
Abstract
Multi-fidelity (MF) surrogate models for incorporating multiple non-hierarchical low-fidelity (LF) datasets, whose rank of fidelity level is unknown, have attracted much attention in engineering problems. However, most of existing approaches either need to build extra surrogate models for LF datasets in the fitting process or ignore the cross-correlations among these LF datasets, resulting in accuracy deterioration of an MF model. To address this, a novel multi-fidelity cokriging model is proposed in this article, termed as MCOK, which can incorporate arbitrary number of non-hierarchical LF datasets without building extra LF surrogate models. A self-contained derivation of MCOK predictor and its mean square error are presented. It puts all the covariances between any two MF datasets into a single matrix and introduces additional parameters “gamma” to account for their cross-correlations. A novel method for tuning these additional parameters in a latent space is developed to deal with the problem associated with non-positive definite correlation matrix. The proposed MCOK method is then validated against a set of numerical test cases and further demonstrated via an engineering example of aerodynamic data fusion for FDL-5A flight vehicle. Results from current test cases show that MCOK outperforms existing non-hierarchical cokriging, linear regression MF surrogate model, and latent-map Gaussian processes model, with more accurate and robust predictions, which makes it more practical for engineering modeling problems.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Surrogate model has been widely applied to different areas of aerospace science and engineering due to its capability of yielding usable approximations of the quantity of interest and simultaneously featuring real-time-capable evaluations (Forrester and Keane 2009; Simpson et al. 2001; Viana et al. 2014; Bertram et al. 2018). Particularly, they are built through a small number of samples and used to replace high-fidelity (HF) but time-consuming physical tests or simulations so that the design efficiency could be greatly improved (Sacks et al. 1989). With the integration of GPU technology, the efficiency could be further accelerated (Gardner et al. 2018). However, in many real-world engineering design, building a sufficiently accurate surrogate model still needs large number of expensive experimental tests or HF simulations, which makes the cost easily become prohibitive (Giselle Fernández-Godino et al. 2019; Park et al. 2017). To tackle this problem, multi-fidelity (MF) surrogate models have gained popularity as they use a set of low-fidelity (LF) models to provide information about variation trend and assist in predicting the quantity of interest, while reducing the number of expensive tests or HF simulations (Han and Görtz 2012). It is a very promising way and strikes a balance between the high cost and prediction accuracy by fusing the HF and LF datasets (Cheng et al. 2021; Han et al. 2020; Liu et al. 2018; Zhou et al. 2020a).
Currently, the existing MF modeling approaches can be divided into three categories according to diverse means of data fusion (Zhou et al. 2017, 2020b). The first category is a correction-based method using a bridge or scaling function to capture the differences and ratios between the LF and HF models. The correction can be multiplicative (Haftka 1991; Alexandrov et al. 2001), additive (Choi et al. 2009; Song et al. 2019), or hybrid (Gano et al. 2005; Han et al. 2013). As these methods are easy to understand with relatively simple forms, they are the most extensive approaches for MF surrogate models (Zhou et al. 2020a). The second category is space mapping (Bandler et al. 1994; Robinson et al. 2008; Jiang et al. 2018), which attempts to establish an appropriate mapping relation between the HF and LF design space. The third category is variable-fidelity kriging, such as cokriging. Cokriging was originally proposed in geostatistical community (Journel and Huijbregts 1978) and then extended to deterministic computer experiments via introducing automatic regression parameters by Kennedy and O’Hagan (2000), also termed as KOH autoregressive model. Later, Qian and Wu (2008) used a Gaussian process model instead of a constant term as the multiplicative factor to account for the nonlinear scaling change, resulting in a dramatic improvement in prediction performance. Le Gratiet and Garnier (2014) proposed a recursive cokriging model, which significantly reduced the computational complexity of the original cokriging model. Ulaganathan et al. (2015) extended this method by incorporating MF gradient information during the model construction. Zaytsev (2016) also used a recursive way to implement a cokriging model incorporating MF data with more than two levels. Perdikaris et al. (2017) developed a nonlinear autoregressive cokriging model to learn the complex nonlinear relations between multiple LF and HF models. Guo et al. (2018) and Park et al. (2018) discussed the properties of different terms in the likelihood function to find a proper scale factor before the LF model. Bu et al. (2022) proposed an alternative way to choose the scale factor by minimizing the posterior variance of the discrepancy function. Han et al. (2012) developed a new cokriging model by redefining the cokriging weights and by a novel approach to constructing the cokriging correlation matrix. He also put forward an extension cokriging method, termed as hierarchical Kriging (HK) model (Han and Görtz 2012), which is as accurate as KOH autoregressive model but provides a more reasonable estimate of the mean-squared error (MSE). Besides, he extended the original HK with two-level fidelities to multi-level HK model (MHK), which can fuse different datasets with arbitrary levels of fidelity (Han et al. 2020). Zimmermann and Han (2010) developed a simplified cross-correlation estimation approach based on Han’s method (Han et al. 2012), which makes the new cokriging model more robust. Courrier et al. (2016) compared these two cokriging models and found that Zimmermann’s method was more efficient and accurate in some engineering modeling cases. Zhou et al. (2020a) proposed a generalized cokriging model which can integrate both nested and non-nested MF sampling data. Due to the remarkable performance, cokriging has gained popularity in various fields (Liu et al. 2018), such as aerospace field (Hebbal et al. 2021; Shi et al. 2020), intelligent manufacturing (Krishnan and Ganguli 2021), and marine industry (Liu et al. 2022).
Although many MF modeling methods mentioned above have already been extended to incorporate multiple LF datasets with three or more fidelities (Han et al. 2020; Le Gratiet and Garnier 2014; Ulaganathan et al. 2015; Zaytsev 2016; Perdikaris et al. 2017), they assume that these LF datasets used for building an MF surrogate model are hierarchical. In other words, the fidelity levels of all LF datasets are determined or ranked in advance. However, in many cases, the fidelity levels of the LF models are not hierarchical and cannot be pre-determined. This can lead to situations where the data fusion process fails to deliver accurate results. Such non-hierarchical LF datasets are commonly encountered but often overlooked, as they are generated in different ways to simplify the HF model. For example, it could be hard to distinguish the fidelity level between the datasets obtained by solving Euler equations on a fine computational grid and those obtained by solving Navier–Stokes equations on a coarse grid. To address this issue, many new MF methods for incorporating non-hierarchical LF datasets have been proposed recently. Yamazaki and Mavriplis (2013) developed a three-level cokriging model based on Han’s work (Han et al. 2012) to handle with non-hierarchical LF datasets and applied it to aerodynamic data fusion. Chen et al. (2016) proposed three different non-hierarchical multi-model fusion approaches based on spatial random processes, with different assumptions and structures to capture the relationships between the simulation models and the HF observations. Zhang et al. (2018) proposed a simple and yet powerful MF surrogate model based on single linear regression, termed as linear regression multi-fidelity surrogate (LR-MFS), especially for fitting HF data with noise. Xiao et al. (2018) developed an extended cokriging model (ECK) by attributing various weights to LF models of different fidelities. Cheng et al. (2021) proposed an MF surrogate modeling method based on variance-weighted sum to flexibly handle multiple non-hierarchical LF data. Eweis-Labolle et al. (2022) used a latent-map Gaussian Processes (LMGP) model to convert data fusion into a latent space learning problem where the relations among different non-hierarchical datasets can be automatically learned. Zhang et al. (2022) improved Xiao’s method by minimizing the second derivative of the prediction values of the discrepancy model to obtain optimal scale factors for the LF surrogate models, and developed a non-hierarchical cokriging modeling method, termed as NHLF-COK, which was comparable to LR-MFS and ECK models. Besides, Yousefpour et al. (2023) developed an open-source library for kernel-based learning via Gaussian Processes (GPs) called GP+, which contains powerful MF modeling methods and shows several unique advantages over other GP modeling libraries.
However, most of these MF models for incorporating multiple non-hierarchical LF datasets have two major limitations: (1) Most approaches, such as LR-MFS and NHLF-COK, require the construction of additional surrogate models for LF datasets as a preliminary step in the fitting process, which makes the MF model predictor largely depend on the accuracy of these LF surrogate models. In other words, if LF surrogate models are built inaccurately or even provide incorrect model variation trends, the final prediction accuracy of the MF model will not be as good as expected. (2) They only consider the covariances between HF and LF datasets while ignoring the effects of cross-covariances among LF models, which may lead to a reduction in model accuracy. Under these circumstances, further improvements in accuracy are still required before they can be widely used in real-world engineering modeling problems, which motivates the study of this article.
The objective of this article is to develop a novel and engineeringly practical surrogate model, termed as multi-fidelity cokriging (MCOK), capable of incorporating non-hierarchical LF datasets with arbitrary levels of fidelity, without building additional surrogate models for LF datasets, and fully considering the effects of cross-covariances among different LF models. Its core idea is to put all the covariances between any two datasets of different fidelities together into a single cokriging correlation matrix and introduce additional parameters in the matrix to account for the cross-correlations between different MF datasets. This is of great benefit to explore underlying factors and improve the prediction accuracy. In fact, our method is an extension of the two-level cokriging model by Zimmermann and Han (2010) to a model that can incorporate data with arbitrary levels of fidelities. Note that such extension is not straightforward since the correlation matrix could easily become non-positive definite, which is fatal for hyperparameter tuning using maximum likelihood estimation (MLE). To deal with this problem, we develop a novel method for tuning the additional parameters by replacing them with the distances between latent points in a two-dimensional latent space, allowing for quantifying the correlations among different datasets. These latent points can move freely to avoid matrix singularity when changing positions during MLE, which makes the proposed MCOK model efficient and robust. Additionally, while our proposed MCOK model and the LMGP model exhibit similarities in optimizing model parameters and both models can consider the cross-covariances among LF models without building extra LF surrogate models during the fitting process, they still differ in the basic assumption regarding the regression function served as the model variation trend. More specifically, in an LMGP model, the authors assume that the random functions for MF data all have stationary and the same mean, while in an MCOK model, we assume that they have stationary but different means. This assumption, indeed, benefits the fusion of multiple MF datasets with systematic biases, such as aerodynamic data obtained from different physical models, making the MCOK model more accurate. A detailed discussion of this will be presented in the next section.
