
Abstract
In parametric stochastic frontier models, the composed error is specified as the sum of a two-sided noise component and a one-sided inefficiency component, which is usually assumed to be half-normal, implying that the error distribution is skewed in one direction. In practice, however, estimation residuals may display skewness in the wrong direction. Model respecification or pulling a new sample is often prescribed. Since wrong skewness may manifest as a finite sample problem, this paper proposes a finite sample adjustment to existing estimators to obtain the desired direction of residual skewness. This provides an alternative empirical approach to deal with the wrong skewness problem that does not require respecification of the model.
Similar content being viewed by others

Notes
Greene (2007, p.131) claims “In this instance, the OLS results are the MLEs, and consequently, one must estimate the one-sided terms as 0.”
For example, estimating the variance parameters in COLS is invalid in this case.
It may also be a consequence of a misspecified model, but that is not our focus here.
Waldman (1982, p. 278) also suggests that \((b,0,s^{2})\) may be a global maximum. There are two roots in this normal-half normal model: OLS \( (b,0,s^{2})\) and one at the MLE with positive \(\lambda \). When the residual skewness is positive, the first is superior to the second (Greene 2007, note 28).
Kumbhakar et al. (2013) propose a stochastic frontier model to accommodate the presence of both efficient and inefficient firms in the sample.
Waldman (1982, p.278) notes that for \(\sigma _{u}>0\) “as the sample size increases the probability that \(\sum e_{t}^{3}>0\) and hence that \( (b,0,s^{2})\) locates a local maximum goes to zero.”
Badunenko et al. (2012) find that the estimation of efficiency scores depends on the estimated ratio of the variation in efficiency to the variation in noise. As discussed by Kim et al. (2007) and Feng and Horrace (2012) in fixed effects stochastic frontier models, small signal-to-noise ratio leads to inaccurate inference.
As pointed out by Simar and Wilson (2010, p.72), this problem could happen in other one-sided specifications. In a previous version of this paper, our Monte Carlo experiments suggest that wrong skewness could also occur with high probability in exponential and binomial SPF models, when the signal-to-noise ratio is small.
This stems from the fact that Waldman (1982) shows that OLS is local maximum in the parameter space of MLE when the OLS residuals are positively skewed. In fact, the non-positivity constraint will bind globally (when the OLS residuals are positively skewed), if OLS is a global maximum, as the Monte Carlo studies of Olsen et al. (1980) suggest.
It is worth noting that (10) is not a direct linearization of (7). Alternatively, a full linearization of (7) can be similarly obtained by replacing \(R=\frac{1}{N}{\tilde{e}}^{\prime }M_{0}X\) with \(R=\frac{1}{N}({\tilde{e}}^{\prime }M_{0}-\sqrt{{\hat{\mu }}_{2}^{\prime }} {\hat{\mu }}_{3}^{\prime }e^{\prime })X\). The additional term \(-\frac{1}{N} \sqrt{{\hat{\mu }}_{2}^{\prime }}{\hat{\mu }}_{3}^{\prime }e^{\prime }X\) is from the effect of the denominator of the constraint in (7). Monte Carlo simulations suggest that the estimation results are robust to this choice. Details are available upon request.
In the empirical example below, the command Frontier in Stata, which allows for a linear constraint, is employed.
Table 1 in Simar and Wilson (2010) provides some guidance. On the one hand, when \(\lambda ^{2}\le 0.1\) (i.e., \(k=1/(\frac{\pi }{\pi -2}\frac{1}{\lambda ^{2}}+1)<0.035)\) for samples with size less than 200, the proportion of wrong skewness is close to \(50\%\), implying that the inefficiency term is hard to distinguish from noise. On the other hand, when \(\lambda ^{2}\ge 1\) (\(k\ge 0.267\)), the wrong skewness probability decreases dramatically. For example, only \(6\%\) of samples display wrong residual skewness for \(\lambda ^{2}=2\) (\(k=0.421\)) and \(N=200\). We have a similar finding both for Simar and Wilson’s design and the design in Sect. 5 of this paper. Results are available upon request.
