
Abstract
This paper aims to investigate whether the predictive performance and behaviour of professional forecasters are different during the COVID-19 pandemic as compared with the global financial crisis of 2008 and normal times. To this end, we use a survey of professional forecasters in Singapore collated by the central bank to analyse the forecasting records for GDP growth and CPI inflation for the period 2000Q1–2021Q4. We first examine the point forecasts to document the extent of forecast failure during the two crises and explore various explanations for it, such as leader-following and herding behaviour. Then, using percentile-based summary measures of probability distribution forecasts, we study how the degree of consensus and extent of subjective uncertainty among forecasters were affected by crisis conditions. A trend break is observed in the subjective uncertainty associated with growth projections after the onset of the COVID-19 crisis. In contrast, both subjective uncertainty and the degree of consensus in inflation projections were essentially unchanged in crises, suggesting that the short-term inflation expectations of forecasters were strongly anchored.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Even in the best of times, economic forecasting is a challenging endeavour. At business cycle turning points, moreover, the inability of forecasters to recognize the onset of recessions and recoveries is well known. Furthermore, there is also ample evidence to show that forecast practitioners tend to underestimate both the severity of downturns and the strength of upswings in economic activity (see, inter alia, Zarnowitz 1992). These deficiencies are accentuated during relatively rarer events such as a financial crisis or a pandemic crisis because the past is a less reliable guide to the future on such occasions.
An illustrative example is provided by the global financial crisis (GFC) of the late 2000s which was triggered by a meltdown in financial markets. For instance, Alessi et al. (2014) found GDP growth forecasts to be markedly overestimated by the European Central Bank and the Federal Reserve Bank of New York during the GFC, with a more than doubling of conventional forecast evaluation statistics compared to pre-GFC levels. As documented by Lewis and Pain (2015), professional forecasters also consistently overestimated economic growth and inflation in the aftermath of the GFC. One way to improve upon the predictions of macroeconomic variables during a financial crisis is to incorporate high-frequency information contained in financial variables into forecasting models. This has led to a burgeoning literature on the application of mixed frequency models such as mixed data sampling (MIDAS) models and mixed frequency-vector autoregressive (MF-VAR) models to macroeconomic forecasting (see inter alia, Kuzin et al. 2011, 2013).
Another good example of forecasting during a crisis is provided by the recent COVID-19 pandemic that broke out in March 2020 and spread across the world in staggered waves of infection, bringing economic devastation in its wake. The difficulty in making economic forecasts during the pandemic crisis owing to its novelty is compounded by the unprecedented nature and scale of the pandemic. The enforced lockdowns, closures of workplaces and shops as well as travel restrictions implemented by governments, combined with a general fear of infection, prompted endogenous responses by economic agents with unpredictable effects on the overall economy. Another complication is the reimposition of movement control measures after they were relaxed whenever a new wave of infection occurs, which makes forecasting all but impossible. Given this, it would not be surprising that there would be widespread forecast failure.Footnote 1 The tools that economists employ to generate projections—and the macroeconomic relationships they relied on in the past—might simply be inadequate to the task.
The unprecedented forecasting difficulties can be traced to the unique characteristics of an epidemiological outbreak. In view of the absence of a comparable global pandemic in modern times, there is no precedent to rely on for guidance on how the economy would be affected. The SARS pandemic of 2003 which hit Singapore badly was quickly found to be a poor template for what was unfolding, since it was confined to Asian countries and rapidly contained. Furthermore, the biological nature of the COVID-19 crisis meant that forecasters could not take their cue from the usual economic indicators and information sources such as business intelligence. Instead, they had to depend on pronouncements made by the medical profession, whose members more often than not held divergent views on the future trajectory of the pandemic at any one time.Footnote 2
Most importantly, COVID-19 produced economic disruptions that interacted in unknown ways, unlike in previous recessions or even financial crises when only an aggregate demand or supply shock was at work. In this case, there was a collapse of consumer spending due to lockdowns and movement restrictions but at the same time, interruptions in supply capacity because of factory and shop closures. In other words, the interplay of macroeconomic forces was exceptionally difficult to grasp and quantify, with indeterminate effects on economic growth and price inflation. Consequently, some economic forecasters had to model the dynamics of the pandemic and its impact using explicit and untested assumptions (see for example Eichenbaum et al. 2021).
From an economic forecasting point of view, a pertinent question is how to treat the extreme COVID observations. Should these be ignored as temporary outlying data points or should they be viewed as having some economic content to be explicitly incorporated into economic forecasting models? Schorfheide and Song (2021) adopted the former approach and developed a MF-VAR model that was estimated without data in the initial crisis period. The authors found this to be a promising method to produce macroeconomic predictions beyond the initial downturn. By contrast, some papers in the forecasting literature account for the pandemic crisis by adjusting model specifications. For instance, Carriero et al. (2021) improved upon the forecast performance of a Bayesian VAR model with stochastic volatility by specifying a Student t-distribution for the innovations and augmenting it with outliers.
