
Abstract
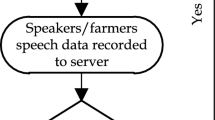
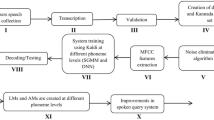
In this paper, a continuous Kannada speech recognition system is developed under different noisy conditions. The continuous Kannada speech sentences are collected from 2400 speakers across different dialect regions of Karnataka state (a state in the southwestern region of India where Kannada is the principal language). The word-level transcription and validation of speech data are done by using Indic transliteration tool (IT3:UTF-8). The Kaldi toolkit is used for the development of automatic speech recognition (ASR) models at different phoneme levels. The lexicon and phoneme set are created afresh for continuous Kannada speech sentences. The 80% and 20% of validated speech data are used for system training and testing using Kaldi. The performance of the system is verified by the parameter called word error rate (WER). The acoustic models were built using the techniques such as monophone, triphone1, triphone2, triphone3, subspace Gaussian mixture models (SGMM), combination of deep neural network (DNN) and hidden Markov model (HMM), combination of DNN and SGMM and combination of SGMM and maximum mutual information. The experiment is conducted to determine the WER using different modeling techniques. The results show that the recognition rate obtained through the combination of DNN and HMM outperforms over conventional-based ASR modeling techniques. An interactive voice response system is developed to build an end-to-end ASR system to recognize continuous Kannada speech sentences. The developed ASR system is tested by 300 speakers of Karnataka state under uncontrolled environment.











Similar content being viewed by others
References
Z. Ansari, S.A. Seyyedsalehi, Toward growing modular deep neural networks for continuous speech recognition. Int. J. Neural Comput. Appl. 28(1), 1177–1196 (2017)
S.S. Bharali, S.K. Kalita, Speech recognition with reference to Assamese language using novel fusion technique. Int. J. Speech Technol. 21(2), 251–263 (2018)
C. Chelba, T. Brants, W. Neveitt, P. Xu, Study on interaction between entropy pruning and kneser-ney smoothing, in Proceedings of the 11th Annual Conference of the International Speech Communication Association (INTERSPEECH) (2010), pp. 2422–2425
S. Chen, J. Goodman, An empirical study of smoothing techniques for language modeling, in Proceedings of the 34th Annual Meeting on Association for Computational Linguistics (1996), pp. 310–318
D. Dimitriadis, E. Bocchieri, Use of micro-modulation features in large vocabulary continuous speech recognition tasks. IEEE/ACM Trans. Audio Speech Lang. Process. 23(8), 102–114 (2015)
S. Ganapathy, Multivariate autoregressive spectrogram modeling for noisy speech recognition. IEEE Signal Process. Lett. 24(9), 1373–1377 (2017)
G. Garau, S. Renals, Template-based continuous speech recognition. IEEE Trans. Audio Speech Lang. Process. 16(3), 508–518 (2008)
G.E. Hinton, S. Osindero, Y.W. Teh, A fast learning algorithm for deep belief nets. Neural Comput. 18(7), 1527–1554 (2006)
S. Katz, Estimation of probabilities from sparse data for the language model component of a speech recognizer. IEEE Trans. Acoust. Speech Signal Process. 35(3), 400–401 (1987)
I.S. Kipyatkova, A.A. Karpov, A study of neural network russian language models for automatic continuous speech recognition systems. Int. J. Autom. Remote Control 78(5), 858–867 (2017)
L. Lu, S. Renals, Small-footprint highway deep neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 25(7), 1502–1511 (2017)
T. Ma, S. Srinivasan, G. Lazarou, J. Picone, Continuous speech recognition using linear dynamic models. Int. J. Speech Technol. 17(1), 11–16 (2014)
K.M.O. Nahar, M.A. Shquier, W.G. Al-Khatib, H. Muhtaseb, M. Elshafei, Arabic phonemes recognition using hybrid LVQ/HMM model for continuous speech recognition. Int. J. Speech Technol. 19(3), 495–508 (2016)
D. Palaz, M. Doss, R. Collobert, Convolutional neural networks-based continuous speech recognition using raw speech signal, in Proceedings of 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia (2015), pp. 4295–4299