The remainder of this article is organized as follows. Section 2 introduces the formulation of MCOK model, including its predictor and MSE, the choice of correlation function and the hyperparameter tuning strategy, along with a novel method for tuning the additional parameters to overcome correlation matrix singularity. Section 3 presents a set of numerical test cases to validate the proposed method and employs an aerodynamic data fusion example involving the FDL-5A hypersonic flight vehicle to further demonstrate our approach. Three other representative MF surrogate models NHLF-COK, LR-MFS, and LMGP are also built for comparison. At last, general conclusions and future work beyond the present scope are presented.
2 Multi-fidelity cokriging model formulation
Cokriging model is a statistical interpolation method for the enhanced prediction of a less intensively sampled primary variable of interest with assistance of intensively sampled auxiliary variables (Han et al. 2012). Compared with the conventional KOH autoregressive model, Han’s cokriging model might be more practical and can reduce the notational complexity of cokriging correlation matrix (Han et al. 2012). Additionally, a scale factor \({{\sigma_{1} } \mathord{\left/ {\vphantom {{\sigma_{1} } {\sigma_{2} }}} \right. \kern-0pt} {\sigma_{2} }}\) (\(\sigma_{1} ,\sigma_{2}\) are the process variances of HF and LF model, respectively) is introduced in the cokriging predictor to account for the influence of the LF model on the prediction of the HF model. However, the optimal value of \({{\sigma_{1} } \mathord{\left/ {\vphantom {{\sigma_{1} } {\sigma_{2} }}} \right. \kern-0pt} {\sigma_{2} }}\) is hard to estimate, resulting in Han’s cokriging model being less robust (Courrier et al. 2016). To avoid this problem, Zimmermann and Han (2010) presented a simplified cross-correlation estimation by introducing additional model parameters before cross-correlation terms in the cokriging correlation matrix. Results show that compared to Han’s method, though Zimmerman’s method is considerably simpler, it performed in all given examples comparable or, arguably, even better (Zimmermann and Han 2010). Herein, our work is based on Zimmermann’s method and a detailed derivation is presented in the following subsections.
2.1 General descriptions and assumptions
For an m-dimensional modeling problem, suppose we are concerned with the prediction of an expensive-to-evaluate HF model \(y_{0} ({\mathbf{x}}),\) with assistance of L cheaper-to-evaluate LF models \(y_{k} = f_{k} ({\mathbf{x}}), \, k = 1,2, \ldots ,L,\) whose fidelity levels are not determined or ranked in advance. This assumption is quite different from that of building an MHK model (Han et al. 2020), which argues that the fidelity levels of LF models can be clearly ranked and applies a hierarchical treatment. In other words, the knowledge of the relative accuracies of all the LF models, \(y_{1} ({\mathbf{x}}),y_{2} ({\mathbf{x}}), \ldots ,y_{L} ({\mathbf{x}})\), with respect to the highest fidelity model \(y_{0} ({\mathbf{x}})\) is not provided here in an MCOK model.
Assume that the high- and all lower-fidelity models are sampled at \(n_{0} ,n_{1} ,n_{2} , \ldots ,n_{L}\) sampling sites, respectively. The HF dataset is denoted as \({\varvec{S}}_{0} {\kern 1pt} = {\kern 1pt} {\kern 1pt} \left[ {{\varvec{x}}_{0}^{(1)} ,{\varvec{x}}_{0}^{(2)} ,...,{\varvec{x}}_{0}^{{(n_{0} )}} } \right]^{{\text{T}}} \in {\mathbb{R}}^{{n_{0} \times m}}\) and the kth LF dataset is denoted as \({\varvec{S}}_{k} {\kern 1pt} = {\kern 1pt} {\kern 1pt} \left[ {{\varvec{x}}_{k}^{(1)} ,{\varvec{x}}_{k}^{(2)} ,...,{\varvec{x}}_{k}^{{(n_{k} )}} } \right]^{{\text{T}}} \in {\mathbb{R}}^{{n_{k} \times m}}\). The corresponding function values are \({\varvec{y}}_{S,0} = \left[ {y_{0}^{(1)} ,y_{0}^{(2)} ,...,y_{0}^{{(n_{0} )}} } \right]^{{\text{T}}} \in {\mathbb{R}}^{{n_{0} }}\) and \({\varvec{y}}_{S,k} = \left[ {y_{k}^{(1)} ,y_{k}^{(2)} ,...,y_{k}^{{(n_{k} )}} } \right]^{{\text{T}}} \in {\mathbb{R}}^{{n_{k} }}\), respectively. Thus, the pairs \(({\varvec{S}}_{0} ,{\varvec{y}}_{S,0} )\) and \(({\varvec{S}}_{k} ,{\varvec{y}}_{S,k} )\) denote the measured input–output dataset of HF and the kth LF level in the vector space, respectively.
As in the case of a kriging, the output of a deterministic computer experiment is treated as a realization of a stationary random process. Hence, we assume that the HF model and the kth LF model are realizations of dependent random functions:
where \({\mathbf{f}}_{0} = \left[ {f_{0}^{(1)} ({\mathbf{x}}),f_{0}^{(2)} ({\mathbf{x}}), \ldots ,f_{0}^{(h)} ({\mathbf{x}})} \right] \in {\mathbb{R}}^{1 \times h} ,\) \({\mathbf{f}}_{k} = \left[ {f_{k}^{(1)} ({\mathbf{x}}),f_{k}^{(2)} ({\mathbf{x}}), \ldots ,f_{k}^{(h)} ({\mathbf{x}})} \right] \in {\mathbb{R}}^{1 \times h} ,\) are a set of \(h\) pre-determined regression or basis functions and \({{\varvec{\upbeta}}}_{0} = \left[ {\beta_{0}^{(1)} ,\beta_{0}^{(2)} , \ldots ,\beta_{0}^{(h)} } \right]^{{\text{T}}} \in {\mathbb{R}}^{h \times 1} ,\) \({{\varvec{\upbeta}}}_{k} = \left[ {\beta_{k}^{(1)} ,\beta_{k}^{(2)} , \ldots ,\beta_{k}^{(h)} } \right]^{{\text{T}}} \in {\mathbb{R}}^{h \times 1}\) are the unknown constant coefficients, serving as the model variation trend. Note that here we assume that the random functions have stationary but different means, namely, \(E\left[ {Y_{0} ({\mathbf{x}})} \right] = {\mathbf{f}}_{0} {{\varvec{\upbeta}}}_{0} \ne E\left[ {Y_{1} ({\mathbf{x}})} \right] = {\mathbf{f}}_{1} {{\varvec{\upbeta}}}_{1} \ne \cdots \ne E\left[ {Y_{L} ({\mathbf{x}})} \right] = {\mathbf{f}}_{L} {{\varvec{\upbeta}}}_{L}\). Besides, the stationary random processes \(Z_{0} ( \cdot )\) and \(Z_{k} ( \cdot )\) have zero mean and a covariance of
for any two different sampling sites \({\mathbf{x}}_{0} ,{\mathbf{x^{\prime}}}_{0}\) from the HF dataset \(({\varvec{S}}_{0} ,{\varvec{y}}_{S,0} )\), and \({\mathbf{x}}_{k} ,{\mathbf{x^{\prime}}}_{k}\) from the kth LF dataset \(({\varvec{S}}_{k} ,{\varvec{y}}_{S,k} )\). Here, \(\sigma_{0}^{2} ,\sigma_{k}^{2}\) are the process variances of \(Z_{0} ( \cdot ),Z_{k} ( \cdot )\) respectively, and \(R^{{{(}00{)}}} ,R^{{{(}kk{)}}}\) are spatial correlation functions only corresponding to the HF data and the data of kth low-fidelity, respectively. Then, the cross-covariances between the HF dataset and the kth LF dataset are given by
Besides, the MCOK model not only considers the cross-covariances between the HF dataset and LF datasets, but also takes the cross-covariance between any two of LF datasets into account. In other words, for each two LF datasets of different fidelities, their underlying correlation can also be learned automatically when tuning MCOK model parameters. Therefore, the cross-covariance corresponding to the kth LF dataset and another different jth LF dataset is given by
where \(R^{(jk)}\) is the cross-correlation function.
