
Abstract
In this paper, we introduce a new monotone inertial Forward–Backward splitting algorithm (newMIFBS) for the convex minimization of the sum of a non-smooth function and a smooth differentiable function. The newMIFBS can overcome two negative effects caused by IFBS, i.e., the undesirable oscillations ultimately and extremely nonmonotone, which might lead to the algorithm diverges, for some special problems. We study the improved convergence rates for the objective function and the convergence of iterates under a local Hölder error bound (Local HEB) condition. Also, our study extends the previous results for IFBS under the Local HEB. Finally, we present some numerical experiments for the simplest newMIFBS (hybrid_MIFBS) to illustrate our results.





Similar content being viewed by others

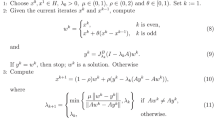

References
Agro, G.: Maximum likelihood and \(l_p\) norm estimators. Stat. Appl. 4, 7 (1992)
Apidopoulos, V., Aujol, J., Dossal, C.: Convergence rate of inertial forward–backward algorithm beyond Nesterov’s rule. Math. Program. 180, 137–156 (2020)
Apidopoulos, V., Aujol, J., Dossal, C., et al.: Convergence rates of an inertial gradient descent algorithm under growth and flatness conditions. Math. Program. (2020). https://doi.org/10.1007/s10107-020-01476-3
Attouch, H., Cabot, A.: Convergence rates of inertial forward–backward algorithms. SIAM J. Optim. 28, 849–874 (2018)
Attouch, H., Peypouquet, J.: The rate of convergence of Nesterov’s accelerated forward–backward method is actually faster than \( {\frac{1}{{{k^2}}}} \). SIAM J. Optim. 26, 1824–1834 (2016)
Attouch, H., Bolte, J., Redont, P., Soubeyran, A.: Proximal alternating minimization and projection methods for nonconvex problems: an approach based on the Kurdyka–Łojasiewicz inequality. Math. Oper. Res. 35(2), 438–457 (2010)
Bauschke, H., Combettes, P.: Convex Analysis and Monotone Operator Theory in Hilbert Spaces. CMS Books in Mathematics, Springer, New York (2011)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2, 183–202 (2009)
Beck, A., Teboulle, M.: Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems. IEEE Trans. Image Process. 18, 2419–2434 (2009)
Bolte, J., Daniilidis, A., Ley, O., Mazet, L.: Characterizations of Łojasiewicz inequalities: subgradient flows, talweg, convexity. Trans. Am. Math. Soc. 362, 3319–3363 (2010)
Bolte, J., Nguyen, T.P., Peypouquet, J., Suter, B.W.: From error bounds to the complexity of first-order descent methods for convex functions. Math. Program. 165, 1–37 (2015)
Bonettini, S., Rebegoldi, S., Ruggiero, V.: Inertial variable metric techniques for the inexact forward–backward algorithm. SIAM J. Sci Comput. 40, A3180–A3210 (2018)
Bonettini, S., Prato, M., Rebegoldi, S.: Convergence of inexact forward–backward algorithms using the forward–backward envelope. SIAM J. Optim. 30, 3069–3097 (2020)
Burke, J.V., Deng, S.: Weak sharp minima revisited Part III: error bounds for differentiable convex inclusions. Math. Program. 116, 37–56 (2009)
Chambolle, A., Dossal, C.: On the convergence of the iterates of the fast iterative shrinkage-thresholding algorithm. J. Optim. Theory Appl. 166, 968–982 (2015)
Combettes, P.L., Wajs, V.R.: Signal recovery by proximal forward–backward splitting. Multisc. Model. Simul. 4, 1168–1200 (2005)
Drusvyatskiy, D., Lewis, A.S.: Error bounds, quadratic growth, and linear convergence of proximal methods. Math. Oper. Res. 43, 919–948 (2018)
Hastie, T., Tibshirani, R., Friedman, J., Hastie, T., Friedman, J., Tibshirani, R.: The Elements of Statistical Learning. Springer, Berlin (2009)
