
Abstract
Given a set of species whose evolution is represented by a species tree, a gene family is a group of genes having evolved from a single ancestral gene. A gene family evolves along the branches of a species tree through various mechanisms, including—but not limited to—speciation (\({\mathbb {S}}\)), gene duplication (\({\mathbb {D}}\)), gene loss (\({\mathbb {L}}\)), and horizontal gene transfer (\({\mathbb {T}}\)). The reconstruction of a gene tree representing the evolution of a gene family constrained by a species tree is an important problem in phylogenomics. However, unlike in the multispecies coalescent evolutionary model that considers only speciation and incomplete lineage sorting events, very little is known about the search space for gene family histories accounting for gene duplication, gene loss and horizontal gene transfer (the \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model). In this work, we introduce the notion of evolutionary histories defined as a binary ordered rooted tree describing the evolution of a gene family, constrained by a species tree in the \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model. We provide formal grammars describing the set of all evolutionary histories that are compatible with a given species tree, whether it is ranked or unranked. These grammars allow us, using either analytic combinatorics or dynamic programming, to efficiently compute the number of histories of a given size, and also to generate random histories of a given size under the uniform distribution. We apply these tools to obtain exact asymptotics for the number of gene family histories for two species trees, the rooted caterpillar and complete binary tree, as well as estimates of the range of the exponential growth factor of the number of histories for random species trees of size up to 25. Our results show that including horizontal gene transfers induce a dramatic increase of the number of evolutionary histories. We also show that, within ranked species trees, the number of evolutionary histories in the \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model is almost independent of the species tree topology. These results establish firm foundations for the development of ensemble methods for the prediction of reconciliations.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
A gene tree represents the evolution of a gene family, a group of genes assumed to descend from a single ancestral gene. The reconstruction of gene trees from molecular sequence data is a central but difficult problem in computational biology. Indeed, while species are mostly expected to evolve through speciation, gene families evolve through a wider variety of mechanisms including gene duplication, gene loss, horizontal gene transfer (HGT) and incomplete lineage sorting (ILS). As a result, it is common to observe an incongruence between gene trees and species trees (Maddison 1997; Degnan and Rosenberg 2006; Degnan et al. 2012; Disanto and Rosenberg 2014; Disanto et al. 2019). This discrepancy has motivated an intense research activity on the problem of reconstructing the gene tree of a gene family, conditional to a given species tree for the considered species. We refer to Szöllősi and Daubin (2012), Szöllősi et al. (2015) for extensive reviews discussing how gene trees evolve within a species tree, describe existing models and methods for reconstructing gene trees within species trees.
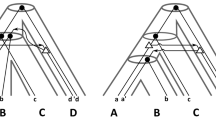
In the case where a gene family contains a single gene per species, observed incongruences between a gene tree and a species tree can be analyzed through the prism of ILS in the multispecies coalescent model (see Degnan and Rosenberg 2009 and references there). The natural question is then to compute the probability of coalescent histories conditional to the given species tree (Degnan and Salter 2005; Wu 2012, 2016; Pei and Wu 2017). For gene families that might contain duplicate copies (or no copy) of a gene in a given species, the multispecies coalescent model is not appropriate, and gene trees need to be inferred in a model including gene duplication, gene loss and, ideally, transfers. Most methods developed to understand the evolution of gene families in this context rely on the concept of gene tree-species tree reconciliation, illustrated in Fig. 1. In this framework, given a gene tree G and a species tree S, one aims to embed G within S, often optimizing a parsimony or probabilistic criterion with regard to the considered evolutionary model.

Left: a species tree \({\mathbf {S}}\). Center: a \({\mathbb {D}}{\mathbb {L}}\)-history for \({\mathbf {S}}\). Right: the associated gene tree. Green squares (resp. blue circles, red diamonds, black rectangles) correspond to nodes x such that \(e(x)={\mathbb {D}}\) (resp. \(e(x)={\mathbb {S}},e(x)={\mathbb {L}},e(x)=Extant\)). The mapping s is represented by the location of the internal nodes of the history within the species tree in the center tree and by the species names in the nodes in the right tree (color figure online)
Early reconciliation methods were developed for an evolutionary model considering only gene duplications and gene losses (the \({\mathbb {D}}{\mathbb {L}}\)-model), and considered a parsimony criterion. This problem, introduced by Goodman et al. (1979), is computationally tractable through dynamic programming. Extending the model to include HGT, while ensuring that HGT events are time-consistent, makes the problem of predicting of the most parsimonious reconciliation intractable in general (Ovadia et al. 2011; Tofigh et al. 2011). However, if the provided species tree is ranked, i.e. is provided with a total ordering of its internal nodes—consistent with the partial ordering induced by the tree structure—describing the order of speciation events, the reconciliation problem becomes tractable [see the discussion in Doyon et al. (2011)]. Over the last 20 years, various efficient dynamic programming algorithms were designed to compute a parsimonious reconciliation, implemented in widely used phylogenomics packages (Durand et al. 2006; Bansal et al. 2018; Scornavacca et al. 2015; Jacox et al. 2016). Similar to parsimony-based methods, probabilistic reconciliation methods were first developed in a model considering only gene duplication and gene loss (Arvestad et al. 2009; Åkerborg et al. 2009; Górecki et al. 2011; Górecki and Eulenstein 2014), before being extended to include HGTs (Szöllősi et al. 2013a; Sjöstrand et al. 2014).
Most methods that reconstruct a gene tree conditional to a species tree, rely on the exploration of the space of possible evolutionary histories. It is then important to develop conceptual tools that can describe this combinatorial space and further enable its efficient exploration. This naturally raises the questions to compute the size of the space of evolutionary histories for a given gene family and a given species tree, and to be able to sample such histories. Both questions are naturally related, as precise counting results often translate into efficient sampling algorithms (Wilf 1977; Flajolet et al. 1994). The former (counting) question has been studied by Rosenberg et al. in the case of the multispecies coalescent model (Degnan and Salter 2005; Rosenberg 2007, 2019; Wu 2012, 2016; Disanto and Rosenberg 2015, 2016, 2017a, 2019a, b; Disanto and Munarini 2019). However similar questions have not been explored as thoroughly for evolutionary models including gene duplication, gene loss and HGT. In this framework, dynamic programming equations aimed at computing a parsimonious reconciled gene tree can be turned into a specification of the corresponding search space (Górecki and Tiuryn 2006; Ranwez et al. 2016). This then leads to efficient algorithms for counting or sampling parsimonious reconciliations (Doyon et al. 2009; Bansal et al. 2013) or sampling reconciled gene trees under the Boltzmann probability distribution (Jacox et al. 2016). However, to the best of our knowledge, such questions have not been considered in the case where a gene tree is not specified at first, i.e. we are only given a species tree and gene family.
This paper provides analytic and algorithmic answers to those questions. We show that, for a given species tree, whether ranked or unranked, the space of all possible evolutionary histories of a fixed size in the \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model can be described using a formal grammar, an approach already used for ranked evolutionary trees (Gavryushkin et al. 2018). This allows us to compute, in polynomial time and space, for given species tree and gene family size, the number of evolutionary histories of this size conditional to the given species tree, as well as to sample among these histories under the uniform probability distribution. Using these algorithms, we can provide estimates of the exponential growth factor of the number of histories in the \({\mathbb {D}}{\mathbb {L}}\)-model and \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model. We show that, as expected, including HGT in a model results in an exponential increase of the number of histories. We also notice that with a ranked species tree, the exponential growth factor of the number of histories in the \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model seems to be almost independent of the chosen species tree. Finally, using enumerative and analytic combinatorics, we provide exact values for the asymptotic number of histories for two specific species tree: the rooted caterpillar tree and the rooted complete binary tree.
2 Model: gene families evolutionary histories
In this section, we introduce the combinatorial objects modeling the evolution of a gene family within a given species tree, that we call histories.
Preliminaries on trees. For a given rooted treeFootnote 1\({\mathbf {T}}\), we say it is uniquely labeled if every node has a label, and the set of labels is totally ordered. For a node x in \({\mathbf {T}}\), we denote by \({\mathbf {T}}_x\) the subtree of \({\mathbf {T}}\) rooted at x. In this work, we consider only binary and unary-binary trees: in a binary tree, every internal node has exactly two children, while in a unary-binary tree, an internal node can have either one child or two children. If a uniquely labeled tree \({\mathbf {T}}\) is unordered we take advantage of the nodes labeling to see it as an ordered tree, with the two children of an internal node x being ordered from left to right in increasing order of their labels; so from now on all trees we consider are ordered. If an internal node x of a tree \({\mathbf {T}}\) is binary, we denote by \(x_\ell \) the left child of x and by \(x_r\) its right child; if x is unary, i.e. has a single child, we denote it by \(x_c\). We denote by \(r({\mathbf {T}})\) the root of \({\mathbf {T}}\). For a node x of \({\mathbf {T}}\), we denote by p(x) its parent in \({\mathbf {T}}\). The size of a tree \({\mathbf {T}}\) is the number of its leaves.
A rooted tree describes a partial order on the set of its nodes, and two nodes are said to be comparable if one is an ancestor of the other one and incomparable otherwise. For a node u, we denote by \({\overline{C}}(u)\) the set of nodes that are incomparable with u.
Ranked trees. A ranking of a tree T of size n is a mapping \(\pi \) from the nodes of T to \(\{1,\dots ,n\}\) such that (1) \(\pi (x)=n\) if x is a leaf, (2) \(\pi (x)\ne \pi (y)\) if x and y are internal nodes, and (3) \(\pi (x) < \pi (y)\) if x is an ancestor of y. A tree augmented with a ranking is called a ranked tree; in our context it models the evolution of a set of species, the ranking providing the relative order of speciation events, under the assumption that no two speciations can occur at the same time.
