expert breast pathologists (National Association of Testing Authorities accredited). These results are correlated with imaging at a weekly clinical multi-disciplinary meeting. The final histopathology outcomes from subsequent breast surgery are entered into the BreastScreen Victoria (BSV) database.
One of the key measures of the performance of a screening program is false negatives. In the case of screening mammography, women who are identified with interval cancers prior to the next screening round or who are diagnosed with cancer in the next screening round are worth assessing as potential false negative cases from the index screening round. Not all such cases will be false negatives as some cancers develop de novo and have had no signs present during the index round, so in order to assess the issue of false negatives, all such cases need careful review. In our study, interval cancers were defined as invasive BCs detected in the 24 months after a negative screening episode [4]. These cancers are detected outside the screening program and reported to the Victorian Cancer Registry (VCR) under legislative guidelines. The VCR collates and subsequently reports these data back to BreastScreen Victoria [4]. All women with a 2017 prevalent screen who were diagnosed with IBC at their first incident round 2 years later were also reviewed.
For the purposes of this study, all data for the interval cancers and cancers diagnosed in the subsequent round were reviewed with the relevant histopathology data provided by BSV.
Consensus review was undertaken by three experienced radiologists (J.E., J.W., and A.L.) who had a combined experience of over 60 years with arbitration and interval cancer review, on full-definition workstations in a two-stage manner as described in other studies [8]. An initial review was done blinded to both the Transpara score and computer-aided detection (CAD) markings. Once consensus had been reached in relation to any abnormalities on the 2017 images, a second review was undertaken with the AI data included to confirm that the expert panel and the AI program were identifying the same mammographic feature. On the basis of this review, there were no mammographic signs present in the 2017 round, they were called true negatives (true intervals), if there were recognisable signs of a relevant abnormality in 2017 they were called false negatives and if there were subtle signs present in 2017, the cases were classified as having “minimal signs.”
“Ground truth” data set
This data set is considered to be “ground truth” as it includes all prevalent screening outcome data as well as verified 3-year follow-up. Women identified with IBC outside of the BreastScreen program after a minimum of 24 months from the time of their 2017 scan were classified as “lapsed attenders” and not included with those women diagnosed in 2019.
AI product
Digital mammograms were obtained using Siemens DR, Mammomat and Inspiration, Sectra DR, and Hologic Dimensions units. The AI software used was Transpara (version 1.7.0), a commercially available product that obtained international regulatory approval in 2018 (US Food and Drug Administration, European Co-operation on Accreditation standard and the Australian Therapeutic Goods Administration). ScreenPoint Medical BV provided the Transpara AI software, which was integrated into the BSV service Sectra IDS7 PACS Platform. Transpara 1.7.0 has been trained on over 1 million mammograms from established test sets. The mammograms used in this study were not used in any part of the algorithm training. The software analyses image information only with no input of patient demographics such as age or BC risk factors, nor does the current version have the capacity to compare studies with prior exams. Image analysis uses deep learning convolutional neural networks to detect calcifications [9] and soft tissue lesions [10] and provides an overall score ranging between 1 and 10, representing the BC risk (where 10 represents the highest chance of malignancy) [11]. The scores of 1–10 represent deciles so that ~10% of women are assigned a score in each of the 10 categories. The current analysis is based solely on the overall score of 1–10 and is not a lesion-specific analysis.
Ethics approval
Ethics approval for this project was gained by Monash Health Human Research Ethics Committee Low Risk Panel Monash Health (Monash Health Ref: RES-20-0000-166L-61177). All women who are screened through BreastScreen sign a form giving permission for their anonymised test results to be used for research purposes.
Data analysis
The performance of the radiologists and the AI system was assessed in terms of all lesions (IBC and DCIS) identified in 2017, IBCs identified in 2017, interval BCs (false negatives and minimal signs, not true negatives) and IBCs identified in the subsequent screening round (minimal signs but not true negatives). Data are presented as frequencies and percentages.