Johnstone, P.R., Moulin, P.: Faster subgradient methods for functions with Holderian growth. Math. Program. 180, 417–450 (2020)
László, S.C.: Convergence rates for an inertial algorithm of gradient type associated to a smooth non-convex minimization. Math. Program. (2020). https://doi.org/10.1007/s10107-020-01534-w
Li, H., Lin, Z.: Accelerated proximal gradient methods for nonconvex programming. In: Proceedings of NeurIPS, pp. 379–387 (2015)
Liu, H.W., Wang, T., Liu, Z.X.: Convergence rate of inertial forward–backward algorithms based on the local error bound condition. http://arxiv.org/pdf/2007.07432
Liu, H.W., Wang, T., Liu, Z.X.: Some modified fast iteration shrinkage thresholding algorithms with a new adaptive non-monotone stepsize strategy for nonsmooth and convex minimization problems. Optimization. http://www.optimization-online.org/DB_HTML/2020/12/8169.html
Liu, H.W., Wang, T.: A nonmonontone accelerated proximal gradient method with variable stepsize strategy for nonsmooth and nonconvex minimization problems. Optimization. http://www.optimization-online.org/DB_HTML/2021/04/8365.html
Luo, Z.Q., Tseng, P.: On the convergence of coordinate descent method for convex differentiable minization. J. Optim. Theory Appl. 72, 7–35 (1992)
Luo, Z.Q., Tseng, P.: On the linear convergence of descent methods for convex essenially smooth minization. SIAM J. Control Optim. 30, 408–425 (1992)
Luo, Z.Q., Tseng, P.: Error bounds and convergence analysis of feasible descent methods: a general approach. Ann. Oper. Res. 46, 157–178 (1993)
Necoara, I., Clipici, D.: Parallel random coordinate descent method for composite minimization: convergence analysis and error bounds. SIAM J. Optim. 26, 197–226 (2016)
Necoara, I., Nesterov, Y., Glineur, F.: Linear convergence of first order methods for non-strongly convex optimization. Math. Program. 175, 69–107 (2019)
Nesterov, Y.: A method for solving the convex programming problem with convergence rate \(O\left( {\frac{1}{{{k^2}}}} \right)\). Dokl. Akad. Nauk SSSR. 269, 543–547 (1983)
Ochs, P., Chen, Y., Brox, T., Pock, T.: Inertial proximal algorithm for nonconvex optimization. SIAM J. Imaging Sci. 7(2), 1388–1419 (2014)
O’Donoghue, B., Candès, E.: Adaptive restart for accelerated gradient schemes. Found. Comput. Math. 15, 715–732 (2015)
Opial, Z.: Weak convergence of the sequence of successive approximations for nonexpansive mappings. Bull. Am. Math. Soc. 73, 591–597 (1967)
Rebegoldi, S., Calatroni, L.: Inexact and adaptive generalized FISTA for strongly convex optimization. https://arxiv.org/pdf/2101.03915.pdf (2021)
Roulet, V., d’Aspremont, A.: Sharpness, restart, and acceleration. SIAM J. Optim. 30, 262–289 (2020)
Schmidt, M., Roux, N.L., Bach, F.: Convergence rates of inexact proximal-gradient methods for convex optimization. In: Advances in Neural Information Processing System 24, NIPS (2011)
Su, W., Boyd, S., Candès, E.J.: A differential equation for modeling Nesterov’s accelerated gradient method: theory and insights. J. Mach. Learn. Res. 17, 1–43 (2016)
Villa, S., Salzo, S., Baldassarres, L., Verri, A.: Accelerated and inexact forward–backward algorithms. SIAM J. Optim. 23, 1607–1633 (2013)
Wang, T., Liu, H.W.: On the convergence results of a class of nonmonotone accelerated proximal gradient methods for nonsmooth and nonconvex minimization problems. Optimization. http://www.optimization-online.org/DB_HTML/2021/05/8423.html
Wang, P.W., Lin, C.J.: Iteration complexity of feasible descent methods for convex optimization. J. Mach. Learn. Res. 15, 1523–1548 (2014)