Given a binary tree \({\mathbf {T}}\) and a ranking \(\pi \), we define an unranked unary-binary tree \({\mathbf {T}}^\pi \) that encodes the ranking information as follows: for each internal node u, considered iteratively in increasing ranking order, and for every edge (p(v), v) such that \(\pi (p(v))<\pi (u)<\pi (v)\), we subdivide the edge (p(v), v) into two edges \((p(v),v_u)\) and \((v_u,v)\), so adding a unary node \(v_u\) on this edge. We denote by t(u) the set of all unary nodes created in this way and we call this set of nodes together with u a time slice. Additionally, we also define the set of all leaves as a time slice (see Fig. 2). Note that in this way we create n different time slices which correspond to the n different values of the ranking. We modify the notion of incomparability for such unary-binary trees as follows: for a node u, \({\overline{C}}(u)=t(u){\setminus } \{u\}\).

An example of a ranked tree with time slices. Left: the complete binary tree \({\mathbf {T}}\) of size 4. Center: the unary-binary tree \({\mathbf {T}}^\pi \) for the ranking \(\pi \) defined by \(\pi (\mathsf{A})=1\), \(\pi (\mathsf{B})=2\), \(\pi (\mathsf{C})=3\) and \(\pi (\mathsf{D})=\pi (\mathsf{E})=\pi (\mathsf{F})=\pi (\mathsf{G})=4\); the time slices in \({\mathbf {T}}^\pi \) are the following sets of nodes: \(\{\mathsf{A}\}\), \(\{\mathsf{B},\mathsf{C}'\}\), \(\{\mathsf{C},\mathsf{D}',\mathsf{E}'\}\),\(\{\mathsf{D},\mathsf{E},\mathsf{F},\mathsf{G}\}\); Right: alternative unary-binary tree \({\mathbf {T}}^{\pi '}\), induced by exchanging the rankings of B and C
Gene Families Evolutionary Histories. The objects we study in this work model the evolution of a gene family within a species tree. A species tree, which will be denoted by \({\mathbf {S}}\) from now on, is a uniquely labeled rooted binary tree that represents the evolution of a set of species through speciation events; \({\mathbf {S}}\) can be either unranked or ranked. A gene family evolves within \({\mathbf {S}}\) from a single ancestral gene, present in the species \(r({\mathbf {S}})\), through four possible kinds of evolutionary events:
Speciation\({\mathbb {S}}\): a gene x present in species u splits into two descendant genes \(x_\ell \) present in species \(u_\ell \) and \(x_r\) present in species \(u_r\).
Duplication\({\mathbb {D}}\): a gene x present in species u is duplicated, with a new copy \(x_d\) of x appearing in species u; x is said to be the original gene while \(x_d\) is the novel gene.
Loss\({\mathbb {L}}\): a gene x present in species u has exactly one descendant either in \(x_\ell \) or in \(x_r\), that is, after a speciation at species u, exactly one of the two resulting genes is lost along the branch toward either \(u_\ell \) or \(u_r\).
Horizontal Gene Transfer \({\mathbb {T}}\) (HGT): this is similar to a duplication but the novel copy, denoted \(x_t\) here, appears in a species v different from u and incomparable with u, called the receiver of the HGT, while u is called the donor of the HGT. If \({\mathbf {S}}\) is ranked, with ranking \(\pi \), the receiver species v is required to exist at the same time as u, i.e. to satisfy two ranking constraints, \(\pi (p(v))<\pi (u)<\pi (v)\).
Definition 2.1
An evolutionary history for a gene family within a species tree \({\mathbf {S}}\) is a unary-binary ordered rooted tree \({\mathbf {T}}\) together with two mappings \(s:\ V({\mathbf {T}}) \rightarrow V({\mathbf {S}})\) and \(e:\ V({\mathbf {T}}) \rightarrow \{{\mathbb {S}}, {\mathbb {D}}, {\mathbb {L}}, {\mathbb {T}}, Extant\}\) satisfying the following constraints:
if x is a leaf, \(e(x) \in \{Extant,{\mathbb {L}}\}\);
if x is internal and binary, \(e(x) \in \{{\mathbb {S}}, {\mathbb {D}}, {\mathbb {T}}\}\);
if x is internal and unary then \(e(x)={\mathbb {S}}\)Footnote 2;
if \(e(x) = {\mathbb {S}}\) and \(s(x)=u\) is binary then \(s(x_\ell )=u_\ell \) and \(s(x_r)=u_r\);
if \(e(x) = {\mathbb {S}}\) and \(s(x)=u\) is unary then \(s(x_c)=u_c\);
if \(e(x) = {\mathbb {D}}\) then \(s(x_\ell )=s(x_r)=s(x)\);
if \(e(x) = {\mathbb {T}}\) then \(s(x_\ell )=s(x)\) and \(s(x_r) \in {\overline{C}}(s(x))\).
The size of a history is the number of leaves x such that \(e(x)=Extant\).
Intuitively, this definition states that a history is represented by a tree where each node corresponds to a gene present in a species, either extant or ancestral (the mapping s), and each ancestral gene either was lost (\(e(x)={\mathbb {L}}\)) or evolved toward extant genes through a duplication (\(e(x)={\mathbb {D}}\)), an HGT to an incomparable receiver species (\(e(x)={\mathbb {T}}\)) or a speciation (\(e(x)={\mathbb {S}}\)), while extant genes belong to extant species; the constraints on the species mapping s ensure that this history can be embedded within \({\mathbf {S}}\) as illustrated in Fig. 1.
By convention, for duplications, we consider that the novel copy of a gene x is its right child \(x_r\), \(x_\ell \) representing the original copy. Histories considered by the \({\mathbb {D}}{\mathbb {L}}\)-model, which allows both duplications and losses (resp. duplications, losses and HGTs), are called \({\mathbb {D}}{\mathbb {L}}\)-histories (resp. \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-histories).
Remark 2.2
By modeling the evolution of a gene family with ordered trees we differ from the classical notion of reconciliation, that also models the evolution of a gene family but considers that when a gene duplication occurs, the original gene and the novel gene are indistinguishable. As a result, the children of a duplication are ordered within a history, whereas they are not in a reconciliation.
Remark 2.3
Gene losses are modeled as speciation events with one disappearing gene. As a consequence, we can not have a duplication or a HGT that results in one of the resulting two gene copies being lost. This is necessary to avoid creating an infinite number of histories of a given size, due to an arbitrary number of duplications within a species, each followed by a loss, or an arbitrary long sequence of HGT, again each followed by a loss, leading to at most one extant gene.
Time Consistency of \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-histories. Given an unranked species tree \({\mathbf {S}}\), a \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-history as defined above is time inconsistent if there exists a gene x belonging to a species u such that one of its ancestors belongs to a species v and one of its descendants belongs to a species \(v'\) ancestral to v. This pattern can be observed due to the fact that, in the definition of a \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-history, the choice of the receiver species v of an HGT of gene x belonging to species u is not restricted to the set of species that are also incomparable with all species containing genes that are ancestral to x; see Fig. 3 for an illustration.

An example of time-inconsistent \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-history
The problem of computing gene family evolutionary scenarios that are both parsimonious and time-consistent has been shown to be intractable when such scenarios are modeled by reconciliations with an unranked species tree (Tofigh et al. 2011; Ovadia et al. 2011), while, when the provided species tree \({\mathbf {S}}\) is ranked, the problem becomes tractable (see Doyon et al. 2011 and references therein). Similarly, when \({\mathbf {S}}\) is ranked, we can ensure time-consistency of evolutionary histories, by requiring that the donor and receiver of any HGT belong to the same time slice in \({\mathbf {S}}^{\pi }\), i.e. the receiver of an HGT of a gene belonging to a species u belongs to \({\overline{C}}(u)=t(u) {\setminus } \{u\}\).
3 Methods
Our results (counting and sampling algorithms) are based on the design of formal grammars specifying, for a given species tree \({\mathbf {S}}\), the combinatorial families of \({\mathbb {D}}{\mathbb {L}}\)-histories and \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-histories constrained by \({\mathbf {S}}\). These grammars are then used as templates to design dynamic programming algorithms for counting and sampling (under the uniform distribution) the number of histories of a fixed size. Moreover, these grammars are amenable to techniques of analytic combinatorics that allow us to compute the asymptotic growth constant for the number of histories. We first describe our grammars, then the counting and sampling algorithms, and finally the asymptotic analysis of these grammars.
3.1 General grammars specifying \(\pmb {{\mathbb {D}}{\mathbb {L}}}\)-histories and \(\pmb {{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}}\)-histories
In this section we describe grammars specifying histories evolving within a species tree using the formalism developed in Flajolet and Sedgewick (2009). We describe grammars for \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-histories, for both an unranked and a ranked species tree; these grammars can then be specialized into grammars for \({\mathbb {D}}{\mathbb {L}}\)-histories by omitting the rules related to HGT.
Let \({\mathbf {S}}\) be a species tree. If \({\mathbf {S}}\) is unranked, it is a binary tree, otherwise, if it comes with a ranking \(\pi \), we consider the unary-binary species tree \({\mathbf {S}}^\pi \). So in the statements below, when mentioning a ranked species tree we mean the unary-binary tree \({\mathbf {S}}^{\pi }\) defined by the ranking, i.e., we omit the ranking \(\pi \) in the sequel.
Recall that \({\mathbf {S}}_u\) denotes the subtree rooted at node u. Likewise, we denote by \({H}_u\) the set of \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-histories for the tree \({\mathbf {S}}_u\). In the most general setting, following (Flajolet and Sedgewick 2009), these grammars contain both terminal symbols, corresponding to atomic elements of the histories (nodes) and non-terminal symbols, corresponding to combinatorial operators applied to sets of histories. We use the non-terminal symbol \({\mathcal {Z}}_u\) to encode a gene present in extant species u; moreover, we use \({\mathcal {X}}_u\) for a gene lost at species u, \({\mathcal {Y}}_u\) for a duplication at species u and \({\mathcal {W}}_u\) for a HGT with donor species u. We consider two combinatorial operators, \(\cup \) the disjoint union and \(\times \) the Cartesian product.
