
Abstract
In a dense RFID sensor network system, in order to prolong the life of the sensor network and reduce the interference between readers and the problem of eliminating redundant readers has always been the concern of the people. Now there are many algorithms and optimization technology to eliminate redundant reader in the RFID system. Inspired by the previous algorithms such as SCBA and RRE, this paper presents an improved algorithm, ICBA (Improved Count Based Algorithm) which based on the RRE and SCBA, using the count of covered tags and the Greedy Algorithm to eliminate redundant readers. The simulation experiments show that the algorithm ICBA can eliminate more redundancy readers than other algorithms. The same case, ICBA algorithm compared with other algorithm is increased by 3.2%–15% of redundant reader eliminating rate.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Radio Frequency Identifier (RFID) is a kind of commonly used wireless communication technology, which can read and write target’s data through the radio signal, and in the identifying process the identify system does not need to establish any contact with the identified targets. Because the RFID system is low cost, high safety, large capacity, nowadays it is widely used in all aspects of people’s life, such as automation and identity identification, access control, supply chain inventory tracking. In a densely deployed RFID network, redundant readers can cause a waste of energy and easily lead to mutual interference, because the radio frequencies of two or more neighboring readers may overlap and interfere. Therefore how to use the minimum number of readers effectively cover every tag, which is called redundant readers elimination problem. Redundant readers elimination problem is a basic problem in the RFID system, which has proved to be NP - hard problem [1].
In this paper, an Improved Count Based Algorithm (ICBA) is designed to detect and eliminate more redundant RFID readers in the complicated RFID networks. ICBA is based on the every tag’s count of readers which covered this tag and the every reader’s count of tags which are covered by this reader. Simulation results illustrate that ICBA has a better capacity to detect more redundant readers, a maximum of up to 15% more effectively than LEO and RRE in the conditions we set,and increased by 3.2% of redundant reader eliminating rate compared with the CBA which is a good algorithm for redundant readers elimination.
2 Relevant Research
The RFID system mainly is composed by two components, tags and readers. The RFID tag can store information and be detected by readers. The readers can read and write data which stored at tag’s memory through radio signal. For reader’s convenience, a definition of redundant reader is given as following.
Definition of redundant reader: In a RFID network, a RFID reader covers a group of RFID tags, which are also covered by the other RFID readers simultaneously. This reader is called as the redundant reader [2,3,4].
As the simulative RFID network showed in Fig. 1, Tag T1 and tag T2 are covered by reader R1 and they also are covered by R2. All tags in R1 are covered by other readers, so the R1 is a redundant reader. Similarly, R2 and R3 are also redundant readers due to the same reason [4]. Although all the readers are redundant readers in this RFID network, we can only eliminate at most two redundant readers without affecting the work of the RFID system.

Redundant reader
Nowadays there are many algorithms and optimization technique to eliminate the redundant reader of the RFID system. Some introduction and analysis of algorithms for eliminating redundant readers are given as following:
2.1 Algorithm RRE
The Redundant Reader Elimination (RRE) is the first distributed algorithm for eliminating redundant readers, which was proposed by Carbunar et al. in 2005 [1]. The main idea of Algorithm RRE is using the greedy algorithm: If a tag T1 is covered by multiple readers, find the reader which covered T1 and covered most of tags, then set T1’s holder to the reader’s ID. With this strategy, the tags will be greatly covered by the few readers and the goal of eliminating some redundant readers can be reached.
Algorithm RRE steps are described below:
-
①
Each reader delivers write commands that write the tagcount (the number of tags which are covered by this readers) to all tags which this reader covers. Each tag stores only the highest value of tagcount that it received and the ID of the corresponding reader.
-
②
The reader queries each of the tags in the inquiry area and reads the tag’s holder of each tag in the coverage area. A non-redundant reader should be locked at least to one tag and this reader will remain active. While readers that do not lock any of the tags are marked as redundant readers and can be safely turned off (Fig. 2).
Fig. 2. 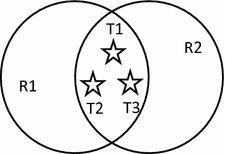
An example of RFID system network

