
Abstract
Key message
We propose an “enviromics” prediction model for recommending cultivars based on thematic maps aimed at decision-makers.
Abstract
Parsimonious methods that capture genotype-by-environment interaction (GEI) in multi-environment trials (MET) are important in breeding programs. Understanding the causes and factors of GEI allows the utilization of genotype adaptations in the target population of environments through environmental features and factor-analytic (FA) models. Here, we present a novel predictive breeding approach called GIS-FA, which integrates geographic information systems (GIS) techniques, FA models, partial least squares (PLS) regression, and enviromics to predict phenotypic performance in untested environments. The GIS-FA approach enables: (i) the prediction of the phenotypic performance of tested genotypes in untested environments, (ii) the selection of the best-ranking genotypes based on their overall performance and stability using the FA selection tools, and (iii) the creation of thematic maps showing overall or pairwise performance and stability for decision-making. We exemplify the usage of the GIS-FA approach using two datasets of rice [Oryza sativa (L.)] and soybean [Glycine max (L.) Merr.] in MET spread over tropical areas. In summary, our novel predictive method allows the identification of new breeding scenarios by pinpointing groups of environments where genotypes demonstrate superior predicted performance. It also facilitates and optimizes cultivar recommendations by utilizing thematic maps.









Similar content being viewed by others

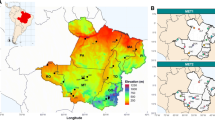

Data availability
The R codes and both datasets used in this study are freely available: https://github.com/Kaio-Olimpio/GIS-FA. Supplementary Material contains a detailed tutorial with a commented script describing the steps for performing GIS-FA analysis with the soybean dataset.
References
Aastveit AH, Martens H (1986) ANOVA interactions interpreted by partial least squares regression. Biometrics 42(4):829–844. https://doi.org/10.2307/2530697
Alvares CA, Stape JL, Sentelhas PC et al (2013) Köppen’s climate classification map for Brazil. Meteorol Zeitschrift 22:711–728. https://doi.org/10.1127/0941-2948/2013/0507
Annicchiarico P, Bellah F, Chiari T (2006) Repeatable genotype \(\times\) location interaction and its exploitation by conventional and GIS-based cultivar recommendation for durum wheat in algeria. Eur J Agron 24:70–81. https://doi.org/10.1016/j.eja.2005.05.003
Baddeley A, Rubak E, Turner R (2015) Spatial point patterns: methodology and applications with R. J Stat Softw 75:1–6. https://doi.org/10.18637/jss.v075.b02
Balestre M, Von Pinho RG, Souza JC et al (2009) Genotypic stability and adaptability in tropical maize based on AMMI and GGE biplot analysis. Genet Mol Res 8(4):1311–1322. https://doi.org/10.4238/vol8-4gmr658
Beebe S, Lynch J, Galwey N et al (1997) A geographical approach to identify phosphorus-efficient genotypes among landraces and wild ancestors of common bean. Euphytica 95:325–338. https://doi.org/10.1023/A:1003008617829
Buntaran H, Forkman J, Piepho HP (2021) Projecting results of zoned multi-environment trials to new locations using environmental covariates with random coefficient models: accuracy and precision. Theor Appl Genet 134:1513–1530. https://doi.org/10.1007/s00122-021-03786-2
Bustos-Korts D, Boer MP, Layton J et al (2022) Identification of environment types and adaptation zones with self-organizing maps: applications to sunflower multi-environment data in europe. Theor Appl Genet 135:2059–2082. https://doi.org/10.1007/s00122-022-04098-9