Nonetheless, the lack of precedence as well as the dearth of economic data for modelling pandemic instabilities have led various other studies to incorporated crisis information via priors. For instance, Huber et al. (2020) used flexible priors to handle the pandemic’s extreme outlying observations in the estimation of an additive regression tree, while Lenza and Primiceri (2020) applied a Pareto-distributed prior to the residual variance of a VAR model. Instead of using priors, Ng (2021) included non-economic indicators of pandemic severity like the number of hospitalisations, infections and deaths, either as control variables in regressions or as additional predictors. It will be useful to examine the comparative forecast performance of these various approaches when more data becomes available.
In this paper, we use a survey of professional forecasters (SPF) in Singapore collated by the central bank to study whether the economic forecasting record during the COVID-19 pandemic is a break from the past. It therefore differs from past studies of professional forecasters’ performance that tended to focus on all periods and mainly dealt with the advanced economies like the US, UK and the Eurozone.Footnote 3 The city-state of Singapore is a small economy, but it is highly open to trade and investment, which means that the negative shocks triggered by COVID-19 originated mostly from abroad and were transmitted domestically. Thus, the local community of forecasters faced the daunting task of predicting both the evolving impact of the pandemic on the global economy and its spillover effects onto Singapore, in addition to the effects of internal infection prevention measures. As the city hosts a vibrant financial sector, the performance and behaviour of the industry’s forecasters in rising to these challenges may be indicative of that experienced by forecasters elsewhere.
The more specific objective of this paper is to investigate whether the predictive ability and behaviour of professional forecasters during the COVID-19 pandemic differ from the GFC and non-crisis (i.e. normal) periods. To this end, we subject the survey forecasts of GDP growth and CPI inflation to various empirical analyses, seeking to shed light on the following three questions: (i) Was there forecast failure during the pandemic? (ii) What are the possible behavioural explanations for the forecast errors?, and (3) How did the COVID-19 shock affect the evolution of forecast uncertainty and disagreement among forecasters? Previous studies on assessing the performance of professional forecasters in Singapore had tended to focus only on point predictions (see for instance Monetary Authority of Singapore 2007, 2014). In contrast, this paper analyses both point forecasts and forecast probability distributions and also extends the sample period of the analysis to include the COVID-19 pandemic episode.
Since SPF participants are not required to disclose the methodology they used to produce forecasts, our aim is not to improve upon forecast accuracy.Footnote 4 Rather, we first compare the relative magnitudes of the errors incurred by our group of forecasters as a whole during the COVID-19 pandemic, the GFC and normal periods in order to investigate their proximate cause by considering various behavioural explanations. Specifically, we test for biased predictions, the influence of the government’s projections on private sector forecasters (“leader-following” behaviour), and the fear of deviating from majority opinion (“herding” behaviour).
In the second part of the paper, we turn the focus of our empirical analysis from point predictions to the forecast probability distributions provided in the SPF. These subjective probability distributions convey the central tendency of the survey participants’ beliefs as well as the uncertainty they experienced (see Li and Tay 2021). In particular, we examine the changes in the degree of consensus and the extent of subjective uncertainty associated with individual forecasts, and how the latter relates to an objective measure of uncertainty. Our specific interest is in comparing these measures between the COVID-19 pandemic and the GFC. Even though the two crises are different in terms of trigger, transmission mechanisms and policy responses, the shock in each episode resulted similarly in a huge spike in uncertainty in the economic environment. Based on nonparametric measures such as medians and central ranges of the individual subjective probability distributions, we assess how forecast uncertainty and disagreement among the forecasters were affected by the heightened economic uncertainty.
The rest of the paper is organized as follows. Section 2 describes the dataset containing the macroeconomic projections of professional forecasters in Singapore from which our evidence is drawn. Section 3 investigates the extent of forecast failure during COVID-19 and the GFC as compared to normal times, as well as its possible behavioural causes. Section 4 contrasts the evolution of measures of consensus and uncertainty during the pandemic with the financial crisis and links forecasters’ subjective uncertainty to an objective indicator of economic uncertainty. Section 5 concludes.
2 Data description
The economic forecasts analysed in this paper are taken from the Monetary Authority of Singapore’s (MAS) Survey of Professional Forecasters, which contains rich information on the private sector’s point forecasts of key macroeconomic variables in Singapore and related probability distribution forecasts. The central bank’s survey began in the last quarter of 1999, and since then, it has regularly polled local forecasters for their short- to medium-term outlook on the economy. The identities of the participants, which typically numbered between twenty to thirty individuals (or institutions) in each survey, are confidential but they consist almost exclusively of professional economists in the Singapore financial sector who work for banks, investment houses and economic consultancies, with academic participation in the early years. Each respondent is assigned a unique identification number so that his forecasts can be followed over time (respondents may drop out or new ones added). A standard questionnaire is sent to participants every quarter following the release to the public of the latest official economic data that constitutes a key reference in information sets.Footnote 5 Survey findings are announced in the first week of the months of March, June, September, and December each year and posted on the MAS website.