The parameters reported include sensitivity, specificity, and positive and negative predictive values, including percentages with confidence intervals. Proportions were compared using the chi-squared test or Fisher’s exact test and the associated p values provided.
This study was exploratory in nature and the size of the sample used was pragmatic and determined by the feasibility of having the AI program provide scores for prevalent screens in a single calendar year and for follow-up data to be available for both interval cancers and cancers identified in the subsequent screening round.
Results
Participants
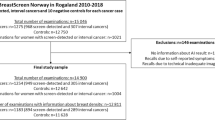
In 2017, 53,584 women attended Monash BreastScreen and a subset of 7829 mammograms were prevalent screens. Women having their prevalent screen ranged in age from 40 and 85+ years. The proportion in the target age group 50–74 years was 68.4%.
Of the 7829 prevalent screens, 296 were unable to be given a Transpara score for a range of technical reasons, so 7533 (96.2%) women were included in this analysis (Fig. 1). There were 2 cases of DCIS and one case of IBC as well as two interval IBCs within the group of women who did not have a Transpara score.

Flow chart showing the number of women with prevalent screens, with Transpara scores available, recalled for further evaluation and diagnosed in the prevalent round
A total of 728 women from the 7533 (9.66%) were recalled for further assessment with 54 diagnosed with IBC and 13 with DCIS on the basis of mammographic abnormalities. Three women within the recalled group whose cancers were not the recalled abnormality and were diagnosed using ultrasound have been excluded from the analysis as their cancers were mammographically occult (Fig. 1).
A total of 798 women (798/7533 10.6%) received a Transpara score of 10.
Of the 728 women recalled by the radiologists, 36.4% had a score of 10 (Table 1). The overlap between the group of women recalled by the radiologists and the women with a score of 10, along with the lesions diagnosed in 2017, is shown in Fig. 2. There were 265 women who were both recalled and had a score of 10.

Women recalled to the clinic, women with a Transpara score of 10, and women in both of these groups
Sixty-three of the 67 lesions diagnosed at the 2017 screening (51 IBCs and 12 DCIS) round were within the 265 women who were both recalled by the radiologists and scored a 10. The other 4 lesions (3 IBC and 1 DCIS) were within the group recalled by the radiologists but did not score a 10 (Table 2 and Fig. 3). This represents a sensitivity of 63/67 (94%) for a score of 10. Two of the four cases not classified as high risk by AI are shown in Fig. 4.

The distribution of women diagnosed with IBC, DCIS, or identified as false positives in the prevalent round of screening (by percentage)

Examples of cancers missed by the AI system. A A 15-mm-large invasive ductal cancer (grade 2) with a soft density appearance (arrows) in both views lacks distinct margins. AI risk score of 5/10 and detected by one of two radiologists. MLO, mediolateral oblique view; CC, craniocaudal view, and ultrasound detail. B A 29-mm-large invasive ductal cancer (grade 3) (US1) is masked within the dense asymmetric fibroglandular tissue in the right upper outer quadrant (circle) with significant axillary lymphadenopathy (arrow and US 2). Both radiologists recalled this case—AI algorithm fails to recognise the context of the lymph node and provides low-risk score of 7. MLO, mediolateral oblique view; CC, craniocaudal view and US, ultrasound details
From this 2017 cohort, there were 12 interval IBCs diagnosed and 16 IBCs diagnosed in the incident round of 2019. There were no cases of interval DCIS or DCIS in 2019 in women cleared by the radiologists in 2017. A further three women were identified with IBC outside of the BS program, after 24 months, and were classified as “lapsed attenders.” One of these three women had a score of 9 on her 2017 screen.