Theorem 3.1
The set \({H}_{r({\mathbf {S}})}\) defined by the grammar below specifies the set of all \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-histories for a species tree \({\mathbf {S}}\).
where \({\overline{C}}(u)\) is the set of nodes that are incomparable with u in \({\mathbf {S}}\). The set of \({\mathbb {D}}{\mathbb {L}}\)-histories is specified by the same grammar where rule (6) is removed and the terms \({T}_u\) are removed from rules (1) and (2).
Proof
The grammar follows the definition of histories, Definition 2.1. Rule (1) simply states that the root (i.e. the first evolutionary event of the history) of a \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-history within the subtree \({\mathbf {S}}_u\), assuming it is not reduced to a leaf, is either a speciation, a duplication or a transfer of the ancestral gene present in species u: non-terminal symbols \({\mathcal {S}}_u\), \({D}_u\) and \({T}_u\) represent respectively these three subsets of \({H}_u\). Rule (2) addresses the case where \({\mathbf {S}}_u\) is composed of a single leaf, in which case there can not be a speciation event, but a history reduced to a single gene in species u.
Rule (3) describes a speciation event at species u. The ancestral gene can either evolve into a gene in each of the two children of u (first term of the union) or into a gene in a single child of u due to a gene loss in the other child of u. In the case where u is unary (due to being a node created by the time slicing in a ranked \({\mathbf {S}}\)), the ancestral gene evolves into a copy in the unique child \(u_c\) of u.
Rule (5) addresses the case of a duplication. It results in two ordered independent histories starting at species u: the first one being the history of the original copy of the starting ancestral gene and the second one the history rooted at the novel gene created by the duplication.
Last, Rule (6) addresses the case of histories starting by a HGT. Generally, a HGT has a structure similar to a duplication but for the fact that the novel gene appears in a species that is incomparable with u.
These various rules cover all cases for describing the possible first event of a history and are mutually exclusive, thus providing a complete recursive specification of \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-histories for a given species tree \({\mathbf {S}}\). It follows immediately that removing the rule and non-terminals associated to HGT gives a grammar specifying \({\mathbb {D}}{\mathbb {L}}\)-histories for \({\mathbf {S}}\). \(\square \)
Remark 3.2
For many applications the grammar given in Theorem 3.1 is too detailed in the sense that it considers e.g. the precise distribution of extant species. In the sequel we will be only interested in the total number of extant species, as well as speciation, duplications and transfer events. Therefore, we replace all non-terminal symbols \({\mathcal {Z}}_u\) (resp. \({\mathcal {X}}_u\), \({\mathcal {Y}}_u\), \({\mathcal {W}}_u\)) by a single variable \({\mathcal {Z}}\) (resp. \({\mathcal {X}}\), \({\mathcal {Y}}\), \({\mathcal {W}}\)).
3.2 Counting and sampling algorithms
The grammar defined above can naturally be turned into a dynamic programming algorithm computing the number of histories of a given size. This algorithm computes tables H, D, S, T where, for a given node u of \({\mathbf {S}}\) and a given history size n, H[u, n] (respectively, D[u, n], S[u, n], T[u, n]) is the number of \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-histories of size n evolving within \({\mathbf {S}}_u\) (respectively, starting with a duplication, a speciation, and an HGT). We illustrate this in the case of \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-histories with an unranked species tree \({\mathbf {S}}\).
A random generation algorithm can then be adapted from the counting recurrences, resulting in an instance of the so-called recursive method (Wilf 1977). Right-hand sides of the counting equation are split into sums of multiplicative terms. Starting from the initial state \(H[r({\mathbf {S}}),n]\), the algorithm randomly chooses a term from the right-hand side of the current state, with probability proportional to its contribution to the counting. When the selected term is a multiplication of two terms, the length n needs to be distributed across the two terms, and a pair of lengths \((m, n-m)\), is chosen with probability proportional to the associated count. For the sake of performances, the various alternatives can be explored in Boustrophedon order, ensuring an overall \({\mathcal {O}}(n\log (n))\) worst-case complexity (Flajolet et al. 1994). Recursive calls are then performed over the states associated with the chosen term, until a leaf is chosen (term \(\mathbb {1}\)). This leads to the following result.
Theorem 3.3
The number of histories of size n constrained by a species tree of size k can be computed in polynomial time \({\mathcal {O}}(\varPhi (n,k))\) and space \({\mathcal {O}}(\varPsi (n,k))\), where \(\varPhi (n,k)\) and \(\varPsi (n,k)\) both depend on the model (\({\mathbb {D}}{\mathbb {L}}\) or \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)) and the ranked/unranked nature of the species tree, as summarized in Table 1.
The uniform random generation of h histories of size n can be performed in time \({\mathcal {O}}(\varPhi (n,k)+ h\cdot \varUpsilon (n,k))\).
3.3 Asymptotic number of histories in the \(\pmb {{\mathbb {D}}{\mathbb {L}}}\)-model
The grammar given in Theorem 3.1 defines a combinatorial specification of the set of histories for a given species tree in a given evolutionary model. In this section, we derive the asymptotic number of histories in the \({\mathbb {D}}{\mathbb {L}}\)-model and use it later on two specific species trees: the caterpillar and complete binary trees. The following theorem is the main result of this section and describes their asymptotic growth for n tending to infinity.
Theorem 3.4
For any given species tree \({\mathbf {S}}\), the number of histories in the unranked \({\mathbb {D}}{\mathbb {L}}\)-model given by Eqs. (1)–(5) is, for large n, equal to
for explicitly computable constants \(\gamma _{\mathbf {S}}>0\) and \(\rho _{\mathbf {S}}\in (0, 1/4]\).
In the remainder of this section we prove this theorem. The grammars are amenable to enumerative and analytic combinatorics techniques. We follow the general approach presented in Flajolet and Sedgewick (2009) and Drmota (1997). It consists mainly in translating the combinatorial specification of a combinatorial family into equations defining its counting generating function. Then, its analytic properties lead to precise asymptotic formulas for its coefficients. We provide an overview of this approach in Example 3.5.
Example 3.5
Consider the class of rooted binary trees \({B}\). Such a tree is either a leaf, or it consists of a root with two children which are also each roots of binary trees. Let us mark each leaf with the variable \({\mathcal {Z}}\). Then, the grammar is given by
Let \(b_n\) be the number of binary trees with n leaves and let \(B(z) = \sum _{n \ge 1} b_n z^n\) be the counting generating function of binary trees. The symbolic method (Flajolet and Sedgewick 2009, Part A) translates this grammar directly into an equation for the generating function:
Its generating function is thus given by \(B(z) = \frac{1-\sqrt{1-4z}}{2}.\)
The general method of singularity analysis from analytic combinatorics (Flajolet and Sedgewick 2009, Chapter VI) allows us to directly get the asymptotics of the coefficients. First, by the Cauchy–Hadamard theorem, the asymptotic growth is directly connected with the dominant singularities (and the radius of convergence) of the counting generating function. Here, the generating function B(z) becomes singular at \(z=1/4\), which is also the unique singular point. Hence, the coefficients \(b_n\) grow like \(4^n\). Second, using transfer theorems of analytic combinatorics (Flajolet and Sedgewick 2009, Theorem VI.1 and Theorem VI.3) we also get the subexponential terms and recover the well-known result for Catalan numbers \(b_{n+1} = \frac{1}{n+1}\left( {\begin{array}{c}2n\\ n\end{array}}\right) \) (see OEIS Foundation Inc. 2020):
for \(n \rightarrow \infty \).
We will now describe this approach applied to the grammar specifying the \({\mathbb {D}}{\mathbb {L}}\)-histories with an unranked species tree \({\mathbf {S}}\). Let \(h_{u,n}\) be the number of \({\mathbb {D}}{\mathbb {L}}\)-histories of \({\mathbf {S}}_u\) consisting of n genes represented in the generating function by the formal variable z. We define the counting generating functions
The coefficients \(h_{u,n}\) represent the number of histories of size n associated with the species tree \({\mathbf {S}}_u\) independent on the number of losses or duplications. These generating functions (one per species u of \({\mathbf {S}}\)) are strongly related to the generating function of binary trees B(z) introduced in Eq. (13).
Lemma 3.6
For a given species tree \({\mathbf {S}}\) the counting generating function \(H_{r({\mathbf {S}})}(z)\) for histories in the unranked \({\mathbb {D}}{\mathbb {L}}\)-model is defined by the system of functional equations
over all nodes u of \({\mathbf {S}}\), where
Proof
The symbolic method (Flajolet and Sedgewick 2009, Part A) translates the unranked \({\mathbb {D}}{\mathbb {L}}\)-grammar of Eqs. (1)–(5) into a system of equations for the generating functions; compare Example 3.5. First, as we are only interested in the total number of extant species (independent of the specific distribution), we replace \(Z_u\) by the counting variable z. Second, we ignore the number of speciation, duplication, and transfer events and replace \(X_u\), \(Y_u\), and \(W_u\) by 1. Third, we replace \(H_u\), \(D_u\), \(T_u\), and \(W_u\) by generating functions \(H_u(z)\), \(D_u(z)\), \(T_u(z)\), and \(W_u(z)\), respectively. Finally, we transform unions into sums and Cartesian products into normal products. This gives a system of equations, that is simplified to the following recursive set of equations for \(H_u(z)\):
Comparing these equations with the one for binary trees from Eq. (13) the claim follows. \(\square \)
The advantage of the generating function approach is that it allows us to identify the universal subexponential growth \(n^{-3/2}\), and to explicitly compute the exponential growth \(\rho _{\mathbf {S}}^{-n}\) and the constant \(\gamma _{\mathbf {S}}\) for a fixed species tree \({\mathbf {S}}\). We will compute the involved constants explicitly for the caterpillar tree in Sect. 4.1.1 and for the complete binary tree in Sect. 4.1.2. Our experiments in Sect. 4.2 suggest that among all species trees of size k the number of \({\mathbb {D}}{\mathbb {L}}\)-histories for given n is maximal for the caterpillar tree and minimal for balanced trees, where complete binary trees are special cases for powers of two; see also Conjecture 4.5. This would imply, that the exponential growth factor \(\rho _{{\mathbf {S}}}\) is bounded by the respective exponential growth factors for the caterpillar and the balanced trees. Note that no such conclusion is possible for the constant \(\gamma _{{\mathbf {S}}}\).