The MAS survey questionnaire requests from each respondent his projections of many macroeconomic variables, including real GDP and its sectoral breakdown, CPI inflation, the unemployment rate, private consumption, and exports. For our purposes here, attention is confined to the point and probability distribution forecasts of the real GDP year-on-year growth rate and the CPI annual inflation rate, i.e. changes in these two variables from one year to the following year. There are three types of point forecasts with varying time horizons, namely a rolling horizon forecast for one quarter ahead and two fixed event forecasts. The first fixed event forecast is produced within a given year for the current year’s outcome, that is, a projection with a varying time horizon of one quarter to four quarters. The second is a forecast produced within a given year for the next year’s outcome, with time horizons of five to eight quarters. As rolling horizon forecasts do not come with probability distributions and are only available for CPI inflation from 2017Q4, we focus on fixed event forecasts with horizons of one and two years.
The point predictions made one and two years in advance are available for the entire sample period 2000Q1–2021Q4, except for a gap of five years from 2005 to 2009 when the following year’s projections were not reported for inflation. However, probability distribution forecasts were introduced only in 2001Q3 for growth and 2017Q4 for inflation. The set of forecast intervals for each variable that survey respondents are asked to attach probabilities to were decided by MAS and their number and width varied across variables and surveys to take account of prevailing economic developments.
The benchmark data against which the accuracy of the professional forecasts is assessed, and the behaviour of the forecasters are evaluated, are retrieved from the singstat database maintained by the national statistical authority. Forecasts issued by the government, on the other hand, are culled from various issues of the Economic Survey of Singapore (GDP growth) and of the Macroeconomic Review (CPI inflation)—the official publications of the Ministry of Trade and Industry and the MAS, respectively. The inflation data in Singapore are not revised although GDP data are. In this regard, we are aware that the use of real-time data may yield different conclusions from revised data as forecasters are assumed to make predictions of the early releases rather than the final version of GDP statistics (Keane and Runkle 1990). Unfortunately, real-time vintages of the growth data are not published separately, compelling us to use revised data in the empirical analyses.Footnote 6
3 This time is different: forecast failure during crises
3.1 Forecast errors
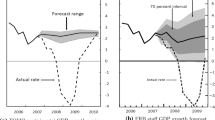
A tentative hypothesis of this paper is that forecast failure during the recent pandemic is worse than in the financial crisis due to its novelty and unique features. Figures 1 and 2 plot the means of the one- and two-year ahead forecasts of survey respondents made in the first quarter of each year together with the revised growth and inflation data. The forecasts errors, computed as realizations minus forecasts, are also included in the figures. The figures generally bear out the observation that GDP growth forecast errors tend to be larger in magnitude during the trough of recessions and the initial upturn of recoveries. In comparison with growth forecast errors and as expected, the errors for CPI inflation are smaller in magnitude.

GDP growth (%)

CPI inflation (%)
More formally, we report the moments of the forecast errors and their magnitude using the root-mean-square error (RMSE) statistics in Tables 1 and 2 for the growth and inflation projections at the two time horizons. We infer from the means in Table 1 that the positive one-year ahead growth forecast errors tend to dominate the negative ones while the opposite is true for the two-year ahead inflation forecast errors. The higher standard deviations in the growth forecast errors vis-à-vis inflation forecast errors reflect the wider variation in the former as apparent in Figs. 1 and 2. Unsurprisingly, the variability in forecast errors increases when the forecast horizon lengthens. The frequency distribution of forecast errors in all cases is neither heavily skewed nor severely leptokurtic. While the first-order autocorrelation is absent in the one- and two-year ahead growth forecast errors, the inflation forecast errors for both time horizons exhibit positive serial correlation.
Table 2 records the RMSE statistics computed separately for the two crisis episodes and for normal periods. We define the sub-sample periods for the GFC and the COVID-19 pandemic as 2008Q3‒2009Q4 and 2020Q1‒2021Q4, respectively. The remainder of the sample period constitutes the normal periods. To better assess the magnitudes of the forecast errors committed by the survey respondents, we include in each case the RMSE statistic generated from a simple benchmark model. For this purpose, a autoregressive process of order two (AR(2)) is used to model the annual growth as well as the annual inflation time series data starting in 1975. The benchmark AR(2) model for each variable is estimated recursively from 2009 to generate one- and two-step ahead forecasts in each recursion that correspond to the one- and two-year ahead SPF forecasts. The RMSE statistics computed from the forecast errors generated by the benchmark models appear in parentheses in Table 2.
It is clear from Table 2 that the SPF forecasts outperform those produced by the benchmark models except for the two-year ahead GDP growth projections during the GFC. Interestingly, Table 2 also shows that the forecast error in predicting growth during the COVID-19 pandemic exceeds that in normal times but not during the GFC for both time horizons. The situation is less clear-cut for CPI inflation, as the one-year ahead prediction errors during COVID-19 are larger than those during the GFC and normal periods but the reverse is true for the two-year ahead forecast errors. Although the lack of observations precludes formal testing of the RMSE differences for statistical significance, they are indicative of the unparalleled challenges encountered by Singapore’s professional forecasters in making predictions during crises periods.