2.2 Multi-fidelity cokriging predictor and mean-squared error
Assuming that the response of the HF model \(y_{0}\) can also be approximated by a linear combination of all the observed datasets with varying fidelity levels (Journel and Huijbregts 1978), the MCOK predictor of \(y_{0} ({\mathbf{x}})\) at an untried HF sampling site \({\mathbf{x}}\) is formally defined as
where \({\mathbf{w}}_{0}^{{\text{T}}} ,{\mathbf{w}}_{k}^{{\text{T}}} { (}k = 1,2, \ldots ,L)\) are the vectors of weight coefficients for the HF dataset and the kth LF dataset, respectively. Note that we do not need to build a surrogate model for each LF dataset, which avoids the accuracy loss caused by inaccurate LF surrogate predictor. We replace \({\mathbf{y}}_{S,0} ,{\mathbf{y}}_{S,k}\) with the corresponding random quantities \({\mathbf{Y}}_{0} ,{\mathbf{Y}}_{k}\), treat \(\hat{y}_{0} ({\mathbf{x}})\) as random, and try to minimize its MSE:
subject to the unbiasedness constraint:
Substituting Eq. (1) into Eq. (7), then the unbiasedness constraint reads
and therefore
In order to fulfill the unbiasedness constraint independent of the choice of the regression parameters \({{\varvec{\upbeta}}}_{0} ,{{\varvec{\upbeta}}}_{k}\), the following stronger unbiasedness conditions must be imposed:
where \({\mathbf{F}}_{0} ,{\mathbf{F}}_{k} {, }k = 1,2, \cdots ,L,\) are basis functions and denoted as the regression matrices:
In this article, we consider an ordinary MCOK model, thus \(h = 1\), and \({\mathbf{F}}_{0} ,{\mathbf{F}}_{k}\) can be written as
Solving the above constrained minimization problem by Lagrange multiplier method, the weights of MCOK in Eq. (5) can be found by the following system of linear equations:
where \({{\varvec{\upmu}}} = \left[ {\mu_{0} ,\mu_{1} , \ldots ,\mu_{L} } \right]^{{\text{T}}}\) are the vectors of Lagrange multipliers, and
Here, \({\mathbf{C}}^{{{(}00{)}}}\) denotes the covariance matrix modeling the correlation between any two observed HF samples \({\mathbf{x}}_{0}^{(p)}\) and \({\mathbf{x}}_{0}^{(q)}\); \({\mathbf{C}}^{{{(}0k{)}}}\) or \({\mathbf{C}}^{{{(}k0{)}}}\) denotes the covariance matrix modeling the cross-correlation between an observed HF sample \({\mathbf{x}}_{0}^{(p)}\) and an observed LF sample \({\mathbf{x}}_{k}^{(q)}\) of kth LF level; \({\mathbf{C}}^{{{(}jk{)}}}\) or \({\mathbf{C}}^{{{(}kj{)}}}\) denotes the covariance matrix modeling the cross-correlation between an observed LF sample \({\mathbf{x}}_{j}^{(p)}\) of jth LF level and an observed LF sample \({\mathbf{x}}_{k}^{(q)}\) of kth LF level. \({\mathbf{c}}_{0} ({\mathbf{x}})\) denotes the covariance vector modeling the correlation between an observed HF samples \({\mathbf{x}}_{0}^{(p)}\) and an unknown sample \({\mathbf{x}}\); \({\mathbf{c}}_{k} ({\mathbf{x}})\) denotes the covariance vector modeling the cross-correlation between an observed LF samples \({\mathbf{x}}_{k}^{{{(}p{)}}}\) of kth LF level and an unknown sample \({\mathbf{x}}\). Note that it is essential that all the blocks comprising the covariance matrix must be positive definite to ensure the covariance matrix is invertible (Bertram and Zimmermann 2018). However, the covariance matrix could be ill-conditioned if two HF or LF samples are very close to each other, and it may also lose its diagonal dominance and become non-positive definite if there is a large difference in hyperparameters for auto- and cross-correlation functions (Han et al. 2010). Besides, searching for the optimal values of these various process variances in Eq. (14) could also incur additional cost during the model training process (Bertram and Zimmermann 2018; Yamazaki and Mavriplis 2013).
In order to make the MCOK predictor more robust and simplify covariance data fitting, we do not follow Han’s (Han et al. 2010) or Yamazaki’s methods (Yamazaki and Mavriplis 2013) but refer to Zimmermann’s simplification method (Zimmermann and Han 2010), and assume that all the Gaussian processes feature the same spatial inter-correlations, more specifically,
As a direct consequence,
This simplification is reasonable because the basic premise assumes that both HF and multiple LF data describe the same phenomenon, although with varying levels of accuracy. It is well suited for the case when the LF data are sufficiently correlated with HF data or have the similar variation trend. But when the correlation is relatively small, the fusion accuracy will be limited, and we get less benefit from this simplification.
To account for the cross-correlations between any two datasets of different fidelities, an additional parameter vector “\({{\varvec{\upgamma}}}\)” is then introduced:
Here, \(\gamma \in (0,1)\) and after optimization, the value of \(\gamma\) is a measure of how strongly the two datasets of different fidelities are correlated (Zimmermann and Han 2010). For \(\gamma\) close to 0, the two datasets are weakly correlated or uncorrelated, while for \(\gamma\) close to 1, they are fully correlated and have a strong connection. Since there exist “L” LF datasets, the total number of additional parameters to be introduced is \({{L(L + 1)} \mathord{\left/ {\vphantom {{L(L + 1)} 2}} \right. \kern-0pt} 2}\). For example, when \(L = 2\), there are two different LF datasets along with a HF dataset, and it needs three parameters \(\gamma^{(01)} ,\gamma^{(02)}\), and \(\gamma^{(12)}\) to learn the correlations between the HF dataset (level 0) and the first LF (level 1) dataset, the HF dataset (level 0) and the second LF (level 2) dataset, and the first LF (level 1) dataset and the second LF (level 2) dataset, respectively.
By utilizing the above hypothesis and substituting Eq. (11), Eq. (13) can be rewritten as
where
Note that only the computations of correlation vector \({\mathbf{r}}_{0}\) and \({\mathbf{r}}_{k}\) involve the unknown sample \({\mathbf{x}}\). After solving for the new weights \({\mathbf{w}}_{0}^{{\text{T}}}\) and \({\mathbf{w}}_{k}^{{\text{T}}}\), the MCOK predictor can be written as follows, which is very similar to a kriging predictor:
where
and for an ordinary MCOK model, we have
Here, \(\, {\tilde{\mathbf{\beta }}}\) is a constant vector and its derivation will be introduced in the Sect. 2.4. Note that the vector \({\mathbf{V}}_{MCOK}\) defined in Eq. (20) only depends on the observed HF and LF datasets, and it can be calculated during the model fitting stage of MCOK. Besides, \({\tilde{\mathbf{\varphi }}}^{{\text{T}}}\) is already known and \({\tilde{\mathbf{\beta }}}\) is also calculated by the observed HF and LF datasets. Once the MCOK is built, \({\mathbf{V}}_{MCOK}\),\({\tilde{\mathbf{\varphi }}}^{{\text{T}}}\) and \({\tilde{\mathbf{\beta }}}\) are all obtained and can be stored. Hence, the prediction of the unknown \(y_{0}\) at an unknown sample \({\mathbf{x}}\) only requires recalculating \({\tilde{\mathbf{r}}}^{{\text{T}}} \left( {\mathbf{x}} \right)\).
Then, the MSE of the MCOK prediction can be derived as follows:
2.3 Correlation function
As presented in Eqs. (19) and (21), the construction of correlation matrix \({\tilde{\mathbf{R}}}\) and correlation vector \({\tilde{\mathbf{r}}}\) for MCOK requires the calculation of correlation function \(R\), which only depends on the Euclidean distance between two different sampling sites, \({\mathbf{x}}\) and \({\mathbf{x^{\prime}}}\), and is often expressed as the form
where \(\theta_{i}\) is a hyperparameter that scales the influence of the ith input variable on the functional response and can be tuned by a specific optimization strategy. Note that the same hyperparameters \({{\varvec{\uptheta}}} = \left[ {\theta_{1} ,\theta_{2} , \ldots ,\theta_{m} } \right]^{{\text{T}}}\) are used in all auto- and cross-correlation functions to reduce the degrees of freedom.
There are various spatial correlation functions such as Gaussian (squared) exponential, cubic splines, and Matérn functions, of which the Gaussian squared exponential function is arguably the one used most widely in engineering cases because of its simplicity, flexibility, and infinite differentiability, it being formulated as
It is frequently shown in practical applications that the Gaussian squared exponential function can result in a more accurate global prediction (Palar et al. 2020; Zhou et al. 2020a).
2.4 Hyperparameter tuning by maximum likelihood estimation
After the correlation function is determined, we will focus on the method of tuning the hyperparameters \({{\varvec{\uptheta}}}\) and additional parameters \({{\varvec{\upgamma}}}\) hereafter.
Assuming that the sampled data are distributed according to a Gaussian process, the responses at sampling sites are considered to be correlated random functions with the corresponding likelihood function given by
Taking logarithm and derivatives with respect to the parameters to be estimated, we can analytically obtain closed-form solutions for the optimum values of \({\tilde{\mathbf{\beta }}},\sigma^{2}\) as follows:
Substituting it into the associated Eq. (26), we are left with maximizing the concentrated ln likelihood function (neglecting constant terms), which is of the form
Herein, we use an improved version of the Hooke-Jeeves pattern search method (by using multi-start search and a trust-region method) to solve the preceding optimization problem. Besides, we normalize the input variables \({\mathbf{x}}\) to the range \([0.0, \, 1.0]^{m}\) and limit the searching of \({{\varvec{\uptheta}}}\) to the range \([10^{ - 6} ,10^{2} ]^{m}\) and \({{\varvec{\upgamma}}}\) to the range \((0, \, 1)^{{{{L(L + 1)} \mathord{\left/ {\vphantom {{L(L + 1)} 2}} \right. \kern-0pt} 2}}}\).