Of the 12 interval cancers, 5 were considered false negatives, and all 5 of these intervals scored a 10 in 2017 (images from 2 of the 5 are shown in Fig. 5). Four of the 12 intervals were classified as “minimal signs” in 2017 and of these, 2 scored a 10 and 2 scored 1–9 (Table 3). Four of the 16 IBCs diagnosed in 2019 were considered to have had minimal signs in 2017 and one of these four scored a 10 in 2017.

Examples of false negative interval cancers detected by AI. A Author’s arrow left CC detail image of a 10-mm-large soft tissue mass in a postero-medial location (red circle CAD marking)—in one view only, scored 10/10 by AI. Adjacent microcalcifications (white diamond CAD markings) attributed a high score also. Clinical presentation 11 months later with a 25 mm invasive ductal cancer (grade 2) on histopathology. CC, craniocaudal view. B In the upper left MLO the red circle CAD marking—in one view only—identifies the findings of an asymmetric density with associated architectural distortion of the adjacent glandular tissue (author’s arrows), scored 10/10 by AI. Clinical presentation 7 months later with a 70 mm invasive lobular cancer (grade 2) on histopathology. MLO, mediolateral oblique view CC, craniocaudal view
The performance of the radiologists and the AI program in relation to 2017 diagnoses, interval cancers (excluding true negatives), and 2019 cancers (excluding those with no signs in 2017) is shown in Table 4. The AI program missed 4 lesions detected by the radiologists in 2017 but the AI program identified as high risk some IBCs that later presented as either interval cancers or IBCs in the 2019 screening round. Despite this, across all the comparisons (IBC and DCIS in 2017; IBC only in 2017; IBC in 2017 + interval false negatives + interval minimal signs; IBC in 2017+ interval false negatives + interval minimal signs + 2019 minimal signs) the differences in the performance of the radiologists and the AI program in terms of sensitivity, specificity, positive and negative predictive value were small, or had wide confidence intervals. The details of the invasive cancers detected by the radiologists and/or scored 10 by AI in the 2017 prevalent round are provided in Table 5.
Discussion
Our study is an independent (not industry-led) assessment of the performance of an established AI program in the prevalent round of screening in a “work as usual” accredited screening mammography program where the likelihood of a true positive lesion is up to 1.2% [4], and where data on interval cancers and next round cancers were available (ground truth) [12]. Our focus on a prevalent screening round was deliberate as recall rates are consistently higher in prevalent than incident rounds [5] and the high negative predictive value for AI demonstrated in this study has the potential to reduce unnecessary recalls (false positives) in this group (Table 2 and Fig. 3).
A Transpara score of 10 identified 63/67 cases of IBC or DCIS in the 2017 screening round, however, a Transpara score of 10 did identify some interval IBCs and IBCs identified in the subsequent screening round, although the difference in the sensitivity between the AI score and the radiologists was not different statistically. A large review of interval cancers [13] noted the problem of small invasive tumours “masked” by dense fibroglandular tissue or with “minimal signs.” Typically, 20–25% of intervals were classified as false negatives, where observable mammographic features were missed by radiologists. In our study, 5/12 intervals were considered as false negatives at “blinded” expert review, and all scored 10 (highest risk) by Transpara and marked by the AI algorithm (images 5A and 5B). Our study confirms the role of AI in the minimisation of “false negatives” [14, 15]. It was notable that two of the four women who were missed by AI in the prevalent round had signs that were not missed by a radiologist [16], demonstrating the need for all images to be read by at least one radiologist [12]. We consider that commencing the task of integrating AI into screening mammography and upskilling radiologists to work in this setting is better started from a position supporting “human in the loop” collaboration [17]. Unlike some recent authors, we would not advocate for a scheme where some images are only analysed by AI and not read by a radiologist [14, 16, 18]. We envisage a system similar to that of McKinney [15] and Raya-Povedano [19]. An iterative review of reader performance will be required to avoid increasing the recall rate from the “cancer-enriched” groups [1]. A review of AI errors is also important [12]. Radiologists also need to understand the psychology of how AI affects their reporting [12, 18, 20]. Senior clinician oversight will be pivotal as protocols evolve which must achieve acceptable clinical standards both for organisations responsible for the governance of breast screening, as well as for the women being screened [12, 20,21,22]. The incorporation of AI into the reading of screening mammograms has been shown to reduce radiologist workload in some settings [23] although this is not universally the case [22]. Resources saved by no longer having all images read by two independent radiologists could be invested in optimising case review and arbitration.