3.2 Behavioural explanations
Turning to behavioural explanations, we first test whether the forecasts made during the two crises episodes and in normal periods are biased, in which case they imply that survey participants do not use information efficiently. In this regard, an earlier study has shown that GDP growth forecasts tend to be unbiased prior to the GFC, but inflation forecasts are not (Monetary Authority of Singapore 2007). Following Holden and Peel (1990), we test for the presence of bias by performing the following pooled regressions on the individual forecast errors of survey participants at the one- and two-year horizons:
where \(y_{t}^{\left( r \right)}\) denotes the realized value of either GDP growth or inflation at time t and yit is the forecast of the respective variable by forecaster i at time t. Table 3 reports the ordinary least squares estimates of the intercept term α that represents the average deviation of forecasts from the realized values, with their heteroscedastic-robust standard errors denoted by s.e. The number of observations used to estimate the regressions for the GFC and COVID-19 crisis episodes is 40 and 66, respectively. The corresponding number for the normal sub-period is different for growth vis-à-vis inflation forecasts; they are 797 and 660, respectively.
Unbiasedness implies that forecast errors are zero, on average, so the estimated constant terms ought to be statistically insignificant. The results indicate that forecasters in Singapore produced biased growth forecasts during the GFC, which is also the case in the OECD countries (Lewis and Pain 2015). While growth forecasts tend to be too low during the GFC, they turned out to be unbiased during the COVID-19 pandemic. As for inflation forecasts, positive bias was detected by the two-tailed t tests at the 5% significance level, suggesting the forecasters tend to underpredict inflation during both crisis episodes. In comparison, both growth and inflation forecasts are biased during normal times.
Given the forecasting difficulties mentioned earlier, the MAS survey participants could exhibit what the forecasting literature has dubbed “leader-following” behaviour. In our study, this refers to forecasters being unduly influenced by the official forecasts made by the government, thereby suppressing private information. In Singapore, official forecasts of current and next year GDP growth and CPI inflation are expressed as ranges of possible values (not to be interpreted as probability density forecasts).Footnote 7 The official forecast range for current (next) year GDP growth is typically published by the Singapore Ministry of Trade and Industry in the year’s first three (last two) quarters. As for inflation, the MAS usually announces the official forecast ranges for the current year in the second and fourth quarters, while those for the next year are provided in the third quarter. Forecasters can choose to locate their point estimates in or out of the ranges, depending on their views—which may or may not coincide with those of the authorities—or the extent to which they are swayed by the government’s outlook.
To determine whether there is a tendency for participants to depart from the official ranges of growth predictions during the GFC and the COVID-19 pandemic, we again analyse the projections made by individual forecasters instead of the consensus forecast since the latter is the mean of the point forecasts reported by respondents and is thus subject to aggregation bias because the heterogeneity among forecasters has been averaged away. Leader-following behaviour can be investigated by counting the number of occasions over each crisis period in which the individual forecasts from the MAS survey fall outside the official ranges. Under the null hypothesis that governmental forecasts do not influence private sector projections, the conditional probability of overshooting or undershooting the official forecast ranges is 0.5 (Rülke et al. 2016).
Combining the current and next year predictions for which official forecasts are available, the proportions of forecasters whose predictions are different from official forecasts (\(\hat{p}\)) are computed. We then perform a two-tailed test on whether the true proportion of such forecasters (p) in each case is 0.5. The z-test statistics, defined by
, and their associated significance levels for the two crisis sub-periods as well as the corresponding proportions are given in Table 4.
The results show that the proportion of growth forecasts that were out of the official ranges during the GFC is not significantly different from 0.5 at the 5% level, indicating that survey participants exercised some independence from official views. The proportion for inflation forecasts is however different from 0.5. By contrast, there is strong evidence that the proportions of growth and inflation forecasts were close to zero during the COVID-19 crisis, suggesting the participants tended to stay within the official forecast ranges. In sum, leader-following behaviour of forecasters appears to be present when predicting macroeconomic variables during the pandemic but is absent for growth projections during the GFC.
Being a relatively small group with professional and social ties, the survey respondents could also exhibit what the forecasting literature has dubbed “herding” behaviour. This refers to pecuniary or reputational incentives for forecasters to influence each other, deviate from their own opinions and follow the crowd. An individual forecaster may do this to avoid making extreme forecasts, or because a wrong forecast may not damage his reputation if other forecasters also delivered poor forecasts (Rülke et al. 2016). However, it is difficult to distinguish between herding behaviour and reliance on a common information set among forecasters which may result in undifferentiated projections. On the other hand, a forecaster may behave in a “contrarian” or anti-herding manner if by doing so, he can enhance his standing in the event his projection turns out to be correct, or to gain publicity (Pons-Novell 2003). Such a strategic bias has been observed among older and more established practitioners, as compared to novices (Lamont 2002).