However, according to our numerical experiments, we found that the correlation matrix \({\tilde{\mathbf{R}}}\) could easily become non-positive definite during the optimization process, which might lead to the failure of matrix decomposition and model construction. Hence, we develop a novel method for tuning the additional parameters to avoid non-positive definite correlation matrix.
2.5 A novel parameter tuning method to avoid non-positive definite correlation matrix
A mandatory requirement for the success of cokriging model is the positive definiteness of the associated cokriging correlation matrix (Bertram and Zimmermann 2018). As spatial correlations are usually modeled by positive definite correlation functions, such as Gaussian squared exponential function, the corresponding correlation matrices for mutually distinct samples are supposed to be positive definite. However, for an MCOK model, we observe that the introduction of additional parameters brings instability and complexity to obtaining a positive definite cokriging correlation matrix since we do not consider the underlying relationship among additional parameters, and they can be any value in the interval \((0,1)\) without any limits.
For example, there exist two LF datasets along with a HF dataset, and \(\gamma^{(01)} = 0.98,\gamma^{(02)} = 0.04,\gamma^{(12)} = 0.95\) in a certain iteration of hyperparameter tuning, which means the HF dataset is strongly correlated to the first LF dataset and they share similar characteristics, while the HF dataset is weakly correlated to the second LF dataset as \(\gamma^{(02)}\) is much smaller than \(\gamma^{(01)}\) and close to 0. In this event, we believe that the cross-correlation between the first and the second LF datasets should also be small, that is, \(\gamma^{(12)}\) is supposed to be close to 0 as well. However, \(\gamma^{(12)}\) is equal to 0.95 in fact. It is evident that this situation is unreasonable but could happen if we do not set constraints for optimizing the additional parameters, resulting in the non-positive definite correlation matrix. To address this, we propose to optimize the latent positions \({\mathbf{z}}\) instead of optimizing original additional parameters \({{\varvec{\upgamma}}}\) directly.
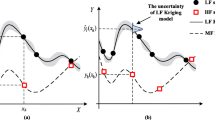
Inspired by the latent space used in the fitting of an LMGP model from Oune and Bostanabad (2021) and Eweis-Labolle et al. (2022), we treat each level of fidelity as a point in a latent space. With this latent representation, the distance between any two different latent points can be recognized as the correlation between these two fidelities. Here, a latent space refers to a low-dimensional manifold encoding underlying factors which distinguish different datasets (Oune and Bostanabad 2021). Figure 1 shows the sketch of a 1D, 2D, and 3D latent space for three different fidelities. The latent points A, B, and C represent HF level, LF1 level, and LF2 level, respectively. Then, the values of three distances, \(d_{AB} ,d_{AC} ,d_{BC}\), represent the cross-correlations between HF and LF1, HF and LF2, LF1 and LF2, respectively, and are calculated by their coordinates \(d_{AB} = \left\| {{\mathbf{z}}(A) - {\mathbf{z}}(B)} \right\|_{2} ,d_{AC} = \left\| {{\mathbf{z}}(A) - {\mathbf{z}}(C)} \right\|_{2} ,d_{BC} = \left\| {{\mathbf{z}}(B) - {\mathbf{z}}(C)} \right\|_{2}\). In order to limit the value of cross-correlation to the range \((0,1)\), we use the following conversion formula to calculate an additional parameter \(\gamma\) from its corresponding Euclidean distance d:

Sketch of varying dimensional latent space for three different fidelities
Therefore, we can obtain the values of original additional parameters \({{\varvec{\upgamma}}}\) when existing three levels of fidelities by \(\gamma^{(01)} = \exp ( - d_{AB}^{2} )\), \(\gamma^{(02)} = \exp ( - d_{AC}^{2} )\), \(\gamma^{(12)} = \exp ( - d_{BC}^{2} )\). Hence, if two latent points are far away from each other, their distance will be quite long and the corresponding \(\gamma\) will be close to 0; if two latent points are close to each other, their distance will be short and \(\gamma\) will be close to 1. Certainly, if any two points coincide, their distance d is equal to 0 and \(\gamma\) is equal to 1, which means the corresponding datasets they represent are fully correlated. However, although the probability of encountering the special scenario where all points coincide is very low, it can still lead to the correlation matrix being ill-conditioned when the HF and LF samples are nested, i.e., the HF sampling set is a subset of the LF one. Hence, when all the \({{\varvec{\upgamma}}}\) are optimized to 1, we reassign their values to 0.9999 to ensure that \({{\varvec{\upgamma}}} \in (0, \, 1)^{{{{L(L + 1)} \mathord{\left/ {\vphantom {{L(L + 1)} 2}} \right. \kern-0pt} 2}}}\) and avoid matrix singularity. In this way, the direct optimization of \({{\varvec{\upgamma}}}\) is substituted with the optimization of the coordinate z of points in a latent space.
It is recommended by Zhang et al. (2020) to use a 2D latent space for each level of fidelity. The reason is that in a 1D latent space, the mappings cannot represent three equally correlated levels. In other words, the situation that \(d_{AB} = d_{AC} = d_{BC}\) will not happen. In a 3D latent space, each point has three coordinates to be optimized, which brings a heavy burden for MLE search. Thus, we choose to use a 2D latent space where each point only has two coordinates to be optimized and all points can move freely to avoid covariance singularity when exchanging positions during the MLE optimization (Zhang et al. 2020). Besides, in order to reduce the computational cost as much as possible, two constraints are employed to ensure translation and rotation invariances: (1) The first latent position of HF level is located at the origin, namely, \(z_{1} (A) = z_{2} \left( A \right) = 0\); (2) The second latent position of LF1 has \(z_{1} (B) \ge 0,z_{2} \left( B \right) = 0\). Thus, fitting an MCOK model with L levels of LF datasets involves estimating \(m + 2 \times (L - 1) + 1\) parameters in total. Note that the number of coordinates \({\mathbf{z}}\) to be optimized, \(2 \times (L - 1) + 1\), is not larger than that of original additional parameters \({{\varvec{\upgamma}}}\), \(L \times (L + 1)/2\), which is helpful to save the computational cost of MLE. In Table 1, we have provided the numbers of the original additional model parameters \({{\varvec{\upgamma}}}\) and the new additional model parameters \({\mathbf{z}}\) that represent the coordinates of latent positions, respectively. It can be observed that, regardless of the value of \(L\), the number of new model parameters never exceeds the number of original model parameters. Moreover, when \(L\) is large than three, the required number of new model parameters is even fewer.
Now, recall the case we mentioned in the first paragraph of this section, we use a 2D latent space to represent it here, as sketched in Fig. 2. According to Eq. (29), we can find that \(d_{AB} = 0.14, \, d_{AC} = 1.73, \, d_{BC} = 0.23\) and these three sides cannot form a triangle, which causes correlation matrix singularity. Note that this can be prevented by using the parameter tunning approach mentioned above. Thus, to avoid non-positive definite correlation matrix, we can optimize the coordinates of latent points representing fidelity levels in a 2D latent space instead.

Sketch of a certain case of three fidelities with \(\gamma^{(01)} = 0.98,\gamma^{(02)} = 0.04,\gamma^{(12)} = 0.95\)
In general, for maximizing Eq. (28), one objective function evaluation at \(({{\varvec{\uptheta}}}_{*} ,{\mathbf{z}}_{*} )\) consists of the following steps:
-
(1)
Compute \({\mathbf{d}}_{*}\) with respect to \({\mathbf{z}}_{*}\) and obtain \({{\varvec{\upgamma}}}_{*}\) according to Eq. (29);
-
(2)
Compute \({\tilde{\mathbf{R}}}({{\varvec{\uptheta}}}_{*} ,{{\varvec{\upgamma}}}_{*} )\) according to Eq. (21);
-
(3)
Compute \({\tilde{\mathbf{\beta }}}({{\varvec{\uptheta}}}_{*} ,{{\varvec{\upgamma}}}_{*} )\) and \(\sigma^{2} ({{\varvec{\uptheta}}}_{*} ,{{\varvec{\upgamma}}}_{*} )\) by solving Eq. (27);
-
(4)
Evaluate Eq. (28).
2.6 The difference between MCOK and LMGP models
The LMGP model is a state-of-the-art surrogate model that was originally proposed to handle the single-fidelity modeling of mixed data, which includes both quantitative and qualitative inputs (Oune and Bostanabad 2021). It has since been extended for MF data fusion (Eweis-Labolle et al. 2022) and Bayesian optimization (Foumani et al. 2023), showcasing its advanced capabilities. In an LMGP model, it is assumed that all the random functions \(Y_{0} ({\mathbf{x}}),Y_{k} ({\mathbf{x}})\) have stationary and the same mean, namely, \(E\left[ {Y_{0} ({\mathbf{x}})} \right] = {\mathbf{f}}_{0} {{\varvec{\upbeta}}}_{0} = E\left[ {Y_{1} ({\mathbf{x}})} \right] = {\mathbf{f}}_{1} {{\varvec{\upbeta}}}_{1} \cdots = E\left[ {Y_{L} ({\mathbf{x}})} \right] = {\mathbf{f}}_{L} {{\varvec{\upbeta}}}_{L} .\) In other words, \({{\varvec{\upbeta}}}_{0} = {{\varvec{\upbeta}}}_{1} = \cdots = {{\varvec{\upbeta}}}_{L}\), and we set them all equal to \({{\varvec{\upbeta}}}\) for convenience. Then, the unbiasedness constraint reads
and therefore,
Note that only one single unbiasedness condition is required in an LMGP model. Then, the LMGP predictor can be written in matrix form as
where
For an ordinary LMGP model, \({\tilde{\mathbf{F}}} = \left[ {1,1, \ldots ,1} \right]{}^{{\text{T}}} \in {\mathbb{R}}^{{\left( {n_{0} + \sum\limits_{k = 1}^{L} {n_{k} } } \right)}}\) and \(\beta\) is a constant scalar. Note that in the experimental study section, the ordinary LMGP model is adopted for the purpose of fair comparison with the ordinary MCOK model.