A strength of this study is that the mammograms analysed represent a consecutive series in one calendar year from one screening service and the outcomes include IBCs and DCIS diagnosed in the prevalent round, as well as 3-year follow-up. Limitations included that a small proportion of mammograms could not be scored by the AI program for technical reasons and this would need to be addressed if AI was to be introduced into routine practice. Furthermore, the study was limited to prevalent round screens from a single calendar year.
Conclusion
Our study has shown that the AI program used in our study has a similar sensitivity to that of expert radiologists in the prevalent round, could reduce interval cancers (false negatives), and has a high negative predictive value for scores 1–9 demonstrating its potential role in false positive reduction.
Abbreviations
- AI:
-
Artificial intelligence
- BC:
-
Breast cancer
- BSA:
-
BreastScreen Australia
- BSV:
-
BreastScreen Victoria
- DCIS:
-
Ductal carcinoma in situ
- DR:
-
Digital radiography
- IBC:
-
Invasive breast cancer
- PACS:
-
Picture archival and communications system
- VCR:
-
Victorian Cancer Registry
References
Wallis MG (2021) Artificial intelligence for the real world of breast screening. Eur J Radiol 144:109661
Hickman SE, Woitek R, Le EPV et al (2022) Machine learning for workflow applications in screening mammography: systematic review and meta-analysis. Radiology 302:88–104
Freeman K, Geppert J, Stinton C et al (2021) Use of artificial intelligence for image analysis in breast cancer screening programmes: systematic review of test accuracy. BMJ 374:n1872
Australian Institute of Health and Welfare (2021) BreastScreen Australia Monitoring Report 2021. https://www.aihw.gov.au/reports/cancer-screening/breastscreen-australia-monitoring-report-2021
Australian Institute of Health and Welfare (2022) BreastScreen Australia Monitoring Report 2022. https://www.aihw.gov.au/reports/cancer-screening/breastscreen-australia-monitoring-report-2022
Commonwealth of Australia (2021) BreastScreen Australia National Accreditation Handbook. https://www.health.gov.au/sites/default/files/documents/2021/03/breastscreen-australia-national-accreditation-handbook
Tabar L, Dean PB (1983) Teaching atlas of mammography. Fortschr Geb Rontgenstrahlen Nuklearmed Erganzungsbd 116:1–222
Lang K, Solveig H, Rodriguez-Ruiz A, Andersson I (2021) Can artificial intelligence reduce the interval cancer rate in mammographic screening? Eur Radiol 31:5940–5947
Bria A, Karssemeijer N, Tortorella F (2014) Learning from unbalanced data: a cascade-based approach for detecting clustered microcalcifications. Med Image Anal 18:241–252
Hupse R, Karssemeijer N (2009) Use of normal tissue context in computer-aided detection of masses in mammograms. IEEE Trans Med Imaging 28:2033–2041
Rodriguez-Ruiz A, Krupinski E, Mordang JJ, Schilling K, Heywang-Kobrunner SH, Sechopoulos I et al (2019) Detection of breast cancer with mammography: effect of an artificial intelligence support system. Radiology 290:305–314
Hickman SE, Baxter GC, Gilbert FJ (2021) Adoption of artificial intelligence in breast imaging: evaluation, ethical constraints and limitations. Br J Cancer 125:15–22
Houssami N, Hunter K (2017) The epidemiology, radiology and biological characteristics of interval breast cancers in population mammography screening. NPJ Breast Cancer 3:12
Dembrower K, Wahlin E, Liu Y, Salim M, Smith K, Lindholm P et al (2020) Effect of artificial intelligence-based triaging of breast cancer screening mammograms on cancer detection and radiologist workload: a retrospective simulation study. Lancet Digit Health 2:e468–e474
McKinney SM, Sieniek M, Godbole V, Godwin J, Antropova N, Ashrafian H et al (2020) International evaluation of an AI system for breast cancer screening. Nature 577:89–94