CFSR (2018) Climate forecast system reanalysis (CFSR), for 1979 to 2011. https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.ncdc:C00765/
Chaves SFS, Alves RS, Dias LAS et al (2023) Analysis of repeated measures data through mixed models: an application in Theobroma grandiflorum breeding. Crop Sci 63(4):2131–2144. https://doi.org/10.1002/csc2.20995
Chaves SFS, Evangelista JSPC, Trindade RS et al (2023) Employing factor analytic tools for selecting high-performance and stable tropical maize hybrids. Crop Sci 63(3):1114–1125. https://doi.org/10.1002/csc2.20911
CHELSA (2023) Climatologies at high resolution for the earth’s land surface areas. https://chelsa-climate.org/
Cooper M, Delacy IH (1994) Relationships among analytical methods used to study genotypic variation and genotype-by-environment interaction in plant breeding multi-environment experiments. Theor Appl Genet 88:561–572. https://doi.org/10.1007/BF01240919
Cooper M, Messina CD (2021) Can we harness “enviromics’’ to accelerate crop improvement by integrating breeding and agronomy? Front Plant Sci 12(735):143. https://doi.org/10.3389/fpls.2021.735143
Cooper M, Messina CD, Podlich D et al (2014) Predicting the future of plant breeding: complementing empirical evaluation with genetic prediction. Crop Pasture Sci 65:311. https://doi.org/10.1071/CP14007
Cooper M, Messina CD, Tang T et al (2022) Predicting genotype \(\times\) environment \(\times\) management (G\(\times\)E\(\times\)M) interactions for the design of crop improvement strategies, pp 467–585. https://doi.org/10.1002/9781119874157.ch8
Costa-Neto G, Fritsche-Neto R (2021) Enviromics: bridging different sources of data, building one framework. Crop Breed Appl Biotechnol 21:e393,521S12. https://doi.org/10.1590/1984-70332021v21Sa25
Costa-Neto G, Morais Júnior OP, Heinemann AB et al (2020) A novel GIS-based tool to reveal spatial trends in reaction norm: upland rice case study. Euphytica 216:37. https://doi.org/10.1007/s10681-020-2573-4
Costa-Neto G, Crossa J, Fritsche-Neto R (2021a) Enviromic assembly increases accuracy and reduces costs of the genomic prediction for yield plasticity in maize. Front Plant Sci 12(717):552. https://doi.org/10.3389/fpls.2021.717552
Costa-Neto G, Fritsche-Neto R, Crossa J (2021b) Nonlinear kernels, dominance, and envirotyping data increase the accuracy of genome-based prediction in multi-environment trials. Heredity 126(1):92–106. https://doi.org/10.1038/s41437-020-00353-1
Costa-Neto G, Galli G, Carvalho HF et al (2021c) EnvRtype: a software to interplay enviromics and quantitative genomics in agriculture. G3 Genes|Genomes|Genetics 11(4):jkab040. https://doi.org/10.1093/g3journal/jkab040
Costa-Neto G, Crespo-Herrera L, Fradgley N et al (2022) Envirome-wide associations enhance multi-year genome-based prediction of historical wheat breeding data. G3: Genes|Genomes|Genetics 13(2):jkac313. https://doi.org/10.1093/g3journal/jkac313
Cowling WA, Castro-Urrea FA, Stefanova KT et al (2023) Optimal contribution selection improves the rate of genetic gain in grain yield and yield stability in spring canola in Australia and Canada. Plants 12:383. https://doi.org/10.3390/plants12020383
Crossa J (2012) From genotype \(\times\) environment interaction to gene \(\times\) environment interaction. Curr Genom. 13(3):225–244. https://doi.org/10.2174/138920212800543066