From the above derivation process, it can be observed that due to the assumption of different means for random functions in MCOK, it is able to effectively eliminate the differences when dealing with MF data fusion with systematic biases. However, the LMGP model does not perform well in this regard because it assumes that all random functions of the MF data have the same mean. In the context of aerodynamic data fusion, there usually exists a systematic bias between MF aerodynamic data obtained from different physical models. For example, the aerodynamic coefficients calculated using the Euler equations and Reynolds-averaged Navier–Stokes (RANS) equations always have a systematic deviation because the Euler equations cannot account for the viscosity of the fluid. Hence, in such a scenario, it is evident that we cannot assume the two aerodynamic datasets of different fidelities to have the same mean and choosing the MCOK model is more appropriate.
2.7 Discussion about the advantages of present MCOK model
Here, we summarize the advantages of the proposed MCOK model as follows:
-
(1)
Different from MHK or other hierarchical MF surrogate models, the proposed MCOK model can incorporate arbitrary number of non-hierarchical LF datasets whose rank of fidelity level or underlying correlations are not known in advance.
-
(2)
It puts all the covariances and cross-covariances between HF and LF sample points into a single matrix and avoids fitting extra surrogate models for LF datasets, which can not only reduce the model complexity but also lower the risk of accuracy loss due to inaccurate LF surrogate models.
-
(3)
It introduces parameter vector “\({{\varvec{\upgamma}}}\)” to account for cross-correlations between datasets of different fidelities and the difficulty associated with modeling cross-covariance is avoided. In addition, the problem associated with non-positive definite correlation matrix is successfully solved by using a novel parameter tuning strategy for \({{\varvec{\upgamma}}}\), which makes the resulting MCOK method efficient and robust for engineering applications.
-
(4)
It is well suited for fusing MF aerodynamic data with systematic biases since it assumes that the random functions of MF data have stationary but different means. These means are served as model variation trends and can eliminate the systematic bias when fusing MF data. This basic assumption makes the MCOK model more general and accurate compared to the LMGP model.
-
(5)
The formulation and implementation of the MCOK model are as simple as that of a conventional kriging model, as presented in Eq. (20), despite requiring slightly increased computational effort. Few modifications are required if one wants to implement an MCOK code with an ordinary kriging code in hand, which makes it more practical for real-world engineering applications.
3 Experimental study
In this section, two numerical cases are firstly employed to demonstrate our proposed MCOK model. Then another six numerical test cases of different dimensions and an aerodynamic data fusion example are used to further validate its merits and effectiveness by comparing it with another three representative MF surrogate models, NHLF-COK, LR-MFS (see Appendix 1 for detailed derivation), and LMGP, that can also incorporate multiple non-hierarchical LF datasets.
To measure the prediction accuracy of the built surrogates, the coefficient of determination \(R^{2}\), the root-mean-square error (RMSE), and the maximum absolute error (MAE) are calculated:
where \(N\) is the number of validation samples, and \(y_{i}\),\(\hat{y}_{i}\) are the true response and predicted value, respectively, of the ith validation sample. The values of \(R^{2}\) and RMSE reflect the global accuracy of the model, and that of MAE reflects the local predictive performance: the closer \(R^{2}\) is to 1 and the smaller the values of RMSE and MAE, the more accurate the model is.
3.1 One-dimensional test case
We are concerned with the modeling of a one-dimensional HF model of interest from Forrester and Keane (2009):
with assistance of two non-hierarchical LF models:
Figure 3a shows the true responses of three models above and the observed samples of each model. It is shown that \(y_{2} (x)\) appears to be more accurate than \(y_{1} (x)\) with respect to \(y_{0} (x)\) as it shares a similar variation trend with \(y_{0} (x)\). Note that we do not use this knowledge of relative accuracy during MF modeling via MCOK. In this case, the HF and LF samples are \({\mathbf{S}}_{0} = [0.0,0.4,0.8,1.0]^{{\text{T}}}\) and \({\mathbf{S}}_{1,2} = [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]^{{\text{T}}}\), respectively. Note that in this case, two LF models share the same low-fidelity sampling sites for convenience. To calculate the error metrics given by Eq. (34), another 100 validation samples are generated by the Latin hypercube sampling (LHS) method. Based on the HF and LF datasets, four MF models are constructed, as sketched in Fig. 3b. The detailed comparison results are summarized in Table 2.

The true model and different MF surrogate models for a one-dimensional test case
It is shown in Fig. 3b that, the MCOK model precisely features the observed functional values at all sampling sites, which verifies the correctness of our proposed method. Compared with NHLF-COK, LR-MFS, and LMGP models, MCOK provides the most accurate prediction and is closer to the exact analytical function, especially in the areas \(x \in \left[ {0.0,0.8} \right]\). Besides, a kriging model built based on the HF samples only is also plotted in Fig. 3b and it has the worst prediction without the assistance of LF samples. In the following cases, we will no longer focus on building a single-fidelity kriging model, but instead, emphasize the comparison of four MF surrogate models. In Table 2, one can also see that the RMSE and MAE of MCOK model is the smallest, and the R2 is closer to 1, which means our proposed method has the highest local and global accuracy. Table 2 also gives the tuned values of additional parameters, which are calculated by the optimized coordinates of latent points. It can be found that, for both LMGP and MCOK models, their additional parameter \(\gamma^{(02)}\) is close to 1 and is larger than \(\gamma^{(01)}\), showing that \(y_{2} (x)\) is more correlated with \(y_{0} (x)\), while \(y_{1} (x)\) has little correlation with \(y_{0} (x)\). This observation matches with our knowledge of the relative accuracies of \(y_{2} (x)\) and \(y_{1} (x)\) with respect to \(y_{0} (x)\). Certainly, for both NHLF-COK and LR-MFS models, their model parameter \(\rho_{1}\) is smaller than \(\rho_{2}\), which also reflects the relative accuracies of LF models with respect to the HF model. Besides, both LMGP and MCOK models additionally provide a parameter \(\gamma^{(12)}\) to quantify the correlation between the two LF models, \(y_{1} (x)\) and \(y_{2} (x)\), which is benefit to improve model accuracy but not available in the other two MF surrogate models.
To further demonstrate the advantages of our MCOK model, particularly in comparison with the LMGP model, we have translated the two original LF models downward by a certain distance and obtain:
Figure 4a shows the true responses of translated LF models above and the observed samples of each model. It can be observed that the translated LF models are far away from each other and also far away from the HF model. Figure 4b shows that the prediction accuracy of the LMGP model significantly decreases, while the predicted curves of the other three MF surrogate models have not shown any noticeable changes when there exist systematic biases among MF datasets. This is because the NHLF-COK and LR-MFS models have separately built LF surrogate models for each LF dataset, so each model has different means, and the discrepancy model in their fitting process can also help to eliminate systematic biases. Therefore, the systematic biases in translated MF datasets do not significantly affect the fusion results of NHLF-COK, LR-MFS, and MCOK models. In Table 3, one can also see that all the error metrics for the LMGP model show a degradation, while the error metrics for NHLF-COK and LR-MFS exhibit slight improvements. It is worth noting that the error metrics for the MCOK model remain unchanged for both the original LF datasets and the translated LF datasets. This can be explained by the model parameters provided in Table 4. It can be found that the change in \(\beta_{1}\) is exactly equal to the translation of the LF1 model, and the change in \(\beta_{2}\) is exactly equal to the translation of the LF2 model. Thus, the optimized \(\theta\) and \({{\varvec{\upgamma}}}\) remain almost unchanged and the fusion result of MCOK also remains unchanged accordingly. For the LMGP model, its model parameters \(\theta\) and \({{\varvec{\upgamma}}}\) vary greatly, leading to significant differences in the final fusion results.

The translated LF datasets and different MF surrogate models for a one-dimensional test case
3.2 Two-dimensional test case
A two-dimensional analytical function with two sets of non-hierarchical LF data modified from Han et al. (2020) is employed here and the HF model is given by
with the two modified LF models given by
Note that the LF2 model exhibits a larger translation relative to the HF model compared to the L1 model. Figure 5 shows the actual contour plot of the HF model, along with the 15 HF sample points selected by a LHS plan and marked with white circles. We also randomly choose 30 LF samples by LHS for \(y_{1} ({\mathbf{x}})\) and \(y_{2} ({\mathbf{x}})\), respectively. To calculate the error metrics, 1000 validation samples are also generated by LHS method.

