
Abstract
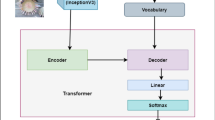
In a globalized world at the present epoch of generative intelligence, most of the manual labour tasks are automated with increased efficiency. This can support businesses to save time and money. A crucial component of generative intelligence is the integration of vision and language. Consequently, image captioning become an intriguing area of research. There have been multiple attempts by the researchers to solve this problem with different deep learning architectures, although the accuracy has increased, but the results are still not up to standard. This study buckles down to the comparison of Transformer and LSTM with attention block model on MS-COCO dataset, which is a standard dataset for image captioning. For both the models we have used pre-trained Inception-V3 CNN encoder for feature extraction of the images. The Bilingual Evaluation Understudy score (BLEU) is used to checked the accuracy of caption generated by both models. Along with the transformer and LSTM with attention block models, CLIP-diffusion model, M2-Transformer model and the X-Linear Attention model have been discussed with state of the art accuracy.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Stefanini M, Cornia M, Baraldi L, Cascianelli S, Fiameni G, Cucchiara R (2021) From show to tell, a survey on image captioning
Takkar S, Jain A, Adlakha P (2021) Comparative study of different image captioning models. In: 2021 5th International conference on computing methodologies and communication (ICCMC), Erode, India, pp 1366–1371. https://doi.org/10.1109/ICCMC51019.2021.9418451
Maroju A, Doma SS, Chandarlapati L (2021) Image caption generating deep learning model. Int J Eng Res Technol. ISSN: 2278-0181
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017)Attention is all you need. arXiv:1706.03762 [cs.CL] 6 Dec 2017
Vedantam R, Lawrence Zitnick C, Parikh D (2014) CIDEr: consensus-based image description evaluation
Anderson P, He X, Buehler C, Teney D, Johnson M, Gould S, Zhang L (2018) Bottom-up and top-down attention for image captioning and visual question answering. arXiv:1707.07998 [cs.CV] 14 Mar 2018
Pawar K, Jagtap V, Bedekar M, Mukhopadhyay D, AFMEACI: a framework for mobile execution augmentation using cloud infrastructure
Vedantam R, Lawrence Zitnick C, Parikh D (2014) CIDEr: consensus-based image description evaluation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311-318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics
Denkowski M, Lavie A (2014) Meteor universal: language specific translation evaluation for any target language. In: Proceedings of the ninth workshop on statistical machine translation, Baltimore, Maryland, USA. Association for Computational Linguistics, pp 376–380. https://www.aclanthology.org/W14-3348/
Pan JY, Yang HJ, Faloutsos C, Duygulu P, GCap: graph-based automatic image captioning
Oliveira G, Neural network methods for natural language processing
Bahdanau D, Cho K, Bengio Y, Neural machine translation by jointly learning to align and translate. arXiv:1409.0473
Le N, Nguyen K, Nguyen A, Le B, Global-local attention for emotion recognition. arXiv:2111.04129
Lu J, Xiong C, Parikh D, Socher R (2016) Knowing when to look, adaptive attention via a visual sentinel for image captioning
Lin T-Y, Maire M, Belongie S, Bourdev L, Girshick R, Hays J, Perona P, Ramanan D, Zitnick CL, Dollár P (2015) arXiv:1405.0312 [cs.CV] 21 Feb 2015
Hodosh M, Young P, Hockenmaier J (2013) Framing image description as a ranking task: data, models and evaluation metrics. JAIR
Young P, Lai A, Hodosh M, Hockenmaier J (2014) From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions. Trans Assoc Comput Linguist 2:67–78
Xu K, Ba J, Kiros R, Cho K, Courville A, Salakhudinov R, Zemel R, Bengio Y (2015) Show, attend and tell: Neural image caption generation with visual attention
Pophale C, Dani A, Gutte A, Choudhary B, Jagtap V, Comparative analysis for an optimized data-driven system
Simonyan K, Zisserman A, Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556v6
He K, Zhang X, Ren S, Sun J (2016) Deep Residual learning for image recognition. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR), Las Vegas, NV, USA, pp 770–778. https://doi.org/10.1109/CVPR.2016.90
Anderson P, Fernando B, Johnson M, Gould S (2016) SPICE: semantic propositional image caption evaluation. In: ECCV
Staudemeyer RC, Morris ER, Understanding LSTM—a tutorial into long short-term memory recurrent neural networks. arXiv:1909.0958v1
Cornia M, Stefanini M, Baraldi L, Cucchiara R, Meshed-memory transformer for image captioning. arXiv:1912.08226
Pan Y, Yao T, Li Y, Mei T, X-linear attention networks for image captioning. arXiv:2003.14080v1
Xu S (2022) Clip-diffusion-LM: apply diffusion model on image captioning. arXiv:2210.04559v1 [cs.CV] 10 Oct 2022
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Dandwate, P., Shahane, C., Jagtap, V., Karande, S.C. (2023). Comparative Study of Transformer and LSTM Network with Attention Mechanism on Image Captioning. In: Choudrie, J., Mahalle, P.N., Perumal, T., Joshi, A. (eds) IOT with Smart Systems. ICTIS 2023. Lecture Notes in Networks and Systems, vol 720. Springer, Singapore. https://doi.org/10.1007/978-981-99-3761-5_47
Download citation
DOI: https://doi.org/10.1007/978-981-99-3761-5_47
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-3760-8
Online ISBN: 978-981-99-3761-5
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)