In the context of this study, a reasonable hypothesis will be that participants in the MAS survey tend to herd in times of heightened economic uncertainty such as the GFC and the COVID-19 pandemic. We investigate the presence of herding behaviour in the fixed event forecasts and use a testing methodology adapted from Pons-Novell (2003).Footnote 8 The test is based on the observed difference between the individual and consensus forecasts made at the start of each year, which should be statistically indistinguishable from zero if a forecaster practised herding behaviour. Instead of running separate regressions for individual survey respondents as in Pons-Novell (2003), which is unviable due to the small number of observations available for the GFC and COVID-19 sub-periods, we again perform the test by pooling the predictions of individual forecasters.
Table 5 records the t-statistics for testing the null hypothesis that the average of the individual deviations from the consensus forecasts is zero. In both crises and for both growth and inflation, the constant terms in the regressions are statistically insignificant at the 5% level, suggesting that forecasters exhibited herding behaviour. These findings are corroborated by an examination of the individual projections separately. If herding behaviour is present, the average deviation of a participant’s forecasts from the consensus forecast should not differ from zero according to a small-sample t test.Footnote 9 The proportion of forecasters whose average projections deviated significantly from the consensus out of the total number who made predictions is recorded in Table 5. We observe that while slightly more than a quarter of the respondents demonstrated contrarian behaviour in their growth and inflation forecasts during each crisis period, the large majority showed herding behaviour.
In summary, we may conclude that forecast failure during crisis periods can be attributed to bias, with the exception of growth predictions during the COVID-19 pandemic. During the GFC, the bias in growth forecasts may be explained by herding but not leader-following behaviour. Conversely, growth forecasts during the pandemic were unbiased even though the survey participants were leader-following as well as herding. Bias in the one- and two-year ahead inflation projections for both the GFC and COVID-19 periods can be traced to a combination of leader-following and herding behaviour.
4 Consensus and uncertainty in crises
4.1 Definitions
In an article three decades ago, Zarnowitz and Lambros (1987) offered seminal definitions of consensus and uncertainty in economic forecasting. They suggested that consensus is best defined as the degree of agreement between the point predictions reported by different forecasters, while uncertainty is properly understood as referring to the spread of the distributions of probabilities that individual forecasters attach to the possible values of a macroeconomic variable. The second definition rules out the commonplace use of a measure of dispersion of individual forecasts around the group average as an indicator of uncertainty. In these instances, it is implicitly assumed that episodes characterized by high (low) dispersion of point forecasts are indicative of a high (low) level of ex-ante uncertainty shared by respondents. However, Zarnowitz and Lambros find that this measure tends to understate uncertainty, as compared to their preferred definition.
Boero et al. (2008) combined the above two definitions in a measure they called “aggregate uncertainty” by considering the variance of the aggregate probability distribution which is computed by summing the individual probabilities reported in survey results, dividing by the number of respondents and then normalizing them to add to unity. If the mean and variance of the aggregate probability distribution are denoted by μA and \(\sigma_{A}^{2}\), respectively, the latter can be expressed in the following equation:
The first component is the average variance of the individual probability distribution (denoted by \(\sigma_{i}^{2}\)) with its square root deemed to be a measure of “individual uncertainty.” The second term is the variance of the point estimates which are the means of the individual probability distribution and denoted by μi. This variance is used as a proxy for the degree of disagreement among survey participants about their point forecasts (or lack of consensus in the Zarnowitz-Lambros terminology).
We next define individual forecaster uncertainty in a similar way as the researchers just cited, i.e. the dispersion of a survey participant’s probability distribution of a macroeconomic variable, but instead of a measure of aggregate uncertainty, we consider the average individual uncertainty in each survey, as in Giordani and Soderlind (2003). The MAS survey does report aggregate probability distributions by averaging the probabilities from individual forecasters’ histograms, which can be the basis for constructing a measure of aggregate uncertainty. Nevertheless, we avoid the use of this measure due to the arbitrary way in which interpersonal subjective probabilities are combined. We also differ from the cited references by using the dispersion in the median of the individual probability distributions as a proxy for the lack of consensus among forecasters. Our definitions are mutually consistent in that they are based solely on the information contained in the probability distribution forecasts and make no use of point projections.Footnote 10
The probability distribution forecasts of annual GDP growth or CPI inflation reported by respondents in the MAS survey take the form of histograms with pre-assigned intervals and open-ended bins at the lower and upper ends of the distribution. As such, it provides a direct measure of subjective forecaster uncertainty, but the problem with the open-ended nature of the intervals needs to be addressed. As in Abel et al. (2016) and Li and Tay (2021), we resort to the use of percentile-based summary measures instead of moment-based statistics that entails fitting normal density functions to the individual histograms. We refrain from using this method in view of the fact many of the histograms are skewed. Besides, percentile-based measures have the advantage that they are invariant to how the open intervals are closed, as long as respondents do not place too much probability in either of them.
In this approach, the central tendency and spread of the individual probability distributions are measured, respectively, by the median (y(0.5)) and the central 68% range (y(0.84)–y(0.16)), where y(0.16), y(0.5) and y(0.84) are the 16th, 50th and 84th percentiles of the growth and inflation forecast probability distributions. The median of the distributions is preferred to the mean to ensure robustness of the central tendency to asymmetries in the forecast distribution. The range that we use has been called the “quasi-standard deviation” by Giordani and Soderlind (2003) and it has the attraction of being twice the standard deviation should the distribution be normal. To compute these percentiles, we assume uniform probabilities within the three bins that the individual percentiles fall into.
