
Abstract
Accidental knowledge discoveries occur most frequently during capricious and unplanned search and browsing of data. This type of undirected, random, and exploratory search and browsing of data results in Serendipity – the art of unsought finding. In our previous work we extracted a set of serendipity-fostering design features for developing intelligent user interfaces on Semantic Web and Linked Data browsing environments. The features facilitate the discovery of interesting and valuable facts in (linked) data which were not initially sought for. In this work, we present an implementation of those features called FERASAT. FERASAT provides an adaptive multigraph-based faceted browsing interface to catalyze serendipity while browsing Linked Data. FERASAT is already in use within the domain of science, technology & innovation (STI) studies to allow researchers who are not familiar with Linked Data technologies to explore heterogeneous interlinked datasets in order to observe and interpret surprising facts from the data relevant to policy and innovation studies. In addition to an analysis of the related work, we describe two STI use cases in the paper and demonstrate how different serendipity design features are addressed in those use cases.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
“Unless you expect the unexpected you will never find [truth], for it is hard to discover and hard to attain.” -HeraclitusFootnote 1
Serendipity (known as the art of unsought finding [19]) plays an important role in the emerging field of data science, allowing the discovery of interesting and valuable facts not initially sought for. Serendipity consists of two main steps: a surprising observation and then a correct interpretation. In our previous work [13], we extracted a set of serendipity-fostering design features (cf. Table 1) which help designers and developers of Semantic Web and Linked Data browsing environments to facilitate discovery and interpretation of new, useful, and interesting facts. For example, design Feature F\(_{10}\) (in Table 1) suggests sharing of surprising observations among multiple users to increase the chance encounter. A surprising observation done by user A, when correctly explained by user B, can result in positive serendipity.
In this work, we present an implementation of those serendipity-fostering features called “FERASAT”Footnote 2 (FacEted bRowser And Serendipity cATalyzer). FERASAT provides an adaptive multigraph-based faceted browsing interface to catalyze serendipity while browsing Linked Data. It is important to mention that serendipitous discovery may be facilitated but it is by definition an emergent process. With our work we aim to facilitate the process of serendipity by providing an incubator-like environment for serendipity. In other words, the FERASAT environment will increase the likelihood of serendipity, without guaranteeing it.
FERASAT is built on top of the LD-R framework [11] to support the following serendipity-fostering principles:
-
Skeuomorphic Design. “One way of overcoming the fear of new is to make it look like the old”, said Don Norman to describe the process of skeuomorphic design [15]. Skeuomorphism in the context of UI design, refers to the practice of incorporating recognizable objects which are familiar to users to decrease the cognitive load of users and to hide complexity of the underlying technology. Most of the current Linked Data browsing interfaces fall into the Pathetic Fallacy of RDF [9] trap where they display RDF data to the users as a graph because the underlying data model is a graph. Abstracting the complexity of RDF and graph-based data representation provides more easily-discoverable and usable interactions (i.e. more affordances) for non-Semantic Web users to serendipitously browse data scattered over multiple knowledge graphs.
-
Adaptive Design. In order to support serendipity-fostering features, the browser UI needs to act in a proactive way to persistently customize and personalize user interfaces based on the type of data and the information needs of the end-users. Intelligent UI adaptation allows the application to act more like a human and consequently, more intelligently.
-
Component-based Design. Component-based design is a prerequisite to realize intelligent UI adaptation. A component-based environment consists of a set of structured UI components as building blocks, that can dynamically get injected to system, replaced and customized while user is interacting with the system.
The contributions of this work are in particular:
-
Design and implementation of an open-source faceted browser to facilitate serendipity while browsing Linked Data.
-
An analysis of the related work in terms of the serendipity design features.
-
Discussing two use cases in the domain of science, technology and innovation (STI) studies to demonstrate the capabilities of our implemented solution.