Crossa J, Vargas M, Van Eeuwijk FA et al (1999) Interpreting genotype\(\times\) environment interaction in tropical maize using linked molecular markers and environmental covariables. Theor Appl Genet 99:611–625. https://doi.org/10.1007/s001220051276
Crossa J, Yang RC, Cornelius PL (2004) Studying crossover genotype \(\times\) environment interaction using linear-bilinear models and mixed models. J Agric Biol Environ Stat 9(3):362–380. https://doi.org/10.1198/108571104x4423
Crossa J, Montesinos-López OA, Crespo Herrera LA et al (2023) Do feature selection methods for selecting environmental covariables enhance genomic prediction accuracy? Front Genet 14:7016. https://doi.org/10.3389/fgene.2023.1209275
Cullis BR, Smith AB, Coombes NE (2006) On the design of early generation variety trials with correlated data. J Agric Biol Environ Stat 11:381. https://doi.org/10.1198/108571106X154443
Cullis B, Beeck CP, Cowling WA (2010) Analysis of yield and oil from a series of canola breeding trials. Part II. Exploring variety by environment interaction using factor analysis. Genome 53:1002–1016. https://doi.org/10.1139/G10-080
Cullis BR, Jefferson P, Thompson R et al (2014) Factor analytic and reduced animal models for the investigation of additive genotype-by-environment interaction in outcrossing plant species with application to a Pinus radiata breeding programme. Theor Appl Genet 127:2193–2210. https://doi.org/10.1007/s00122-014-2373-0
Dayal BS, MacGregor JF (1997) Improved PLS algorithms. J Chemom 11(1):73–85
de los Campos G, Pérez-Rodréguez P, Bogard M et al (2020) A data-driven simulation platform to predict cultivars’ performances under uncertain weather conditions. Nat Commun 11:4876. https://doi.org/10.1038/s41467-020-18480-y
Denis BJ (1988) Two way analysis using covariates. Statistics 19(1):123–132. https://doi.org/10.1080/02331888808802080
Dias KOG, Gezan SA, Guimarães CT et al (2018) Improving accuracies of genomic predictions for drought tolerance in maize by joint modeling of additive and dominance effects in multi-environment trials. Heredity 121:24–37. https://doi.org/10.1038/s41437-018-0053-6
Dias KOG, Santos JPR, Krause MD et al (2022) Leveraging probability concepts for cultivar recommendation in multi-environment trials. Theor Appl Genet 135:1385–1399. https://doi.org/10.1007/s00122-022-04041-y
Diepenbrock CH, Tang T, Jines M et al (2022) Can we harness digital technologies and physiology to hasten genetic gain in us maize breeding? Plant Physiol 188(2):1141–1157. https://doi.org/10.1093/plphys/kiab527
Dunnington D (2023) ggspatial: spatial data framework for ggplot2. https://CRAN.R-project.org/package=ggspatial, r package version 1.1.8
Eberhart SA, Russell WA (1966) Stability parameters for comparing varieties. Crop Sci 6:36–40. https://doi.org/10.2135/cropsci1966.0011183X000600010011x
ECMWF (2023) European centre for medium-range weather forecasts. https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.ncdc:C00765/
EOSDIS (2023) Nasa earth observing system data and information system. https://worldview.earthdata.nasa.gov
FAO (2014) World reference base for soil resources 2014. www.fao.org/3/i3794en/I3794en.pdf
Fick SE, Hijmans RJ (2017) WorldClim 2: new 1-km spatial resolution climate surfaces for global land areas. Int J Climatol 32:4302–4315. https://doi.org/10.1002/joc.5086
Finlay K, Wilkinson G (1963) The analysis of adaptation in a plant-breeding programme. Aust J Agric Res 14:742. https://pdf.usaid.gov/pdf_docs/PNAAS139.pdf
Gauch HG Jr, Zobel R (1997) Identifying mega-environments and targeting genotypes. Crop Sci 37:311–326. https://doi.org/10.2135/cropsci1997.0011183X003700020002x
