
Abstract
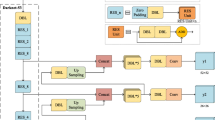
Improving the accuracy of target recognition is always the focus of machine learning research. YOLOv3 multi-scale detection accelerates the speed while ensuring accuracy, and the self-attention mechanism takes into account the attention weight of each pixel feature to enhance the ability of information extraction. In view of the large size difference between different targets in the target detection task, which makes it difficult to effectively detect multi-size targets, and the publication of the latest self-attention mechanism COT.NET, a combination of the YOLOv3 network Darknet-53 and the self-attention network COT.NET is proposed. The idea of YOLOv3 is improved by adding a self-attention mechanism to the residual structure of YOLOv3.Through verification on the VOC image set, the improved YOLOv3 is 1.34% higher than the original YOLOv3 map. Experimental results show that YOLOv3 integrated into the self-attention mechanism can improve the accuracy of image recognition.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Jin, L.S., Guo, B.C., Wang, F.R., Shi, J.: Dynamic multi-target detection algorithm in front of vehicles based on improved YOLOv3. J. Jilin Univ. (Eng. Technol. Edn.) 51(04), 1427–1436 (2021)
Luo, S.J.: Research and application of YOLOv3 algorithm in the field of intelligent transportation. Lanzhou University, Lanzhou (2020)
Xu, L.F., Fu, Z.J., Mo, H.W.: Recognition of breast ultrasound tumor based on improved YOLOv3 algorithm. J. Intell. Syst. 16(01), 21–29 (2021)
Diao, R., Hu, Y.L., Jiang, Y.Z., Lu, W.: Human body detection technology based on YOLOv3 improved algorithm. Inf. Technol. Inf. Technol. (08), 249–252 (2021)
Liu, W., et al.: SSD: single shot multibox detector. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9905, pp. 21–37. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_2
Lin, T., Dollar, P., Girshick, R., et al.: Feature pyramid networks for object detection. In: Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition, pp. 936–944. IEEE Press, Washington D.C., USA (2017)
Joseph, R., Ali, F.: YOLOv3: an incremental improvement. Comput. Vis. Pattern Recogn. 2021(01), 48–50 (2021)
Ge, Z., Liu, S.T., Wang, F., Li, Z.M., Sun, J.: YOLOX: exceeding YOLO series in 2021. ArXiv abs/2107.08430 (2021)
Fang, Y.X., et al.: You only look at one sequence: rethinking transformer in vision through object detection. ArXiv abs/2106.00666 (2021)
Tong, N., Lu, H.C., Zhang, L.H., Ruan, X.: Saliency detection with multi-scale superpixels. IEEE Signal Process. Lett. 21(9), 1035–1039 (2014)
Redmon, J., Farhadi, A.: YOLOv3: an incremental improvement. ArXiv abs/1804.02767 (2018)
Chefer, H.L., Shir, G., Lior, W.: Transformer interpretability beyond attention visualization. In: Proceeding of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, pp. 782–791 (2021)
Li, Y.H., Yao, T., Pan, Y.W., Mei, T.: Contextual transformer networks for visual recognition. ArXiv abs/2107.12292 (2021)
He, K., Zhang, X., Ren, S., et al.: Deep residual learning for image recognition. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778. IEEE Press, Washington D.C., USA (2016)
Pascal VOC Dataset Mirror. pjreddie.com
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Zhang, J., Jia, Y., Yu, H. (2022). Application Research of YOLOv3 Incorporating Self-attention Mechanism. In: S. Shmaliy, Y., Abdelnaby Zekry, A. (eds) 6th International Technical Conference on Advances in Computing, Control and Industrial Engineering (CCIE 2021). CCIE 2021. Lecture Notes in Electrical Engineering, vol 920. Springer, Singapore. https://doi.org/10.1007/978-981-19-3927-3_45
Download citation
DOI: https://doi.org/10.1007/978-981-19-3927-3_45
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-3926-6
Online ISBN: 978-981-19-3927-3
eBook Packages: EngineeringEngineering (R0)