Kerschke L, Weigel S, Rodriguez-Ruiz A, Karssemeijer N, Heindel W (2022) Using deep learning to assist readers during the arbitration process: a lesion-based retrospective evaluation of breast cancer screening performance. Eur Radiol 32:842–852
Mendelson EB (2019) Artificial intelligence in breast imaging: potentials and limitations. AJR Am J Roentgenol 212:293–299
Leibig C, Brehmer M, Bunk S, Byng D, Pinker K, Umutlu L (2022) Combining the strengths of radiologists and AI for breast cancer screening: a retrospective analysis. Lancet Digit Health 4:e507–e519
Raya-Povedano JL, Romero-Martin S, Elias-Cabot E, Gubern-Merida A, Rodriguez-Ruiz A, Alvarez-Benito M (2021) AI-based strategies to reduce workload in breast cancer screening with mammography and tomosynthesis: a retrospective evaluation. Radiology 300:57–65
Aristidou A, Jena R, Topol EJ (2022) Bridging the chasm between AI and clinical implementation. Lancet 399:620
Lamb LR, Lehman CD, Gastounioti A, Conant EF, Bahl M (2022) Artificial intelligence (AI) for screening mammography, from the AJR special series on AI applications. AJR Am J Roentgenol 219:369–380
European Society of R (2022) Current practical experience with artificial intelligence in clinical radiology: a survey of the European Society of Radiology. Insights Imaging 13:107
Rodriguez-Ruiz A, Lang K, Gubern-Merida A, Teuwen J, Broeders M, Gennaro G et al (2019) Can we reduce the workload of mammographic screening by automatic identification of normal exams with artificial intelligence? A feasibility study. Eur Radiol 29:4825–4832
Acknowledgements
We gratefully acknowledge technical support from ScreenPoint Medical, BreastScreen Victoria IT division, Volpara Health, and Sectra Australia. We also acknowledge the work of our data team at Monash BreastScreen.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions. This study has received funding from Monash Health Department of Surgery and the BreastScreen Australia Quality Program. The study was supported in kind by ScreenPoint Medical BV by providing the Transpara AI software.
Author information
Authors and Affiliations
Contributions
Concept and design of the study JW, JE, and RJB, reading of the mammograms JW, JE, MM, DL, PA, and AL, data collection and analysis JW and RJB, writing of the manuscript JW and RJB, revision of the manuscript by all authors.
Corresponding author
Ethics declarations
Guarantor
The scientific guarantor of this publication is Prof Robin Bell.
Conflict of interest
The authors of this manuscript declare no relationships with any companies, whose products or services may be related to the subject matter of the article.
Statistics and biometry
One of the authors (RJB) has significant statistical expertise.
Informed consent
Written informed consent was not required for this study because all women who are screened through BreastScreen sign a form giving permission for their test results to be used for research purposes.
Ethical approval
Institutional Review Board approval was obtained (Monash Health Human Research Ethics Committee Low Risk Panel Monash Health (Monash Health Ref: RES-20-0000-166L-61177)).
Study subjects or cohorts overlap
No AI data on the study subjects have been previously reported.
Methodology
• retrospective
• observational
• performed at one institution
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Waugh, J., Evans, J., Miocevic, M. et al. Performance of artificial intelligence in 7533 consecutive prevalent screening mammograms from the BreastScreen Australia program. Eur Radiol 34, 3947–3957 (2024). https://doi.org/10.1007/s00330-023-10396-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00330-023-10396-7