The RRE algorithm has its flaw that the selection of tag’s holder is random and unreliable [4]. Because when a tag is in the overlapping areas of two or more reader and the number of tags covered by the two or more readers is the same, each reader of them has a same chance to become this tag’s holder and this tag randomly chooses a reader of them as its holder. In Fig. 1 R1 and R2 have same chance to become the holder of T1, T2 and T3 according to Algorithm RRE, because R1’s tagcount is same as the R2’s tagcount. R1 and R2 randomly become the holder of these tags. The time-complexity of RRE is O(n logβ logm) m is the number of readers, n is the number of tags and β is the bit length of RFID tag identifiers [1, 7].
2.2 Algorithm LEO
In order to effectively reduce the read and write operations of readers, Ching - Hsien et al. proposed the LEO (Layered Elimination Optimization) algorithm [5]. This algorithm is based on the principle of “first come, first served”.
Algorithm RRE steps are described below:
-
①
RFID reader (Ri) delivers a query signal that check the tag’s holder (holder) to all tags in its query area and the tags respond the corresponding readers.
-
②
There are two possibilities for receiving a tag response, the tag’s holder = “NULL” or the tag’s holder = “Rk”. If the holder = “NULL”, the reader delivers a write command that set the reader’s Id to the tag holder. If the holder = “Rk” and Rk ≠ Ri, the reader skips the reply information of this tag.
-
③
When a reader receives all tags’ response that their holder ≠ Ri, that means all tags have belonged to other readers, the reader is a redundant reader, close the reader.
LEO algorithm can effectively reduce the read and write operation compared with other algorithms [2]. But the LEO algorithm randomly determines the holder of the tag, so the algorithm is unreliable. In Fig. 1 R1 and R2 have same chance to become the holder of T1, T2 and T3 and which is the holder depends on the first query command. The time-complexity of LEO is O(mn), m is the number of readers and n is the number of tags [2].
2.3 Algorithm CBA
Algorithm CBA is based on the number of covered readers and involves the influence of the neighboring readers. In algorithm CBA, the redundant readers will be eliminated according to the sum of the count of the neighboring readers and the count of tags covered [6].
Algorithm RRE steps are described below:
-
①
RFID reader (Ri) delivers a query signal that check the tag’s holder (holder) to all tags in its query area and records the number of tags covered by this reader as tagcount. Each tag records how many readers cover it and writes this value as its readercount.
-
②
If the reader queries a tag’s readercount = 1 in the inquiry area, change the holder of all tags that are covered by this reader to the reader ID. If there is readercount > 1 for all tags in the reader’s query area, mark the reader as a redundant reader and close the reader. Decrement the reader count of all tags in the query area.
-
③
When all readers in the RFID system have run step 2, the algorithm ends and some redundant readers are eliminated.
Algorithm CBA involves the influence of the neighboring readers and finds the un-redundant readers in the first step while RRE and LEO don’t, but the RRE algorithm also has its flaw that the elimination rate is connected with the order of reader selection.
Such as shown in the Fig. 3, if in the order of R1-> R2-> R3, T1’s readercount = 2 and T2’s readercount = 2, the R1 and R2 are eliminated according the Algorithm CBA. If in the order of R3-> R1-> R2, the R3 is the only redundant reader which should be eliminated in this wireless network according to Algorithm CBA. So this means that the redundant reader eliminating rate of Algorithm CBA is related with the order of reader selection. The time-complexity of CBA algorithm is O(mn2), m is the number of readers and n is the number of tags [6].

An example of RFID system network
3 Algorithm ICBA
Algorithm ICBA (Improved Count Based Algorithm) is designed by improving CBA and RRE. Algorithm ICBA concerns about the influence of the neighboring readers while RRE and LEO don’t. In algorithm ICBA, the redundant readers will be eliminated according to readercount from small to large order while CBA don’t. So Algorithm ICBA can solve the problem that the elimination rate is connected with the order of reader selection in the Algorithm CBA and the problem that the selection of tag’s holder is random and unreliable in Algorithm LEO and RRE.
3.1 Algorithm ICBA
Input: The information of readers and tags, such as reader coordinates and tag coordinates (The value of readercount and tagcount will be calculated by the reader coordinates and tag coordinates).
Output: The ID of redundant readers and the number of the redundant readers.

