
Abstract
The primary module of Quality Function Deployment (QFD) is the House of Quality (HoQ), which supports the design of new products and services by translating customer requirements (CRs) into engineering characteristics (ECs). Within the HoQ framework, the traditional technique for prioritizing ECs is the independent scoring method (ISM), which aggregates the weights of the CRs and the relationships between CRs and ECs (i.e., null, weak, medium, and high) through a weighted sum. However, ISM incorporates two questionable operations: (i) an arbitrary numerical conversion of the relationships between CRs and ECs, and (ii) the “promotion” of these relationships from ordinal to cardinal scale. To address these conceptual shortcomings, this paper introduces a novel procedure for prioritizing ECs, inspired by the Thurstone’s Law of Comparative Judgment (LCJ). This procedure offers a solution that is conceptually sound and practical, overcoming the conceptual shortcomings of ISM, while maintaining its simplicity, flexibility, and ease of implementation. The proposed approach is supported by a realistic application example illustrating its potential.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
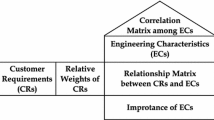
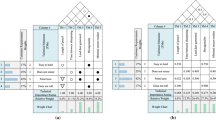
Quality Function Deployment (QFD) is a commonly used methodology for facilitating customer-oriented design of new products and services (Franceschini 2001). The initial module of QFD, known as the House of Quality (HoQ), aims to translate the customer requirements (CRs) of a new product/service into engineering characteristics (ECs), i.e., technical design features that directly impact the CRs (Zare Mehrjerdi 2010). Figure 1a exemplifies the HoQ’s relationship matrix with CRs and ECs indicated in rows and columns; the symbols in Fig. 1b represent the intensities of the relationships between ECs and CRs. Additionally, a weight (\({w}_{{CR}_{i}}\)) is assigned to each i-th CR, reflecting its importance from three complementary perspectives: final customer, corporate brand image, and improvement goals for the new product/service in relation to existing counterparts in the market (Akao 1994; Franceschini and Maisano 2018).

a Relationship matrix and EC prioritization using the independence scoring method (ISM). b Intensity of the relationships between ECs and CRs, and conventional conversion into numerical coefficients (rij)
Several actors participate in the QFD construction. The leading role is played by the members of the QFD team, i.e., a working group consisting of experts from the company of interest, with complementary skills ranging from marketing, design, quality, production, maintenance, etc. Another important role is played by a sample of interviewed respondents—i.e., (potential) end users who contribute to the collection of the so-called voice of the customer (VoC)—from which the QFD team extrapolates the HoQ’s CRs (Akao 1994; Franceschini and Rossetto 1995). To effectively identify the VoC, which is foundational to the whole QFD process, it is needed to meticulously select interviewees. This selection should be based on both the quantity and the quality of participants, ensuring that they possess a comprehensive understanding of the product or service under consideration, even if not from a technical standpoint. Concurrently, the QFD team members are expected to bring their specialized technical knowledge to the table, facilitating collaborative decision-making throughout the design and development stages. This approach, as outlined by Akao (1994) and Huang et al. (2022), is integral to the traditional HoQ construction method, which aims to equitably distribute tasks among all involved parties. Thus, while there may be room for enhancing the traditional HoQ, it would be ill-advised to alter the fundamental (largely manual) methods of data gathering that are familiar to the above-mentioned groups. This stance, however, does not preclude the possibility of refining the data processing stage, provided that the initial data collection methods remain unchanged.
Returning to the traditional QFD construction method, ECs should be prioritized considering their impact on the final customer; in general, ECs that have relatively intense relationships with CRs characterized by relatively high \({w}_{{CR}_{i}}\) values deserve more attention during the design phase. The conventional approach for prioritizing ECs is the so-called independence scoring method (ISM), which is a weighted sum of the coefficients (rij) derived from the numerical conversion of the relationship matrix symbols (see Fig. 1b), utilizing the \({w}_{{CR}_{i}}\) values as weights (Akao 1994). The resulting EC weight can be determined by Eq. 1, as exemplified in the lower part of Fig. 1a:
However, the ISM method incorporates two conceptually questionable operations: (i) an inherently arbitrary conversion of the relationship intensities (defined on an ordinal scale: ∅ < \(\Delta\) < \(\bigcirc\) < ●) into conventional numerical coefficients (rij: ∅ → 0, \(\Delta\)→ 1, \(\bigcirc\) → 3, ● → 9, cf. Figure 1b), and (ii) the aggregation of rij values through a weighted sum, which introduces an (undue) promotion to a cardinal scale with meaningful intervals (Franceschini et al. 2015). These questionable transformations can result in a distorted prioritization of ECs (Lyman 1990).