The constraint \(k\ge k_{0}\) is always binding in the neighborhood of OLS. And a restriction on k is equivalent on \(\lambda \), which is a monotonic increasing function of k in the half-normal model,
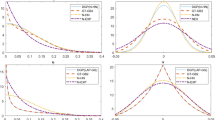
$$\begin{aligned} \lambda =\sqrt{\frac{\sigma _{u}^{2}}{\sigma _{v}^{2}}}=\sqrt{\frac{ Var(u_{i})}{\frac{\pi -2}{\pi }\sigma _{v}^{2}}}=\sqrt{\frac{k}{\frac{\pi -2 }{\pi }(1-k)}}=\sqrt{\frac{\pi }{\pi -2}\frac{1}{(1/k-1)}}. \end{aligned}$$Per a referee’s advice, we experimented with selecting \(k_0\) by minimizing the mean integrated squared error of the difference between the constrained and unconstrained residual densities, but the selection performed poorly in terms of the RMSE of the estimated coefficients in finite samples.
In this sense, our approach is different from the literature on models with moment conditions, e.g., Moon and Schorfheide (2009).
When N is large, the wrong skewness problem is less likely to occur unless the inefficiency variance ratio is very small. When it does occur in this setting, alternative approaches including respecification may be considered.
Strictly speaking, restricting \(\lambda \) as a constraint yields a different result from constraint (7). Though the population skewness is equal to \(g(k_{0})\) and thus a monotonic function of \(\lambda \), the sample skewness is not a function of \(\lambda \). However, the insights derived here on the effect of the chosen value of \(k_{0}\) on estimation still apply.
As pointed out by a referee, the second term on the right-hand side of (17) is a constant in X. See Papadopoulos (2018), pp. 338–339. This is due to the fact we only take a first-order Taylor expansion of \(\phi (\frac{\lambda }{\sigma }\varepsilon _{i})/ [1-\Phi (\frac{\lambda }{\sigma }\varepsilon _{i})]\). With higher-order terms included, constrained MLE and COLS involve additional terms.
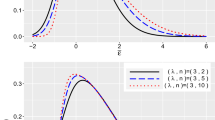
For a small value of \(k_{0}\), e.g., \(k_{0}\in [0.1,0.3]\), \(\lambda \) lies in the interval [0.5530, 1.0860].
Coelli (1995) also uses this signal-to-noise ratio measure, denoted by \( \gamma ^{*}\), in his Monte Carlo experiments.
Due to misspecification and small sample, the variance estimates with proposed method do not show a consistency property and may yield extreme estimates in some cases, for instance \(N=200\) with \(k=0.5\).
With the exception of perhaps Green and Mayes (1991), Mester (1997), and Parmeter and Racine (2012), there appear to be very few empirical studies with wrong skewness in the literature. As in Greene (2007, Table 2.11), we use this panel data example as a cross-sectional one only for the purpose of illustration.
Inconsistent with the statements of Waldman (1982) and Greene (2007), the MLE with positive \(\lambda \) achieves a slightly bigger value of log-likelihood than OLS for this dataset. Similarly, the inconsistency between OLS and MLE in the presence of positive OLS residual skewness by using FRONTIER is discussed by Simar and Wilson (2010). Greene (2007, p. 202) notes: “... for this data set, and more generally, when the OLS residuals are positively skewed, then there is a second maximizer of the log-likelihood, OLS, that may be superior to the stochastic frontier.”
This property can be obtained by the equation (3) in Waldman (1982, p.278):
$$\begin{aligned} \Delta l=\frac{\mu ^{3}}{6s^{3}}\sqrt{\frac{2}{\pi }}\frac{\pi -4}{\pi } \sum \limits _{i=1}^{N}e_{i}^{3} \end{aligned}$$where \(\mu \) can be regarded as \(\lambda \) changing from 0 as in the analysis in Sect. 3.1. Since \(\pi -4<0\), in the presence wrong skewness \( (\sum \nolimits _{i=1}^{N}e_{i}^{3}>0\)), the log-likelihood decreases with the imposed value of \(\lambda \) (and \(k_{0}\)).
The constant term is calculated by OLS intercept plus \(\sqrt{2{\hat{\sigma }} _{u}^{2}/\pi }\). The standard errors formula of the COLS estimators of constant term, \(\sigma ^{2}\) and \(\gamma \) (not \(\lambda \)) can be found in Coelli (1995).