For forecaster i, we denote the median and central 68% range of his one-year ahead probability distribution forecasts of growth or inflation surveyed at time t as mi,t and ri,t, respectively. That is, the time series ri,t traces the evolution of forecaster i’s uncertainty over the sample period t = 2000Q1, 2000Q2,…, 2021Q4. For each survey, we then calculate the mean of the standard deviation measure (ri,t/2) across the panel of forecasters i = 1, 2,…, n to represent average forecaster uncertainty:
Next, we compute the standard deviation of the mi,t measure across forecasters in each survey as representing the lack of consensus among them (\(\mu_{t}^{m}\) is the mean of mi,t):
Finally, we compute the shares of these measures as follows:
The same computations are repeated for the two-year ahead probability distribution forecasts. In the next section, these measures are tracked over time and comparisons are made between the COVID-19 pandemic and the GFC.
4.2 Comparison of COVID-19 and GFC
To trace the evolution of consensus and uncertainty over various sub-periods, Figs. 3 and 4 present the time profiles of the Ct and Ut measures for economic growth and inflation rate forecasts from 2002Q1–2021Q4, where the series are plotted for all survey dates. A seasonal zigzag pattern is expected of the uncertainty series since with more data being released and fewer quarters to forecast as the fixed event approached when we go from the first quarter to the fourth quarter of each year, average uncertainty would diminish. Similarly, we expect to see a seasonal pattern in the lack of consensus series as forecasters tend to disagree less on their predictions when there is more information available. Hence, we present the seasonally adjusted version of the two measures by projecting the seasonality pattern out a priori from each time series through a regression on seasonal dummy variables. The top row of Figs. 3 and 4 displays the consensus and uncertainty measures without the seasonal component, while the bottom row of the two figures plots their shares.

Consensus and uncertainty measures for growth forecasts

Consensus and uncertainty measures for inflation forecasts
A first feature worth noticing in Fig. 3a, b is the general correspondence between the consensus and uncertainty measures. The correlations between them are 0.49 and 0.58 for the one- and two-year ahead growth forecasts, respectively. Another notable feature is that the lack of consensus statistic and the uncertainty measure are much less variable for inflation forecasts compared to growth predictions (see Fig. 4a, b). It is also evident from Figs. 3c, d, 4c, d that the consensus share is almost always lower than the uncertainty share even though both are standard deviation measures by construction. It appears that the level of disagreement among forecasters tends to be lower than their average level of uncertainty when forecasting GDP growth and CPI inflation.
Figure 3a shows the level of disagreement among survey respondents on their current and next year growth projections was generally stable except during the two crisis periods. However, a rising trend in the uncertainty of current year growth projections is set in from the start of the GFC until 2012, after which it reversed and uncertainty declined to low levels in 2018 and 2019. Then, COVID-19 struck, whereupon a sudden and sharp increase akin to a trend break occurred. In terms of its level, the uncertainty due to the pandemic was slightly higher than during the GFC but comparable to its aftermath, although the lack of consensus measure was lower.
The most surprising feature of the movements in the uncertainty of current year growth forecasts is the further increase in 2010 to 2011. This measure was higher after the financial crisis subsided than during the crisis itself, which could be due to the Eurozone sovereign debt crisis and the difficulty of forecasting the long-drawn recovery from the financial crisis. The sharp fall in disagreement among forecasters and uncertainty from 2017 to 2019 for both one- and two-year predictions at first glance seems anomalous given the rise of trade frictions between the USA and China. Nevertheless, their depressing effect on global economic activity appears to have led to lower growth forecasts and narrower official forecast ranges, which could have reduced the disagreement and lowered the uncertainty in private sector predictions.
Turning to the inflation forecasts, we see from Fig. 4a, b that the level of uncertainty for both horizons remained rather stable even with the occurrence of the COVID-19 crisis. Similarly, the level of disagreement over current and next year inflation projections were essentially unchanged during the pandemic. It is probably not evident to forecasters that the pandemic would change the low inflationary environment prior to the crisis, given the curtailment in demand arising from lockdowns and movement restrictions. Indeed, forecasts of inflation during the pandemic were unusually low—below 1% in the current year prediction. It appears that up until the end of 2021, inflationary expectations of the professional forecasters were well anchored. In terms of their relative share, the stability of both measures is also evident from Fig. 4c, d.
4.3 Subjective versus objective uncertainty
Following up on the preceding analysis of uncertainty and consensus during crises, this section poses the question of what caused changes in these measures among professional forecasters in Singapore. We approach the issue by first drawing a clear distinction between two uncertainty concepts: the “subjective” uncertainty measure extracted from the reported probability distributions of individual forecasters versus the “objective” uncertainty metrics constructed from observable macroeconomic developments. Our aim is to assess the relationship between these two types of uncertainty by correlating the survey measure to a recently developed proxy for the level of uncertainty in the macroeconomic and policy environment.