GHCNd (2023) Global historical climatology network daily. https://www.ncei.noaa.gov/products/land-based-station/global-historical-climatology-network-daily/
Gilmour AR, Cullis B, Verbyla Ap (1997) Accounting for natural and extraneous variation in the analysis of field experiment. J Agric Biol Environ Stat 2:269–293. https://doi.org/10.2307/1400446
Gogel B, Smith A, Cullis B (2018) Comparison of a one- and two-stage mixed model analysis of Australia’s national variety trial southern region wheat data. Euphytica 214:44. https://doi.org/10.1007/s10681-018-2116-4
Guarino L, Jarvis A, Hijmans RJ et al (2002) Geographic information systems (GIS) and the conservation and use of plant genetic resources. In: Managing plant genetic diversity. Proceedings of an international conference, Kuala Lumpur, Malaysia, 12–16 June 2000, CABI publishing, Wallingford, pp 387–404
Guo Y, Xiang H, Li Z et al (2021) Prediction of rice yield in East China based on climate and agronomic traits data using artificial neural networks and partial least squares regression. Agronomy 11(2):282. https://doi.org/10.3390/agronomy11020282
Hartung J, Piepho HP (2021) Effect of missing values in multi-environmental trials on variance component estimates. Crop Sci 61(6):4087–4097. https://doi.org/10.1002/csc2.20621
Heinemann AB, Costa-Neto G, Fritsche-Neto R et al (2022) Enviromic prediction is useful to define the limits of climate adaptation: a case study of common bean in Brazil. Field Crop Res 286(108):628. https://doi.org/10.1016/j.fcr.2022.108628
Henderson CR (1949) Estimates of changes in herd environment. J Dairy Sci 61:294–300
Henderson CR (1950) Estimation of genetic parameters. Ann Math Stat 21:309–310
Hernández MV, Ortiz-Monasterio I, Pérez-Rodríguez P et al (2019) Modeling genotype \(\times\) environment interaction using a factor analytic model of on-farm wheat trials in the Yaqui Valley of Mexico. Agron J 111(6):2647–2657. https://doi.org/10.2134/agronj2018.06.0361
Hijmans R (2020) raster: Geographic data analysis and modeling. R package version 3.6-3. https://CRAN.R-project.org/package=raster
Hijmans RJ, Barbosa M, Ghosh A et al (2023) geodata: Download geographic data. https://CRAN.R-project.org/package=geodata, r package version 0.5-8
Jarquún D, Crossa J, Lacaze X et al (2014) A reaction norm model for genomic selection using high-dimensional genomic and environmental data. Theor Appl Genet 127(3):595–607. https://doi.org/10.1007/s00122-013-2243-1
Jarquún D, de Leon N, Romay C et al (2021) Utility of climatic information via combining ability models to improve genomic prediction for yield within the genomes to fields maize project. Front Genet 11(592):769. https://doi.org/10.3389/fgene.2020.592769
Krause MD, Dias KOG, Singh AK et al (2022) Using large soybean historical data to study genotype by environment variation and identify mega-environments with the integration of genetic and non-genetic factors. bioRxiv 4:487885. https://doi.org/10.1101/2022.04.11.487885
Lembrechts JJ, van den Hoogen J, Aalto J et al (2022) Global maps of soil temperature. Glob Chang Biol 28(9):3110–3144. https://doi.org/10.1111/gcb.16060
Li X, Guo T, Mu Q et al (2018) Genomic and environmental determinants and their interplay underlying phenotypic plasticity. Proc Natl Acad Sci 115(26):6679–6684. https://doi.org/10.1073/pnas.1718326115
Liland KH, Mevik BH, Wehrens R (2022) PLS: partial least squares and principal component regression. https://CRAN.R-project.org/package=pls, r package version 2.8-1