The rest of this paper is organized as following: In Sect. 2 we elaborate on the design and architecture of the FERASAT environment and indicate how it addresses the proposed serendipity-fostering features. Implementation details are described in Sect. 3. Section 4 presents two use cases on serendipitous knowledge discovery when FERASAT was used in the STI domain. In Sect. 5, we review the related work in the area of serendipity on Linked Data and compare FERASAT to existing Linked Data-based faceted browsers. Finally in Sect. 6 we conclude and briefly mention the future directions of this work.

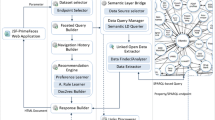
Architecture of the FERASAT adaptive faceted browser. (Color figure online)
2 FERASAT: A Trigger and Facilitator for Serendipity on Linked Data
Figure 1 depicts the architecture of FERASAT where related elements are color coded. The system provides three main modes of interaction with data namely search, browse and view. During the user interactions, based on the semantics of data and the given user context, the system adapts its behavior by rendering appropriate interactive UI components. In the following sections we describe the main architectural building blocks of the FERASAT environment together with how they support the serendipity-fostering features shown in Table 1.
2.1 Interaction Layer
According to the theory of “Seven Stages of Action” [15], which explains the psychology of a person while executing a task, user interactions with a system occur in two gulfs namely a gulf of execution and a gulf of evaluation. The gulf of execution focuses on allowable interactions (i.e., affordances – clues about how an object should be used, typically provided by the object itself or its context) in the system, whereas the gulf of evaluation reflects the amount of effort that the person must exert to interpret the state of the system after an interaction. Within the FERASAT environment, interactions in the gulf of execution (e.g. interacting to invert a selected facet) are used as triggers for serendipity and interactions in the gulf of evaluation (e.g. visualization & in-detail browsing of the properties of a resource) are used to support the process of abduction – the process of guessing, interpreting, creating and testing hypotheses in order to find a correct explanation, one that is evidence-based.
Figure 2 shows a mock-up of the design we devised for the FERASAT faceted browser (Fig. 5 depicts the actual implementation). When browsing a set of linked data which is scattered over multiple knowledge graphs (e.g. Figure 3), the first step is to identify properties of interest as semantic links to move forward and backward in the data space. The index facet lists these designated RDF properties grouped by the aspect they are addressing. In the initial state, all the RDF resources are displayed without any constraints. When a user selects a property, a new facet is generated to display the object values of the selected property together with the number of resources containing those values. The facet can be configured to employ different interactive UI components (e.g. charts, maps, etc. in Fig. 2) to render the values of a selected property.
Flexible UI components support the serendipity-fostering features F\(_{1}\), F\(_{2}\) and F\(_{4}\) (see Table 1) by allowing users to exploit multiple interactive visualizations to do surprising observations and also discover successful errors in data together with the possible explanations for their occurrence. The list of values in a facet can be shuffled to change the ordering based on a random factor or some criteria other than the default sorting criterion which is the frequency of the corresponding resources (supporting F\(_{7}\)). When a user selects one or more values of an active facet, a SPARQL query with the corresponding constraints is generated and executed to update the results list. Users can invert the selected values in a facet to see the results which exclude those selected values (supporting F\(_{6}\)). If multiple facets are active, any change to a facet will affect the remaining active facets to take into account the constraint imposed by that change (supporting F\(_{9}\)). Users can focus on each facet, search within its values and view in-detail characteristics of each object value (supporting both convergent and divergent information behavior presented by F\(_{12}\)). When a user is browsing a facet which was browsed before, the UI provides some reminders as pop-ups about the previous usage of that facet (supporting F\(_{8}\)).

A mock-up of the FERASAT adaptive faceted browser.

An example of the linked data scattered over multiple graphs (datasets).