The true HF model and sampling sites for a two-dimensional test case
Then, NHLF-COK, LR-MFS, LMGP, and MCOK models are built based on the same HF and LF datasets, and the comparison results are listed in Table 5. It is shown that our proposed MCOK model is the most accurate one among the four MF surrogate models since it has the best error metrics. Additional model parameters \({{\varvec{\upgamma}}}\) of MCOK and LMGP models suggest that \(y_{1} ({\mathbf{x}})\) appears to be more accurate than \(y_{2} ({\mathbf{x}})\) with respect to \(y_{0} ({\mathbf{x}})\) as \(\gamma^{(01)}\) is larger than \(\gamma^{(02)}\). This is consistent with the tuned model parameters \({{\varvec{\uprho}}}\) of the other two MF surrogate models, which shows that MCOK and LMGP models have accurately determined the correlations between the HF model and LF models. Note that the additional model parameter \(\gamma^{(02)}\) of the LMGP model is smaller than that of the MCOK model, which indicates that the LF2 model’s translation reduces its correlation with the HF model. However, for the MCOK model, translation does not have any impact on the learning of their correlation. The predicted contour plots of the four MF surrogate models are sketched in Fig. 6a–d, respectively. Compared with the true HF model, the predicted contour by our proposed MCOK model shares a more accurate variation trend than the other MF models and can correctly identify the locations of local and global optimal domains.

The true model and different MF surrogate models for a two-dimensional test case
3.3 Additional numerical test cases
In this subsection, six additional numerical test cases of different dimensions and numbers of LF models are tested to further demonstrate the effectiveness of the MCOK model. The features of the six numerical test cases are summarized in Table 6, including problem dimension, number of LF models, and sampling configurations for the HF model and each LF model. These cases are all chosen or modified from Cheng et al. (2021) and Zhang et al. (2022), and their detailed mathematical expressions are listed in Appendix 2. For the fairness of model comparison, we no longer intentionally translate the LF models in these numerical test cases.
For each test case, the initial HF and LF samples are randomly and uniformly generated by LHS method. Note that the selection of the number of sample points for HF data and LF data is obtained from Cheng et al. (2021), which suggests that the number of HF samples is about 5–20 times the problem dimension and the number of LF samples for each model is about 4–6 times that of HF samples. To alleviate the influence of the distribution of initial sample points on the modeling accuracy, each case is duplicated 20 times. We also generate 2000 validate sample points randomly by LHS for each test case to calculate the values of three error metrics.
The average values of three error metrics are summarized in Table 7 and the best values of these metrics for different MF surrogate models are marked in bold. It can be seen that the results of our proposed MCOK model have the largest values of R2 and the smallest values of both RMSE and MAE in the six numerical test cases, except for Case No.4, where the local accuracy of the MCOK model is slightly worse than that of the LMGP model. Overall, the MCOK model shows the best prediction performance in both global and local accuracy. The boxplots of R2, RMSE, and MAE for different MF surrogate models are shown in Fig. 7. It is shown that although there exist some outliers of the proposed MCOK model in some cases, it still performs the best among the four MF surrogate models. In general, our proposed MCOK modeling method can be promising and effective in most function problems.


The boxplots of three error metrics results of different MF surrogate models for six test cases
3.4 Engineering test example: aerodynamic data fusion for a hypersonic flight vehicle
To further demonstrate the performance of our proposed MCOK model for engineering problems, we apply it to aerodynamic data fusion for the FDL-5A hypersonic flight vehicle developed by the US Air Force Flight Dynamics Laboratory (Ehrlich 2008), whose baseline configuration is shown in Fig. 8.

Baseline configuration of FDL-5A hypersonic flight vehicle (Ehrlich 2008)
To fuse the aerodynamic force coefficients of the FDL-5A under different configurations and flight conditions, we first parameterize its geometric shape with 22 design variables, i.e., five geometric parameters for the planar shape of its body, six parameters for the middle control section defined by the class-shape transformation (CST) method, three thickness parameters, and eight shape parameters of the vertical fin and elevons, as shown in Fig. 9. We also consider four quantities defining the flight conditions as input variables, giving a total of 26 input variables for building the MF surrogate model; their detailed descriptions and their variation ranges are given in Table 8. Here, the ranges of some of the geometric shape variables are restricted to avoid generating abnormal configurations and causing difficulties in aerodynamic computation.

Parameterized geometry of FDL-5A hypersonic flight vehicle
In this experiment, both RANS and Euler solvers are used for simulating hypersonic flows over changed configurations to establish different datasets with varying fidelities for aerodynamic data fusion. Note that for demonstrating our method and for simplicity, real-gas effects are not considered in the simulations. In order to determine the HF and LF models, the grid convergence for the baseline configuration by RANS and Euler solvers is carried out, with the flow condition being \(Ma = 7.98, \, H = 24.5\;{\text{km}}, \, \alpha = 10^{ \circ }\). The results are shown in Fig. 10 and the zero-grid spacing lift, drag, and pitching moment (Lyu et al. 2015), which were obtained using Richardson’s extrapolation based on RANS results, are also plotted in Fig. 10a. It can be seen that the variation of each aerodynamic coefficient is nearly constant for each grid level, and we finally decide to use the L0 grid and L1 grid with 2 million and 0.5 million cells, respectively, for RANS computations, and the L2 grid and L3 grid with 2 million and 1 million cells, respectively, for Euler computations. These computations grids are sketched in Fig. 11. Table 9 shows the comparison of aerodynamic coefficients computed by different fidelity models and wind tunnel experimental data for baseline configuration, with the relative errors given in the brackets. It can be seen that the RANS results using the L0 Grid have the smallest relative error among the four different fidelity models and hence it is supposed to be the HF CFD model. However, the relative accuracies of the remaining three CFD models are difficult to be assigned as they behave differently for each aerodynamic coefficient. Our proposed MCOK model can handle such non-hierarchical LF datasets without assigning fidelity levels for them, as long as the HF model has been determined. Besides, the zero-grid spacing values by RANS solver are the closest to the experimental data, which also means that using higher fidelity physical model on finer computational grid is more accurate.

Variation of aerodynamic coefficients with respect to grid size (\(Ma = 7.98, \, H = 24.5\;{\text{km}}, \, \alpha = 10^{ \circ }\))

Computational grids for the RANS and Euler computations
We randomly but uniformly generate 150 samples for the HF model and 600 samples for each LF model using LHS method in the aforementioned design space, and establish a training dataset with 1950 samples in total. Then, we additionally generate 450 HF samples for testing the model accuracy. Also, to avoid the influence of initial samples on the modeling accuracy, this experiment is repeated 5 times and each experiment has a different MF dataset of training and testing samples.
The average results of the error metrics for the four MF approaches for this experiment are shown in Table 10 and it can be seen that the proposed MCOK model outperforms the other MF models in terms of both local and global accuracy, with the largest R2 value and the smallest RMSE, MAE values. The LMGP model performs slightly worse than the MCOK model in predicting lift and drag coefficients, but the fusion results for the moment coefficient are comparatively poor. Besides, the results of the other two MF models are significantly worse than that of LMGP and MCOK models. Figure 12 shows the boxplots of three error metrics, which also presents that MCOK model is much more accurate and robust than the other three MF models, with a smaller interquartile range. Figure 13 plots heatmaps of the correlation matrix for CFD models of different fidelities. It can be found that the CFD models applying the same governing equations on different grids are essentially very close to each other and strongly correlated, while the CFD models using different governing equations are dramatically different and are weakly correlated. Hence, our modeling method can construct a more accurate MF model by learning the relationships or correlations among different datasets of various fidelities.

The boxplots of three error metrics results of different MF surrogate models for FDL-5A hypersonic flight vehicle aerodynamic data fusion example

The heatmaps of the correlation matrix for CFD models with different fidelities
4 Conclusions
In this article, a novel multi-fidelity cokriging model, termed as MCOK, is proposed to incorporate multiple non-hierarchical LF datasets with unknown rank of fidelity level or underlying correlations. It can not only avoid fitting surrogate models for every LF dataset, reducing the risk of accuracy loss due to inaccurate LF predictor, but also fully take the effects of cross-covariance among LF models into account, resulting in significant improvement of model accuracy. The proposed MCOK model is validated against a set of numerical test cases of varying dimensions and further demonstrated via an engineering problem of aerodynamic data fusion for FDL-5A hypersonic flight vehicle. Some conclusions can be drawn as follows.
-
(1)
The core idea of MCOK model is to put the covariance and cross-covariance between any two MF sample points into a single matrix, which is simplified by introducing parameter vector “\({{\varvec{\upgamma}}}\)” to account for the cross-correlations between different MF datasets. The parameter vector \({{\varvec{\upgamma}}}\) can be tuned through maximum likelihood estimation, which also provides a promising way for fidelity identification and correlation analysis in some engineering problems.
-
(2)
It is observed that the correlation matrix can be non-positive definite if we directly tune the parameter vector “\({{\varvec{\upgamma}}}\)” and a novel method is proposed to deal with it. The parameters are transformed to the distances between latent points and optimized to quantify the cross-correlations between different datasets. This is crucial for the success of an MCOK model as non-positive definite matrix will lead to the failure of matrix decomposition and hyperparameter tuning.
-
(3)
Compared to the LMGP model, which can also consider the cross-covariances among LF models without building extra surrogate models, our proposed MCOK model is able to handle with multiple MF datasets with large systematic biases, such as aerodynamic data obtained by different physical models. This is because the LMGP model assumes that all random functions for each MF dataset have stationary and the same mean, while our approach assumes that they have stationary but different means, and thus the systematic bias can be eliminated through model training.
-
(4)
The implementation of the proposed MCOK model is as simple as that of a conventional kriging model, such as an ordinary kriging, despite requiring slightly increased computational effort for decomposing a larger correlation matrix. Few modifications are required to turn an ordinary kriging code into an MCOK code.
