
Abstract
As a multi-modal task, remote sensing image captioning (RSIC) plays an essential role in image understanding. However, most current RSIC methods ignore sufficient utilization of image features. we propose an improved image description method with improved attention mechanism, named attention-guided visual semantic fusion (AVSF) method for RSIC, based on the encoder-decoder framework. Attention mechanism contributes to obtaining the relationship between global and local image, as well as the relationship between image region and corresponding text, which is more conducive to the generation of description. Firstly, convolutional neural network VGG16 is introduced as the main network to construct the encoder and extract the features for remote sensing images. Secondly, image features are fused with text features, and attention mechanism is introduced to enhance the attention to vision features. Then, long short-term memory is used to build a decoder for learning the mapping relationships between image visual features and text semantic features. The experiments show that evaluation metrics have been improved on the UCM and Sydney datasets.
This work was supported by the National Natural Science Foundation of China (61702528, 61806212), Hunan Postgraduate Innovation Project (CX20210011).
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

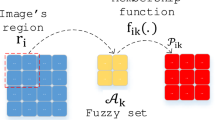

References
Shi, Z., Zou, Z.: Can a machine generate humanlike language descriptions for a remote sensing image? IEEE Trans. Geosci. Remote Sens. 55(6), 3623–3634 (2017)
Zhang, J., Su, Q., Tang, B., et al.; DPSNet: multitask learning using geometry reasoning for scene depth and semantics. IEEE Trans. Neural Netw. Learn. Syst. 1057–1071 (2021)
Vinyals, O., Toshev, A., Bengio, S., et al.: Show and tell: a neural image caption generator. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3156–3164 (2015)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Xu, K., Ba, J., Kiros, R., et al.: Show, attend and tell: neural image caption generation with visual attention. Comput. Sci. 2048–2057 (2015)
Ranzato, M., Chopra, S., Auli, M., et al.: Sequence level training with recurrent neural networks. Comput. Sci. 1378–1392 (2015)
Chen, S., Jin, Q., Wang, P., et al.: Say as you wish: fine-grained control of image caption generation with abstract scene graphs. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9962–9971 (2020)
Liu, W., Chen, S., Guo L., et al.: CPTR: full transformer network for image captioning (2021)
Dai, B., Fidler, S., Urtasun, R., et al.: Towards diverse and natural image descriptions via a conditional gan. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2970–2979 (2017)
Hou, J., Wu, X., Zhang, X., et al.: Joint commonsense and relation reasoning for image and video captioning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, pp. 10973–10980 (2020)
Qu, B., Li, X., Tao, D., et al.: Deep semantic understanding of high resolution remote sensing image. In: 2016 International Conference on Computer, Information and Telecommunication Systems (Cits), pp. 1–5. IEEE (2016)
Lu, X., Wang, B., Zheng, X., et al.: Exploring models and data for remote sensing image caption generation. IEEE Trans. Geosci. Remote Sens. 56(4), 2183–2195 (2017)
Shen, X., Liu, B., Zhou, Y., et al.: Remote sensing image caption generation via transformer and reinforcement learning. Multimedia Tools Appl. 79(35), 26661–26682 (2020)
Shen, X., Liu, B., Zhou, Y., et al.: Remote sensing image captioning via variational autoencoder and reinforcement learning. Knowl.-Based Syst. 203, 105920 (2020)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image ecognition. Comput. Sci. 3841–3855 (2014)
Graves, A.: Sequence transduction with recurrent neural networks. Comput. Sci. 58(3), 235–242 (2012)
Papineni, K., Roukos, S., Ward, T., et al.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual meeting of the Association for Computational Linguistics, pp. 311–318 (2002)
Lin, C.Y.: Rouge: a package for automatic evaluation of summaries. In: Text Summarization Branches Out, pp. 74–81 (2004)
Vedantam, R., Lawrence Zitnick, C., Cider, P.D.: Consensus-based image description evaluation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4566–4575 (2015)
Lu, X., Wang, B., Zheng, X.: Sound active attention framework for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 58(3), 1985–2000 (2019)
Sumbul, G., Nayak, S., Demir, B.: SD-RSIC: summarization-driven deep remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 59(8), 6922–6934 (2020)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 Chinese Institute of Command and Control
About this paper

Cite this paper
Wei, T., Luo, J., Yuan, W., Zhang, W. (2022). An Attention-Guided Visual Semantic Fusion Method for Remote Sensing Image Captioning. In: Proceedings of 2022 10th China Conference on Command and Control. C2 2022. Lecture Notes in Electrical Engineering, vol 949. Springer, Singapore. https://doi.org/10.1007/978-981-19-6052-9_78
Download citation
DOI: https://doi.org/10.1007/978-981-19-6052-9_78
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-6051-2
Online ISBN: 978-981-19-6052-9
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)