To address these conceptual shortcomings, this paper proposes a novel technique for prioritizing ECs based on Thurstone’s Law of Comparative Judgment (LCJ) (Thurstone 1927). Some advantages of the LCJ are that this technique is well-established, conceptually rigorous, effective and robust in practice (Maranell, 1974; Brown and Peterson 2009; Kelly et al. 2022). The integration of the LCJ into the new procedure and the integration of some “dummy” ECs (see Sect. 5) will enable the prioritization of ECs on a cardinal scale (Franceschini et al. 2022).
The remainder of this article is organized into five sections. Section 2 contains a brief review of the state-of-art techniques for prioritizing ECs that are alternative to ISM. Section 3 illustrates a case study that will accompany the description of the new procedure. Section 4 briefly recalls the LCJ, illustrating its underlying assumptions and practical application. Section 5 provides a step-by-step description of the proposed procedure, accompanied by an application example referring to the case study introduced in Sect. 3. The concluding section summarizes the major contributions of this research, its practical implications, limitations and insights for future development.
2 Literature review
Although ISM is the most widely used technique for EC prioritization, it has some shortcomings documented in a plurality of scientific contributions. In addition to (i) the arbitrary numerical conversion of the relationship matrix coefficients and (ii) the undue promotion of their ordinal scale into a cardinal one (cf. Figure 1b), there are other shortcomings, such as the fact that EC weights may not be consistent with CR weights. The latter shortcoming has inspired a corrective normalization (Lyman 1990) that, however, does not resolve the previous two.
The scientific literature includes multiple alternative techniques that aim to overcome the weaknesses of ISM and expand its scope. At the risk of oversimplifying, these techniques can be synthesized into three macro-categories (Franceschini et al. 2022).
-
1.
Rule-based techniques. Practical techniques achieve a computationally simple, intuitive, and satisfactory prioritization of ECs, which is not necessarily the optimal one (assuming it exists). In some operational contexts, these techniques are classified as “heuristic” or “experience-based”. Let us recall, for example, Borda’s method or other techniques based on pairwise comparisons (Dym et al. 2002), and another technique (called ordinal prioritization method) based on the adaptation of a model proposed by Yager to the HoQ context (Franceschini et al. 2015; Galetto et al. 2018; Yager 2001).
-
2.
Multi-criteria decision-making (MCDM) techniques. EC prioritization can be also seen as an MCDM problem involving conflicting CRs. Several MCDM techniques have been used in previous studies to improve the performance of QFD (Huang et al. 2022; Ping et al. 2020). Let us recall for example the application of the ELECTRE-II (ÉLimination Et Choix Traduisant la REalité) method (Liu and Ma 2021) or the EDAS approach (evaluation based on distance from average solution) (Ghorabaee et al. 2015; Mao et al. 2021).
-
3.
Techniques based on fuzzy logic. These techniques, which could also be interpreted as advanced heuristics, take into account the inherent uncertainty in the formulation of CR-importance judgments (by interviewed respondents) or in the formulation of relationship matrix intensities (by QFD team members). For example, the techniques proposed by Li et al. (2019) and Shi et al. (2022) apply to the open design contest, in which the intensity of relationships between CRs and ECs and the prioritization of ECs are inferred on the basis of linguistic variables and text-format information, describing the subjective imprecision of human cognition.
Most of the aforementioned techniques require additional information beyond that collected in the traditional QFD process. For example, techniques to handle information related to linguistic variables require verbatim transposition of interviews that were conducted in open-ended form (Li et al. 2019); most of the techniques based on fuzzy logic require some technical expertise in setting working parameters, such as thresholds or weights. The procedure proposed in this paper—which can be referred to as “distribution-based” since it relies on statistical assumptions regarding the distribution of the QFD team preferences (Franceschini et al. 2022)—fits the information contained in the classic HoQ and can also be implemented and automated by non-experts (cf. Section 5).