References
Aigner DJ, Lovell CAK, Schmidt P (1977) Formulation and estimation of stochastic frontier production function models. J Econ 6:21–37
Amemiya T (1985) Advanced econometrics. Harvard University Press, Cambridge
Almanidis P, Sickles RC (2011) The Skewness issue in stochastic frontier models: fact of fiction? In: van Keilegom I, Wilson PW (eds) Exploring research frontiers in contemporary statistics and econometrics. Springer, Berlin
Almanidis P, Qian J, Sickles R (2014) 2014, Stochastic Frontier with Bounded Efficiency. In: Sickles RC, Horrace WC (eds) Festschrift in Honor of Peter Schmidt: Econometric Methods and Applications. Springer Science & Business Media, New York, NY, pp 47–81
Badunenko O, Henderson D, Kumbhakar S (2012) When, where and how to perform efficiency estimation. J Roy Stat Soc Ser A 175:863–892
Bai J, Ng S (2002) Determining the number of factors in approximate factor models. Econometrica 70:191–221
Carree M (2002) Technological inefficiency and the skewness of the error component in stochastic frontier analysis. Econ Lett 77:101–107
Coelli T (1995) Estimator and hypothesis tests for a stochastic frontier function: a MonteCarlo analysis. J Prod Anal 6:247–268
Coelli T (1996) A guide to frontier version 4.1: a computer program for stochastic frontier production and cost function estimation, CEPA working paper No. 96/07, Centre for efficiency and productivity analysis, University of New England, Arimidale, NSW 2351, Australia
Feng Q, Horrace WC (2012) Alternative technical efficiency measures: skew, bias and scale. J Appl Econ 27:253–268
Green A, Mayes D (1991) Technical inefficiency in manufacturing industries. Econ J 101:523–538
Greene W (1980) On the estimation of a flexible frontier production model. J Econ 3:101–115
Greene W (1995) LIMDEP Version 7.0 User’s Manual. Econometric Software, Inc, New York
Greene W (2007) The econometric approach to efficiency analysis. In: Fried HO, Lovell CAK, Schmidt S (eds) The measurement of productive efficiency: techniques and applications. Oxford University Press, New York
Greene W (2012) Econometric analysis, 7th edn. Pearson, London
Hafner C, Manner H, Simar L (2019) The “Wrong Skewness” problem in stochastic frontier models: a new approach. Econ Rev 37:380–400
Horrace WC, Wright IA (2020) Stationary points for stochastic frontier models. J Bus Econ Stat 38(3):516–526
Kim M, Kim Y, Schmidt P (2007) On the accuracy of bootstrap confidence intervals for efficiency Levels in Stochastic Frontier Models with Panel Data. J Prod Anal 28:165–181
Kumbhakar S, Lovell K (2000) Stochastic frontier analysis. Cambridge University Press, Cambridge
Li Q (1996) Estimating a stochastic production frontier when the adjusted error is symmetric. Econ Lett 52:221–228
Kumbhakar S, Parmeter C, Tsionas E (2013) A zero inefficient stochastic frontier model. J Econ 172:66–76
Meeusen W, van den Broeck J (1977) Efficiency estimation from cobb-douglas production functions with composed error. Int Econ Rev 18:435–444
Mester LJ (1997) Measuring efficiency at us banks: accounting for heterogeneity is important. Eur J Oper Res 98:230–242
Moon HR, Schorfheide F (2009) Estimation with overidentifying inequality moment conditions. J Econ 153:136–154
Olson J, Schmidt P, Waldman DM (1980) A monte carlo study of estimators of stochastic frontier production functions. J Econ 13:67–82
Papadopoulos A (2018) The two-tier stochastic frontier framework: theory and applications, models and tools. Ph.D. Thesis, Athens University of Economics and Business
Parmeter CF, Racine JS (2012) Smooth constrained frontier analysis. In: Recent advances and future directions in causality, prediction, and specification analysis: essays in Honor of Halbert L. White Jr., edited by X. Chen and N.E. Swanson, Chapter 18, pp 463–489, Springer, New York
Simar L, Wilson PW (2010) Inferences from cross-sectional stochastic frontier models. Econ Rev 29:62–98
Stevenson R (1980) Likelihood functions for generalized stochastic frontier estimation. J Econ 13:58–66
Waldman D (1982) A stationary point for the stochastic frontier likelihood. J Econ 18:275–279
Wang WS, Schmidt P (2009) On the distribution of estimated technical efficiency in stochastic frontier models. J Econ 148:36–45
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Feng and Wu acknowledge financial support of the MOE AcRF Tier 1 Grant M4012113 at Nanyang Technological University.