Lindgren F, Geladi P, Wold S (1993) The kernel algorithm for PLS. J Chemom 7(1):45–59. https://doi.org/10.1002/cem.1180070104
Lynch M, Walsh B (1998) Genetics and analysis of quantitative traits, 1st edn. Sinauer Associates, Sunderland
Malosetti M, Ribaut JM, Eeuwijk FAV (2013) The statistical analysis of multi-environment data: modeling genotype-by-environment interaction and its genetic basis. Genet Sel Evol 4:44. https://doi.org/10.3389/fphys.2013.00044
Meuwissen THE, Hayes BJ, Goddard ME (2001) Prediction of total genetic value using genome-wide dense marker maps. Genetics 157(1819–1829):11290733
Millet EJ, Kruijer W, Coupel-Ledru A et al (2019) Genomic prediction of maize yield across European environmental conditions. Nat Genet 51(6):952–956. https://doi.org/10.1038/s41588-019-0414-y
Monteverde E, Gutierrez L, Blanco P et al (2019) Integrating molecular markers and environmental covariates to interpret genotype by environment interaction in rice (Oryza sativa L.) grown in subtropical areas. G3 Genes|Genomes|Genetics 9(5):1519–1531. https://doi.org/10.1534/g3.119.400064
Montesinos-López OA, Montesinos-López A, Kismiantini, Roman-Gallardo A et al (2022a) Partial least squares enhances genomic prediction of new environments. Front Genet 13:920689. https://doi.org/10.3389/fgene.2022.920689848
Montesinos-López OA, Montesinos-López A, Sandoval DAB et al (2022b) Multi-trait genome prediction of new environments with partial least squares. Front Genet 13:966775. https://doi.org/10.3389/fgene.2022.966775851
Mrode RA (2014) Linear models for the prediction of animal breeding values, 3rd edn. CABI
NasaPower (2022) Prediction of worldwide energy resource. https://power.larc.nasa.gov/data-access-viewer
NOAA (2023) Climate data online. https://www.ncei.noaa.gov/cdo-web
Nuvunga JJ, Silva CP, Oliveira LA et al (2019) Bayesian factor analytic model: an approach in multiple environment trials. PLoS ONE 14(8):e0220290. https://doi.org/10.1371/journal.pone.0220290
Oliveira IC, Guilhen JHS, Ribeiro PCO et al (2020) Genotype-by-environment interaction and yield stability analysis of biomass sorghum hybrids using factor analytic models and environmental covariates. Field Crop Res 257(107):929. https://doi.org/10.1016/j.fcr.2020.107929
Ortiz R, Crossa J, Vargas M et al (2007) Studying the effect of environmental variables on the genotype \(\times\) environment interaction of tomato. Euphytica 153:119–134. https://doi.org/10.1007/s10681-006-9248-7
Ortiz R, Reslow F, Montesinos-López A et al (2023) Partial least squares enhance multi-trait genomic prediction of potato cultivars in new environments. Sci Rep 13(1):9947. https://doi.org/10.1038/s41598-023-37169-y
Patterson HD, Thompson R (1971) Recovery of inter-block information when block sizes are unequal. Biometrika 58:545–554. https://doi.org/10.2307/2334389
Pebesma E, Bivand R (2023) Spatial data science: with applications in R. https://r-spatial.org/book/
Piepho HP (1997) Analysis of a randomized block design with unequal subclass numbers. Agron J 89:718–723. https://doi.org/10.2134/agronj1997.00021962008900050002x
Piepho HP (2019) A coefficient of determination (r\(^{2}\)) for generalized linear mixed models. Biom J 61(4):860–872. https://doi.org/10.1002/bimj.201800270
Piepho H, Möhring J (2006) Selection in cultivar trials–is it ignorable? Crop Sci 46(1):192–201. https://doi.org/10.2135/cropsci2005.04-0038
Piepho HP, Möhring J, Melchinger AE et al (2008) BLUP for phenotypic selection in plant breeding and variety testing. Euphytica 161:209–228. https://doi.org/10.1007/s10681-007-9449-8