The proxy we use as our measure of objective uncertainty is the news-based Singapore Economic Policy Uncertainty Index (EPU) which starts in January 2003 and is produced by Baker et al. (2016). The EPU is a weighted average of the monthly economic policy uncertainty indexes of 21 countries, i.e. those measuring the relative frequency of own-country newspaper articles which discuss economic policy uncertainty.Footnote 11 Time-varying trade weights based on the sum of annual imports and exports between Singapore and each of the 21 countries are used for the computation of EPU. To link this objective measure of uncertainty to our subjective measures extracted from the MAS survey, we first convert the monthly EPU series to quarterly frequency by taking the average in each quarter and then scaling it by dividing the index by 100.
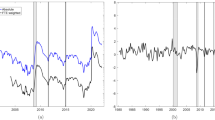
The EPU index is plotted with the current and next year “seasonally adjusted” uncertainty series for GDP growth in the top panel of Fig. 5.Footnote 12

EPU and uncertainty measures for growth forecasts
The relationship between the uncertainty measures and EPU is not easily discernible from the graphs, so we ran the following dynamic rolling regression with a four-year fixed window:
where \({\text{GDP}}_{t}^{u}\) denotes the (non-seasonally adjusted) uncertainty measure Ut when forecasting GDP growth; \(S_{i} , i = 1, 2, 3\) are seasonal dummy variables to capture the periodicity in the uncertainty series for the current year forecasts. To conserve degrees of freedom, we assume all parameters to be constant except the coefficient of EPUt which is allowed to be time-varying, and we ran the same equation for the next year predictions. The lagged dependent variable is included to allow for persistence in the time series. The plots of the estimated rolling regression coefficient β2t are juxtaposed in the lower panel of Fig. 5 and they suggest that the uncertainty measures, after accounting for seasonality, are most of the time positively correlated with EPU.
Insofar as crises are concerned, the correlations for both current and next year uncertainty are stronger during the COVID-19 pandemic. There is a significant fall in the uncertainty series in 2016 and 2017, a period of high uncertainty in the global economy caused by US President Donald Trump’s policies. The result is the negatively signed rolling regression coefficients seen in the figures.
5 Conclusions
Given the nature and scale of the COVID-19 crisis, it would be unsurprising if forecast failure occurred in the economic projections of Singapore’s professional forecasters. Indeed, the forecast error in predicting GDP growth during the COVID-19 pandemic does exceed that in normal times (but not during the GFC) for the one- and two-year ahead predictions. Using percentile-based summary measures of the forecast probability distributions associated with growth forecasts, we observe a trend break in subjective uncertainty among forecasters after the occurrence of the pandemic. The measure of uncertainty for next year predictions rose to a record high. This was simultaneously matched by a rise in an index that gauges the degree of uncertainty in the economic policy environment to its highest level in the last two decades, thereby demonstrating that the increase in forecasters’ subjective uncertainty was empirically grounded. This heightened level of objective uncertainty is a possible explanation for the forecasters’ tendency not to depart from the official forecast ranges and to exhibit herding behaviour during the COVID-19 pandemic.
Turning to inflation forecasting, forecast failure is detected particularly for the one-year ahead projections. The forecast error in the one-year ahead inflation predictions during the COVID-19 pandemic not only exceeds that in normal times but also during the GFC. Both the one- and two-year ahead forecasts of inflation were unusually low in both crises, as the forecasters exhibited leader-following and herding behaviour in these episodes. In contrast to growth forecasts, neither subjective uncertainty nor disagreement over inflation projections showed any increase during the pandemic. Taken together, these results suggest that the short-term inflation expectations of the survey respondents were strongly anchored throughout the sample period. In conclusion, we surmise from the paper’s findings that the difficulties in making economic forecasts during the pandemic did generally lead to forecast failure in both output growth and inflation in Singapore.
Notes
We refer to larger than usual forecast errors as a forecast failure.
The projections in the IMF’s World Economic Outlook of April and October 2020 provide good examples of how economists’ forecasts depended on epidemiological scenarios.
There is a strand in the literature on forecast evaluation that analyse forecast errors produced by international organizations with the aim of improving upon forecast accuracy (see, for example, Celasun et al. 2021).
New questions have been added recently although the older ones were retained.
Since the vintage data are not published, we are unable to gauge the extent of revisions. Upon request, the official statistical agency in Singapore has provided the information that the mean revision one year later of Singapore’s real annual GDP growth estimates is 0.4%-point with 2010 to 2020 as the reference period.
For instance, the official forecast ranges for 2020’s GDP growth are 4–7%, 6–7% and 6–7% in quarters one to three of 2020, respectively. Plots of the mid-points of the official forecast ranges are available from the authors upon request.
This test does not require knowledge of the information sets used by forecasters.
For the test to be viable, we combined the fixed event forecasts at all horizons.
As a robustness check, we compared our measure of lack of consensus with the standard deviation of point forecasts across the panel of respondents and found that they are very close to each other.