The result list is the terminal facet in the system which shows the final result of the generated SPARQL query as a set of RDF resources constrained by the selected RDF properties and values. Clicking on a resource reveals the detailed characteristics of that resource (supporting F\(_{2}\) to study a particular surprising observation). To further investigate the results, a user can select multiple resources and ask for the potential correlations between them (supporting F\(_{9}\) to investigate by-products). For example, given the linked data in Fig. 3, a user might want to browse and find the relation between entities of type universities which are founded in certain years AND are located in certain administrative boundaries AND have published on certain research topics. Using the faceted browser, such a query is generated in a progressive way where users can investigate the effect of each selected facet on other facets and on the results list, while traversing multiple distributed knowledge graphs (in this case, graphs that provide data about universities connected to graphs that provide values related to publications and administrative boundaries), until the full query is answered.
2.2 Data Layer
There are five different sorts of data taken into account within the FERASAT environment: (1) user’s profile data to understand the user preferences, (2) user’s background knowledge to consider a user’s domain of interest while browsing data, (3) original data to be browsed, (4) configuration data as output of adaptation process to customize and personalize both data and UIs, (5) complementary data added as enrichment to original data for richer contextualization. All the above datasets are represented as single or multiple RDF graphs (e.g., Fig. 3) to be ready for integration (using federated SPARQL queries) and analysis.
FERASAT supports resource annotation to interlink the original data with the user’s background knowledge and to generate complementary data connected to the original data to be browsed (supporting F\(_{11}\) for user contextualization by giving users additional contextual facets to complement their browsing experience). At the moment, two types of annotation are supported within the system: Named Entity Recognition (NER) using DBpedia SpotlightFootnote 3 and Geo-boundary-tagging supported by open geo boundaries from OpenStreetMap and GADMFootnote 4. There are interactive UIs embedded in the FERASAT system to interactively annotate a dataset before the browsing activity starts. Above semi-automatic annotation supports F\(_{6}\) and F\(_{8}\), as information diverges (by adding annotations) with possible by-products resulting from the annotations.
2.3 UI Layer
As depicted in Fig. 4, there are four core component levels in an FERASAT Web application. Each core component abstracts the actions required for retrieving and updating the graph-based data and provides a basis for user-defined components to interact with Linked Data in three modes: search, browse and view. The data-flow in the system starts from the Dataset component which handles all the events related to a set of resources under a named graph identified by a URI. The next level is the Resource component which is identified by a URI and indicates the RDF resource to be described in the application. A resource includes a set of properties which are handled by the Property component. Properties can be either individual or aggregate when combining multiple features of a resource (e.g. a component that combines longitude and latitude properties; start date and end date properties for a date range, etc.). Each property is instantiated by an individual value or multiple values in case of an aggregate object. The value(s) of properties are controlled by the Value component. In turn, Value components invoke different components to search, browse and view the property values. Value components are terminals in the FERASAT single directional data flow where customized user-generated components (e.g. charts, maps, diagrams, etc.) can be plugged into the system.

(Left) core reactor components, (right) example configuration hypergraph.
2.4 Adaptation Engine
An adaptive UIFootnote 5 is a UI which adapts, that is, changes its layout and elements to the needs of the user or context and is similarly alterable by each user. In the context of FERASAT, we devised a particular type of adaptive UI called a data-aware UI [10] that (a) can understand users’ data and (b) can interact with users accordingly. As depicted in Fig. 1, FERASAT incorporates an adaptation engine to realize data-aware UIs when users interact with data. The task of adaptation engine is to make a bridge between data (enriched by semantics) and existing UI components suitable to render data. The adaptation engine includes the following core components:
-
Querying. This part is responsible for composing, sharing and running of SPARQL queries within the FERASAT environment. FERASAT exploits the WYSIWYQ (What You See Is What You Query) model [12] to allow sharing, modification and repurposing of SPARQL queries among multiple users in a visual and interactive way (supporting F\(_{3}\)). The WYSIWYQ mode translates SPARQL queries to a set of user interface components in certain states and renders this set as a faceted browsing environment. It also provides a set of SPARQL query templates similar to the one discussed in [3] to find analogous resources within the same domain (partially supporting F\(_{5}\)).