3.2 Process
Algorithm ICBA steps are described below:
-
①
The first step is information gathering phase. Every reader broadcasts a query command to tags which are covered by this reader and the reader records the number of tags it covers as the value of tagcount. Meanwhile each tag records the number of readers cover it as the value of readercount. Then readers deliver a query command again and readers send the data of their tagcount and every tag’s readercount to the centralized processing host.
-
②
All tags are sorted by the value of readercount from small to large in the centralized processing host. Meanwhile, the centralized processing host assigns a list of reader to each tag that used to record which readers cover this tag.
-
③
According to readercount from small to large order, find every tag’s holder. If the tag’s readercount = 0, it means no reader cover this tag and we set its holder to −1. If the tag’s readercount = 1, it means this tag is only covered by a unique reader and this reader is non-redundant reader. All the tags in this non-redundant reader’s interrogation zones are held by this reader. The tag that has the holdid value only responds to the reader access that corresponds to the holdid value (for other readers do not respond to). When each tag set the tag’ holder, the tagcount of the corresponding readers also update. If a reader’s tagcount = 0, this reader can be safely turned off, because no tag is covered by this reader.
-
④
To those tags whose readercount ≥ 2, using the ideas of RRE greedy algorithm, set the tag’s holdid to the ID of reader which is maximum tagcount value and covers this tag.
-
⑤
When all tags have their holders, the algorithm ends and some redundant readers are eliminated.
3.3 Analysis
Algorithm ICBA is based on CBA and RRE. Through the order of tags according the value of readercount, the ICBA can solve the problem of the eliminating rate is related with the order of reader selection. And the second step of ICBA is a kind of improved Greedy Algorithm that tags which has holder only respond the query commands of theirs holders, so Algorithm ICBA can avoid the happening of random selection in the RRE. The algorithm firstly calculates the value of readercount and tagcount. The time-complexity of the first step is O(mn). Then the time-complexity of sorting tags is O(nlogn) (Using the Quicksort). The time-complexity of finding tag’s holder and updating the value of other readers is O(mn2). In summary, the time-complexity of ICBA is O(mn2), m is the number of readers and n is the number of tags. The algorithm ICBA has the same time complexity as the algorithm CBA. Compared with other algorithms such as RRE(O(n logβ logm)) and LEO(O(nm)), the ICBA(O(mn2)) needs more time but has a better elimination effect.
4 Simulation Experiments and Analysis
A RFID network simulation environment was designed and then compared with the classic algorithms RRE, LEO and CBA. ICBA algorithm turns out to be highly efficiency.
The following experiment data are all from the average of 3 experiments.
4.1 Experiment 1
The first experiment is designed to illustrate the performance of different algorithms under different number of tags. At the invariable regional size of 1000 × 1000, randomly deploying 500 readers, and the working radius of readers are 50 m. The numbers of tags increases from 1000 to 5000. The following Fig. 4 shows the comparison of results among RRE, LEO, CBA and ICBA under the condition of the above variables.

Performance comparison of each algorithm under different number of tags.
As it is shown in Fig. 4, ICBA algorithm can detect and eliminate the most of redundant readers in all situations. As the number of tags increases, the number of redundant readers eliminated by each algorithm has declined. Because more readers might become non-redundant readers, with more tags covered by a certain reader.
4.2 Experiment 2
In the second experiment is designed to figure out the performance of different algorithms under different number of readers. At the invariable regional size of 1000 × 1000, we randomly generate 1000 tags and the numbers of readers increases from 200 to 600 and their working distance is 50 m. when the number of randomly deployed RFID. The following Fig. 5 shows the comparison of results among RRE, LEO, CBA and ICBA under the condition of the above variables.