By basic principles of analytic combinatorics, the asymptotic growth of a counting sequence is directly related to the radius of convergence of the corresponding generating function. In particular, its dominant singularity (i.e. the one closest to the origin) defines its asymptotic growth. By the construction in terms of nested radicals, the generating function \(H_u(z)\) is singular if and only if at least one of its radicals vanishes. Writing the explicit form of the outermost B(z) in (14) gives
Then, the radicands satisfy the following recurrence
The recurrence can be used to determine the nature of the radii of convergence. For a node u we define \(\rho _u\) as the radius of convergence of \(H_u(z)\).
Lemma 3.7
Let u be the parent of v in \({\mathbf {S}}\). Then, \(\rho _u < \rho _v\) and \(\rho _u \in (0,1/4]\) with \(\rho _u=1/4\) if u is a leaf. Furthermore, \(R_u(z)\) is the only radicand of \(H_u(z)\) that vanishes at \(z=\rho _u\) and \(\rho _u\) is a simple root.
Proof
By combinatorial construction \(H_u(z)\) is built of nested radicals and does not include any poles. Therefore, its dominant singularity \(\rho _u\) must be at the point minimal in modulus where (at least) one of its radicands vanishes. By Pringsheim’s Theorem (Flajolet et al. 1990, Theorem IV.6) we know \(\rho _u \in (0,+\infty )\). When u is a leaf we directly see from (17) that \(\rho _u=1/4\).
We continue by induction on the depth of the subtree with root u given by \({\mathbf {S}}_u\). The depth is the longest path from the root to any leaf. As a first step, we prove that \(R_{u}(0)=1\). For a leaf u it is clear from Relation (17) that \(R_u(0) = 1\).
Next, let v and w be the children of u.
By the induction hypothesis we directly get
In order to continue, note that \(R_u(z)\) is monotonically decreasing on \([0,+\infty )\), because from the decomposition in (16) and (15) we see that
for certain non-negative numbers \(a_n\).
Next, assume that for the given v and w we have \(\rho _v \le \rho _w\). Note that \(R_v(z)\) and \(R_w(z)\) are continuous on \((0,\rho _v)\). Therefore, by Relation (17), \(R_u(z)\) is continuous on \((0,\rho _{v})\). Hence, we get
Thus, on the one hand, by the intermediate value theorem \(R_u(z)\) must have at least one zero in the interval \((0,\rho _{v})\). On the other hand, as \(R_u(z)\) is monotonically decreasing it has at most one zero in \((0,\rho _{v})\). Hence, this zero is equal to \(\rho _u\) and \(\rho _u < \rho _v\).
Finally, the above reasoning implies that among the nested radicals of \(H_u(z)\) the outermost one is the first one that vanishes, and no other radical vanishes at the same time. Thus, \(\rho _u\) is the radius of convergence of \(H_u(z)\). Moreover, by (18) we see that the derivative \(R_u'(z)\) has non-positive coefficients. Hence, \(\rho _u\) is a simple root. \(\square \)
Let us shortly digress and discuss in a more general context how to numerically compute the exponential growth for the coefficients of the generating function with the fastest exponential growth that is defined by a system of functional equations involving generating functions \({B}_1,\dots ,{B}_k\) of the form
where the \(\varPhi _i\) are polynomials with non-negative integer coefficients in \(k+1\) variables. Note that the grammar given in Theorem 3.1 is of this form. In order to decide which of the \(B_i\)’s has this specific exponential growth, further information on the problem, like in our case given by Lemma 3.7, is needed. By Banach’s fixed point theorem, these equations admit a unique solution vector \((B_{1},\ldots ,B_{k}) \in ({\mathbb {C}}[[z]])^k\) with respect to the formal topology (Flajolet and Sedgewick 2009, Section A.5). Furthermore, each \(B_{i}(z)\) has non-negative coefficients in its expansion around 0 (which is already clear from the combinatorial nature of the problem). Then, the multivariate version of the implicit function theorem implies that each of them has a non-zero radius of convergence which we call \(\rho _i\). By Pringsheim’s Theorem (Flajolet and Sedgewick 2009, Theorem IV.6), \(\rho _i \in [0,+\infty ]\) is a singularity of \(B_{i}(z)\). Moreover, as \(B_{i}(z)\) is an ordinary generating function of an infinite combinatorial class, we must have \(\rho _i \in [0,1]\). Finally, in order to compute the radius of convergence, we find the minimal point \(z \in [0,1]\) where the implicit function theorem fails. To be more precise, we numerically compute solutions \(\rho \in [0,1]\) and \(b_1,\ldots ,b_k \in [0,+\infty )\) of the following system
where \(\delta _{i,j}\) is the Kronecker symbol: \(\delta _{i,i}=1\), and \(\delta _{i,j}=0\) for \(i \ne j\).
Remark 3.8
The unranked \({\mathbb {D}}{\mathbb {L}}\)-grammars lead to the following specific shape
Hence, we get \( \det \left( \delta _{i,j} - \frac{\partial }{\partial b_j} \varPhi _{i}(\rho ,b_1,\ldots ,b_k)\right) = \prod _{i=1}^{k} (1-2b_i). \) We actually know by Lemma 3.7 that the outermost square-root vanishes, which gives \(b_k = B_k(\rho )=1/2\). Additionally, we can also directly deduce from this system that \(\rho _{k} \le \rho _{k-1}\).
In the unranked \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model the system is as follows
where the last equation is the only one involving \(B_k\), as the root can not be a receiver of an HGT. Note that the subsystem of the first \(k-1\) equations is strongly connected but still does not satisfy the a-properness condition (i.e. there is no contraction in the formal topology) of the Drmota–Lalley–Woods Theorem (Flajolet and Sedgewick 2009, Theorem VII.6) which would directly imply a square root singularity. Thus, we conjecture that the dominant singularity still comes solely from the outermost square root of \(B_k\) implying \(b_k=1/2\).
In the ranked \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model we are dealing with blocks of strongly connected components that correspond to the time slices. Note that the root is contained in a singleton time slice. An experimental analysis of the corresponding systems of functional equations using computer algebra suggests the same behavior as in the previous cases.
However, one fact holds in all models: we always have \(\rho _{r({\mathbf {S}})} \le \rho _u\) for all other subtrees with root u of the species tree. Hence, there will be always a dominant minimal singularity in [0, 1] that can be (numerically) computed. Note however, that the determinant computation quickly becomes extremely heavy.
After determining the radius of convergence, we must determine the number of singularities on it. As shown in the case of \(\lambda \)-terms in (Bodini et al. 2018, Lemma 8) there can only be one dominant singularity \(\rho _u\). Let us quickly repeat this argument here. Assume that there exists a root \(z_0 = \rho _u e^{i \theta }\) of the same modulus. Substituting this value into \(R_u(z)\) from (18) gives
which can only hold if \(e^{i n \theta } = 1\) whenever \(a_n \ne 0\). Now, due to \(a_1 \ne 0\) we have \(z_0=\rho _u\). Hence, \(\rho _u\) is the unique dominant real singularity of \(H_u(z)\).
Combining the previous results, we have shown for a family of constants \(\gamma _{u,i}\) the following local singular expansion
The fact that \(R_u(z)\) has a simple root at \(z=\rho _u\) implies that \(\gamma _{u,0} \ne 0\). Furthermore, as \(R_u(z)\) is monotonically decreasing in a neighborhood of \(\rho _u\) (see Lemma 3.7) we have \(\gamma _{u,0} >0\). (This follows also a-posteriori from the fact that the generating function has non-negative coefficients and therefore the subsequent asymptotics has to be non-negative.) This information suffices to deduce the asymptotic expansion of the coefficients using singularity analysis (Flajolet and Sedgewick 2009, Chapter VI); compare also Example 3.5.
First, the asymptotic growth is given by the reciprocal of the dominant singularity, i.e., the one closest to the origin. In our case this singularity is \(\rho _u\) and therefore the asymptotic growth is equal to \(\rho _u^{-n}\). Second, by transfer theorems of analytic combinatorics (Flajolet and Sedgewick 2009, Theorem VI.1 and Theorem VI.3), the subexponential terms are related to the asymptotic expansion at \(z=\rho _u\) which we see above; see also (Flajolet and Sedgewick 2009, Figure VI.5). In particular, we have a square-root singularity and we get, after applying the scaling rule of Taylor expansions,
This is the claimed asymptotic expansion of Eq. (12), where \(\gamma _{\mathbf {S}}= \frac{\gamma _{u,0}}{2\sqrt{\pi }} > 0\). This ends the proof of Theorem 3.4.
Remark 3.9
There are several possible extensions of the previous approach in order to rigorously analyze a conjectured behavior for other models. First of all, it is straightforward to extend it to the ranked \({\mathbb {D}}{\mathbb {L}}\)-model. In that case one only needs to incorporate unary nodes arising from the time slices. Second, an extension to the \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model is also possible, yet the computations are more involved as the binary tree structure leading to Lemma 3.6 does not hold anymore. However, it can still be modeled with colored binary trees, where the number of colors depends on the size of the set of incomparable nodes (in the current time slice). Third, it is also possible to consider the distribution of certain parameters, such as the number of gene losses, or the number of gene duplications, see e.g. for related results in lattice paths and trees (Bóna and Flajolet 2009; Gittenberger et al. 2018; Banderier and Wallner 2016). Using multivariate generating functions and marking each such event by an additional variable like in the general grammar of Theorem 3.1, the above results for the \({\mathbb {D}}{\mathbb {L}}\)-model directly generalize to the respective ones on multivariate generating functions. All these generalizations are interesting future research directions.
