
Abstract
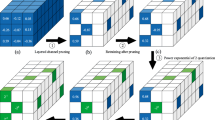
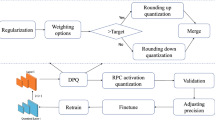
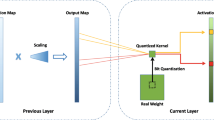
Model compression technology investigates the compression of deep neural networks by quantizing the full-precision weights of the network into low-bit ones, to achieve network acceleration. However, most of the existing quantization operations are calculated by simple thresholding operations, which will lead to serious precision loss. In this paper, we propose a new quantization framework combined with pruning, called Multiple Residual Quantization of Pruning (MRQP), to achieve higher precision quantization neural network (QNN). MRQP recursively performs quantization of the full-precision weights by combining the low-bit weights stem and residual parts many times, to minimize the error between the quantized weights and the full-precision weights, and to ensure higher precision quantization. At the same time, MRQP prunes some weights that have less impact on loss function to further reduce model size.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
References
Pradhyumna, P., Shreya, G.P.: Graph neural network (GNN) in image and video understanding using deep learning for computer vision applications. In: International Conference on Electronics and Sustainable Communication Systems (ICESC), pp. 1183–1189 (2021). https://doi.org/10.1109/ICESC51422.2021.9532631
Zhang, X., Yi, W.J., Saniie, J.: Home surveillance system using computer vision and convolutional neural network. In: International Conference on Electro Information Technology (EIT), pp. 266–270 (2019). https://doi.org/10.1109/EIT.2019.8833773
Bantupalli, K., Xie, Y.: American sign language recognition using deep learning and computer vision. IEEE International Conference on Big Data (Big Data), pp. 4896–4899 (2018). https://doi.org/10.1109/BigData.2018.8622141
Nassif, A.B., Shahin, I., Attili, I., et al.: Speech recognition using deep neural networks: a systematic review[J]. IEEE ACCESS 7, 19143–19165 (2019)
Shewalkar, A.: Performance evaluation of deep neural networks applied to speech recognition: RNN, LSTM and GRU. J. Artif Intell. Soft Comput. Res. 9(4), 235–245 (2019)
Lokesh, S., Malarvizhi Kumar, P., Ramya Devi, M., et al.: An automatic Tamil speech recognition system by using bidirectional recurrent neural network with self-organizing map[J]. Neural Comput. Appl. 31(5), 1521–1531 (2019)
Giménez, M., Palanca, J., Botti, V.: Semantic-based padding in convolutional neural networks for improving the performance in natural language processing. a case of study in sentiment analysis. Neurocomputing 378, 315–323 (2020)
Galassi, A., Lippi, M., Torroni, P.: Attention in natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 32(10), 4291–4308 (2020)
Moon, J., Kim, H., Lee, B.: View-point invariant 3D classification for mobile robots using a convolutional neural network. Int. J. Control Autom. Syst. 16(6), 2888–2895 (2018)
Zeng, R., Zeng, C., Wang, X., Li, B., Chu, X.: Incentive mechanism for federated learning and game-theoretical approach. IEEE Netw. (Early Access), 1–7 (2022)
Zhang, T., Ma, L., Liu, Q., et al.: Genetic programming for ensemble learning in face recognition. In: International Conference on Sensing and Imaging. Springer, Cham, pp. 209–218 (2022) https://doi.org/10.1007/978-3-031-09726-319
Ma, L., Wang, X., Huang, M., Lin, Z., Tian, L., Chen, H.: Two-level master-slave rfid networks planning via hybrid multi-objective artificial bee colony optimizer. IEEE Trans. Syst. Man Cybernet. Syst. 49(5), 861–880 (2019)
Lianbo. M., Cheng, S., Shi, M.: Enhancing learning efficiency of brain storm optimization via orthogonal learning design. IEEE Trans. Syst. Man Cybernet.: Syst. 51(11), 6723–6742 (2021)
Ma, L., Huang, M., Yang, S., Wang, R., Wang, X.: An adaptive localized decision variable analysis approach to large-scale multiobjective and many-objective optimization. IEEE Trans. Cybern. 52(7) (2022)
Molchanov, P., Mallya, A., Tyree, S., et al.: Importance estimation for neural network pruning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11264–11272 (2019). https://doi.org/10.1109/CVPR.2019.01152
Yang, Y., Qiu, J., Song, M., et al.: Distilling knowledge from graph convolutional networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7074–7083 (2020). https://doi.org/10.1109/CVPR42600.2020.00710