-
(5)
From current test cases presented herein, it is shown that MCOK model outperforms existing MF surrogate models, such as NHLF-COK, LR-MFS, and LMGP models, with smaller error metrics and standard deviations in the repeated experiments, which makes it more promising for engineering modeling and data fusion problems.
Beyond the scope of this research, we will apply MCOK model to higher-dimensional modeling problems with more input variables to further examine its performance. Besides, the influence of decomposing large correlation matrix of an MCOK model on the modeling efficiency should also be investigated.
Abbreviations
- \({\mathbf{C}}\) :
-
Covariance matrix
- \(C_{L} , \, C_{D} , \, C_{M}\) :
-
Lift, drag, and pitching moment coefficients
- \({\mathbf{c}}\) :
-
Covariance vector
- \({\mathbf{F}}\) :
-
Regression matrix
- \({\mathbf{f}}_{0} ,{\mathbf{f}}_{k}\) :
-
A set of pre-determined regression functions for high-fidelity and the kth low-fidelity dataset
- \(h\) :
-
Number of pre-determined regression functions
- \(L\) :
-
Number of low-fidelity models
- \(Ma\) :
-
Mach number
- \(m\) :
-
Number of dimensions or number of design variables
- \(n_{0} ,n_{k}\) :
-
Number of samples for high-fidelity model and the kth low-fidelity model
- \({\mathbf{R}}\) :
-
Correlation matrix
- \(R\) :
-
Correlation function
- \({\mathbf{r}}\) :
-
Correlation vector
- \({\mathbf{S}}_{0} ,{\mathbf{S}}_{k}\) :
-
Sampling sites for high-fidelity model and the kth low-fidelity model
- \({\mathbf{w}}_{0} ,{\mathbf{w}}_{k}\) :
-
Weight coefficients for high-fidelity function values and the kth low-fidelity function values
- \({\mathbf{x}}_{0} ,{\mathbf{x}}_{k}\) :
-
Independent variables for high-fidelity model and the kth low-fidelity model
- \(Y_{0} ,Y_{k}\) :
-
Random functions for high-fidelity dataset and the kth low-fidelity dataset
- \({\mathbf{y}}_{S,0} ,{\mathbf{y}}_{S,k}\) :
-
Vector of observed function values for high-fidelity model and the kth low-fidelity model
- \(y_{0} ,y_{k}\) :
-
High-fidelity unknown model and the kth low-fidelity unknown model
- \(Z_{0} ( \cdot ),Z_{k} ( \cdot )\) :
-
Gaussian random processes
- \({\mathbf{z}}\) :
-
Coordinates of a latent point
- \(\alpha\) :
-
Angle of attack
- \({{\varvec{\upbeta}}}_{0} ,{{\varvec{\upbeta}}}_{k}\) :
-
Coefficients of regression functions served as the model trend of kriging predictor
- \({{\varvec{\upgamma}}}\) :
-
Additional parameter vector for modeling cross-correlations between two different datasets
- \(\delta\) :
-
Deflection of elevon
- \({{\varvec{\uptheta}}}\) :
-
Hyperparameter vector for spatial correlation function
- \(\mu\) :
-
Lagrange multiplier
- \(\sigma^{2}\) :
-
Process variance
- \({\mathbf{\varphi }}\) :
-
Regression vector
- \(i\) :
-
Index \(\in [1,m]\), Referring to the ith dimension
- \(k,j\) :
-
Index \(\in [1,L]\), referring to the kth or jth level of low-fidelity
- \((p),(q)\) :
-
Index \(\in [1,n_{k} ]\), referring to the pth or qth sample with the kth level of fidelity
- \({{\prime}}\) :
-
New sampling site
- \(\wedge\) :
-
Approximated value
- \(\sim\) :
-
Redefined value
References
Alexandrov NM, Lewis RM, Gumbert CR, Green LL, Newman PA (2001) Approximation and model management in aerodynamic optimization with variable-fidelity models. J Aircraft 38(6):1093–1101
Bandler JW, Biernacki R, Chen SH (1994) Space mapping technique for electromagnetic optimization. IEEE Trans Microw Theory 42(12):2536–2544
Bertram A, Zimmermann R (2018) Theoretical investigations of the new cokriging method for variable-fidelity surrogate modeling: well-posedness and maximum likelihood training. Adv Comput Math 44(6):1693–1716
Bertram A, Othmer C, Zimmermann R (2018) Towards real-time vehicle aerodynamic design via multi-fidelity data-driven reduced order modeling. In: AIAA/ASCE/AHS/ASC structures, structural dynamics, and materials conference
Bu HY, Song LM, Guo ZD, Li J (2022) Selecting scale factor of Bayesian multi-fidelity surrogate by minimizing posterior variance. Chin J Aeronaut 35(11):59–73
Chen SS, Jiang Z, Yang SX, Apley DW, Chen W (2016) Nonhierarchical multi-model fusion using spatial random processes. Int J Numer Methods Eng 106:503–526
Cheng M, Jiang P, Hu JX, Shu LS, Zhou Q (2021) A multi-fidelity surrogate modeling method based on variance-weighted sum for the fusion of multiple non-hierarchical low-fidelity data. Struct Multidisc Optim 64(6):3797–3818
Choi S, Alonso JJ, Kim S, Kroo IM (2009) Two-level multifidelity design optimization studies for supersonic jets. J Aircraft 46(3):776–790
Courrier N, Boucard PA, Soulier B (2016) Variable-fidelity modeling of structural analysis of assemblies. J Glob Optim 64(3):577–613
Ehrlich C (2008) FDL-5A precursor to high performance lifting entry spacecraft: an historical review. In: 15th AIAA international space planes and hypersonic systems and technologies conference
Eweis-Labolle JT, Oune N, Bostanabad R (2022) Data fusion with latent map Gaussian processes. J Mech Des 144(9):091703
Forrester AIJ, Keane AJ (2009) Recent advances in surrogate-based optimization. Prog Aerosp Sci 45(1–3):50–79
Foumani ZZ, Shishehbor M, Yousefpour A, Bostanabad R (2023) Multi-fidelity cost-aware Bayesian optimization. Comput Method Appl Mech Eng 407:115937
Gano SE, Renaud JE, Sanders B (2005) Hybrid variable fidelity optimization by using a kriging-based scaling function. AIAA J 43(11):2422–2430
Gardner JR, Pleiss G, Bindel D, Weinberger KQ, Wilson AG (2018) GpyTorch: blackbox matrix-matrix Gaussian Process inference with GPU acceleration. NeurIPS 2018:7587–7597
Giselle Fernández-Godino M, Park CY, Kim NH, Haftka RT (2019) Issues in deciding whether to use multifidelity surrogates. AIAA J 57(5):2039–2054
Guo ZD, Song LM, Park CY, Li J, Haftka RT (2018) Analysis of dataset selection for multi-fidelity surrogates for a turbine problem. Struct Multidisc Optim 57(6):2127–2142
Haftka RT (1991) Combining global and local approximations. AIAA J 29(9):1523–1525
Han ZH, Görtz S (2012) Hierarchical Kriging model for variable-fidelity surrogate modeling. AIAA J 50(9):1885–1896
Han ZH, Zimmermann R, Görtz S (2010) A new Cokriging method for variable-fidelity surrogate modeling of aerodynamic data. In: 48th AIAA aerospace sciences meeting including the new horizons forum and aerospace exposition
Han ZH, Zimmermann R, Görtz S (2012) An alternative cokriging model for variable-fidelity surrogate modeling. AIAA J 50(5):1205–1210
Han ZH, Görtz S, Zimmermann R (2013) Improving variable-fidelity surrogate mod-eling via gradient-enhanced kriging and a generalized hybrid bridge function. Aerosp Sci Technol 25(1):177–189
Han ZH, Xu CZ, Liang Z, Zhang Y, Zhang KS, Song WP (2020) Efficient aerodynamic shape optimization using variable-fidelity surrogate models and multilevel computational grids. Chin J Aeronaut 33(1):31–47
Hebbal A, Brevault L, Balesdent M, Talbi EG, Melab N (2021) Multi-fidelity modeling with different input domain definitions using deep Gaussian processes. Struct Multidisc Optim 63(5):2267–2288
Jiang P, Xie TL, Zhou Q, Shao XY, Hu JX, Cao LC (2018) A space mapping method based on Gaussian process model for variable fidelity metamodeling. Simul Model Pract Theory 81:64–84
Journel AG, Huijbregts CJ (1978) Mining geostatistics. Academic, London
Kennedy MC, O’Hagan A (2000) Predicting the output from a complex computer code when fast approximations are available. Biometrika 87(1):1–13
Krishnan KVV, Ganguli R (2021) Multi-fidelity analysis and uncertainty quantification of beam vibration using co-kriging interpolation method. Appl Math Comput 398:125987
Le Gratiet SL, Garnier J (2014) Recursive co-kriging model for design of computer experiments with multiple levels of fidelity. Int J Uncertain Quantif 4(5):365–386
Liu HT, Ong YS, Cai JF, Wang Y (2018) Cope with diverse data structures in multi-fidelity modeling: a Gaussian process method. Eng Appl Artif Intell 67:211–225
Liu XW, Zhao WW, Wan DC (2022) Multi-fidelity co-kriging surrogate model for ship hull form optimization. Ocean Eng 243:110239
Lyu ZJ, Kenway GKW, Martins JRRA (2015) Aerodynamic shape optimization investigations of the common research model wing benchmark. AIAA J 53(4):968–985
Oune N, Bostanabad R (2021) Latent map Gaussian processes for mixed variable metamodeling. Comput Method Appl Mech Eng 387:114128
Palar PS, Zuhal LR, Shimoyama K (2020) Gaussian process surrogate model with composite kernel learning for engineering design. AIAA J 58(4):1864–1880
Park C, Haftka RT, Kim NH (2017) Remarks on multi-fidelity surrogates. Struct Multidisc Optim 55(3):1029–1050