3 Test case
Referring to an application example adapted from the scientific literature (Franceschini et al. 2015), let us consider a company of mountain sports accessories that plans to design a new model of climbing safety harness through the QFD. Figure 2 illustrates the HoQ that was constructed by combining information obtained through interviews with a sample of respondents (i.e., potential end users) and from the technical examination of QFD team members (i.e., corporate staff with technical and design expertise). Eight CRs and eight ECs were identified.Footnote 1 The \({w}_{{CR}_{i}}\) values inherently may take into account information concerning the CR importance to final customers, corporate brand image, and improvement goals, combining them through a multiplicative aggregation model (Franceschini 2001; Franceschini and Maisano 2018). For simplicity, Fig. 2 shows only the \({w}_{{CR}_{i}}\) values, omitting the three CR-importance contributions mentioned above. Next, ECs are prioritized, determining the \({w}_{{EC}_{j}}\) values reported in the lower part of Fig. 2 through the ISM (cf. Equation 1). This HoQ will be used as a test case to illustrate the new EC prioritization procedure step-by-step (cf. Section 5). The concluding part compares the results of the new prioritization procedure with those derived from the traditional ISM.

4 Basics of the law of comparative judgment
The very general problem in which Thurstone’s LCJ finds application is summarized as follows: a set of experts formulate their individual (subjective) judgments about a specific attribute of some objects and these judgments must be merged into a collective one (Maranell, 1974; Kelly et al. 2022). The attribute can be defined as “a specific feature of objects, which evokes a subjective response in each expert”. Consider, for example, the intensity of the aroma (attribute) of some alternative coffee blends (objects), which are assessed by a panel of experienced café customers (experts).
In this scenario, Thurstone (1927) postulated the existence of a psychological continuum, i.e., “an abstract and unknown unidimensional scale, in which the position of the objects is directly proportional to their degree of the attribute of interest”. Although the psychological continuum is a unidimensional imaginary scale, the LCJ can be used to approximate the position of the objects of interest on it. According to the so-called case V of Thurstone’s LCJ, the position of a generic j-th object (ECj) is in fact postulated to be distributed normally: ECj ~ N(\({\mu }_{{EC}_{j}}\), \({\sigma }_{{EC}_{j}}^{2}\)), where \({\mu }_{{EC}_{j}}\) and \({\sigma }_{{EC}_{j}}^{2}\) are the unknown mean value and variance of that object’s attribute.Footnote 2 Figure 3 represents the hypothetical distributions of the position of any two generic objects, \({EC}_{j}\) and \({EC}_{k}\). The distribution associated with a given object is characterized by a dispersion (or variance), which reflects the intrinsic expert-to-expert variability in positioning (albeit indirectly, as we will better understand below) that object on the psychological continuum. Let \({\mu }_{{EC}_{j}}\) and \({\mu }_{{EC}_{k}}\) correspond to the (unknown) expected values of the two objects and \({\sigma }_{{EC}_{j}}^{2}\) and \({\sigma }_{{EC}_{k}}^{2}\) the (unknown) variances. The difference \(\left({EC}_{j}-{EC}_{k}\right)\) will follow a normal distribution with parameters:
where:

Theoretical distributions of the position of two generic objects (i.e., \({EC}_{j}\) and \({EC}_{k}\)) in the psychological continuum. b Graphical representation of the quantity (\({{1} - {p}_{jk}}\)), being \({p}_{jk}\; =\;P[{\left({{EC}_{j}} - {{EC}_{k}}\right)\geq{0}}]\)
\({\mu }_{{EC}_{j}}\) and \({\mu }_{{EC}_{k}}\) denote the (unknown) mean values of \({EC}_{j}\) and \({EC}_{k}\) in the psychological continuum;
\({\sigma }_{{EC}_{j}}^{2}\) and \({\sigma }_{{EC}_{k}}^{2}\) denote the (unknown) variances of \({EC}_{j}\) and \({EC}_{k}\);
\({\rho }_{{EC}_{j},{ EC}_{k}}\) denotes the (unknown) correlation between objects \({EC}_{j}\) and \({EC}_{k}\).
Considering the area subtended by the distribution of \(\left({EC}_{j}-{EC}_{k}\right)\), let us draw a vertical line passing through the point with \({EC}_{j}-{EC}_{k}=0\) (see Fig. 3b). The area to the right of the line depicts the observed proportion of times (\({p}_{jk}\)) that \({EC}_{j}\ge {EC}_{k}\) or \(\left({EC}_{j}-{EC}_{k}\right)\ge 0\). Of course, the area to the left depicts the complementary proportion \(\left({1-p}_{jk}\right)\).