-
Reasoning. This is the core part of the engine where different datasets mentioned in Sect. 2.2 are analyzed in an integrative way to find the best strategy for data rendering and UI augmentation.
-
Selection. This part allows to manually or automatically (as result of the reasoning) select or replace an existing UI component. FERASAT employs a specific notation to identify a chain of facet properties using RDF property path and federated SPARQL queries. For example, ex:address->geo:geo selects a property path, ex:orcidID->[http://orcid.org]rdfs:label allows using a property path which ends up in a named graph, and ex:orcidID->[http://myendpoint.com>>http://orcid.org]rdfs:label refers to a property path which is on a named graph located in a different SPARQL endpoint.Footnote 6
-
Customization. This part allows to manually or automatically customize an existing UI component.
-
Personalization. This part allows to manually or automatically personalize an existing UI component. Personalization will overwrite the configurations used for customization to consider the user’s context.
Figure 4 shows that the configuration process is done by traversing the hypergraph generated either manually by a user or automatically as result of the reasoning. FERASAT exploits a hierarchical permutation of the Dataset, Resource, Property, and Value components as scopes to select specific parts of the UI to be customized or personalized. Each scope conveys a certain level of specificity on a given context ranging from 1 (most specific: DRPV) to 15 (least specific: D). Scopes are defined by using either the URIs of named graphs, resources, and properties, or by identifying the resource types and data types. A configuration is defined as a setting which affects the way the UI components are interpreted and rendered (e.g. render a specific component for a specific RDF property or a specific RDF resource within a specific RDF graph). UI adaptation is handled by traversing the configurations for scopes, populating the configurations and overwriting the configurations when a more specific applicable scope is found.

An screenshot of the implemented FERASAT adaptive faceted browser.
3 Implementation
FERASAT is implemented as a ReactJS component (backed by NodeJS) within the open-source Linked Data ReactorFootnote 7 (LD-R) framework and is available to download at http://ferasat.ld-r.org together with its documentation and demos (see Fig. 5 for an screenshot of the FERASAT environment). FERASAT supports two strategies for creating UI configurations:
-
Dynamic Configurations: This option (that is necessary for reasoning and automatic UI adaptation) uses a SPARQL endpoint to store user configurations dynamically as RDF. This is a flexible approach that allows updating user configurations on-the-fly without the need to restart or rebuild the entire application. It also facilitates sharing and querying of the user configurations.
-
Static Configuration: For this option, users do not require to provide a read/write SPARQL endpoint to store their configurations and can enter and store all their configurations locally on the application server as JSON. This options is faster than the static method (since it removes the overhead of using a triple store) and more secure, however the cost of this option is that users need to restart their application server anytime they modify the configurations. Users can combine this method with the dynamic method where the static configurations always have a higher priority in UI configuration.
4 Use Cases
FERASAT is integrated into the SMSFootnote 8 (Semantically Mapping Science) platform as the technical core within the RISIS.eu project. It is actively used to browse data related to Science, Technology & Innovation (STI) studies. The SMS platform has already 388 registered users varying from senior and experienced to junior researchers (professors, postdocs, PhD students), but also policy makers, librarians, project managers, scientific officers, etc. In this section, we provide a brief summary of two use cases related to serendipitous knowledge discovery in the STI domain written by two social scientists who experienced browsing data on FERASAT environment while conducting research. A complete list of use cases is available at http://sms.risis.eu/usecases.