Performance comparison of each algorithm under different number of readers
As it is shown in Fig. 5, the numbers of redundant readers eliminated in all four algorithms increase gradually when the number of readers deploying in this area is rising. When more readers come into the system, the network becomes denser and the probability of every reader with more neighbors gets larger. ICBA algorithm involves a condition of neighbor count, therefore an increasing number of redundant readers will be detected.
4.3 Experiment 3
The third experiment is designed to figure out the performance of different algorithms under different length of working radius of RFID readers. At the invariable regional size of 1000 × 1000, 500 readers and 1000 tags are randomly generated. The length of radius of readers in the experiments are from 20 m to 60 m. The following Fig. 6 shows the comparison of results among RRE, LEO, CBA and ICBA under the condition of the above variables.

Performance comparison of each algorithm under different radius of readers
As it is shown in Fig. 6, the tendencies of all algorithms are similar in this experiment. At the beginning, with the increase of working radius of readers, the count of tags each reader covering gradually rises and the probability of a reader becoming redundant. Later, when the working radius goes up to 30 m, more multiple readers might cover the same tags simultaneously, which causes more readers become redundant (Fig. 7).

Picture of simulation
5 Conclusion
In this paper, we have designed a new centralized algorithm named ICBA (Improved Count Based Algorithm) which based on the value of readercount (how many reader covers this tag) and tagcount (how many tags are covered by this reader) to solve the redundant reader elimination problem in wireless RFID network system.
Algorithm ICBA solves the problems of eliminating rate is relate with order in CBA and the randomness in RRE and LEO. Simulations show that compared to other algorithms the performance in redundant reader elimination of ICBA algorithm is more efficient in most of the situations and maximum of up to 15% more effectively than Algorithm LEO.
The data of simulation experiments is based on the ideal experimental environment. Although it is made close to the deployment of RFID system actual applying environment as much as possible, there is still a difference from the actual situations, which needs further testing. Meanwhile it is also necessary to consider the indoor environment and other interferential factors on the signal attenuation.
References
Carbunar, B., Ramanathan, M.K., Koyuturk, M., Hoffmann, C., Grama, A.: Redundant-reader elimination in RFID systems. In: 2005 Second Annual IEEE Communications Society Conference on Sensor and Ad Hoc Communications and Networks, pp. 176–184 (2005)
Ma, M., Wang, P., Chu, C.H.: A novel distributed algorithm for redundant reader elimination in RFID networks. In: 2013 IEEE International Conference on RFID - Technologies and Applications (RFID-TA), pp. 1–6. IEEE (2013)
Yu, K.M., Yu, C.W., Lin, Z.Y.: A density-based algorithm for redundant reader elimination in a RFID network. In: Second International Conference on Future Generation Communication and Networking, FGCN 2008, vol. 1, pp. 89–92. IEEE (2008)
Shen, Z., Yang, Z.: Three-count based algorithm for redundant readers elimination in the complicated RFID system. Internet Things Cloud Comput. 3(2), 8–13 (2015). doi:10.11648/j.iotcc.20150302.11
Hsu, C.-H., Chen, Y.-M., Yang, C.-T.: A layered optimization approach for redundant reader elimination in wireless RFID networks. In: IEEE Asia-Pacific Services Computing Conference, pp. 138–145 (2007)
Pan, S., Yang, Z.: A count based algorithm for redundant reader elimination in RFID application system. In: 2013 Third International Conference on Intelligent System Design and Engineering Applications (ISDEA), pp. 30–33, 16–18 January 2013
Hung, J.W., Li, I.H., Lin, H.H., et al.: The first search right algorithm for redundant reader elimination in RFID network. In: Proceedings of the 9th WSEAS International Conference on Software Engineering, Parallel and Distributed Systems (SEPADS), pp. 177–183 (2010)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 IFIP International Federation for Information Processing
About this paper
Cite this paper
Zhang, X., Yang, Z. (2017). An Improved Algorithm for Redundant Readers Elimination in Dense RFID Networks. In: Shi, Z., Goertzel, B., Feng, J. (eds) Intelligence Science I. ICIS 2017. IFIP Advances in Information and Communication Technology, vol 510. Springer, Cham. https://doi.org/10.1007/978-3-319-68121-4_29
Download citation
DOI: https://doi.org/10.1007/978-3-319-68121-4_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-68120-7
Online ISBN: 978-3-319-68121-4
eBook Packages: Computer ScienceComputer Science (R0)