Appendix: Constrained COLS
Appendix: Constrained COLS
Proof of Proposition 1
As defined in Sect. 3, the constrained COLS is the restricted least squares with the linear constraint
where \(R=\frac{1}{N}{\tilde{e}}^{\prime }M_{0}X\) and \(q(k_{0})=R{\hat{\beta }} _\mathrm{OLS}+\frac{{\hat{\mu }}_{3}^{\prime }}{3}+\frac{\Pi }{3}k_{0}^{3/2}({\hat{\mu }} _{2}^{\prime })^{3/2}\), with the slope estimator
and the corresponding sum of squared residuals
where \({\hat{\beta }}_\mathrm{OLS}=(X^{\prime }X)^{-1}X^{\prime }y\). Thus,
Given the facts that \({\hat{\mu }}_{3}^{\prime }>0\) in the presence of wrong skewness, the scalar
In addition,
and the scalar \(R(X^{\prime }X)^{-1}R^{\prime }>0\) since the matrix \( X^{\prime }X\) is positive definite. Therefore,
\(\square \)
Since \(C(k_{0})=\frac{1}{N}SSR_{r}(k_{0})-k_{0}{\hat{\sigma }}_{\varepsilon }^{2}\frac{\ln N}{N}\), the FOC is
or
Substituting \(R{\hat{\beta }}_\mathrm{OLS}-q(k_{0})=-[\frac{{\hat{\mu }}_{3}^{\prime }}{3} +\frac{\Pi }{3}k_{0}^{3/2}({\hat{\mu }}_{2}^{\prime })^{3/2}]\) and \(\frac{ dq(k_{0})}{dk_{0}}=\frac{1}{2}({\hat{\mu }}_{2}^{\prime })^{3/2}\Pi k_{0}^{1/2}\) into the equation above, we obtain
The LHS \(k_{0}^{2}+\frac{1}{\Pi }\frac{{\hat{\mu }}_{3}^{\prime }}{({\hat{\mu }} _{2}^{\prime })^{3/2}}k_{0}^{1/2}\) is a monotonic increasing function of \( k_{0}\), with a minimum 0 at \(k_{0}=0\) and a maximum of \(1+\frac{1}{\Pi } \frac{{\hat{\mu }}_{3}^{\prime }}{({\hat{\mu }}_{2}^{\prime })^{3/2}}\) at \(k_{0}=1\) . Since the OLS residual skewness \(\frac{{\hat{\mu }}_{3}^{\prime }}{({\hat{\mu }} _{2}^{\prime })^{3/2}}\) is usually a very small positive number in the presence of wrong skewness, \(1+\frac{1}{\Pi }\frac{{\hat{\mu }}_{3}^{\prime }}{( {\hat{\mu }}_{2}^{\prime })^{3/2}}\) is slightly bigger than 1.
Consider the RHS \(\frac{3}{\Pi ^{2}}\frac{{\hat{\sigma }}_{\varepsilon }^{2}}{( {\hat{\mu }}_{2}^{\prime })^{3}}\frac{\ln N}{N}\cdot N[R(X^{\prime }X)^{-1}R^{\prime }]\). It is positive. In addition, the positive scalar
where \(P_{X}\iota =\iota \) and \({\tilde{e}}^{\prime }\iota =N{\hat{\mu }} _{2}^{\prime }\). We normalize \({\tilde{e}}\) by dividing it by its average \( {\hat{\mu }}_{2}^{\prime }\), i.e., \(\mathring{e}={\tilde{e}}/{\hat{\mu }} _{2}^{\prime }\) , such that \(\mathring{e}^{\prime }\iota ={\tilde{e}}^{\prime }\iota /{\hat{\mu }}_{2}^{\prime }=N\). Thus,
Since for a large N,
we obtain,
For a relatively large sample size N, RHS falls into the unity interval, implying the existence of \({\hat{k}}_{0}\) as the solution to \(\min _{k_{0}\in [ 0,1)}C(k_{0})\).
Uniqueness of \({\hat{k}}_{0}\) is guaranteed by the second-order condition. The second-order derivative of \(C(k_{0})\) is
for any \(0<k_{0}<1\) since OLS residual skewness \(\frac{{\hat{\mu }}_{3}^{\prime }}{({\hat{\mu }}_{2}^{\prime })^{3/2}}>0\) in the presence of wrong skewness.
Rights and permissions
About this article

Cite this article
Cai, J., Feng, Q., Horrace, W.C. et al. Wrong skewness and finite sample correction in the normal-half normal stochastic frontier model. Empir Econ 60, 2837–2866 (2021). https://doi.org/10.1007/s00181-020-01988-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00181-020-01988-z