The counting and sampling algorithms described above have been implemented in Python, and are available at https://github.com/cchauve/DLTcount.
4 Results
Over the next two sections, we will apply Theorem 3.4 to the special cases of the caterpillar and complete binary species tree in the unranked \({\mathbb {D}}{\mathbb {L}}\)-model, and explicitly determine the constants involved in the asymptotic expansion. Then, we apply our dynamic programming counting and sampling algorithms to study properties of random evolutionary histories.
4.1 Asymptotic expansion for extremal species trees in the \(\pmb {{\mathbb {D}}{\mathbb {L}}}\)-model
Our experimental results (Sect. 4.2) suggest that for a given k, the species trees having the largest (resp. smallest) number of \({\mathbb {D}}{\mathbb {L}}\)-histories are respectively the caterpillar tree and the balanced binary tree with k leaves (Conjecture 4.5), defined below. In the present section, our main results are the explicit computation of the asymptotic growth and the leading constant of Theorem 3.4 for the caterpillar species tree (Propositions 4.1 and 4.2) and for the complete binary species tree, the special case of balanced trees when k is a power of 2 (Propositions 4.3 and 4.4, see also Table 2).
The rooted caterpillar tree \(\mathbf {CT}_k\) can be defined as follows: \(\mathbf {CT}_1\) is the tree reduced to a single leaf, while \(\mathbf {CT}_k\) (\(k > 1\)) is the tree formed by a left subtree equal to \(\mathbf {CT}_{k-1}\) and a right subtree equal to \(\mathbf {CT}_1\). Observe that every subtree of a caterpillar tree is itself a caterpillar tree, see Fig. 4.

Left: the caterpillar species tree \(\mathbf {CT}_5\). Right: the complete binary species tree \(\mathbf {CB}_2\)
The complete binary tree \(\mathbf {CB}_h\) with \(k=2^h\) leaves can be defined as follows: \(\mathbf {CB}_0\) is the tree reduced to a single leaf, while \(\mathbf {CB}_h\) (\(h\ge 1\)) is the tree formed by a left and a right subtree both equal to \(\mathbf {CB}_{h-1}\). Observe again that every subtree is itself a complete binary tree, see Fig. 4. The complete binary tree is a special case of the class of balanced trees, defined as trees where, for each node, the number of leaves in the left subtree differs from the number of leaves in the right subtree by at most one. Complete binary trees are the only balanced trees in which the number of leaves is a power of two.
We can observe that the number of \({\mathbb {D}}{\mathbb {L}}\)-histories grows much faster for the caterpillar tree than for the complete binary tree. This is actually unsurprising given that the number of \({\mathbb {D}}{\mathbb {L}}\)-histories can be linked to the size of the grammar, which itself depends on the structure of the species tree. More precisely, the size of the grammar depends on the number of unique subtrees of the considered species tree S. Each such subtree may be identified by its root u and corresponds to one set of rules (1)–(6), while subtrees having the same topology lead to isomorphic subgrammars with the same counting generating functions. The caterpillar (resp. complete binary) tree has the largest (resp. smallest) number of unique subtrees within the set of species trees of the same size (when k is a power of 2 for the complete binary tree), compare also Table 2. The special role of the caterpillar and complete binary trees echoes recent observations regarding these two trees (Gavryushkin and Drummond 2016; Gavryushkin et al. 2018).
4.1.1 Counting \(\pmb {{\mathbb {D}}{\mathbb {L}}}\)-histories associated with the caterpillar species tree
Denote by \({H^{\mathbf {CT}{}}_{{k}}}\) the set of \({\mathbb {D}}{\mathbb {L}}\)-histories over the caterpillar \(\mathbf {CT}_k\), then the general grammar of \({\mathbb {D}}{\mathbb {L}}\)-histories, where extant genes are marked by a single terminal \({\mathcal {Z}}\), is the following:
Let \(f_{k,n}\) be the number of \({\mathbb {D}}{\mathbb {L}}\)-histories of the caterpillar \(\mathbf {CT}_k\) consisting of n genes. The corresponding counting generating function is given by
Now we use Lemma 3.6 to derive a functional equation, which we immediately simplify by the defining recursive structure of caterpillars: The right child is always a leaf with generating function B(z) and the left child is a smaller caterpillar. Therefore, we get
In Table 3 we computed the first few initial terms for \(k=1,\ldots ,5\). Note that none but the first one was found in the OEIS before we added them.
Applying Theorem 3.4, the asymptotic expansion of the coefficients for \(n \rightarrow \infty \) is
for some constants \(\alpha _k>0\) and \(\lambda _k>0\) that are made explicit below.
Proposition 4.1
We define the following sequence of rational functions in X
Let \(X_k\) be the minimal positive real solution of the fixed point equation
Then, the dominant singularity of \(F_{k}(z)\) can be found at \(\lambda _k = \frac{1-X_k^2}{4}\).
Proof
We need to analyze the nested radicals of \(F_k(z)\) in more detail. Therefore, as done in Eq. (16) for the general case, we define the decomposition
Thus, we directly get the specialized version of the recurrence for the radicands from Eq. (17) by
The dominant singularity \(\lambda _k\) is given by the minimal positive root of \(P_k(z)\). This already proves the case \(k=1\). We introduce the shorthand \(X=\sqrt{1-4z}\) and define new polynomials \({\tilde{P}}_k(X)\) such that \(P_k(z)={\tilde{P}}_k(\sqrt{1-4z})\). This directly gives
Hence, this equation is zero if and only if
For \(k=2\) this proves the claim as \(\sqrt{{\tilde{P}}_1(X)}=X\). Now we proceed by induction. Squaring this equation and substituting the known expression for \({\tilde{P}}_{k-1}(X)\) gives
Repeating this process proves the claim. \(\square \)
Proposition 4.2
Using the notation of Proposition 4.1, the constant \(\alpha _k\) is equal to
In particular, \(\alpha _k >0\).
Proof
We will prove that \({\tilde{P}}_k(X)\) admits the following expansion in a neighborhood of \(X_k\):
where the derivative is with respect to X. Note that this derivative exists, as \({\tilde{P}}_k(X)\) is analytic on \((0,(1-X_{k-1}^2)/4)\) and we know from Lemma 3.7 that \(X_{k-1} < X_k\).
Next, recall the shorthand \(X=\sqrt{1-4z}\) and that by the chain rule \(\partial _z {\tilde{P}}_k(X) = \partial _X {\tilde{P}}_k(X) \partial _z X\). Then, the transfer theorems of analytic combinatorics (Flajolet and Sedgewick 2009) directly show that the n-th coefficient of \(F_k(z)\) satisfies the form (12) with \(\alpha _k = \sqrt{\lambda _k {\tilde{P}}_k'(X_k)/(8 \pi X_k)}\).
Therefore, it remains to find an expression for \({\tilde{P}}_k'(X_k)\).
Let us take the derivative of Eq. (25). We get
In the proof of Proposition 4.1 we have seen that \(\sqrt{{\tilde{P}}_{i}(X_k)} = s_{k-i+1}(X_k)\). Iterating this equation until \({\tilde{P}}_1'(X)=2X\) shows the claim. Finally, the positivity of the constant holds as all terms are positive. \(\square \)
With these formulas it is easy to compute explicit values for the constant \(\alpha _k\) and the asymptotic growth factor \(\lambda _k^{-1}\). We show the first few values in Table 2.
4.1.2 Counting \(\pmb {{\mathbb {D}}{\mathbb {L}}}\)-histories associated with the complete binary species tree
Let \(H^{\mathbf {CB}}_{h}\) be the set of \({\mathbb {D}}{\mathbb {L}}\)-histories associated with the complete binary tree \(\mathbf {CB}_h\). Then, the respective grammar, considering again only terminals \({\mathcal {Z}}\) marking extant genes, is the following:
Let \(g_{h,n}\) be the number of histories over the complete binary tree \(\mathbf {CB}_h\) consisting of n genes represented by z. As before, we analyze the counting generating function which is given by
As in the case of a caterpillar species tree, we get from Lemma 3.6 combined with the recursive definition of binary species trees the following functional equation
As before, we computed the first few initial terms in Table 4. Again, none but the first one was found in the OEIS [50] before we added them.
Applying Theorem 3.4 gives the asymptotic expansion of the coefficients for \(n \rightarrow \infty \) as
where \(\beta _h>0\) and \(\mu _h>0\) are nonnegative constants computed as follows.
Proposition 4.3
The dominant singularity of \(G_h(z)\) is \(\mu _h = \frac{1-q_{h}}{4}\), where
Furthermore, \(q_h\) and \(\mu _h\) are algebraic numbers of degree \(2^h\).
Proof
As for the caterpillar tree, we need to analyze the nested radicals. To make this structure visible, we again define
Then, the radicands satisfy the following recurrence
When comparing it with the recurrence of radicands for the caterpillar grammar in (24) we notice a major difference: the coefficients are independent of z.
Then, the reasoning follows the same lines as the proof of Proposition 4.1. Yet, due to the independence of the coefficients of z, the induction yields an explicit expression. Note that \(Q_{h-i}(\mu _h) = q_i\). \(\square \)
In a similar way we are also able to compute the constant \(\beta _h\) explicitly.
Proposition 4.4
Using the notation of Proposition 4.3, the constant \(\beta _h\) is equal to
Proof
By Eq. (30) the singularity of \(G_h(z)\) is determined by the smallest root \(\mu _h\) of \(Q_h(z)\). The constant is determined by the expansion for \(z\rightarrow \mu _h\):
By the recursive definition, \(Q_h(z)\) is differentiable in \((0,\mu _{h-1})\) due to \(\mu _{h} < \mu _{h-1}\). Thus, \(b_h = Q_h'(\mu _h)\) is well-defined. Differentiating the recurrence of \(Q_h(z)\) we get
Iterating this relation and applying \(Q_{h-i}(\mu _h) = q_i\) proves the claim. \(\square \)
As before, we computed the first few explicit values for the constant \(\beta _h\) and the asymptotic growth factor \(\mu _h^{-1}\), where h is a power of 2, and show them in Table 2.