4.1 Analyzing Change in the Research/Higher Education (HE) Systems
The RISIS datastore contains many datasets with information about organizations. I was mainly interested in structural change in HE systems by navigating through those datasets. The faceted browser was of great help, as it enabled me to explore the available information in a graphical form. While browsing the datasets, I found a property “foundation year”. Selecting that property for a country, I got the frequency of new foundations of HE institutions per year (see Fig. 5), and I saw immediately (F\(_{1}\)) a high concentration in two consecutive years: in 1986 and 1987 some 21 new HE institutions were founded in the Netherlands, on a total of 114: So some substantial changes in the HE system seem to have taken place! By selecting these two years, the list of organizations shows the names of the institutions that were founded in these two years. I could inspect the list, but also select a single institution and inspect the available information in the datastore, but also more broadly on the web, as all the organizations are also linked to their website and their Wikipedia page (F\(_{7}\), F\(_{8}\), F\(_{9}\)). So, I did not only have much numerical data in the data network, such as numbers of students and staff, but also qualitative (textual) data for further inspection. Looking at the various newly founded schools showed that these are all Universities of Applied Sciences, so the “second layer” Dutch HE institutions. By reading the historical information on their Websites, one would find out that the new founded institutions in fact are conglomerations of smaller schools into very large new institutions (F\(_{7}\), F\(_{9}\)). This indeed can be considered as a major reform of the Dutch HE system.
A follow-up question would be whether this is a typical Dutch phenomenon, or whether similar changes have taken place in other countries (F\(_{11}\)). Belgium could be a second case to inspect, and I followed the same steps. Indeed, as the browser shows, also here we find concentrations of foundations of new HE institutions, but now in the year 1995 when 32 new HE institutions were founded in Belgium. If I select the year 1995, I get a list with the names of the newly founded institutions and can further inspect the available information on those institutions. I did not have any prior knowledge on the Belgian system (F\(_{7}\)), but inspecting the list of names in the results, one immediately sees that the changes probably took place in the French speaking part of Belgium, as all institution names are French, and not in the Flemish speaking part (F\(_{6}\)). Indeed, the two language regions have their own HE system, so this could clearly be the case.
The third example I tried was Austria, and indeed also there I detected a concentration of new institutions in 2007 - a decade after the changes in Belgium and two decades after the changes in the Netherlands. Of the total of 102 HE institutions in Austria, 15 were created in 2007 - again a percentage suggesting some form of structural change. Even if one is completely unknowledgeable about the Austrian HE system, selecting the entity type in the browser tells us (F\(_{5}\)) that the changes have taken place in the sector of teacher education: the newly founded HE institutions are all of type “University of Education”, “University College of Teacher Education”, and “Pedagogical University”. Without further investigation, one already can conclude that the changes in the Austrian system are less broad than in the Netherlands or in Belgium, where the changes seem to cover a much larger part of the HE system.

Employing background knowledge to facilitate browsing of data.
4.2 Evaluating Research Portfolios with Regards to Current Societal Challenges
I used the faceted browser to browse CORDIS open dataset on H2020 EU projects to evaluate research portfolios. The browser showed the relevant characteristics of the projects, such as organizations involved, the organization type, and the program the project belongs to. The CORDIS dataset contains among others a text summarizing the content of the projects. Using the annotator tool helped me to extract general encyclopedic concepts from these textual descriptions and enabled me to browse data using two new facets (F\(_{7}\)), one for extracted terms and one for categories these terms belong to (see Fig. 6). Combining extracted terms has a great advantage, as we can combine technical research terms and policy related terms to retrieve the relevant projects (F\(_{1}\)). This may solve the problem of finding how research links to the grand societal challenges. This is a core problem in assessing relevance of research (described in technical terms and policy related terms). Because the resulting set for a very specific topic is generally not too large, I could even manually inspect the policy-science link. As an example, I looked at chemical research in H2020 projects, related to one of the societal challenges. There are quite some water related topics in the H2020 projects. In total 22.5% of the water projects seem related to chemistry. Going a little deeper into this case shows the multidisciplinary character of the water related research in H2020, and what disciplines are more and what are less important in this portfolio (F\(_{5}\), F\(_{8}\), F\(_{9}\)).

Comparing existing RDF faceted browsers based on the proposed serendipity design features.