In addition, it is postulated that the variances of the objects are all equal (\({\sigma }_{{EC}_{1}}^{2}={\sigma }_{{EC}_{2}}^{2}= \dots ={\sigma }^{2}\)) and the intercorrelations (in the form of Pearson coefficients \({\rho }_{{EC}_{j}{, EC}_{k}}\)) between pairs of objects (\({EC}_{j}\), \({EC}_{k}\)) are all equal too (\({\rho }_{{EC}_{j}{, EC}_{k}}=\rho , \forall j,k\)).
Having outlined this framework, let us now focus on the LCJ's application, which is based on the following four steps:
-
1.
A set of experts (j1, j2, …) formulate their preferences for each object (ECj) versus every other object (ECk), considering all possible \({C}_{2}^{m}\)= m∙(m – 1)/2 pairs, m being the total number of objects. In practice, the following question needs to be answered: “How do you judge the degree of the attribute of ECj compared to that of ECk, in relative terms?”. Judgments are expressed through relationships of strict preference (e.g., “EC1 > EC2” or “EC1 < EC2”) or indifference (e.g., “EC1–EC2”). Results are then aggregated into a proportion matrix (P). Precisely, for each possible paired comparison between two objects (ECj and ECk), the conventional portion of experts who prefer the first object to the second one is determined as:
$$p_{{jk}} = 1 \cdot p_{{jk}}^{{^{{( > )}} }} + {1 \mathord{\left/ {\vphantom {1 2}} \right. \kern-\nulldelimiterspace} 2} \cdot p_{{jk}}^{{^{ (\sim) } }} + 0 \cdot p_{{jk}}^{{^{{( < )}} }} , \in \left[ {0,1} \right],$$(3)\({p}_{jk}^{(>)}\) being the portion of experts for whom ECj > ECk,
\({p}_{jk}^{(\sim )}\) being the portion of experts for whom ECj ~ ECk,
\({p}_{jk}^{(<)}\) being the portion of experts for whom ECj < ECk.
It can be noted that \({p}_{jk}\) is the same quantity represented in Fig. 3b. The LCJ allows for its quantification on the basis of the (empirical) expert judgments.
The coefficient “½” multiplying \({p}_{jk}^{(\sim )}\) conventionally weighs the indifference relationship as an intermediate coefficient between that related to the “favourable” (“ECj > ECk”) strict preference relation (with coefficient “1”) and that related to the “unfavourable” (“ECj < ECk”) strict preference relation (with coefficient “0”). Taking into account that \({p}_{jk}^{(\sim )}={p}_{kj}^{(\sim )}\), this type of weighting guarantees the complementarity relationship:
$${p}_{jk}=1-{p}_{kj},$$(4)which can be demonstrated by combining Eq. 3 with the two following relationships:
$${p}_{jk}^{\left(>\right)}+{p}_{jk}^{\left(\sim \right)} +{p}_{jk}^{\left(<\right)}=1,$$(5) -
2.
Next, pjk values are transformed into zjk values, through the relationship:
$$z_{jk}\, = \,{\Phi }^{ - 1} \left( {1{ }{-}{ }p_{jk}} \right)$$(6) -
3.
Φ−1(·) being the reverse of the cumulative distribution function (Φ) of the standard normal distribution. The element zjk represents a unit normal deviate, which will be positive for all values of (1 – pjk) over 0.50 and negative for all values of (1 – pjk) under 0.50.
-
4.
In general, objects are judged differently by experts. However, if all experts express the same preference for each outcome, the model is no more viable (pjk values of 1.00 and 0.00 would correspond to zjk values of \(\pm \infty\)). A simplified approach for tackling this problem is to associate those pjk values ≤ 0.00135 with zjk = Φ−1(1–0.00135) = 3 and those pjk values ≥ 0.99865 with zjk = Φ−1 (1 – 0.99865) = − 3. More sophisticated solutions to deal with this issue have been proposed (Franceschini et al. 2022).
Next, the zjk values related to the possible paired comparisons are reported into a matrix Z. The element zjk is reported in the j-th row and k-th column. The relationship zkj = −zjk holds, being unit normal deviates related to complementary cumulative probabilities (cf. Equation 4).
