
Abstract
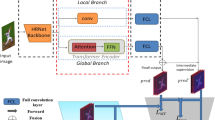
Recently, CNN-Transformer hybrid network has been proposed to resolve either the heavy computational burden of CNN or the difficulty encountered during training the Transformer-based networks. In this work, we design an efficient and effective CNN-Transformer hybrid network for human pose estimation, namely CTHPose. Specifically, Polarized CNN Module is employed to extract the feature with plentiful visual semantic clues, which is beneficial for the convergence of the subsequent Transformer encoders. Pyramid Transformer Module is utilized to build the long-term relationship between human body parts with lightweight structure and less computational complexity. To establish long-term relationship, large field of view is necessary in Transformer, which leads to a large computational workload. Hence, instead of the entire feature map, we introduced a reorganized small sliding window to provide the required large field of view. Finally, Heatmap Generator is designed to reconstruct the 2D heatmaps from the 1D keypoint representation, which balances parameters and FLOPs while obtaining accurate prediction. According to quantitative comparison experiments with CNN estimators, CTHPose significantly reduces the number of network parameters and GFLOPs, while also providing better detection accuracy. Compared with mainstream pure Transformer networks and state-of-the-art CNN-Transformer hybrid networks, this network also has competitive performance, and is more robust to the clothing pattern interference and overlapping limbs from the visual perspective.
This work was supported by the National Natural Science Foundation of China (Grant Nos. 51508105 and 61601127), and the Fujian Provincial Department of Science and Technology of China (Grant Nos. 2019H0006, 2021J01580 and 2022H0008).
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Carion, N., Massa, F., Synnaeve, G., et al.: End-to-end object detection with transformers. In: Vedaldi, A., Bischof, H. (eds.) Computer Vision – ECCV 2020. LNCS, vol. 12346, pp. 213–229. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58452-8_13
Chen, Y., Wang, Z., Peng, Y., et al.: Cascaded pyramid network for multi-person pose estimation. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7103–7112 (2018)
Cheng, B., Xiao, B., Wang, J., et al.: HigherHRNet: scale-aware representation learning for bottom-up human pose estimation. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5385–5394 (2020)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al.: An image is worth 16 \(\times \) 16 words: transformers for image recognition at scale. In: 9th International Conference on Learning Representations (ICLR), pp. 1–21 (2021)
Duan, H., Zhao, Y., Chen, K., et al.: Revisiting skeleton-based action recognition. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2959–2968 (2022)
Fang, H.S., Xie, S., Tai, Y.W., et al.: RMPE: regional multi-person pose estimation. In: 2017 IEEE International Conference on Computer Vision (ICCV), pp. 2353–2362 (2017)
Geng, Z., Sun, K., Xiao, B., et al.: Bottom-up human pose estimation via disentangled keypoint regression. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 14671–14681 (2021)
He, K., Zhang, X., Ren, S., et al.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778 (2016)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. Commun. ACM 60(6), 84–90 (2017)
Li, K., Wang, S., Zhang, X., et al.: Pose recognition with cascade transformers. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1944–1953 (2021)
Li, Y., Xie, S., Chen, X., et al.: Benchmarking detection transfer learning with vision transformers. CoRR (2021). https://arxiv.org/abs/2111.11429
Li, Y., Zhang, S., Wang, Z., et al.: TokenPose: learning keypoint tokens for human pose estimation. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 11293–11302 (2021)
Lin, T.Y., Dollár, P., Girshick, R., et al.: Feature pyramid networks for object detection. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 936–944 (2017)
Lin, T.Y., Maire, M., Belongie, S., et al.: Microsoft COCO: common objects in context. In: Fleet, D., Pajdla, T. (eds.) Computer Vision – ECCV 2014. LNCS, vol. 8693, pp. 740–755. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10602-1_48
Liu, H., Liu, F., Fan, X., et al.: Polarized self-attention: towards high-quality pixel-wise mapping. Neurocomputing 506, 158–167 (2022)
Liu, Z., Lin, Y., Cao, Y., et al.: Swin transformer: hierarchical vision transformer using shifted windows. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9992–10002 (2021)
Madrigal, F., Lerasle, F.: Robust head pose estimation based on key frames for human-machine interaction. EURASIP J. Image Video Process. 2020, 13 (2020)
Newell, A., Yang, K., Deng, J.: Stacked hourglass networks for human pose estimation. In: Ferrari, V., Hebert, M. (eds.) Computer Vision – ECCV 2016. LNCS, vol. 9912, pp. 483–499. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_29
Ramachandran, P., Parmar, N., Vaswani, A., et al.: Stand-alone self-attention in vision models. In: Advances in Neural Information Processing Systems (2019)
Sun, K., Xiao, B., Liu, D., et al.: Deep high-resolution representation learning for human pose estimation. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5686–5696 (2019)
Vaswani, A., Shazeer, N., Parmar, N., et al.: Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 6000–6010. Curran Associates Inc., Red Hook, NY, USA (2017)
Wang, W., Xie, E., Li, X., et al.: Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 548–558 (2021)
Wang, W., Xie, E., Li, X., et al.: PVT v2: improved baselines with pyramid vision transformer. Comput. Vis. Media 8(3), 415–424 (2022)
Wang, Y., Xu, Z., Wang, X., et al.: End-to-end video instance segmentation with transformers. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8737–8746 (2021)
Wang, Z., Cun, X., Bao, J., et al.: Uformer: a general u-shaped transformer for image restoration. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 17662–17672 (2022)
Xiao, B., Wu, H., Wei, Y.: Simple baselines for human pose estimation and tracking. In: Ferrari, V., Hebert, M. (eds.) Computer Vision – ECCV 2018. LNCS, vol. 11210, pp. 472–487. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01231-1_29
Yang, S., Quan, Z., Nie, M., et al.: Transpose: keypoint localization via transformer. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 11782–11792 (2021)
YUAN, Y., Fu, R., Huang, L., et al.: Hrformer: high-resolution vision transformer for dense predict. In: Advances in Neural Information Processing Systems, pp. 7281–7293. Curran Associates, Inc. (2021)
Zhang, F., Zhu, X., Dai, H., et al.: Distribution-aware coordinate representation for human pose estimation. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7091–7100 (2020)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Chen, D., Wu, L., Chen, Z., Lin, X. (2024). CTHPose: An Efficient and Effective CNN-Transformer Hybrid Network for Human Pose Estimation. In: Liu, Q., et al. Pattern Recognition and Computer Vision. PRCV 2023. Lecture Notes in Computer Science, vol 14429. Springer, Singapore. https://doi.org/10.1007/978-981-99-8469-5_26
Download citation
DOI: https://doi.org/10.1007/978-981-99-8469-5_26
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-8468-8
Online ISBN: 978-981-99-8469-5
eBook Packages: Computer ScienceComputer Science (R0)