These are Australia, Brazil, Canada, Chile, China, Colombia, France, Germany, Greece, India, Ireland, Italy, Japan, Mexico, the Netherlands, Russia, South Korea, Spain, Sweden, the United Kingdom, and the USA. Their economic policy uncertainty indexes are normalized to a mean of 100 from 2007 to 2015.
The exercise is not carried out for the inflation uncertainty measure given the lack of data observations. In any case, the correlations between it and the EPU index are close to zero.
References
Abel J, Rich R, Song J, Tracy J (2016) The measurement and behavior of uncertainty: evidence from the ECB survey of professional forecasters. J Appl Econ 31:533–550
Alessi L, Ghysels E, Onorante L, Peach R, Potter S (2014) Central bank macroeconomic forecasting during the global financial crisis: the European Central Bank and Federal Reserve Bank of New York experiences. J Bus Econ Stat 32(4):483–500
Baker SR, Bloom N, Davis SJ (2016) Measuring economic policy uncertainty. Q J Econ 131(4):1593–1636
Boero G, Smith J, Wallis K (2008) Uncertainty and disagreement in economic prediction: the Bank of England Survey of external forecasters. Econ J 118:1107–1127
Boero G, Smith J, Wallis K (2015) The measurement and characteristics of professional forecaster’s uncertainty. J Appl Econom 30:1029–1046
Carriero A, Clark TE, Marcellino M, Mertens E (2021) Addressing COVID-19 outliers in BVARs with stochastic volatility. Manuscript, Deutsche Bundesbank
Celasun O, Lee J, Mrkaic M, Timmermann A (2021) An evaluation of world economic outlook growth forecasts, 2004–17. IMF Working Paper No. 21/216
Eichenbaum MS, Rebelo S, Trabandt M (2021) The macroeconomics of epidemics. NBER Working Paper 26882, Revised Version
Engelberg J, Manski CF, Williams J (2009) Comparing the point predictions and subjective probability distributions of professional forecasters. J Bus Econ Stat 27(1):30–34
Giordani P, Soderlind P (2003) Inflation forecast uncertainty. Eur Econ Rev 47:1037–1059
Holden K, Peel DA (1990) On testing for unbiasedness and efficiency of forecasts. Manch Sch Econ Soc Stud 58(2):120–127
Huber F, Koop G, Onorante L, Pfarrhofer M, Schreiner J (2020) Nowcasting in a pandemic using non-parametric mixed frequency VARs. J Econom 6:6
Keane M, Runkle D (1990) Testing the rationality of price forecasts: new evidence from panel data. Am Econ Rev 80:714–735
Kuzin V, Marcellino M, Schumacher C (2011) MIDAS versus mixed-frequency VAR: nowcasting GDP in the Euro Area. Int J Forecast 27:529–542
Kuzin V, Marcellino M, Schumacher C (2013) Pooling versus model selection for nowcasting GDP with many predictors: empirical evidence for six industrialized countries. J Appl Econom 28:392–411
Lamont OA (2002) Macroeconomic forecasts and microeconomic forecasters. J Econ Behav Organ 48(3):265–280
Lenza M, Primiceri GE (2020) How to estimate a VAR after March 2020. NBER Working Paper 27771
Lewis C, Pain N (2015) Lessons from OECD forecasts during and after the financial crisis. OECD Econ Stud 2014:9–39
Li Y, Tay A (2021) The role of macroeconomic and policy uncertainty in density forecast dispersion. J Macroecon 67:1–19
Monetary Authority of Singapore (2007) Assessing the performance of professional forecasters. Macroecon Rev 6(1):74–84
Monetary Authority of Singapore (2014) Do professional forecasts in Singapore contain useful information? Macroecon Rev 13(2):33–35
Ng S (2021) Modelling macroeconomic variations after COVID-19. NBER Working Paper 29060
Pons-Novell J (2003) Strategic bias, herding behaviour and economic forecasts. J Forecast 22:67–77
Primiceri GE, Tambalotti A (2020) Macroeconomic forecasting in the time of COVID-19. Manuscript, Northwestern University
Rülke JC, Silgoner M, Worz J (2016) Herding behavior of business cycle forecasters. Int J Forecast 32:23–33
Schorfheide F, Song D (2021) Real-time forecasting with a (standard) mixed-frequency VAR during a pandemic. NBER Working Paper 29535
Zarnowitz V (1992) Business cycles: theory, history, indicators, and forecasting. University of Chicago Press, Chicago
Zarnowitz V, Lambros LA (1987) Consensus and uncertainty in economic prediction. J Polit Econ 95(3):591–621
Acknowledgements
The authors are grateful for constructive suggestions from the journal referee, which led to significant improvements in the paper. We would also like to thank Josiah Lim Shi Jie for his excellent research assistance.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Hwee Kwan Chow declares that she has no conflict of interest. Keen Meng Choy declares that he has no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chow, H.K., Choy, K.M. Economic forecasting in a pandemic: some evidence from Singapore. Empir Econ 64, 2105–2124 (2023). https://doi.org/10.1007/s00181-022-02311-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00181-022-02311-8