B. Popovic, S. Ostrogonac, E. Pakoci, N. Jakovljevic, V. Delic, Deep neural network based continuous speech recognition for serbian using the kaldi toolkit, in Proceedings 17th International Conference on Speech and Computer (SPECOM), Athens, Greece (2015), pp. 186–192
D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlce, Y. Qian, P. Schwarz, J. Silovsky, G. Stemmer, K. Vesely, The Kaldi speech recognition toolkit, in Proceedings IEEE 2011 Workshop on Automatic speech recognition and Understanding, Hilton Waikoloa Village, Big Island, Hawaii, US (2011)
D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlce, Y. Qian, P. Schwarz, J. Silovsky, G. Stemmer, K. Vesely, The subspace gaussian mixture model-a structured model for speech recognition. Int. J. Comput. Speech Lang. 25(2), 404–439 (2011)
L. Rabiner, B.H. Juang, Fundamentals of Speech Recognition (Prentice-Hall, Inc, Upper Saddle River, 1993)
L. Rabiner, Applications of voice processing to telecommunications. Proc. IEEE 82, 199–228 (1994)
S. Ravuri, Hybrid DNN-latent structured SVM acoustic models for continuous speech recognition, in Proceedings of 015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, Arizona, USA (2015), pp. 37–44
R.C. Rose, S.C. Yin, Y. Tang, An investigation of subspace modeling for phonetic and speaker variability in automatic speech recognition, in Proceedings ICASSP (2011), pp. 4508–4511
H.B. Sailor, H.A. Patil, A novel unsupervised auditory filterbank learning using convolutional RBM for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 24(12), 2341–2353 (2016)
H. Sameti, H. Veisi, M. Bahrani, B. Babaali, K. Hosseinzadeh, A large vocabulary continuous speech recognition system for Persian language. EURASIP J. 2011(1), Art. No. 6 (2011). https://doi.org/10.1186/1687-4722-2011-426795
J. Sangeetha, S. Jothilakshmi, An efficient continuous speech recognition system for Dravidian languages using support vector machine, in Proceedings of the Artificial Intelligence and Evolutionary Algorithms in Engineering Systems (ICAEES), New Delhi, India (2015), pp. 359–367
M.V. Segbroeck, H.V. Hamme, Advances in missing feature techniques for robust large-vocabulary continuous speech recognition. IEEE Trans. Speech Audio Process. 19(1), 123–137 (2011)
P. Sharma, V. Abrol, A.K. Sao, Deep-sparse-representation-based features for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 25(11), 2162–2175 (2017)
S.M. Siniscalchi, D. Yu, L. Deng, C.H. Lee, Speech recognition using long-span temporal patterns in a deep network model. IEEE Signal Process. Lett. 20(3), 201–204 (2013)
A. Stolcke, SRILM: An extensible language modeling toolkit, in Proceedings of the 7th International Conference on spoken language processing (ICSLP 2002) (2002), pp. 901–904
R. Su, X. Liu, L. Wang, Automatic complexity control of generalized variable parameter HMMs for noise robust speech recognition. IEEE Trans. Speech Audio Process. 23(1), 102–114 (2015)
F. Triefenbach, K. Demuynck, J.P. Martens, Large vocabulary continuous speech recognition with reservoir-based acoustic models. IEEE Signal Process. Lett. 21(3), 311–315 (2014)
M.D. Wachter, M. Matton, K. Demuynck, P. Wambacq, R. Cools, D.V. Compernolle, Template-based continuous speech recognition. IEEE Trans. Speech Audio Process. 15(4), 1377–1389 (2007)
E. Zarrouk, Y. Benayed, F. Gargouri, Graphical models for the recognition of Arabic continuous speech based triphones modeling, in Proceedings of 2015 IEEE/ACIS 16th International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Takamatsu, Japan (2015), pp. 1–6
Y. Zhao, A speaker-independent continuous speech recognition system using continuous mixture Gaussian density HMM of phoneme-sized units. IEEE Trans. Speech Audio Process. 1(3), 345–361 (1993)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Praveen Kumar, P.S., Thimmaraja Yadava, G. & Jayanna, H.S. Continuous Kannada Speech Recognition System Under Degraded Condition. Circuits Syst Signal Process 39, 391–419 (2020). https://doi.org/10.1007/s00034-019-01189-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-019-01189-9