Porker K, Coventry S, Fettell N et al (2020) Using a novel PLS approach for envirotyping of barley phenology and adaptation. Field Crop Res 246(107):697. https://doi.org/10.1016/j.fcr.2019.107697
R Core Team (2023) R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/
Ramburan S, Zhou M, Labuschagne M (2012) Integrating empirical and analytical approaches to investigate genotype-environment interactions in sugarcane. Crop Sci 52(5):2153–2165. https://doi.org/10.2135/cropsci2012.02.0128
Resende RT, Piepho HP, Rosa GJM et al (2021) Enviromics in breeding: applications and perspectives on envirotypic-assisted selection. Theor Appl Genet 134:95–121. https://doi.org/10.1007/s00122-020-03684-z
Rincent R, Malosetti M, Ababaei B et al (2019) Using crop growth model stress covariates and AMMI decomposition to better predict genotype-by-environment interactions. Theor Appl Genet 132(12):3399–3411. https://doi.org/10.1007/s00122-019-03432-y
Rogers AR, Dunne JC, Romay C et al (2021) The importance of dominance and genotype-by-environment interactions on grain yield variation in a large-scale public cooperative maize experiment. G3: Genes|Genomes|Genetics 11(2):jkaa050. https://doi.org/10.1093/g3journal/jkaa050
Sae-Lim P, Komen H, Kause A et al (2014) Identifying environmental variables explaining genotype-by-environment interaction for body weight of rainbow trout (Onchorynchus mykiss): reaction norm and factor analytic models. Genet Sel Evol 46(16):1–11. https://doi.org/10.1186/1297-9686-46-16
Santos HG (2018) Sistema brasileiro de classificação de solos (in Portuguese), 5th edn. Embrapa, Brasília, DF. https://www.embrapa.br/en/busca-de-publicacoes/-/publicacao/1094003/sistema-brasileiro-de-classificacao-de-solos
Shelford VE (1911) Animal communities in temperate America as illustrated in the Chicago region. Biol Bull 21:95–167. https://doi.org/10.5962/bhl.title.34437
Silva KJ, Teodoro PE, da Silva MJ et al (2021) Identification of mega-environments for grain sorghum in Brazil using GGE biplot methodology. Agron J 113:1–12. https://doi.org/10.1002/agj2.20707
Smith AB, Cullis BR (2018) Plant breeding selection tools built on factor analytic mixed models for multi-environment trial data. Euphytica 214:143. https://doi.org/10.1007/s10681-018-2220-5
Smith AB, Cullis B, Thompson R (2001) Analyzing variety by environment data using multiplicative mixed models and adjustments for spatial field trend. Biometrics 57:1138–1147. https://doi.org/10.1111/j.0006-341X.2001.01138.x
Smith AB, Ganesalingam A, Kuchel H et al (2015) Factor analytic mixed models for the provision of grower information from national crop variety testing programs. Theor Appl Genet 128:55–72. https://doi.org/10.1007/s00122-014-2412-x
Smith A, Norman A, Kuchel H et al (2021) Plant variety selection using interaction classes derived from factor analytic linear mixed models: models with independent variety effects. Front Plant Sci 12(978):248. https://doi.org/10.3389/fpls.2021.737462
SoilGrids (2022) Soilgrids—global gridded soil information. https://www.isric.org/explore/soilgrids/
Sparks AH (2018) NasaPower: a NASA power global meteorology, surface solar energy and climatology data client for R. J Open Source Softw 3(30):1035. https://doi.org/10.21105/joss.01035
Stefanova KT, Buirchell B (2010) Multiplicative mixed models for genetic gain assessment in lupin breeding. Crop Sci 50(3):880–891. https://doi.org/10.2135/cropsci2009.07.0402
The VSNi Team (2023) asreml: Fits linear mixed models using REML. www.vsni.co.uk, r package version 4.2.0.267
