
Abstract
Stencil computation is a performance critical kernel that is widely used in scientific and engineering applications. In this paper we develop a redundant computation elimination (RCE) algorithm to exploit temporal locality. We implement the RCE optimization strategy using ROSE compiler infrastructure. The experiments with a benchmark of eleven stencil applications show that temporal locality of RCE averagely improves performance by 15.4% and 10.1% for benchmark without or with SIMD optimization.
G.Tan —We would like to express our gratitude to all reviewers constructive comments for helping us polishing this paper. This work is supported by The National Key Research and Development Program of China (2016YFB0201305), National Science and Technology Major Project (2013ZX0102-8001-001-001) and National Natural Science Foundation of China, under grant No. (91430218, 31327901, 61472395, 61272134, 61432018).
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
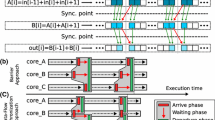


References
Briggs, P., Cooper, K.D., Simpson, L.T.: Value numbering. Softw.-Practice Exp. 27(6), 701–724 (1997)
Callahan, D., Carr, S., Kennedy, K.: Improving register allocation for subscripted variables. In: ACM Sigplan Notices, vol. 25, pp. 53–65. ACM (1990)
Cooper, K., Eckhardt, J., Kennedy, K.: Redundancy elimination revisited. In: Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques, pp. 12–21. ACM (2008)
Datta, K., Yelick, K.A.: Auto-tuning stencil codes for cache-based multicore platforms. Ph.D. thesis, University of California, Berkeley (2009)
Denning, P.J.: The locality principle. Commun. ACM 48(7), 19–24 (2005)
Denning, P.J., Schwartz, S.C.: Properties of the working-set model. Commun. ACM 15(3), 191–198 (1972)
Ding, C., Zhong, Y.: Predicting whole-program locality through reuse distance analysis. In: ACM SIGPLAN Notices, vol. 38, pp. 245–257. ACM (2003)
Gupta, S., Xiang, P., Yang, Y., Zhou, H.: Locality principle revisited: a probability-based quantitative approach. J. Parallel Distrib. Comput. 73(7), 1011–1027 (2013)
Himeno, R.: Himeno benchmark (2011)
Lam, M., Sethi, R., Ullman, J., Aho, A.: Compilers: Principles, Techniques, and Tools (2006)
Malony, A.D., Cuny, J., Tau, S.S.: Tuning and analysis utilities. Technical report, LALP-99-205, Los Alamos National Laboratory Publication (1999)
Peng, L., Seymour, R., Nomura, K.-I., Kalia, R.K., Nakano, A., Vashishta, P., Loddoch, A., Netzband, M., Volz, W.R., Wong, C.C.: High-order stencil computations on multicore clusters (2009)
Phillips, E.H., Fatica, M.: Implementing the Himeno benchmark with CUDA on GPU clusters. In: 2010 IEEE International Symposium on Parallel & Distributed Processing (IPDPS), pp. 1–10. IEEE (2010)
Pouchet, L.-N.: Polybench: The polyhedral benchmark suite, July 2012. http://www.cs.ucla.edu/~pouchet/software/polybench/
Quinlan, D., Liao, C., Too, J., Matzke, R., Schordan, M.: Rose compiler infrastructure (2013)
Sair, S., Charney, M.: Memory behavior of the spec2000 benchmark suite. IBM TJ Watson Research Center Technical Report (2000)
Unat, D., Cai, X., Baden, S.B.: Mint: realizing CUDA performance in 3D stencil methods with annotated C. In: Proceedings of the International Conference on Supercomputing, pp. 214–224. ACM (2011)
Zhang, Y., Mueller, F.: Autogeneration and autotuning of 3D stencil codes on homogeneous and heterogeneous GPU clusters. IEEE Trans. Parallel Distrib. Syst. 24(3), 417–427 (2013)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing AG
About this paper
Cite this paper
Yuan, L., Liu, J., Luo, Y., Tan, G. (2016). Locality of Computation for Stencil Optimization. In: Carretero, J., Garcia-Blas, J., Ko, R., Mueller, P., Nakano, K. (eds) Algorithms and Architectures for Parallel Processing. ICA3PP 2016. Lecture Notes in Computer Science(), vol 10048. Springer, Cham. https://doi.org/10.1007/978-3-319-49583-5_34
Download citation
DOI: https://doi.org/10.1007/978-3-319-49583-5_34
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-49582-8
Online ISBN: 978-3-319-49583-5
eBook Packages: Computer ScienceComputer Science (R0)