Park C, Haftka RT, Kim NH (2018) Low-fidelity scale factor improves Bayesian multi-fidelity prediction by reducing bumpiness of discrepancy function. Struct Multidisc Optim 58(2):399–414
Perdikaris P, Raissi M, Damianou A, Lawrence ND, Karniadakis GE (2017) Nonlinear information fusion algorithms for data-efficient multi-fidelity modelling. Proc R Soc A 473(2198):20160751
Qian PZG, Wu CFJ (2008) Bayesian hierarchical modeling for integrating low-accuracy and high-accuracy experiments. Technometrics 50(2):192–204
Robinson TD, Eldred MS, Willcox KE, Haimes R (2008) Surrogate-based optimization using multifidelity models with variable parameterization and corrected space mapping. AIAA J 46(11):2814–2822
Sacks J, Welch WJ, Mitchell TJ, Wynn HP (1989) Design and analysis of computer experiments. Stat Sci 4(4):409–423
Shi RH, Liu L, Long T, Wu YF, Wang GG (2020) Multi-fidelity modeling and adaptive co-kriging-based optimization for all-electric geostationary orbit satellite systems. J Mech Des 142(2):021404
Simpson TW, Peplinski JD, Koch PN, Allen JK (2001) Metamodels for computer-based engineering design: survey and recommendations. Eng Comput 17(2):129–150
Song XG, Lv LY, Sun W, Zhang J (2019) A radial basis function-based multi-fidelity surrogate model: exploring correlation between high-fidelity and low-fidelity models. Struct Multidisc Optim 60(3):965–981
Ulaganathan S, Couckuyt I, Ferranti F, Laermans E, Dhaene T (2015) Performance study of multi-fidelity gradient enhanced kriging. Struct Multidisc Optim 51:1017–1033
Viana FAC, Simpson TW, Balabanov V, Toropov V (2014) Metamodeling in multidisciplinary design optimization: how far have we really come? AIAA J 52(4):670–690
Xiao MY, Zhang GH, Breitkopf P, Villon P, Zhang WH (2018) Extended Co-Kriging interpolation method based on multi-fidelity data. Appl Math Comput 323:120–131
Yamazaki W, Mavriplis DJ (2013) Derivative-enhanced variable fidelity surrogate modeling for aerodynamic functions. AIAA J 51(1):126–137
Yousefpour A, Foumani ZZ, Shishehbor M, Mora C, Bostanabad R (2023) GP+: a python library for kernel-based learning via Gaussian Processes. arXiv preprint arXiv:2312.07694
Zaytsev A (2016) Reliable surrogate modeling of engineering data with more than two levels of fidelity. In: IEEE International conference on mechanical and aerospace engineering
Zhang YM, Kim NH, Park CY, Haftka RT (2018) Multifidelity surrogate based on single linear regression. AIAA J 56(12):4944–4952
Zhang YC, Tao SY, Chen W, Apley DW (2020) A latent variable approach to Gaussian process modeling with qualitative and quantitative factors. Technometrics 62(3):291–302
Zhang LL, Wu YD, Jiang P, Choi SK, Zhou Q (2022) A multi-fidelity surrogate modeling approach for incorporating multiple non-hierarchical low-fidelity data. Adv Eng Inform 51:101430
Zhou Q, Jiang P, Shao XY, Hu JX, Cao LC, Li W (2017) A variable fidelity information fusion method based on radial basis function. Adv Eng Inform 32:26–39
Zhou Q, Wu YD, Guo ZD, Hu JX, Jin P (2020a) A generalized hierarchical co-kriging model for multi-fidelity data fusion. Struct Multidisc Optim 62(4):1885–1904
Zhou Q, Yang Y, Song XG, Han ZH, Cheng YS, Hu JX, Shu LS, Jiang P (2020b) Survey of multi-fidelity surrogate models and their applications in the design and optimization of engineering equipment. J Mech Eng 56(24):219–245
Zimmermann R, Han ZH (2010) Simplified cross-correlation estimation for multi-fidelity surrogate cokriging models. Adv Appl Math Sci 7(2):181–202
Acknowledgements
This research was supported by the National Natural Science Foundation of China under Grant Nos. 11972305 and U20B2007. The work was carried out at National Supercomputer Center in Tianjin, and the CFD calculations were performed on TianHe-1 (A). The authors thank the original authors of NHLF-COK model, Prof. Qi Zhou and Dr. Lili Zhang, for providing their code to compare the performance of MCOK to NHLK-COK.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Replication of results
The detailed process of the proposed MCOK model is shown in Sect. 2 and the numerical results to support the conclusions can be obtained using existing approaches described in the literature, such as NHLK-COK model by Zhang et al. (2022) and LR-MFS model by Zhang et al. (2018). For the implementation of MCOK model, it is available on request from the corresponding author.
Additional information
Responsible Editor: Ramin Bostanabad
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Details of the comparative methods
1.1 Non-hierarchical co-kriging (NHLF-COK)
The formulation of the NHLF-COK model, which incorporates the data from an HF model and “\(L\)” LF models, can be written as
where \(\rho_{k} \, (k = 1,2, \ldots ,L)\) is the multiplicative scale factor corresponding to the LF model prediction \(\hat{y}_{k} ({\mathbf{x}})\), and \(\hat{y}_{d} ({\mathbf{x}})\) denotes the prediction of a discrepancy model between the HF model and the ensembled L LF models. Note that we continue to use the same nomenclature as that of our MCOK model defined in Nomenclature for consistency.
Then, the covariance matrix that expresses the correlations between the HF and LF datasets can be formally defined as
where \(\sigma_{( \cdot )}^{2}\) denotes the process variance of the LF model and discrepancy model, the notion \({\mathbf{R}}_{k} ({\mathbf{S}}_{i} ,{\mathbf{S}}_{j} )\) represents a matrix of correlations of the form \({\mathbf{R}}_{k}\) between the datasets \({\mathbf{S}}_{i}\) and \({\mathbf{S}}_{j}\), and \({\mathbf{R}}_{d} ({\mathbf{S}}_{0} ,{\mathbf{S}}_{0} )\) represents a matrix of the form \({\mathbf{R}}_{d}\) between the data \({\mathbf{S}}_{0}\) and \({\mathbf{S}}_{0}\). The Gaussian squared exponential function mentioned in Sect. 2.3 can still be chosen as the correlation function here.
In the construction of an NHLF-COK model, there are more model hyperparameters to estimate: \({{\varvec{\uptheta}}}_{d} ,{{\varvec{\uptheta}}}_{k} \, (k = 1,2, \ldots ,L)\) and \(L\) scale factors \(\rho_{k} (k = 1,2, \ldots ,L)\). Here, the hyperparameters \({{\varvec{\uptheta}}}\) of all L LF surrogate models and discrepancy model can be tuned by MLE, while the optimal scale factors \({{\varvec{\uprho}}}\) are obtained by solving a suboptimization problem, whose objective is to minimize the mean second derivative of the prediction value of the discrepancy model, with the following expression:
where \(N\) is the number of validation samples. The interior-point method is adopted here to search for the optimal scale factors.
To obtain the NHLF-COK predictor for any untried \({\mathbf{x}}\), the covariance vector is defined as
Then, the prediction response \(\hat{y}_{0} ({\mathbf{x}})\) can be formulated as
where
By using the standard stochastic-process approach, the MSE of this predictor is given by
1.2 Linear regression multi-fidelity surrogate (LR-MFS)
LR-MFS model shares a similar formulation with the NHLF-COK, but has a different discrepancy model. The basic formulation of LR-MFS is expressed as
where \(\hat{y}_{d} ({\mathbf{x}})\) denotes the discrepancy model that is presented in the form of polynomial response surface (PRS) as
where \(\xi_{j} ({\mathbf{x}})\) denotes the jth monomial basis, and \(b_{j}\) is the unknown coefficient of \(\xi_{j} ({\mathbf{x}})\). A const or low-order polynomials is often used for approximating the discrepancy model due to the limited HF samples. Hence, the LR-MFS predictor is given by
Written in matrix form, Eq. (49) is given by
where
Note that \(n_{0}\) is the number of HF samples, X is the augmented design matrix, and B is the unknown coefficient vector, which can be obtained by the square sum of errors as
where \({\varvec{y}}_{S,0} = \left[ {y_{0} ({\mathbf{x}}^{(1)} ),y_{0} ({\mathbf{x}}^{(2)} ), \ldots ,y_{0} ({\mathbf{x}}^{{(n_{0} )}} )} \right]^{{\text{T}}}\) and the standard regression technique can yield the following form of unknown coefficients:
In this article, a second-order fully expanded polynomial is taken as the discrepancy model.
Appendix 2: Expression about six numerical cases
The expressions of another six numerical test cases used in Sect. 3.2 are listed below.
Case 1
Case 2
Case 3
Case 4
Case 5
Case 6
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xu, C., Han, Z., Zhang, K. et al. A novel multi-fidelity cokriging model assisted by multiple non-hierarchical low-fidelity datasets. Struct Multidisc Optim 67, 52 (2024). https://doi.org/10.1007/s00158-024-03744-8
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00158-024-03744-8