Wen, B., Chen, X.J., Pong, T.K.: Linear convergence of proximal gradient algorithm with extrapolation for a class of nonconvex nonsmooth minimization problems. SIAM J. Optim. 27, 124–145 (2017)
Yang, T.B.: Adaptive accelerated gradient converging methods under Hölderian error bound condition. http://arxiv.org/pdf/1611.07609v2
Yangy, T., Lin, Q.: A stochastic gradient method with linear convergence rate for a class of non-smooth non-strongly convex optimization. Tech. rep. (2015)
Zhang, H.: The restricted strong convexity revisited: analysis of equivalence to error bound and quadratic growth. Optim. Lett. 11, 817–833 (2017)
Zhang, H., Cheng, L.: Restricted strong convexity and its applications to convergence analysis of gradient type methods in convex optimization. Optim. Lett. 9, 961–979 (2015)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Proof of Lemma 3.2
Proof
From (3.1) with \(y: = {y_{k + 1}},x: = {x_k}\), we obtain that
which means that \(\sum \nolimits _{k = 1}^{ + \infty } {{{\left\| {{z_{k + 1}} - {y_{k + 1}}} \right\| }^2}} < + \infty ,\) i.e., \(\mathop {\lim }\limits _{k \rightarrow \infty } {\left\| {{z_{k + 1}} - {y_{k + 1}}} \right\| ^2} = 0\) and \(F\left( {{z_{k+1}}} \right) - {F\left( {{x^*}} \right) } \le \xi \) for \(\xi = F\left( {{x_1}} \right) - {F\left( {{x^*}} \right) } + \frac{1}{{2\lambda }}{\left\| {{z_1} - {x_0}} \right\| ^2},\) i.e., \({x_{k + 1}} \in {S_\xi }.\) Based on the nonexpansiveness property of the proximal operator [16], \(\nabla f\) is Lipschitz continuous and \(\lambda = \frac{\mu }{{{L_f}}}\) with \(\mu \in \left( {0,1} \right) ,\) we can deduce that
Using Lemma 2.3, we can conclude that
Applying (3.1) with \(y: = {y_{k + 1}},x: = {x^*}\) and using (A.3), we have
where \(\tilde{\tau }= \frac{{1 + {2^{\frac{1}{{1 - \theta }}}}\bar{\tau }}}{{2\lambda }}.\) \(\square \)
Appendix B: Proof of Theorem 4.1
Proof
From (3.1) with \(y: = {x_k},x: = {x^*}\), we obtain that
and with \(y: = {x_k},x: = {x_k},\) we obtain that
Similar with the proof of Lemma 3.2, we have
Consider the Local HEB condition with \(\theta \in \left[ {0,\frac{1}{2}} \right) .\) Multiplying (B.2) by \({k^\alpha },\) where \(\alpha \in \left[ {0,1} \right] \) is a constant, we obtain
where
and \({\varPsi _k} = {\left( {{{\left( {1 + \frac{1}{k}} \right) }^\alpha } - 1} \right) ^{\frac{{2\left( {1 - \theta } \right) }}{{1 - 2\theta }}}} \cdot {k^\alpha } = O\left( {{k^{\alpha - 1}}} \right) .\) Hence, let \(\frac{{{\varepsilon ^{2\left( {1 - \theta } \right) }}}}{{2\left( {1 - \theta } \right) }} = \frac{1}{{2\lambda }}\) and \(\alpha = \frac{1}{{1 - 2\theta }},\) then, \({\varPsi _k} = O\left( {\frac{1}{k}} \right) \) and
which means that
Using (B.3), then
Further, using the monotonic of \(\left\{ {F\left( {{x_k}} \right) - F\left( {{x^ * }} \right) } \right\} ,\) we obtain that
The proof for the case that \(\theta = \frac{1}{2}\) is more simple. The inequality (B.3) now become
Using above inequality to (B.2), we have
which means that the sequence \(\left\{ {F\left( {{x_k}} \right) - F\left( {{x^ * }} \right) } \right\} \) generated by FBS is Q-linear convergent.
The point (iii) is trivially. \(\square \)
Rights and permissions
About this article

Cite this article
Wang, T., Liu, H. Convergence Results of a New Monotone Inertial Forward–Backward Splitting Algorithm Under the Local Hölder Error Bound Condition. Appl Math Optim 85, 7 (2022). https://doi.org/10.1007/s00245-022-09859-y
Accepted:
Published:
DOI: https://doi.org/10.1007/s00245-022-09859-y
Keywords
- Optimization
- Monotone Inertial Forward–Backward Splitting algorithm
- Local hölder error bound condition
- Rate of convergence