4.2 Empirical investigations and open questions
In this section we present empirical results and observations derived using the counting and sampling algorithms described in Sect. 3.2. These results provide the first detailed view, especially in the \({\mathbb {D}}{\mathbb {L}}\)-model, of the general question: in how many ways can n genes have evolved from a single ancestral gene, for a given species tree?
4.2.1 Counting histories for random species trees
We are first interested in computing the number of histories in a given evolutionary model. We considered the following models: \({\mathbb {D}}{\mathbb {L}}\)-histories with an unranked or ranked species tree (called respectively models \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\) and \(\textsf {r}{\mathbb {D}}{\mathbb {L}}\) from now), \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-histories with an unranked species tree or a ranked species tree (called respectively models \(\textsf {u}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\) and \(\textsf {r}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\) from now).
For a given evolutionary model and species tree S of size k, let \(h_S(n)\) be the number of histories of size n. As shown in Eq. (12) for the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\)-model, this number grows asymptotically with n as follows
where \(\gamma _\mathbf{S}\) and \(\rho _\mathbf{S}\), both depend only on \(\mathbf{S}\). From now, we denote \(E_S = \rho _\mathbf{S}^{-1}\) the exponential growth factor for the number \(h_\mathbf{S}(n)\). In the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\)-model, as discussed in Sect. 3.3, we can compute precisely the growth factor from the grammar specifying the \({\mathbb {D}}{\mathbb {L}}\)-histories for the given species tree \(\mathbf{S}\). For other models, we can estimate \(E_\mathbf{S}\) from the number \(h_\mathbf{S}(n)\) of histories of size n as follows:
this estimate precision increasing naturally with n.
\({\mathbb {D}}{\mathbb {L}}\)-models. We considered species trees of size ranging from \(k=3\) to \(k=25\) and for each species tree size k, we generated 98 random species tree of size k under the uniform distribution, using the RANRUT algorithm described in Nijenhuis and Wilf (1978), and we completed this set of species tree by adding the caterpillar species tree with k leaves and the balanced tree with k leaves;Footnote 3 so for small values of k, the same species tree can occur several times in the sample of 100 trees. When working in the \(\textsf {r}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model, we generated, for each species tree 10 random rankings under the uniform distribution, using the algorithm described in Bodini et al. (2018). Then, for each instance, we computed the number of histories of size \(n=50\) in the models \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\), \(\textsf {u}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\) and \(\textsf {r}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)Footnote 4 and used these numbers to estimate the growth factor using (32).
Figure 5 shows the exponential growth factor in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\)-model obtained using the exact approach described in Sect. 3.3 and the ratio between this exact growth factor and the growth factor estimated using the experimental approach described above. A first observation from Fig. 5 is that estimating the growth factor from the number of histories of size \(n=50\) approximates well the exact growth factor in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\)-model; we believe it is also the case in the other models (data not shown).

Box-plot of the distribution of the growth factor for each 100 random species tree per size k in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\)-model. (Top) exact growth factor; (Bottom) box-plot of the distribution, for each species tree, of the ratio between the exact growth factor and the estimated growth factor
Moreover, following up on the results shown in Table 2, our experiments lead to the following conjecture, characterizing the species trees leading to extreme growth factors for a given value of k.
Conjecture 4.5
For a given k, and n large enough, the unranked species tree of size k having the largest number of \({\mathbb {D}}{\mathbb {L}}\)-histories of size n is the caterpillar tree; moreover the exponential growth factor of the number of histories for a caterpillar of size k grows superlinearly as a function of k. Species trees having the smallest number of \({\mathbb {D}}{\mathbb {L}}\)-histories are balanced species trees of size k and the exponential growth factor of the number of histories for a balanced tree of size k grows linearly as a function of k.
We verified that the conjecture is true for all values of k in our experiments. We investigated several proof ideas, in particular linking the exponential growth factor to the number of unique subtrees in a species tree. Indeed this is a feature for which caterpillar and balanced trees reach extreme values for a given value of k; actually the caterpillar is the unique tree with the maximum number of subtrees, while balanced trees have the minimum number of subtrees, although if k is not a power of 2, some unbalanced trees can have the same number of subtrees as the balanced ones. We did find examples of pairs of species trees for which the one with the larger (resp. smaller) number of unique subtrees has a smaller (resp. larger) exponential growth factor. There are also species trees with the same number of unique subtrees as balanced trees of the same size and showing a larger exponential growth rate. So the number of unique subtrees is not the determinant leading to an extreme growth factor. We observed similar examples when considering the height of the species tree, another feature for which caterpillar and balanced trees attain extreme values. Generally the question of understanding which features of species trees of the same size that makes one having more \({\mathbb {D}}{\mathbb {L}}\)-histories than the other one is open.
\({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-models. Next, we consider models including HGT; in Fig. 6 we show the estimated growth constants in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)- and \(\textsf {r}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-models.

Box-plot of the distribution of the growth factor for each 100 random species tree per size k in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\) (top) and \(\textsf {r}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\) (bottom) models. The growth factor is estimated from the number of \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-histories of size \(n=50\) using formula (32)
An observation that addresses one of the main questions motivating our work, is that the number of histories in models involving HGT grows much faster than in models excluding HGT; this is apparent by comparing the growth factors in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\) and \(\textsf {u}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\) models, but even more through Fig. 7 that shows the ratio of the number of \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-histories over the number of \({\mathbb {D}}{\mathbb {L}}\)-histories for selected pairs (k, n), considered over all randomly chosen ranked or unranked species trees. We can observe that the ratios grow as large as \(10^{40}\) in the unranked model and \(10^{29}\) in the ranked model for histories of size 50 over a species tree of size 25, that correspond to parameters of realistic phylogenomics datasets. It is nevertheless interesting to observe that considering ranked species trees tames significantly the magnitude of the search space explosion when introducing HGT in a model.

Box-plots of the distribution of the ratio of the number of DLT-histories over the number of \({\mathbb {D}}{\mathbb {L}}\)-histories over all species trees size k and histories size n for selected pairs (k, n). The distributions are obtained, for each (k, n), over 100 randomly chosen (resp. 1000) unranked (resp. ranked) species trees
Finally, we can observe that in the \(\textsf {r}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model, the growth factor seems to be almost independent of the topology of the chosen species tree and ranking (Fig. 6 (Bottom)). Intuitively, this can be explained by the fact that a ranked species tree can almost be seen as a sequence of time slices, each composed of a set of branches (from 1 branch for the time slice containing the root of S to k branches for the time slice containing all leaves), with exactly one ending with a speciation node while all other end by a unary node. Within each time slice, the genes can evolve freely by duplication and HGT, where a duplication can be seen as equivalent to a HGT within the same branch. Thus, the number of histories is dominated by the number of evolutionary events taking place in each time slice, with some variability being introduced by the number of genes leaving a time slice right after the only speciation node it contains, that can create extra gene copies entering the next time slice.
In order to understand this phenomenon, we investigated a reduced evolutionary model, in which every speciation is followed by a random loss, i.e. does not create an extra gene copy entering the next time slice; we name this model the \(\textsf {r}{\mathbb {D}}{\mathbb {T}}\)-\({\mathbb {S}}{\mathbb {L}}\)-model, where \({\mathbb {S}}{\mathbb {L}}\) stands for Speciation-Loss. In this model, we are able to prove the independence of the chosen species trees.
Theorem 4.6
In the \(\textsf {r}{\mathbb {D}}{\mathbb {T}}\)-\({\mathbb {S}}{\mathbb {L}}\)-model, the number of histories of size n is the same for every ranked species tree of size k.
Proof
Let a ranked species tree of size k be given, and consider the unary-binary tree induced by its time slices. We then transform this tree into a directed graph called the events graph describing the possible events of duplication, HGT, and speciation in the following way:
- 1.
Label the leaves from 1 to k.
- 2.
Label each internal node with a set containing the labels of the leaves of its induced subtree. These labels are the possible leaves reachable by speciation;
- 3.
Encode speciation events by super edges called speciation edges which consist of the one (unary) or two (binary) edges leading to the children of a node. By doing so, the two edges are treated as a single edge;
- 4.
Encode duplication events by adding loops called duplication edges to each node;
- 5.
Encode HGT events by adding edges called transfer edges from each node to each other node within the same time slice;
Note that by 5 we have a complete directed graph in every time slice, i.e., all nodes in a time slice are adjacent to each other. An example of this transformation is shown in Fig. 8.
Let us briefly state some properties of the events graph. The labels of the nodes of each time slice form a set partition of \(\{1,\ldots ,k\}\) by construction. Due to the rankings, each time slice contains one node more than the previous one and every path from the root to the previous leaves contains \(k-1\) speciation edges.
The main idea of the proof is that we can encode a history H for a species tree S of size k by an ordered unary-binary tree \(H_e\) whose nodes are labeled by nodes of the events graph, that encodes unambiguously H, and then show that in the \(\textsf {r}{\mathbb {D}}{\mathbb {T}}\)-\({\mathbb {S}}{\mathbb {L}}\)-model, given the events graph \(E'\) of another ranked species tree \(S'\) of the same size, we can transform \(H_e\) into an ordered unary-binary tree \(H'_e\) whose nodes are labeled by nodes of \(E'\) that encodes a unique history for \(S'\). This establishes a one-to-one correspondence between the sets of histories for two arbitrary ranked species trees of size k, S and \(S'\), and thus proves the stated result.