A scaling can be performed by (i) summing the values into each column of the matrix Z and (ii) dividing these sums by m. It can be demonstrated that the result obtained for each k-th column (xk) corresponds to the unknown average value (\({\mu }_{{EC}_{k}}\)) of the k-th object’s attribute, up to a positive scale factor and an additive constant: \({x}_{k}={\sum }_{k}\left({z}_{jk}\right)/m={c}_{1}\cdot {\mu }_{{EC}_{k}}+{c}_{2}\). In other words, the LCJ results into an interval scaling, i.e., objects are defined on a scale (x) with arbitrary zero point and unit (Thurstone 1927; Franceschini et al. 2022).
5 Methodological approach
The LCJ can be adapted for prioritizing the ECs within the HoQ context. In this case, the focus is on the ECs (i.e., objects), which need to be prioritized according to the degree of intensity (i.e., attribute) of their relationships with each specific CR. Unlike the traditional application of LCJ, where individual experts formulate paired comparisons of objects, in this context paired comparisons emerge indirectly from the HoQ's relationship matrix. This approach represents a departure from the traditional LCJ method, since experts do not make individual judgements that are then aggregated. Instead, in the new procedure, several expert judgements—derived from the collective compilation of the relationship matrix by the QFD team members (Zare Mehrjerdi 2010)—are then aggregated through the LCJ. This point is clarified in the explanation below, which is structured in four steps (a, b, c and d).
(a) Transformation of relationship matrix into rankings Focusing on the i-th specific row of the relationship matrix, a ranking of ECs can be determined according to the degree of their relationships with the i-th CR. For example, with reference to the relationship matrix in Fig. 2 and to “CR6—Lightweight”, the following ranking can be obtained: ∙
In addition to the “regular” ECs, i.e., EC1 to EC8, the above ranking also includes four “dummy” or “anchor” ECs, i.e., EC●, \({{EC}}_{\bigcirc } ,{{EC}}_{\Delta } ,{{ and}}\;{{EC}}_{\emptyset }\), which represent the degree of intensity of the relationships expressed in the relationship matrix, espresso in absolute terms (“None” → \(\varnothing\), “Low” → \(\Delta\), “Medium” → \(\bigcirc\), and “High” → ●; cf. Figure 1b). The introduction of these objects in the rankings, which by their nature are formulated in relative terms, is necessary in order not to lose part of the available information content: that is, the degree of intensity of the relationships in absolute terms. For example, referring to the new simplified relationship matrix in Fig. 4 (which is different from that in the test case in Fig. 2), the relationships of the three ECs (EC1, EC2 and EC3) with CR1 (i.e., \({EC}_{1}\to ,{EC}_{2}\to \varnothing ,{EC}_{3}\to \varnothing\)) result into the ranking \({EC}_{1}>\left({EC}_{2}\sim {EC}_{3}\right),\) which would be identical to that obtained by considering the relationships of the same ECs with CR2 (i.e., \(EC_{1} \to \bigcirc ,EC_{2} \to {\Delta } ,EC_{3} \to \Delta\)). In this case, the transformation into relative rankings leads to losing information about the absolute degree of intensity of individual relationships, which distinguishes the two configurations.

Transformation of a relationship matrix into EC rankings, with or without dummy ECs (i.e., EC●, \({{EC}}_{\bigcirc } ,{{EC}}_{\vartriangle } ,{{ and}}\;{{EC}}_{\emptyset }\))
Referring to the LCJ framework, similarly to regular ECs, dummy ECs are assumed to project a normal distribution on the psychological continuum, with unknown mean value and unknown variance, equal to that of the other objects (cf. Section 4) (Franceschini and Maisano 2019). The dummy objects are also used to perform the so-called “anchoring” of the scaling resulting from the LCJ, as described below.
