
Abstract
Up-sampling operations are frequently utilized to recover the spatial resolution of feature maps in neural networks for segmentation task. However, current up-sampling methods, such as bilinear interpolation or deconvolution, do not fully consider the relationship of feature maps, which have negative impact on learning discriminative features for semantic segmentation. In this paper, we propose a pixel and channel enhanced up-sampling (PCE) module for low-resolution feature maps, aiming to use the relationship of adjacent pixels and channels for learning discriminative high-resolution feature maps. Specifically, the proposed up-sampling module includes two main operations: (1) increasing spatial resolution of feature maps with pixel shuffle and (2) recalibrating channel-wise high-resolution feature response. Our proposed up-sampling module could be integrated into CNN and Transformer segmentation architectures. Extensive experiments on three different modality datasets of biomedical images, including computed tomography (CT), magnetic resonance imaging (MRI) and micro-optical sectioning tomography images (MOST) demonstrate the proposed method could effectively improve the performance of representative segmentation models.






Similar content being viewed by others
Data Availability
The authors confirm that the Synapse and MSD data supporting the findings of this study are available within the article. But the MOST data are not publicly available.
Code Availability
Not applicable.
References
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L.u., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3431–3440 (2015)
Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 40(4), 834–848 (2018). https://doi.org/10.1109/TPAMI.2017.2699184
Chen, L.-C., Papandreou, G., Schroff, F., Adam, H.: Rethinking Atrous Convolution for Semantic Image Segmentation (2017). https://doi.org/10.48550/arXiv.1706.05587
Jarujareet, U., Wiratchawa, K., Panpisut, P., Intharah, T.: Deepddm: A compact deep-learning assisted platform for micro-rheological assessment of micro-volume fluids. IEEE Access 11, 66467–66477 (2023). https://doi.org/10.1109/ACCESS.2023.3290496
Zheng, S., Lu, J., Zhao, H., Zhu, X., Luo, Z., Wang, Y., Fu, Y., Feng, J., Xiang, T., Torr, P.H.S., Zhang, L.: Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6881–6890 (2021)
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 10012–10022 (2021)
Lin, A., Chen, B., Xu, J., Zhang, Z., Lu, G., Zhang, D.: Ds-transunet: Dual swin transformer u-net for medical image segmentation. IEEE Trans. Instrum. Meas. 71, 1–15 (2022). https://doi.org/10.1109/TIM.2022.3178991
Poudel, R.P.K., Liwicki, S., Cipolla, R.: Fast-SCNN: Fast Semantic Segmentation Network (2019). https://doi.org/10.48550/arXiv.1902.04502
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Paszke, A., Chaurasia, A., Kim, S., Culurciello, E.: ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation (2016). https://doi.org/10.48550/arXiv.1606.02147
Zhang, X., Chen, Z., Wu, Q.M.J., Cai, L., Lu, D., Li, X.: Fast semantic segmentation for scene perception. IEEE Trans. Industr. Inf. 15(2), 1183–1192 (2019). https://doi.org/10.1109/TII.2018.2849348
Noh, H., Hong, S., Han, B.: Learning deconvolution network for semantic segmentation. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 1520–1528 (2015)
Badrinarayanan, V., Kendall, A., Cipolla, R.: Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39(12), 2481–2495 (2017). https://doi.org/10.1109/TPAMI.2016.2644615
Cao, H., Wang, Y., Chen, J., Jiang, D., Zhang, X., Tian, Q., Wang, M.: Swin-unet: Unet-like pure transformer for medical image segmentation. In: Karlinsky, L., Michaeli, T., Nishino, K. (eds.) Computer Vision – ECCV 2022 Workshops, pp. 205–218. Springer, Cham (2023). https://doi.org/10.1007/978-3-031-25066-8_9
Chen, M.-J., Huang, C.-H., Lee, W.-L.: A fast edge-oriented algorithm for image interpolation. Image Vis. Comput. 23(9), 791–798 (2005). https://doi.org/10.1016/j.imavis.2005.05.005
Asuni, N., Giachetti, A.: Accuracy improvements and artifacts removal in edge based image interpolation. In: Proceedings of the Third International Conference on Computer Vision Theory and Applications - Volume 1: VISAPP, (VISIGRAPP 2008), vol. 2, pp. 58–65. SciTePress, Funchal (2008). https://doi.org/10.5220/0001074100580065
Seo, H., Huang, C., Bassenne, M., Xiao, R., Xing, L.: Modified u-net (mu-net) with incorporation of object-dependent high level features for improved liver and liver-tumor segmentation in ct images. IEEE Trans. Med. Imaging 39(5), 1316–1325 (2020). https://doi.org/10.1109/TMI.2019.2948320
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7132–7141 (2018)