5 Related Work
Path-finding on semantic graphs such as RDF graphs, where semantics of the relations between resources are explicitly defined, leads to discovering meaningful and insightful connections between multiple resources. That is the reason why most of the current research work which investigates serendipity on Linked Data is focused on novel approaches for semantic traversal of RDF graphs and thereby serendipitous discovery of new related nodes.
Tools such as Everything_Is_Connected_Engine [2] and DBpedia RelFinderFootnote 9 allow serendipitous storytelling and relation extraction which benefit from path-finding on general knowledge graphs. In addition to that, domain-specific knowledge graphs enable experts to reveal unsuspected connections and/or hidden analogies. For instance, the Linked Data version of the TCGA (The Cancer Genome Atlas Database) [18] allows bio-medical experts to discover how cancer types tend to metastasize into other cancer types and to serendipitously explore linked data to see how the rheology of certain cancer types affects this metastasis. Furthermore, serendipitous recommendation realized by LOD paths-based techniques has been incorporated into the design of many personalized systems to minimize blind spots in information delivery. For example, in [14], a serendipity-powered TV recommender using BBC programs dataset is presented.
There are also several frameworks, tools and related works in the area of browsing (semi) structured data which do not claim explicitly for a contribution in terms of serendipity (cf. Figure 7):
In [16] a generic guideline is proposed for designing expressive exploration environments over semi-structured data which organizes the design space of exploration tools in a three-layer architecture: Data Access, Functional, and Interaction/Interface. Except for the adaptation engine, their proposed architecture fits very well with the technical architecture of the FERASAT.
SemFacet [1] is a faceted search tool enhanced by the Semantic Web technologies to allow browsing of interlinked documents. SemFacet is implemented on top of a fragment of Yago and DBpedia abstracts. Similar to the pivot change feature in FERASAT, SemFacet allows refocusing results to support F\(_{8}\). Although SemFacet exploits ontology-based reasoning for generation of facets and queries, no user-contextualization is supported. The main advantages of FERASAT over SemFacet are supports for customized interactive facet visualizations and enabling federated SPARQL queries over multiple knowledge graphs tailored based on the user context. VisiNav [5] is another linked data navigation system which combines features such as keyword search, object focus, path traversal and facet selection to browse web of data with a large variance. Although VisiNav provides some mechanisms to address the issue of naked objects (i.e. objects that are displayed without type-specific styling), it does not provide any personalized integrated view on distributed knowledge graphs. In our opinion, VisiNav acts more as a tool for traversing web of data rather than a direct knowledge discovery tool. \facet [7] is a linked data faceted browser very similar to FERASAT but with limited capabilities to share the generated queries, adapt the results based on user context and to invert and randomize the facets for increasing the chance encounter. \facet enables multi-type browsing experience and allows adapting the dynamically generated facets based on their RDF relations. It also allows users to create facet specifications and build facet dependent visualizations and interactions to make surprising observations more noticeable. Linked Data Query Wizard [8] is a linked data browsing UI, heavily dependent on RDF Data Cube standard, which turns graph-based data into a tabular interface with support for search and filtering to facilitate exploring linked data. Although converting graphs to interactive spreadsheet tables increases the learnability of UI for users, it also results in limited capabilities for serendipity by limiting the flexibility of information visualization related to certain dimensions of data. gFacet [6] is a graph-based faceted browser which allows users to build their facets of interest on the fly. It enable users to perform a pivot operation and switch a facet to a result list. Color coded facets and their relationships facilitate explaining the surprising observations. However, no mechanism for sharing the query results, inverting and randomizing values is offered. Sparklis [4] is a query-based faceted search UI that uses the expressivity of natural language to facilitate browsing Linked Data and understanding the generated query. It does not exploit any interactive visualizations in the facets to make surprising observations more noticeable. Also using only a single facet on a single knowledge graph, to browse data, makes the divergent information behavior difficult to achieve, though it increases the expressiveness and scalability of the traversed paths.