(b) Transformation of rankings into paired comparison relationships. Each ranking can be uniquely translated into paired comparisons. Figure 5 exemplifies this process for each CR in the relationship matrix. Since the test case includes twelve total ECs—i.e., eight regular (EC1 to EC8) and four dummy ones (EC●\({{EC}}_{\bigcirc } ,{{EC}}_{\Delta } ,{{ and}}\;{{EC}}_{\emptyset }\))—the total paired comparisons are \({C}_{2}^{12}=\left(\begin{array}{c}12\\ 2\end{array}\right)=\frac{12\cdot 11}{2}=66.\)

Transformation of the relationship matrix in (a) into EC rankings (b) and paired comparison relationships (c)
(c) LCJ application. Next, a proportion (pjk) must be associated with each jk-th paired comparison. In the traditional LCJ (cf. Section 4), pjk reflects the portion of expert population that expressed a preference of object ECj over object ECk(Footnote 3). Although experts do not directly express their preferences between pairs of ECs, for each CR in the relationship matrix (which was collectively constructed by the QFD team members), an EC ranking can be determined as illustrated in Fig. 4; then, this ranking can be decomposed into paired comparisons between ECs.
Additionally, each CR in the HoQ corresponds to a certain percentage weight (i.e., \({w}_{{CR}_{i}}\), being \(\sum_{\forall i}{w}_{{CR}_{i}}=1\)), which describes its importance from different points of view (cf. Section 3). This weight can also be associated with the relative EC ranking and the paired comparison relationships resulting from it. For a given (jk-th) comparison between pairs of ECs, there are therefore as many paired comparison relationships as the number of CRs (with their associated weights). Figure 5 exemplifies the process of constructing paired comparison relationships from the relationship matrix in Fig. 2.
Adapting the LCJ (cf. Section 4), the pjk proportions can be determined by aggregating the preceding comparisons by means of a weighted sum; before showing this aggregation, for the sake of clarity, it is appropriate to take a step back.
With reference to each i-th CR and each jk-th paired comparison (i.e., ECj versus ECk), the following three binary coefficients are defined:
It can be seen that these coefficients are mutually exclusive and the complementarity relationship holds: \({c}_{i,jk}^{\left(>\right)}+{c}_{i,jk}^{\left(\sim \right)} +{c}_{i,jk}^{\left(<\right)}=1\). A general coefficient expressing the degree of preference of ECj over ECk from the perspective of the i-th CR can be defined as:
Note the similarity between Eqs. 3 and 9; by construction, it results that: \({c}_{i,jk}=1-{c}_{i,kj}\). Figure 6 exemplifies the calculation of the binary coefficients and the corresponding \({c}_{i,jk}\) values, for the paired comparison relationships in Fig. 5c.

Calculation of the \({c}_{i,jk}\) values (bolded) by combining the binary coefficients \({{c}_{i,jk}^{\left(>;\right)}}, {{c}_{i,jk}^{\left(\sim\right)}}, {{c}_{i,jk}^{\left(<;\right)}}\) obtained from the paired comparison relationships in Fig. 4, through Eq. 9. The relevant pjk values (in the last column) are calculated by applying Eq. 10
Finally, the coefficients \({c}_{i,jk}\) are aggregated in the following weighted sum, which determines the pjk value:
This value expresses the weighted fraction of CR for which the j-th EC has a greater influence than the k-th one. For example, the paired comparison “EC1, EC2” (at the top of Fig. 6) would result in:
The pjk values can be aggregated into a P matrix of proportions, which—consistently with the LCJ—is made up of elements that are symmetrical with respect to the main diagonal and complementary to each other with respect to the unitFootnote 4. Figure 7a contains the P matrix that results from the paired comparison relationships in Fig. 5c. Henceforth, the traditional LCJ (cf. Section 4) is applied, determining the Z matrix (see Fig. 7b) and, subsequently, the interval scaling (x) of the ECs (see Fig. 7c).

a P matrix, b Z matrix, and c scaling resulting from the application of the proposed procedure to the test case. Items marked with “*” in the matrix P are associated with values of ± 3 in the matrix Z (cf. Section 4). \(\sum_{k}\) is the summation of the values reported in the k-th column of the matrix Z; the xk values concern the interval scaling resulting from the LCJ; the yk values concern the ratio scaling downstream of the anchoring in Eq. 12
(d) Scale anchoring. Taking inspiration from the methodology developed in (Franceschini and Maisano 2019), the interval scaling resulting from the LCJ can be “anchored” with respect to the (unknown) psychological continuum, using two of the previously introduced dummy objects: EC∅, i.e., an anchor object corresponding to the absence of relationship, and EC●, i.e., an anchor object corresponding to the maximum possible degree of intensity of the relationship with the CR of interest. Therefore, the (interval) scale (x) is transformed into a new one (y), defined in the conventional range [0, 10], through the following linear transformation:
where.
x∅ and x● are the scale values of EC∅ and EC● respectively, resulting from the LCJ;
xk is the scale value of a generic k-th EC, resulting from the LCJ;
yk is the relevant transformed scale value in the conventional range [0, 10].