The principle of the encoding is to associate each internal node of a history with a (deterministic) label which is a node of the events graph. Let E be the events graph of S. The encoding works as follows: for a node x of a history H for species tree S, if t is the time slice it belongs to and i its left-most leaf (defined in a depth-first traversal of the ordered tree representing the history), then we label x by the unique node of E in the time slice t that contains i. Extant leaves stay labeled by their extant species. After deleting leaves corresponding to gene losses from the history, speciation-loss nodes become unary, while duplication and HGT nodes stay binary. Call \(H_e\) the ordered unary-binary tree for history H. The original history H can be unambiguously recovered from \(H_e\) and E, by reinserting these losses and removing the labels, as any edge of \(H_e\) corresponds to an edge of E, so defines an evolutionary event.
Next, let \(S'\) be another ranked species tree of the same size k as S and \(E'\) its events graph. We transform \(H_e\) into \(H'_e\) as follows: for every node x, whose left-most leaf is u and that belongs to time slice t, replace its label by the unique node of time slice t of \(E'\) that contains the u. This is always possible, as, by construction of the events graph in models with HGT, any leaf is reachable from any node. We claim that \(H'_e\) defines unambiguously a history for \(S'\). The key argument to prove this claim is that, by the way we constructed \(E'\) and \(H'_e\), for any edge in \(H'_e\) the labels of its two nodes, that are either in the same time slice or in consecutive time slices, are incident in \(E'\): if both nodes are in the same time slice, then by construction of \(E'\) they are either the same node (so linked by a duplication edge) or are incident by a transfer edge, while if they are in consecutive time slices, they contain a common species and so are incident by a speciation edge. It follows that \(H'_e\) encodes a history \(H'\) for \(S'\). The construction from H to \(H'\) is deterministic and reversible, which provides a one-to-one correspondence between the histories of S and the histories of \(S'\) in the \(\textsf {r}{\mathbb {D}}{\mathbb {T}}\)-\({\mathbb {S}}{\mathbb {L}}\)-model.
Note that this construction does not work in models with no duplication, HGT or unrestricted speciation as the key argument that any edge in \(H'_e\) can be found in \(E'\) does not hold anymore, thus preventing to be able to transform \(H'_e\) into a history for \(S'\). \(\square \)

Transformation of a ranked species tree (left part of the figure) (\(\pi (A)=1,\pi (B)=2,\pi (C)=3,\pi (D)=\pi (E)=\pi (F)=\pi (G)=4\)) into an events graph (right part of the figure) in the \(\textsf {r}{\mathbb {D}}{\mathbb {T}}\)-\({\mathbb {S}}{\mathbb {L}}\)-model used in the proof of Theorem 4.6
Remark 4.7
From the previous proof we can also deduce an iterative tree growing algorithm for the histories offering an alternative explanation for Theorem 4.6. Every internal node gets a label that is a pair consisting of its time slice and the number of its left-most leaf. Note that this uniquely identifies a node in the species tree.
We start with a root node labeled by the first time slice and an arbitrary number from \(\{1,\ldots ,k\}\). At every step, choose a leaf of the current history and consider the corresponding node in the events graph. Then traverse one of its edges and perform the action of this edge: If it is a speciation edge then add a new node with a label consisting of the successive time slice and the same number as only child . If it is a duplication or transfer edge then add a left child with the same label as the root and a right child labeled with the current time slice and an arbitrary number from the set the edge is pointing to. Once all leaves correspond to extant nodes the tree is a valid history.
Remark 4.8
The construction of the events graph in Theorem 4.6 can be adapted to all models. If there are no duplication events, the duplication edges are removed; if there are no HGT events, the transfer edges are removed. The characteristics of the \({\mathbb {S}}{\mathbb {L}}{}\) dynamics are not encoded in the events graph but in the bijection or the history growing algorithm.
4.2.2 On the parsimony and profile of random histories.
We also considered the distribution of the evolutionary score for randomly sampled histories, where the score of a history is the sum of the number of duplications, losses and HGT, for \(k=16\) and \(n=30\), over 50 random unranked species trees, sampling 10, 000 random histories for each species tree.
Figure 9 below suggests that the space of histories for a given species tree is dominated by histories with a relatively high score and that, as expected, for a given species tree including HGT in the evolutionary model leads to a significant decrease of the evolutionary score of histories.

Distribution of the score (number of duplications plus losses plus HGT) over 50 random species trees of size 16 and 10, 000 random histories of size 30 per tree in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\)- and \(\textsf {u}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-models

Distribution of the ratio Duplications/losses in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\) (top) and of the ratios HGT/score, Duplications/score and losses/score in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model (bottom). For both figures the distribution is over 50 random species trees of size 16 and 10,000 random histories of size 30 per tree
In fact, when looking at the distribution of the number of duplications in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model (results not shown), we observed that the duplication number drops significantly in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model compared to the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\)-model. We can also note that, when comparing the score of histories in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\)-model and the number of duplications, most of the score is due to gene losses (Fig. 10), a characteristic we also see in the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model where the number of duplications (resp. HGT) rarely exceeds 5 (resp. 25) in the sampled histories.
5 Conclusion and perspectives
Our work introduces the first results on counting and sampling evolutionary scenarios in models accounting for gene duplication, gene loss and HGT. The originality of our work, compared to previous work in the reconciliation framework, is that we only consider the species tree to be given, and thus consider all possible evolutionary histories of a given size, i.e. leading to a given number of genes. Our results include formal grammars describing this combinatorial space, together with counting and sampling algorithms, obtained using either dynamic programming or enumerative and analytic combinatorics methods. These results complement a growing body of work developed over the last few years in the case of matching gene and species trees.
Using our method, we were able to obtain precise asymptotics on the number of histories for the two specific species trees, the rooted caterpillar and the complete binary tree in the unranked \({\mathbb {D}}{\mathbb {L}}\)-model, although our method also applies to any given species tree in this model. Our counting and sampling algorithms allowed us to complement these results for other models, especially models accounting for HGT. Our experimental results provide a first global view of the space of potential evolutionary histories for a given species tree. They confirm the expected fact that introducing HGT in a model results in a dramatic increase of the space of possible histories; they also lead to the interesting observation that in the ranked \({\mathbb {D}}{\mathbb {L}}{\mathbb {T}}\)-model, the total number of histories is asymptotically almost independent of the given species tree.
Our work suggests several avenues for further research. First, our notion of evolutionary history assumes that gene trees are ordered, i.e. that gene copies created by a gene duplication are distinguishable; this differs from the notion of reconciled gene trees, where duplicated copies are not distinguishable. While our assumption follows naturally from an evolutionary biology point of view, it would be interesting to see if our approach could be applied to count and sample reconciliations instead of histories. Reconciliations can indeed be specified using formal grammars, but their combinatorial analysis is more involved and we were not able to obtain results such as precise asymptotics estimates of the number of reconciliations. This question deserves further research. Next, the last few years have seen the development of more comprehensive models of gene family evolution, accounting for example for genes appearing at a given species by an HGT from an unsampled or extinct species (Szöllősi et al. 2013b), incomplete lineage sorting (ILS) (Rasmussen and Kellis 2012; Wu et al. 2014; Zhang and Wu 2017; Du and Nakhleh 2018; Stolzer et al. 2012; ban Chan et al. 2017), or gene conversion (Hasić and Tannier 2019). In these models, reconciled gene trees can be computed using dynamic programming algorithms and it is natural to ask if such algorithms could be turned into grammars for the corresponding space of evolutionary scenarios. Last, from an applied point of view, a limitation of our work lies in the fact that histories are parameterized by their size, i.e. the number of extant genes, while in applications, the genes of a gene family are assigned to specific extant species. Ideally, in order to explore (through counting or sampling) the space of all possible evolutionary scenarios for gene families whose distribution of genes in extant species is given, we would need to parameterize our algorithms by this distribution, which leads to dynamic programming algorithms with a much higher time and space complexity, dependent on the number of extant species. However, we believe that advanced combinatorial sampling, especially multiparametric combinatorial samplers (Bodini and Ponty 2010; Bendkowski et al. 2018), can be used within the framework we developed in the present work to provide efficient counting and sampling algorithms.
Notes
In the present work we consider only rooted trees.
Note that technically the event associated to a unary node in the species tree is not speciation in the biological meaning, but we chose to label it as such for expository reasons.
Note that for a given k, any two balanced ordered binary trees with k leaves differ only by swapping the left and right children of some internal nodes, so for our purpose there is essentially a unique balanced species tree for every value of k.
We omit here the results for the \(\textsf {r}{\mathbb {D}}{\mathbb {L}}\)-model as they are very similar to the results for the \(\textsf {u}{\mathbb {D}}{\mathbb {L}}\)-model, with a lower dispersion.