Thompson R, Cullis B, Smith A et al (2003) A sparse implementation of the average information algorithm for factor analytic and reduced rank variance models. Aust N Z J Stat 45(4):445–459. https://doi.org/10.1111/1467-842X.00297
Tolhurst DJ, Gaynor RC, Gardunia B et al (2022) Genomic selection using random regressions on known and latent environmental covariates. Theor Appl Genet 135:3393–3415. https://doi.org/10.1007/s00122-022-04186-w
Van Eeuwijk FA, Elgersma A (1993) Incorporating environmental information in an analysis of genotype by environment interaction for seed yield in perennial ryegrass. Heredity 70(5):447–457. https://doi.org/10.1038/hdy.1993.66
van Eeuwijk FA, Bustos-Korts DV, Malosetti M (2016) What should students in plant breeding know about the statistical aspects of genotype \(\times\) environment interactions? Crop Sci 56(5):2119–2140. https://doi.org/10.2135/cropsci2015.06.0375
Vargas M, Crossa J, Van Eeuwijk F et al (2001) Interpreting treatment-environment interaction in agronomy trials. Agron J 93(4):949–960. https://doi.org/10.2134/agronj2001.934949x
Vargas M, van Eeuwijk FA, Crossa J et al (2006) Mapping QTLs and QTL \(\times\) environment interaction for CIMMYT maize drought stress program using factorial regression and partial least squares methods. Theor Appl Genet 112(6):1009–1023. https://doi.org/10.1007/s00122-005-0204-z
Wickham H (2016) ggplot2: elegant graphics for data analysis, 2nd edn. Springer, Cham
Wold HOA (1966) Estimation of principal components and related models by iterative least squares. Academic Press, New York
Wold S, Sjöström M, Eriksson L (2001) PLS-regression: a basic tool of chemometrics. Chemom Intell Lab Syst 58:109–130. https://doi.org/10.1016/S0169-7439(01)00155-1
Wong J (2022) Pdist: partitioned distance function. https://CRAN.R-project.org/package=pdist, r package version 1.2.1
Wood J (1976) The use of environmental variables in the interpretation of genotype–environment interaction. Heredity 37(1):1–7. www.nature.com/articles/hdy197661
Xu Y (2016) Envirotyping for deciphering environmental impacts on crop plants. Theor Appl Genet 129:653–673. https://doi.org/10.1007/s00122-016-2691-5
Yan W, Hunt LA, Sheng Q et al (2000) Cultivar evaluation and mega-environment investigation based on the GGE biplot. Crop Sci 40:597–605. https://doi.org/10.2135/cropsci2000.403597x
Yan W, Kang MS, Ma B et al (2007) GGE biplot vs. AMMI analysis of genotype-by-environment data. Crop Sci 47:643–653. https://doi.org/10.2135/cropsci2006.06.0374
Yates F, Cochran WG (1938) The analysis of groups of experiments. J Agric Sci 28:556–580. https://doi.org/10.1017/S0021859600050978
Acknowledgements
This work was supported by the Minas Gerais State Agency for Research and Development (FAPEMIG), the Brazilian National Council for Scientific and Technological Development (CNPq), Coordination for the Improvement of Higher Education Personnel (CAPES), the Mato Grosso do Sul Foundation (Fundação MS), the Brazilian Agricultural Research Corporation (Embrapa Rice and Beans), and the Federal University of Viçosa (UFV).
Funding
This research was supported by the Minas Gerais State Agency for Research and Development (FAPEMIG), the Coordination for the Improvement of Higher Education Personnel (CAPES), and the Brazilian National Council for Scientific and Technological Development (CNPq). Fundação de Amparo à Pesquisa do Estado de Minas Gerais. Coordenação de Aperfeiçoamento de Pessoal de Nível Superior. Conselho Nacional de Desenvolvimento Científico e Tecnológico.