To the best of our knowledge, the related work in the domain of Linked Open Data where other aspects of serendipity than mere semantic path-finding are addressed, is quite scarce. The closest to our work is [3] which is based on SPARQL querying perspective where authors propose a query modification process to support serendipity features F\(_{11}\): analogy, F\(_{1}\): surprising observation, F\(_{3}\): inversion, and F\(_{4}\): disturbance. There are also similar querying-based approaches in the domain of data mining [17] to enhance the expressiveness of query languages to allow queries like “Find all the customers with deviant transactions.” Or to offer meta-query languages (“Find me a pattern that connects something about writers” backgrounds and the characters in their novels”). What distinguishes our approach from the above work is our more comprehensive investigation of serendipity design features and their implications on linked data faceted browsing environments for fostering serendipity on LOD.
6 Conclusions and Future Work
In this paper we presented a novel faceted browsing environment on Linked Data called FERASAT which aims to foster accidental knowledge discovery while browsing data scattered over multiple knowledge graphs. We reviewed the related work and showcased the applicability of FERASAT in the domain of science, technology and innovation by describing two relevant use cases.
As future work, we plan to implement more serendipity-fostering strategies within our faceted browser environment, in particular for detecting successful errors and performing cross-domain analogical reasoning. We also envisage to evaluate the usability of our implementation using a rigorous evaluation framework and also to extend its application to other domains such as life sciences. Another important direction for future work is handling access control when combining public and private datasets in an integrated way as well as potential privacy issues entailed by our proposed Linked Data-based faceted browser.
Notes
- 1.
According to secondary sources.
- 2.
In Persian, the term ‘Ferasat’ refers to the ability of intuitive knowledge acquisition.
- 3.
- 4.
- 5.
- 6.
More details are available at http://ld-r.org/docs/configFacets.html.
- 7.
- 8.
- 9.
References
Arenas, M., Grau, B.C., Kharlamov, E., Marciuska, S., Zheleznyakov, D., Jiménez-Ruiz, E.: SemFacet: semantic faceted search over yago. In: 23rd International World Wide Web Conference, WWW 2014, Seoul, Republic of Korea, 7–11 April 2014, Companion Volume, pp. 123–126 (2014)
De Vocht, L., Coppens, S., Verborgh, R., Vander Sande, M., Mannens, E., Van de Walle, R.: Discovering meaningful connections between resources in the web of data. In: LDOW (2013)
Eichler, J.S.A., et al.: Searching linked data with a twist of serendipity. In: Dubois, E., Pohl, K. (eds.) CAiSE 2017. LNCS, vol. 10253, pp. 495–510. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-59536-8_31
Ferré, S.: Expressive and scalable query-based faceted search over SPARQL endpoints. In: Mika, P., Tudorache, T., Bernstein, A., Welty, C., Knoblock, C., Vrandečić, D., Groth, P., Noy, N., Janowicz, K., Goble, C. (eds.) ISWC 2014. LNCS, vol. 8797, pp. 438–453. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-11915-1_28
Harth, A.: VisiNav: a system for visual search and navigation on web data. Web Semant. Sci. Serv. Agents World Wide Web 8(4), 348–354 (2010)
Heim, P., Ertl, T., Ziegler, J.: Facet graphs: complex semantic querying made easy. In: Aroyo, L., Antoniou, G., Hyvönen, E., ten Teije, A., Stuckenschmidt, H., Cabral, L., Tudorache, T. (eds.) ESWC 2010. LNCS, vol. 6088, pp. 288–302. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-13486-9_20