References
Åkerborg Ö, Sennblad B, Arvestad L, Lagergren J (2009) Simultaneous Bayesian gene tree reconstruction and reconciliation analysis. Proc Natl Acad Sci 106(14):5714–5719
Arvestad L, Lagergren J, Sennblad B (2009) The gene evolution model and computing its associated probabilities. J ACM 56(2):7:1–7:44
ban Chan Y, Ranwez V, Scornavacca C (2017) Inferring incomplete lineage sorting, duplications, transfers and losses with reconciliations. J Theor Biol 432:1–13
Banderier C, Wallner M (2016) Lattice paths with catastrophes. Discrete Math Theor Comput Sci 19(1), Sept. 2017. Full version of extended abstract with the same title appeared in the proceedings of conference on random generation of combinatorial structures—GASCom
Bansal MS, Alm EJ, Kellis M (2013) Reconciliation revisited: handling multiple optima when reconciling with duplication, transfer, and loss. J Comput Biol 20(10):738–754
Bansal MS, Kellis M, Kordi M, Kundu S (2018) Ranger-dtl 2.0: rigorous reconstruction of gene-family evolution by duplication, transfer and loss. Bioinformatics 34(18):3214–3216
Bendkowski M, Bodini O, Dovgal S (2018) Polynomial tuning of multiparametric combinatorial samplers. In: Proceedings of the fifteenth workshop on analytic algorithmics and combinatorics, ANALCO 2018, New Orleans, LA, USA, 8–9 Jan 2018. SIAM, pp 92–106
Bodini O, Ponty Y (2010) Multi-dimensional Boltzmann sampling of languages. In: Drmota M, Gittenberger B (eds) 21st International meeting on probabilistic, combinatorial, and asymptotic methods in the analysis of algorithms (AofA’10), volume DMTCS proceedings, vol. AM, pp 49–64, Vienna, Austria, June. Discrete Mathematics and Theoretical Computer Science
Bodini O, Gardy D, Gittenberger B, Gołębiewski Z (2018) On the number of unary–binary tree-like structures with restrictions on the unary height. Ann Comb 22(1):45–91
Bóna M, Flajolet P (2009) Isomorphism and symmetries in random phylogenetic trees. J Appl Probab 46(4):1005–1019
Degnan JH, Rosenberg NA (2006) Discordance of species trees with their most likely gene trees. PLOS Genet 2(5):1–7
Degnan J, Rosenberg N (2009) Gene tree discordance, phylogenetic and the multispecies coalescent. Trends Ecol Evolut 24:332–340
Degnan JH, Salter LA (2005) Gene tree distribution under the coalescent process. Evolution 59(1):24–37
Degnan JH, Rosenberg NA, Stadler T (2012) A characterization of the set of species trees that produce anomalous ranked gene trees. IEEE/ACM Trans Comput Biol Bioinform 9(6):1558–1568
Disanto F, Munarini E (2019) Local height in weighted dyck models of random walks and the variability of the number of coalescent histories for caterpillar-shaped gene trees and species trees. SN Appl Sci 1(6):578
Disanto F, Rosenberg NA (2014) On the number of ranked species trees producing anomalous ranked gene trees. IEEE/ACM Trans Comput Biol Bioinform 11(6):1229–1238
Disanto F, Rosenberg NA (2015) Coalescent histories for lodgepole species trees. J Comput Biol 22(10):918–929
Disanto F, Rosenberg NA (2016) Asymptotic properties of the number of matching coalescent histories for caterpillar-like families of species trees. IEEE/ACM Trans Comput Biol Bioinform 13(5):913–925
Disanto F, Rosenberg NA (2017a) Enumeration of ancestral configurations for matching gene trees and species trees. J Comput Biol 24(9):831–850
Disanto F, Rosenberg NA (2019a) On the number of non-equivalent ancestral configurations for matching. Bull Math Biol 81:384–407
Disanto F, Rosenberg NA (2019b) Enumeration of compact coalescent histories for matching gene trees and species trees. J Math Biol 78:155–188
Disanto F, Miglionico P, Narduzzi G (2019) On the unranked topology of maximally probable ranked gene tree topologies. J Math Biol 79(4):1205–1225
Doyon J-P, Chauve C, Hamel S (2009) Space of gene/species trees reconciliations and parsimonious models. J Comput Biol 16(10):1399–1418
Doyon J-P, Ranwez V, Daubin V, Berry V (2011) Models, algorithms and programs for phylogeny reconciliation. Brief Bioinform 12(5):392–400
Drmota M (1997) Systems of functional equations. Random Struct Algorithms 10(1–2):103–124
Du P, Nakhleh L (2018) Species tree and reconciliation estimation under a duplication-loss-coalescence model. In: Proceedings of the 2018 ACM international conference on bioinformatics, computational biology, and health informatics, BCB’18. ACM, pp 376–385
Durand D, Halldórsson BV, Vernot B (2006) A hybrid micro-macroevolutionary approach to gene tree reconstruction. J Comput Biol 13(2):320–335
Flajolet P, Sedgewick R (2009) Analytic combinatorics. Cambridge University Press, Cambridge
Flajolet P, Zimmermann P, Van Cutsem B (1994) A calculus for the random generation of labelled combinatorial structures. Theor Comput Sci 132(1–2):1–35
Flajolet P, Sipala P, Steyaert JM (1990) Analytic variations on the common subexpression problem. In: Automata, languages and programming (Coventry, 1990), volume 443 of lecture notes in computer science. Springer, New York, pp 220–234
Gavryushkin A, Drummond AJ (2016) The space of ultrametric phylogenetic trees. J Theor Biol 403:197–208
Gavryushkin A, Whidden C, Matsen FA (2018) The combinatorics of discrete time-trees: theory and open problems. J Math Biol 76(5):1101–1121
Gittenberger B, Jin EY, Wallner M (2018) On the shape of random Pólya structures. Discrete Math 341(4):896–911
Goodman M, Czelusniak J, Moore GW, Romero-Herrera AE, Matsuda G (1979) Fitting the gene lineage into its species lineage, a parsimony strategy illustrated by cladograms constructed from globin sequences. Syst Zool 28(2):132–163
Górecki P, Eulenstein O (2014) Drml: probabilistic modeling of gene duplications. J Comput Biol 21(1):89–98
Górecki P, Tiuryn J (2006) DLS-trees: a model of evolutionary scenarios. Theor Comput Sci 359(1):378–399
Górecki P, Burleigh GJ, Eulenstein O (2011) Maximum likelihood models and algorithms for gene tree evolution with duplications and losses. BMC Bioinform 12(1):S15
Hasić D, Tannier E (2019) Gene tree species tree reconciliation with gene conversion. J Math Biol 78(6):1981–2014
Jacox E, Chauve C, Szöllősi GJ, Ponty Y, Scornavacca C (2016) eccetera: comprehensive gene tree-species tree reconciliation using parsimony. Bioinformatics 32(13):2056–2058
Maddison WP (1997) Gene trees in species trees. Syst Biol 46(3):523–536
Nijenhuis A, Wilf HS (1978) Combinatorial algorithms. Academic Press, New York
OEIS Foundation Inc. (2020) The On-Line Encyclopedia of Integer Sequences. http://oeis.org
Ovadia Y, Fielder D, Conow C, Libeskind-Hadas R (2011) The cophylogeny reconstruction problem is NP-complete. J Comput Biol 18(1):59–65
Pei J, Wu Y (2017) STELLS2: fast and accurate coalescent-based maximum likelihood inference of species trees from gene tree topologies. Bioinformatics 33(12):1789–1797
Ranwez V, Scornavacca C, Doyon J-P, Berry V (2016) Inferring gene duplications, transfers and losses can be done in a discrete framework. J Math Biol 72(7):1811–1844
Rasmussen MD, Kellis M (2012) Unified modeling of gene duplication, loss, and coalescence using a locus tree. Genome Res 22(4):755–765
Rosenberg NA (2007) Counting coalescent histories. J Comput Biol 14(3):360–377
Rosenberg NA (2019) Enumeration of lonely pairs of gene trees and species trees by means of antipodal cherries. Adv Appl Math 102:1–17
Scornavacca C, Jacox E, Szöllősi GJ (2015) Joint amalgamation of most parsimonious reconciled gene trees. Bioinformatics 31(6):841–848
Sjöstrand J, Tofigh A, Daubin V, Arvestad L, Sennblad B, Lagergren J (2014) A bayesian method for analyzing lateral gene transfer. Syst Biol 63(3):409–420
Stolzer M, Lai H, Xu M, Sathaye D, Vernot B, Durand D (2012) Inferring duplications, losses, transfers and incomplete lineage sorting with nonbinary species trees. Bioinformatics 28(18):i409–i415
Szöllősi, G.J., Daubin, V (2012) Modeling gene family evolution and reconciling phylogenetic discord. In: Anisimova M (ed) Evolutionary genomics: statistical and computational methods, volume 2, volume 856 of methods in molecular biology. Humana Press, Totowa, pp 29–51
Szöllősi GJ, Rosikiewicz W, Boussau B, Tannier E, Daubin V (2013a) Efficient exploration of the space of reconciled gene trees. Syst Biol 62(6):901–912
Szöllősi GJ, Tannier E, Lartillot N, Daubin V (2013b) Lateral gene transfer from the dead. Syst Biol 62(3):386–397
Szöllősi GJ, Tannier E, Daubin V, Boussau B (2015) The inference of gene trees with species trees. Syst Biol 64(1):e42–e62
Tofigh A, Hallett MT, Lagergren J (2011) Simultaneous identification of duplications and lateral gene transfers. IEEE/ACM Trans Comput Biol Bioinform 8(2):517–535
Wilf HS (1977) A unified setting for sequencing, ranking, and selection algorithms for combinatorial objects. Adv Math 24(3):281–291
Wu Y (2012) Coalescent-based species tree inference from gene tree topologies under incomplete lineage sorting by maximum likelihood. Evolution 66(3):763–775
Wu Y (2016) An algorithm for computing the gene tree probability under the multispecies coalescent and its application in the inference of population tree. Bioinformatics 32(12):i225–i233
Wu Y-C, Rasmussen MD, Kellis M (2014) Most parsimonious reconciliation in the presence of gene duplication, loss, and deep coalescence using labeled coalescent trees. Genome Res 24(3):475–486
Zhang B, Wu Y-C (2017) Coestimation of gene trees and reconciliations under a duplication-loss-coalescence model. In: Cai Z, Daescu O, and Li M (eds) Bioinformatics research and applications, volume 10330 of lecture notes in computer science. Springer, Berlin, pp 196–210
Acknowledgements
Open access funding provided by Austrian Science Fund (FWF).
Funding
The first author is supported by a Discovery Grant of the Natural Sciences and Engineering Research Council of Canada (RGPIN-2017-03986). This research was enabled in part by support provided by Westgrid (https://www.westgrid.ca/) and Compute Canada (https://www.computecanada.ca) through a Resource Allocation (ID 838) to the first author. The third author was supported by the Exzellenzstipendium of the Austrian Federal Ministry of Education, Science and Research and the Erwin Schrödinger Fellowship of the Austrian Science Fund (FWF): J 4162-N35.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chauve, C., Ponty, Y. & Wallner, M. Counting and sampling gene family evolutionary histories in the duplication-loss and duplication-loss-transfer models. J. Math. Biol. 80, 1353–1388 (2020). https://doi.org/10.1007/s00285-019-01465-x
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00285-019-01465-x