
Abstract
Traditionally, data mining algorithms deal with a static set of input. The major bottlenecks with this class of algorithms may include redundant computation, higher latency along with increased consumption of available resources. Given the essence of dealing with dynamic data, this work focused on designing incremental mining algorithms specifically in the field of density-based clustering and outlier detection. The primary reason being density-based algorithms shows robustness in finding clusters of varying granularity or extracting outliers from variable density regions. Through these works, we proposed incremental extensions to two density-based clustering algorithms: MBSCAN, SNN-DBSCAN and an outlier detection algorithm KNNOD. The incremental extensions to MBSCAN (iMass) and KNNOD (KAGO) are approximate in nature supporting single point insertions. While for SNN-DBSCAN, we proposed exact incremental algorithms (\(\text {BISDB}_\mathrm{add}\) and \(\text {BISDB}_\mathrm{del}\)) supporting both insertion and removal of data in batch mode. iMass obtained a maximum efficiency upto an order of 2.28 (\(\approx \)191 times) maintaining a mean clustering accuracy of around 60.375%. \(\text {BISDB}_\mathrm{add}\) and \(\text {BISDB}_\mathrm{del}\) achieved high efficiency upto an order of 3, 4, respectively. The clusters obtained through both these algorithms were identical to SNN-DBSCAN. KAGO outperformed KNNOD by achieving a maximum efficiency upto an order of 3.9 (\(\approx \)8304 times) across two intrusion detection datasets and a bidding data pertaining to a search engine. On evaluating outliers using these datasets, the Rand-Index and F1-score pertaining to KAGO showed an average improved accuracy of around 3.3%.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
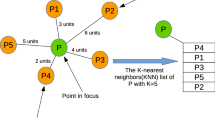
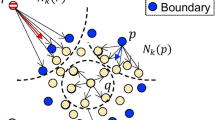

Notes
- 1.
Dataset upon which updates are made.
References
Chang H, Lin J, Cheng M, Huang S (2016) A novel incremental data mining algorithm based on fp-growth for big data. In: 2016 International Conference on Networking and Network Applications (NaNA), pp 375–378
Pham DT, Dimov SS, Nguyen CD (2004) An incremental k-means algorithm. In: Proc Inst Mech Eng Part C: J Mech Eng Sci 218(7):783–795
Moses C, Chandra C, Tomás F, Rajeev M (2004) Incremental clustering and dynamic information retrieval. SIAM J Comput 33(6):1417–1440
Su M-Y, Yu G-J, Chun-Yuen L (2009) A real-time network intrusion detection system for large-scale attacks based on an incremental mining approach. Comput Secur 28(5):301–309
Jain AK, Murty MN, Flynn PJ (1999) Data clustering: a review. ACM Comput Surv (CSUR) 31(3):264–323
Xu R, Wunsch DC (2005) Survey of clustering algorithms
Martin E, Hans-Peter K, Jörg S, Xu X et al (1996) A density-based algorithm for discovering clusters in large spatial databases with noise. In Kdd 96:226–231
Sammut C, Webb GI (2017) Encyclopedia of machine learning and data mining. Springer Publishing Company, Incorporated
Ng RT, Han J (2002) Clarans: a method for clustering objects for spatial data mining. IEEE Trans Knowl Data Eng 5:1003–1016
Hartigan JA, Wong MA (1979) Algorithm as 136: a k-means clustering algorithm. J Roy Stat Soc. Series C (Appl Stat) 28(1):100–108
Silverman BW (2018) Density estimation for statistics and data analysis. Routledge
Gan G, Ma C, Wu J (2007) Data clustering: theory, algorithms, and applications, vol 20. Siam
Ertöz L, Steinbach M, Kumar V (2003) Finding clusters of different sizes, shapes, and densities in noisy, high dimensional data. In: Proceedings of the 2003 SIAM international conference on data mining, pp 47–58. SIAM, 2003
Varun C, Arindam B, Vipin K (2009) Anomaly detection: a survey. ACM Comput Surveys (CSUR) 41(3):15