Hildebrand, M., van Ossenbruggen, J., Hardman, L.: /facet: a browser for heterogeneous semantic web repositories. In: Cruz, I., Decker, S., Allemang, D., Preist, C., Schwabe, D., Mika, P., Uschold, M., Aroyo, L.M. (eds.) ISWC 2006. LNCS, vol. 4273, pp. 272–285. Springer, Heidelberg (2006). https://doi.org/10.1007/11926078_20
Hoefler, P., Granitzer, M., Veas, E.E., Seifert, C.: Linked data query wizard: a novel interface for accessing SPARQL endpoints. In: LDOW (2014)
Karger, D., Schraefel, M.: The pathetic fallacy of RDF. In: SWUI (2006)
Khalili, A., de Graaf, K.A.: Linked data reactor: towards data-aware user interfaces. In: 2017 SEMANTiCS. ACM (2017)
Khalili, A., Loizou, A., van Harmelen, F.: Adaptive linked data-driven web components: building flexible and reusable semantic web interfaces. In: Sack, H., Blomqvist, E., d’Aquin, M., Ghidini, C., Ponzetto, S.P., Lange, C. (eds.) ESWC 2016. LNCS, vol. 9678, pp. 677–692. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-34129-3_41
Khalili, A., Meroño-Peñuela, A.: WYSIWYQ - what you see is what you query. In: Ivanova, V., Lambrix, P., Lohmann, S., Pesquita, C. (eds.) Proceedings of the Third International Workshop on Visualization and Interaction for Ontologies and Linked Data Co-located with the 16th International Semantic Web Conference (ISWC 2017). CEUR Workshop Proceedings, Vienna, Austria, 22 October 2017, vol. 1947, pp. 123–130. CEUR-WS.org (2017)
Khalili, A., van Andel, P., den Besselaar, P.V., de Graaf, K.A.: Fostering serendipitous knowledge discovery using an adaptive multigraph-based faceted browser. In: Corcho, Ó., Janowicz, K., Rizzo, G., Tiddi, I., Garijo, D. (eds.) Proceedings of the Knowledge Capture Conference, K-CAP 2017, Austin, TX, USA, 4–6 December 2017, pp. 15:1–15:4. ACM (2017)
Maccatrozzo, V., Terstall, M., Aroyo, L., Schreiber, G.: SIRUP: serendipity in recommendations via user perceptions. In: IUI 2017, pp. 35–44. ACM (2017)
Norman, D.A.: The Design of Everyday Things: Revised and Expanded Edition. Basic Books Inc., New York (2013)
Nunes, T., Schwabe, D.: Towards the design of expressive data exploration environments. In: Proceedings of the Third International Workshop on Visualization and Interaction for Ontologies and Linked Data Co-located with the 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, 22 October 2017, pp. 60–74 (2017)
Ramakrishnan, N., Grama, A.Y.: Data mining: from serendipity to science. Computer 32(8), 34–37 (1999)
Saleem, M., Kamdar, M.R., Iqbal, A., Sampath, S., Deus, H.F., Ngonga, A.-C.: Fostering serendipity through big linked data. In: ISWC SemWeb Challenge (2013)
van Andel, P.: Anatomy of the unsought finding. serendipity: origin, history, domains, traditions, appearances, patterns and programmability. Br. J. Philos. Sci. 45(2), 631–648 (1994)
Acknowledgement
We would like to thank our colleagues from the Knowledge Representation and Reasoning research group at Vrije Universiteit Amsterdam for their helpful comments during the development of our Linked Data-based faceted browser. This work was supported by a grant from the European Union’s 7th Framework Programme provided for the project RISIS (GA no. 313082).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Khalili, A., van den Besselaar, P., de Graaf, K.A. (2018). FERASAT: A Serendipity-Fostering Faceted Browser for Linked Data. In: Gangemi, A., et al. The Semantic Web. ESWC 2018. Lecture Notes in Computer Science(), vol 10843. Springer, Cham. https://doi.org/10.1007/978-3-319-93417-4_23
Download citation
DOI: https://doi.org/10.1007/978-3-319-93417-4_23
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-93416-7
Online ISBN: 978-3-319-93417-4
eBook Packages: Computer ScienceComputer Science (R0)