
Abstract
Due to the rise in deep learning techniques used for the task of automatic image captioning, it is now possible to generate natural language descriptions of images and their regions. However, these captions are often too plain and simple. Most users on social media and other micro blogging websites use flowery language and quote like captions to describe the pictures they post online. We propose an algorithm that uses a combination of deep learning and natural language processing techniques to provide contextually relevant quotes for any given input image. We also present a new dataset, QUOTES500K, with the goal of advancing research requiring large dataset of quotes. Our dataset contains five hundred thousand (500K) quotes along with the author name and their category tags.
S. Goel, R. Madhok and S. Garg—Contributed equally to this work.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

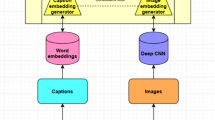

Notes
References
Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. CoRR abs/1409.0473 (2014)
Chaudhuri, S., Ganti, V., Kaushik, R.: A primitive operator for similarity joins in data cleaning. In: 22nd International Conference on Data Engineering (ICDE 2006), p. 5, April 2006
Denil, M., Bazzani, L., Larochelle, H., de Freitas, N.: Learning where to attend with deep architectures for image tracking. Neural Comput. 24(8), 2151–2184 (2012)
Elliott, D., Keller, F.: Image description using visual dependency representations. In: EMNLP, pp. 1292–1302. ACL (2013)
Farhadi, A., Hejrati, M., Sadeghi, M.A., Young, P., Rashtchian, C., Hockenmaier, J., Forsyth, D.: Every picture tells a story: generating sentences from images. In: Daniilidis, K., Maragos, P., Paragios, N. (eds.) ECCV 2010. LNCS, vol. 6314, pp. 15–29. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-15561-1_2
Kiros, R., Salakhutdinov, R., Zemel, R.: Multimodal neural language models. In: Xing, E.P., Jebara, T. (eds.) Proceedings of the 31st International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 32, pp. 595–603. PMLR, Bejing, China, 22–24 June 2014
Kiros, R., Salakhutdinov, R., Zemel, R.S.: Unifying visual-semantic embeddings with multimodal neural language models. CoRR abs/1411.2539 (2014)
Kiros, R., Zhu, Y., Salakhutdinov, R., Zemel, R.S., Torralba, A., Urtasun, R., Fidler, S.: Skip-thought vectors. CoRR abs/1506.06726 (2015)
Kondrak, G.: N-Gram similarity and distance. In: Consens, M., Navarro, G. (eds.) SPIRE 2005. LNCS, vol. 3772, pp. 115–126. Springer, Heidelberg (2005). https://doi.org/10.1007/11575832_13
Li, S., Kulkarni, G., Berg, T., Berg, A., Choi, Y.: Composing simple image descriptions using web-scale N-grams, pp. 220–228 (2011)
Miller, D.R.H., Leek, T., Schwartz, R.M.: A hidden Markov model information retrieval system. In: Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 1999, pp. 214–221. ACM (1999)
Mnih, V., Heess, N., Graves, A., Kavukcuoglu, K.: Recurrent models of visual attention. In: Advances in Neural Information Processing Systems, vol. 27, pp. 2204–2212 (2014)
Rashtchian, C., Young, P., Hodosh, M., Hockenmaier, J.: Collecting image annotations using Amazon’s Mechanical Turk. In: Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, CSLDAMT 2010, pp. 139–147. Association for Computational Linguistics (2010)
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Goel, S., Madhok, R., Garg, S. (2018). Proposing Contextually Relevant Quotes for Images. In: Pasi, G., Piwowarski, B., Azzopardi, L., Hanbury, A. (eds) Advances in Information Retrieval. ECIR 2018. Lecture Notes in Computer Science(), vol 10772. Springer, Cham. https://doi.org/10.1007/978-3-319-76941-7_49
Download citation
DOI: https://doi.org/10.1007/978-3-319-76941-7_49
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-76940-0
Online ISBN: 978-3-319-76941-7
eBook Packages: Computer ScienceComputer Science (R0)