The new scale (y) has a conventional unit and a zero point (which corresponds to the absence of the attribute); it can therefore be considered as a ratio scale.
Although the mathematical operations required to implement the LCJ might seem complex, they are in fact computationally straightforward and can be entirely automated using a basic spreadsheets such as MS Excel (Brown and Peterson 2009; Franceschini and Maisano 2019).
6 Concluding remarks
This paper introduced a new procedure for prioritizing the HoQ’s ECs, based on Thurstone’s LCJ. Besides being conceptually more rigorous and overcoming some shortcomings of the traditional ISM, the new procedure offers several other advantages. First, it can be integrated into the traditional procedure for constructing the HoQ without requiring additional or extra works from participants. This means that interviewees providing the VoC and the QFD team members responsible for creating the relationship matrix do not have to change their traditional work, as the mathematical implementation of the LCJ is fully automatable with a simple spreadsheet. Second, it prioritizes the ECs in the form of a ratio scaling, anchoring the LCJ solution through several dummy ECs. In addition, it is easy to implement, flexible, and adaptable to other response modes than the traditional one (e.g., those in which judgments are inherently uncertain or incomplete). The effectiveness and the robustness of the new EC prioritization are ensured by the LCJ itself, which is a well-established technique that has been used and tested in multiple contexts (Franceschini et al. 2022).
With reference to the exemplified test case, it is interesting to note that the proposed procedure produces results quite in line with those of the ISM, as shown in Fig. 8. This diagram denotes a relatively high correlation (i.e., Pearson correlation coefficient R2 ≈ 0.8602) between the two approaches, which produce two very similar final rankings of ECs (only a rank reversal between EC1 and EC8 is observed):

Other tests have confirmed some agreement between the proposed procedure and the ISM although there are specific situations in which the two approaches may produce different results. Precisely for these situations, the authors claim the superiority of the new procedure, as it avoids questionable and potentially distorting operations. This aspect will be further investigated in future studies.
In conclusion, the new procedure represents an additional tool in the QFD-team's toolbox, to expand the perspective of analysis. The limitations of the proposed procedure are those inherent in the LCJ, namely some postulates concerning the (normal) distribution of judgments in the psychological continuum (cf. Section 4).
Regarding the future, possible adaptations of the proposed procedure to problems characterized by uncertain and/or incomplete formulation of relationships between ECs and CRs will be investigated. Additionally, a structured comparison will be made between the results of the new procedure and those of other alternative procedures to ISM, which are already present in the scientific literature.
Data availability
Not applicable.
Notes
The fact that the two quantities coincide is purely incidental.
This notation will facilitate understanding the description in Sect. 5, since the objects of the problem of interest are the HoQ’s ECs.
This preference combines the relationships of strict preference and indifference according to the conventional weighting in Eq. 3.
By combining the relationships \({c}_{i,jk}^{\left(>\right)}+{c}_{i,jk}^{\left(\sim \right)} +{c}_{i,jk}^{\left(<\right)}=1\), \({c}_{i,jk}=1-{c}_{i,kj}\), and \(\sum_{\forall i}{w}_{{CR}_{i}}=1\), it can be easily deduced that \({p}_{jk}=1-{p}_{kj}\).