Wang, Q., Wu, B., Zhu, P., Li, P., Zuo, W., Hu, Q.: Eca-net: Efficient channel attention for deep convolutional neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11534–11542 (2020)
Nair, V., Hinton, G.E.: Rectified linear units improve restricted boltzmann machines. In: Proceedings of the 27th International Conference on Machine Learning (ICML-10), pp. 807–814 (2010)
Li, A., Gong, H., Zhang, B., Wang, Q., Yan, C., Wu, J., Liu, Q., Zeng, S., Luo, Q.: Micro-optical sectioning tomography to obtain a high-resolution atlas of the mouse brain. Science 330(6009), 1404–1408 (2010). https://doi.org/10.1126/science.1191776
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 801–818 (2018)
Zhao, H., Shi, J., Qi, X., Wang, X., Jia, J.: Pyramid scene parsing network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2881–2890 (2017)
Chaurasia, A., Culurciello, E.: Linknet: Exploiting encoder representations for efficient semantic segmentation. In: 2017 IEEE Visual Communications and Image Processing (VCIP), pp. 1–4 (2017). https://doi.org/10.1109/VCIP.2017.8305148
Chen, J., Lu, Y., Yu, Q., Luo, X., Adeli, E., Wang, Y., Lu, L., Yuille, A.L., Zhou, Y.: TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation (2021). https://doi.org/10.48550/arXiv.2102.04306
Xu, G., Wu, X., Zhang, X., He, X.: LeViT-UNet: Make Faster Encoders with Transformer for Medical Image Segmentation (2021). https://doi.org/10.48550/arXiv.2107.08623
Wang, Y., Zhou, Q., Xiong, J., Wu, X., Jin, X.: Esnet: An efficient symmetric network for real-time semantic segmentation. In: Lin, Z., Wang, L., Yang, J., Shi, G., Tan, T., Zheng, N., Chen, X., Zhang, Y. (eds.) Pattern Recognition and Computer Vision, pp. 41–52. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-31723-2_4
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778 (2016)
Acknowledgements
This work is supported by the Guangdong Provincial Key Laboratory of Human Digital Twin (No. 2022B1212010004), the Open-Fund of WNLO (Grant No. 2018WNLOKF027) and the Graduate Innovative Fund of Wuhan Institute of Technology (No. CX2022349). We thank the Optical Bioimaging Core Facility of WNLO-HUST for the support in MOST data acquisition.
Funding
Funding for this study was received from the Guangdong Provincial Key Laboratory of Human Digital Twin (No. 2022B1212010004), the Fundamental Research Funds for the Central Universities of China (Grant No. PA2023IISL0095) and the Graduate Innovative Fund of Wuhan Institute of Technology (No.CX2022349).
Author information
Authors and Affiliations
Contributions
Not applicable.
Corresponding author
Ethics declarations
Conflict of interest
We confirm that there are no known conflicts of interest associated with this publication and there has been no significant financial support for this work that could have influenced its outcome.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
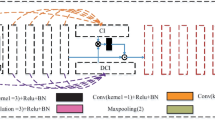
The details how to plug into the PCE into other architectures are presented in the appendix part. Specifically, the PCE module proposed in this paper can be seamlessly integrated into other segmentation architectures, as illustrated in Figs. 5 and 6. The PCE module can directly replace the up-sampling module (indicated by the red block and red arrows in the figures) in U-Net and Fast-SCNN models, improving segmentation accuracy compared to traditional up-sampling modules.
The two different phases in the PCE module provide different functions, and in order to determine the contribution of the key components in the PCE to its success, ablation experiments were performed on both aspects as shown in Table 4. We found that it could increase 0.82% Dice by integrating with the global relationship in our up-sampling module. Moreover, the experimental results demonstrate the PS (Pixel Shuffle) in our PCE module is more critical for segmentation task.
The experiments demonstrate the effectiveness of the global relationship enhancement feature. In addition, we conducted ablation experiments on the attention mechanism in the PCE module, as shown in Table 5. After replacing the attention mechanism in the PCE module with SE or ECA in turn, the segmentation results are all decreased. The segmentation result of the attention mechanism proposed in this paper is 87.79%. Compared with other attention mechanisms, the method of enhancing global relations proposed in this paper is more advantageous.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhang, X., Xu, G., Wu, X. et al. A pixel and channel enhanced up-sampling module for biomedical image segmentation. Machine Vision and Applications 35, 30 (2024). https://doi.org/10.1007/s00138-024-01513-7
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00138-024-01513-7