Liu, F., Wu, X., Ge, S., et al.: Exploring and distilling posterior and prior knowledge for radiology report generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13753–13762 (2021). https://doi.org/10.1109/CVPR46437.2021.01354
Li, Y., Ding, W., Liu, C., et al.: TRQ: Ternary neural networks with residual quantization. Proc. AAAI Conf. Artif. Intell. 35(10), 8538–8546 (2021). https://doi.org/10.1609/aaai.v35i10.17036
Qu, Z., Zhou, Z., Cheng, Y., et al.: Adaptive loss-aware quantization for multi-bit networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7988–7997 (2020). https://doi.org/10.1109/CVPR42600.2020.00801
Peng, H., Wu, J., Zhang, Z., et al.: Deep network quantization via error compensation. IEEE Trans. Neural Netw. Learn. Syst. 33(9), 4960–4970 (2021)
Chen, P., Zhuang, B., Shen, C.: FATNN: fast and accurate ternary neural networks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5219–5228 (2021). https://doi.org/10.1109/ICCV48922.2021.00517
Courbariaux, M., Bengio, Y., David, J.P.: BinaryConnect: training deep neural networks with binary weights during propagations. Adv. Neural. Inf. Process. Syst. 2, 3123–3131 (2015)
Rastegari, M., Ordonez, V., Redmon, J., Farhadi, A.: XNOR-Net: ImageNet classification using binary convolutional neural networks. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 525–542. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_32
Zhu, C., Han, S., Mao, H., et al.: Trained ternary quantization (2016). https://arxiv.org/abs/1612.01064
Nahshan, Y., Chmiel, B., Baskin, C., et al.: Loss aware post-training quantization. Mach. Learn. 10(11), 3245–3262 (2021)
Yin, P., Lyu, J., Zhang, S,. et al.: Understanding straight-through estimator in training activation quantized neural nets (2019). https://arxiv.org/abs/1903.05662
Yang, J., Shen, X., Xing, J., et al.: Quantization networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7308–7316 (2019). https://doi.org/10.1109/CVPR.2019.00748
Liu, Z., Wang, Y., Han, K., et al.: Post-training quantization for vision transformer. Adv. Neural. Inf. Process. Syst. 34, 28092–28103 (2021)
Nedic, A., Olshevsky, A., Ozdaglar, A., et al.: On distributed averaging algorithms and quantization effects. IEEE Trans. Autom. Control 54(11), 2506–2517 (2009)
Deng, L., Jiao, P., Pei, J., et al.: GXNOR-Net: training deep neural networks with ternary weights and activations without full-precision memory under a unified discretization framework[J]. Neural Netw. 100, 49–58 (2018)
Bulat, A., Tzimiropoulos, G.: XNOR-Net++: improved Binary Neural Networks (2019). https://arxiv.org/abs/1909.13863
Kim, H., Kim, K., Kim, J., et al.: BinaryDuo: reducing gradient mismatch in binary activation network by coupling binary activations. In: International Conference on Learning Representations (2019). https://doi.org/10.48550/arXiv.2002.06517
Kim, D., Lee, J., Ham, B.: Distance-aware quantization. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5271–5280 (2021). https://doi.org/10.1109/ICCV48922.2021.00522
Hou, L., Yao, Q., Kwok, J.T.Y.: Loss-aware binarization of deep networks. In: International Conference on Learning Representations (2017). https://ui.adsabs.harvard.edu/abs/2016arXiv161101600H
Zhang, D., Yang, J., Ye, D., Hua, G.: LQ-Nets: learned quantization for highly accurate and compact deep neural networks. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11212, pp. 373–390. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01237-3_23
Louizos, C., Reisser, M., Blankevoort, T., et al.: Relaxed quantization for discretized neural networks. In: International Conference on Learning Representations (2018). https://doi.org/10.48550/arXiv.1810.01875
Miyashita, D., Lee, E.H., Murmann, B.: Convolutional neural networks using logarithmic data representation (2016). https://arxiv.org/abs/1603.01025v1
Acknowledgments
This work is partially suported by NSFC under grant No. 62172083 and the Fundamental Research Funds for the Central Universities.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Zhou, Y., Kang, H., Zhang, T., Ma, L., Xing, T. (2022). Multiple Residual Quantization of Pruning. In: Tan, Y., Shi, Y. (eds) Data Mining and Big Data. DMBD 2022. Communications in Computer and Information Science, vol 1744. Springer, Singapore. https://doi.org/10.1007/978-981-19-9297-1_16
Download citation
DOI: https://doi.org/10.1007/978-981-19-9297-1_16
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-9296-4
Online ISBN: 978-981-19-9297-1
eBook Packages: Computer ScienceComputer Science (R0)