
Abstract
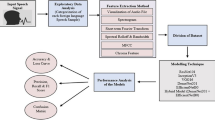
Automatic speech recognition has allowed human beings to use their voices to speak with a computer interface. Nepali speech recognition involves conversion of Nepali language to corresponding text in Devanagari lipi. This work proposes a novel approach for developing Nepali Speech recognition model based using CNN-GRU. The data is collected from the Librispeech. The collected data is pre-processed and MFCC is applied on it for feature extraction. CNN-GRU model is responsible for extraction of the features and development of the acoustic model. CTC is responsible for decoding. The performance of the developed model has been assessed using Word Error Rate of the transcribed text.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Karita, S., et al.: A comparative study on transformer vs rnn in speech applications. In: 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 449–456. IEEE (2019)
Passricha, V., Aggarwal, R.K.: Convolutional neural networks for raw speech recognition. In: From Natural to Artificial Intelligence-Algorithms and Applications. IntechOpen (2018)
Ssarma, M.K., Gajurel, A., Pokhrel, A., Joshi, B.: Hmm based isolated word nepali speech recognition. In: 2017 International Conference on Machine Learning and Cybernetics (ICMLC), vol. 1, pp. 71–76. IEEE (2017)
Regmi, P., Dahal, A., Joshi, B.: Nepali speech recognition using rnn-ctc model. Int. J. Comput. Appl. 178(31), 1–6 (2019)
Bhatta, B., Joshi, B., Maharjhan, R.K.: Nepali speech recognition using CNN, GRU and CTC. In: Proceedings of the 32nd Conference on Computational Linguistics and Speech Processing (ROCLING 2020), pp. 238–246 (2020)
Gupta, R., Sivakumar, G.: Speech recognition for Hindi language. IIT BOMBAY (2006)
Kopparapu, S.K., Laxminarayana, M.: Choice of mel filter bank in computing MFCC of a resampled speech. In: 10th International Conference on Information Science, Signal Processing and their Applications (ISSPA 2010), pp. 121–124. IEEE (2010)
Kong, X., Choi, J.Y., Shattuck-Hufnagel, S.: Evaluating automatic speech recognition systems in comparison with human perception results using distinctive feature measures. In: 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5810–5814. IEEE (2017)
Sodimana, K., et al.: A step-by-step process for building TTS voices using open source data and framework for Bangla, Javanese, Khmer, Nepali, Sinhala, and Sundanese. In: Proceedings of the 6th International Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU), pp. 66–70, Gurugram, India, August 2018
Acknowledgement
This work has been supported by the University Grants Commission, Nepal under a Faculty Research Grant (UGC Award No. FRG-76/77-Engg-1) for the research project “Preparation of Nepali Speech Corpus: Step towards Efficient Nepali Speech Processing”.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Joshi, B., Bhatta, B., Panday, S.P., Maharjan, R.K. (2022). A Novel Deep Learning Based Nepali Speech Recognition. In: Mekhilef, S., Shaw, R.N., Siano, P. (eds) Innovations in Electrical and Electronic Engineering. ICEEE 2022. Lecture Notes in Electrical Engineering, vol 894. Springer, Singapore. https://doi.org/10.1007/978-981-19-1677-9_39
Download citation
DOI: https://doi.org/10.1007/978-981-19-1677-9_39
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-1676-2
Online ISBN: 978-981-19-1677-9
eBook Packages: EnergyEnergy (R0)