Liao Y, Vemuri VR (2002) Use of k-nearest neighbor classifier for intrusion detection. Comput Secur 21(5):439–448
Breunig MM, Kriegel H-P, Ng RT, Sander J (2000) Lof: identifying density-based local outliers. In: ACM Sigmod Rec 29:93–104. ACM (2000)
Basilico J, Hofmann T (2004) Unifying collaborative and content-based filtering. In: Proceedings of the twenty-first international conference on Machine learning. ACM, p 9
Cha M, Kwak H, Rodriguez P, Ahn Y-Y, Moon S (2007) I tube, you tube, everybody tubes: analyzing the world’s largest user generated content video system. In: Proceedings of the 7th ACM SIGCOMM conference on internet measurement, IMC ’07, New York, NY, USA, ACM, pp 1–14
Shah H, Mustafizur R, Syed A (2015) Sensor anomaly detection in wireless sensor networks for healthcare. Sensors 15(4):8764–8786
Tuarob S, Tucker CS, Salathe M, Ram N (2015) Modeling individual-level infection dynamics using social network information. In: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, CIKM ’15, New York, NY, USA, ACM, pp 1501–1510
Robert M, Ray C (2013) Behavior-rule based intrusion detection systems for safety critical smart grid applications. IEEE Trans Smart Grid 4(3):1254–1263
Li Y, Fang B, Guo L, Chen Y (2007) Network anomaly detection based on tcm-knn algorithm. In: Proceedings of the 2nd ACM symposium on information, computer and communications security. ACM, pp 13–19
Abhinav S, Amlan K, Shamik S, Arun M (2008) Credit card fraud detection using hidden markov model. IEEE Trans Dependable and Secure Comput 5(1):37–48
Ting KM, Zhu Y, Carman M, Zhu Y, Zhou Z-H (2016) Overcoming key weaknesses of distance-based neighbourhood methods using a data dependent dissimilarity measure. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. ACM, pp 1205–1214
Dang TT, Ngan HYT, Liu W (2015) Distance-based k-nearest neighbors outlier detection method in large-scale traffic data. In: 2015 IEEE international conference on Digital Signal Processing (DSP). IEEE, pp 507–510
Panthadeep B, Pinaki M (2021) Imass: an approximate adaptive clustering algorithm for dynamic data using probability based dissimilarity. Front Comput Sci 15(2):1–3
Asuncion A, Newman D (2007) Uci machine learning repository
Fränti P, Sieranoja S (2018) K-means properties on six clustering benchmark datasets
Panthadeep B, Pinaki M (2020) Bisdbx: towards batch-incremental clustering for dynamic datasets using snn-dbscan. Pattern Anal Appl 23(2):975–1009
Singh S, Awekar A (2013) Incremental shared nearest neighbor density-based clustering. In: Proceedings of the 22nd ACM international conference on Information & Knowledge Management. ACM, pp 1533–1536
Bhattacharjee P, Garg A, Mitra P (2021) Kago: an approximate adaptive grid-based outlier detection approach using kernel density estimate. Pattern Anal Appl 1–22
Svante W, Kim E, Paul G (1987) Principal component analysis. Chemomet Intell Lab Syst 2(1–3):37–52
Qin X, Cao L, Rundensteiner EA, Madden S (2019) Scalable kernel density estimation-based local outlier detection over large data streams. In: EDBT, pp 421–432
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this chapter

Cite this chapter
Bhattacharjee, P., Mitra, P. (2022). Density-Based Mining Algorithms for Dynamic Data: An Incremental Approach. In: Dash, S.R., Lenka, M.R., Li, KC., Villatoro-Tello, E. (eds) Intelligent Technologies: Concepts, Applications, and Future Directions. Studies in Computational Intelligence, vol 1028. Springer, Singapore. https://doi.org/10.1007/978-981-19-1021-0_13
Download citation
DOI: https://doi.org/10.1007/978-981-19-1021-0_13
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-1020-3
Online ISBN: 978-981-19-1021-0
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)