Author information
Authors and Affiliations
Contributions
M.S.A., S.F.S.C., and K.O.G.D. conceived the research. M.S.A. and S.F.S.C. executed the statistical analyses and drafted the initial manuscript. M.D.K. and G.C.N. provided insights into the methodology. L.A.S.D., F.M.F., G.R.P., R.S.A., P.C.S.C., M.D.K., and G.C.N. provided critical revisions of the paper drafts. A.R.G.B. provided knowledge on the structure of the soybean dataset, while A.B.H. and F.B. provided information about the rice dataset. M.S.A., S.F.S.C., and M.D.K. built the tutorial available in the Supplementary Material. All authors approved the final version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Communicated by Hiroyoshi Iwata.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: Partial least squares regression
Appendix A: Partial least squares regression
Here, we employed the kernel PLS algorithm (Lindgren et al. 1993; Dayal and MacGregor 1997) to predict the factor loadings of untested environments. Details about this algorithm are presented below:
Take the following multiple regressions as a starting point:
where \(\hat{\boldsymbol{\Lambda }}^\star\) is the \(J \times K\) matrix of K rotated loadings for the J observed environments, \(\textbf{W}\) is a \(J \times P\) matrix of scaled values for P environmental features in the J observed environments, \(\textbf{B}\) is a \(P \times K\) vector of coefficients, and \(\textbf{E}\) is a \(J \times K\) matrix of lack of fit effects. Note that most of the environmental features are correlated (Supplementary Figure 4), so \(\textbf{W}\) has multicollinearity problems, and \(\textbf{B} = (\textbf{W}^\prime \textbf{W})^{-1} \textbf{W}^\prime \hat{\boldsymbol{\Lambda }}^\star\) does not yield a proper solution. To overcome this issue, we employed kernel PLS regression to transform \(\textbf{B}\) into \(\textbf{B}^*\), using the following equation:
where \(\boldsymbol{\Phi }\) is a \(P \times C\) matrix of weights for \(\textbf{W}\) (\(\boldsymbol{\Phi } = \{\boldsymbol{\phi }_1 \, \boldsymbol{\phi }_2 \, \ldots \boldsymbol{\phi }_C \}\)), with C being the number of PLS components; \(\boldsymbol{\Theta }\) is a matrix of loadings for \(\textbf{W}\) (\(\boldsymbol{\Theta } = \{\boldsymbol{\theta }_1 \, \boldsymbol{\theta }_2 \, \ldots \boldsymbol{\theta }_C \}\)) and has the same dimension as \(\boldsymbol{\Phi }\), and \(\boldsymbol{\Xi }\) is a \(K \times C\) matrix of weights for \(\boldsymbol{\Lambda }\) (\(\boldsymbol{\Xi } = \{\boldsymbol{\xi }_1 \boldsymbol{\xi }_2 \ldots \boldsymbol{\xi }_C\}\)). We describe the CV procedure that defined the number of components (\(c = 1, 2, \ldots , C\)) in section Spatial predictions in the breeding zone. \(\boldsymbol{\Phi }\), \(\boldsymbol{\Theta }\), and \(\boldsymbol{\Xi }\) were defined using an iterative process that leveraged the kernel functions of \(\textbf{W}\) and \(\boldsymbol{\Lambda }\). First, \(\boldsymbol{\phi }_c\) is estimated as the eigenvector that is equivalent to the largest eigenvalue of the kernel \(\textbf{W}^\prime \hat{\boldsymbol{\Lambda }}^\star \hat{\boldsymbol{\Lambda }}^{\star ^\prime } \textbf{W}\). We used this vector to initialize an iterative process whose number of repetitions is equivalent to C. Let \(\textbf{R} = \boldsymbol{\Phi } (\boldsymbol{\Theta }^\prime \boldsymbol{\Phi })^{-1}\), with \(\textbf{R} = \{\textbf{r}_1 \; \textbf{r}_2 \; \dots \; \textbf{r}_C\}\). In the first iteration, \(\textbf{r}_1 = \boldsymbol{\phi }_1\). Subsequently, \(\textbf{r}_c = \boldsymbol{\phi }_c - \boldsymbol{\theta }_{c-1}^\prime \boldsymbol{\phi }_c \boldsymbol{\xi }_{c-1}^\prime\). On each iteration, \(\boldsymbol{\theta }_c\) and \(\boldsymbol{\xi }_c\) are estimated as follows:
The solutions of these equations are stored in \(\boldsymbol{\Theta }\) and \(\boldsymbol{\Xi }\), respectively, and are used to update the covariance matrix for the next iteration as follows:
When the iteration process is finished, \(\textbf{B}^*\) provides a proper solution to Eq. (A1) and can be used for prediction purposes. We used \(\textbf{B}^*\) in Eq. (17) to train the PLS model and in Eq. (18) to make predictions.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Araújo, M.S., Chaves, S.F.S., Dias, L.A.S. et al. GIS-FA: an approach to integrating thematic maps, factor-analytic, and envirotyping for cultivar targeting. Theor Appl Genet 137, 80 (2024). https://doi.org/10.1007/s00122-024-04579-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00122-024-04579-z