Abbreviations
- CR:
-
Customer Requirement
- EC:
-
Engineering Characteristic
- HoQ:
-
House of Quality
- ISM:
-
Independence Scoring Method
- LCJ:
-
Law of Comparative Judgment
- MCDM:
-
Multi-Criteria Decision Making
- QFD:
-
Quality Function Deployment
- VoC:
-
Voice of the Customer
References
Akao Y (1994) Development history of quality function deployment. Cust Driven Approach Qual Plan Deploy 339:90
Brown TC, Peterson GL (2009) An enquiry into the method of paired comparison: reliability, scaling, and Thurstone’s Law of Comparative Judgment. U.S. Department of Agriculture, Forest Service, Rocky Mountain Research Station. General Technical Report RMRS-GTR-216WWW, U.S. Forest Service Fort Collins, Colorado
Dym CL, Wood WH, Scott MJ (2002) Rank ordering engineering designs: pairwise comparison charts and Borda counts. Res Eng Design 13:236–242
Franceschini F (2001) Advanced quality function deployment. CRC Press
Franceschini F, Maisano D (2018) A new proposal to improve the customer competitive benchmarking in QFD. Qual Eng 30(4):730–761
Franceschini F, Maisano D (2019) Fusing incomplete preference rankings in design for manufacturing applications through the ZMII-technique. Int J Adv Manuf Technol 103:3307–3322
Franceschini F, Rossetto S (1995) QFD: the problem of comparing technical/engineering design requirements. Res Eng Design 7:270–278
Franceschini F, Galetto M, Maisano D, Mastrogiacomo L (2015) Prioritisation of engineering characteristics in QFD in the case of customer requirements orderings. Int J Prod Res 53(13):3975–3988
Franceschini F, Maisano DA, Mastrogiacomo L (2022) Rankings and decisions in engineering. Springer International Publishing, Cham, Switzerand
Galetto M, Franceschini F, Maisano D, Mastrogiacomo L (2018) Engineering characteristics prioritisation in QFD using ordinal scales: a robustness analysis. Eur J Ind Eng 12(2):151–174
Ghorabaee MK, Zavadskas EK, Olfat L, Turskis Z (2015) Multi-criteria inventory classification using a new method of evaluation based on distance from average solution (EDAS). Informatica 26:435–451
Huang J, Mao LX, Liu HC, Song MS (2022) Quality function deployment improvement: a bibliometric analysis and literature review. Qual Quant 56(3):1347–1366
Kelly KT, Richardson M, Isaacs T (2022) Critiquing the rationales for using comparative judgement: a call for clarity. Assess Educ Princ Polic Pract 29(6):674–688. https://doi.org/10.1080/0969594X.2022.2147901
Li S, Tang D, Wang Q (2019) Rating engineering characteristics in open design using a probabilistic language method based on fuzzy QFD. Comput Ind Eng 135:348–358
Liu X, Ma Y (2021) A method to analyze the rank reversal problem in the ELECTRE II method. Omega 102:102317
Lyman D (1990) Deployment normalization. In: Transactions from the Second Symposium on Quality Function Deployment. Automotive Division of the American Society for Quality Control, the American Supplier Institute, Inc., Dearborn, MI, and GOAL/QPC, Methuen, MA, pp. 307–315
Mao LX, Liu R, Mou X, Liu HC (2021) New approach for quality function deployment using linguistic Z-numbers and EDAS method. Informatica 32(3):565–582
Maranell G (ed) (1974) Scaling: a sourcebook for behavioral scientists, 1st edn. Routledge, New York
Ping YJ, Liu R, Lin W, Liu HC (2020) A new integrated approach for engineering characteristic prioritization in quality function deployment. Adv Eng Inform 45:101099
Shi H, Mao LX, Li K, Wang XH, Liu HC (2022) Engineering characteristics prioritization in quality function deployment using an improved ORESTE method with double hierarchy hesitant linguistic information. Sustainability 14(15):9771
Thurstone LL (1927) A law of comparative judgments. Psychol Rev 34(4):273
Yager RR (2001) Fusion of multi-agent preference orderings. Fuzzy Sets Syst 117(1):1–12
Zare Mehrjerdi Y (2010) Quality function deployment and its extensions. Int J Qual Reliab Manag 27(6):616–640
Acknowledgements
This research was carried out under the MICS (Made in Italy, Circular and Sustainable) Extended Partnership and partially funded by the European Union Next-GenerationEU (Piano Nazionale di Ripresa e Resilienza—Missione 4, Componente 2, Investimento 1.3, D.D. 1551.11-10-2022, PE00000004).
Funding
Open access funding provided by Politecnico di Torino within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Contributions
The authors have provided an equal contribution to the drafting of the paper.
Corresponding author
Ethics declarations
Conflict of interests
The authors do not have conflict of interest.
Ethical approval
The authors respect the Ethical Guidelines of the Journal.
Consent to participate
Not applicable.
Consent to publish
Not applicable.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Maisano, D.A., Carrera, G., Mastrogiacomo, L. et al. A new method to prioritize the QFDs’ engineering characteristics inspired by the Law of Comparative Judgment. Res Eng Design (2024). https://doi.org/10.1007/s00163-024-00436-8
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00163-024-00436-8