
Abstract
With the increasing number of Web services, the personalized recommendation of Web services has become more and more important. Fortunately, the social network popularity nowadays brings a good alternative for social recommendation to avoid the data sparsity problem that is not treated very well in the collaborative filtering approach. Since the social network provides a big data about the users, the trust concept has become necessary to filter this abundance and to foster the successful interactions between the users. In this paper, we firstly propose a trusted friend detection mechanism in a social network. The dynamic of the users’ interactions over time and the similarity of their interests have been considered. Secondly, we propose a Web service social recommendation mechanism which considers the expertise of the trusted friends according to their past invocation histories and the active user’s query. The experiments of each mechanism produced satisfactory results.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The growing number of Web services makes it difficult for the user to discover the appropriate Web services by using the specialized search engines (e.g. Xmethods.net, WebServiceX.net, ProgrammableWeb.com) or public registries (e.g. UDDI, ebXml). The reason is that the latter ones suffer from low accuracy results [14] mainly because of their centralized structure and do not take into account the users’ profiles (e.g. interests, preferences, behaviors). A successful approach to tackle information overload [22] is the Recommender System (RS) [20] which can help the users to provide a list of selected items (i.e. services, products) that they are likely to enjoy. Collaborative Filtering (CF) is one of the most successful approaches which utilizes the feedback of many users to find similar users and items that serve as a basis for the recommendations. However, this approach has some problems, such as the data sparsity and the cold start [23]. In the past few years, the advent of social media enables the user to easily communicate and make relationships with other users. Frequently, the user spends more time to use his Egocentric (or personnel) Social Network (ESN) to find items which are liked by his friends in the past. Consequently, the CF approach has become unqualified to make more effective recommendation [23] because it always considers that the users one independent. In fact, the Social Recommendation (SR) approach appeared to provide the users with more personalized recommendation [23]. It takes into account the online users who are connected via various types of social relations (e.g. friendship, co-worker, family, business). Moreover, the SR takes advantage of research results from Social Network Analysis (SNA) in order to capture and analyze the social information.
At the first level, in our real life, the users would like to turn to his closest friends to solicit recommendations [13]. However, in SN, some noisy and malicious information, can be provided. This type of information may sneak into the inputs of RS [5]. For this reason, trust [8] is required to filter the big data about the users and to foster their successful interactions. In fact, how to detect trust relation between the users is another challenge. In general, trust is a complex relationship based on a wide range of factors [21] and may be affected by the users’ interactions, their interests, etc. However, most of the trust– aware Web service recommendation studies neglect these users’ social data and are based only on the measures which are related to the network structure, such as centrality degree [2], similarity of network structure [11] or users’ proximity [12, 15]. Other research studies [18, 19] focused on users’ interactions to compute the social trust but all of them have neglected the impact of the time. Contrariwise, [3, 17] are considered the temporal factor. At the second level, the majority of SR approach use only the rating of similar or trusted users in the prediction step of service to be recommend but they neglect the user’s expertise. Thus, in our real life, some users prefer the advice not only of their trusted friends but also of their expertise [12, 27]. Some few works [15, 27] have proposed to quantify the user’s expertise, for example in terms of how many times the user has used the required Web service. For this reason, we envisage that the exploitation of the SN to capture the social trust from the collective users and their expertise are promising solutions to enhance Web service discovery process.
In this paper, we present an enhancement of our previous research on Web service decentralized discovery [11]. Our approach exploits the knowledge of users’ social networks to provide higher quality recommendations than current CF approach. We propose, in the first step, a social trust detection mechanism between the users who are involved in ESN. The level of social trust is computed by aggregating two influential factors such as the degree of interaction over time between a couple of users and the similarity degree of their interests. In the second step, we propose to take into account the computed trust level to personalize the Web service recommendation of an active user according to the expertise of his trusted friends.
The rest of this paper is organized as follows. Section 2 presents briefly a background of the trust notion in social computing. Section 3 presents the enhanced architecture of our previous Web service decentralized discovery process. Sections 4 and 5 detail respectively the social trust detection mechanism and the expertise– based web service social recommendation. Section 6 illustrates an example to explain better our idea. Section 7 exposes some experiments and discusses the obtained results for each proposed mechanism. Section 8 states some studies which related to Web service social recommendation. Finally, we conclude by outlining our future works.
2 Background
With the growing popularity of social media, Social Recommender System (SRS) [23] has attracted increasing attention. SRS is defined as any RS that recommends items with online social relations as an additional input. In addition, the main contributions of SRS are, firstly, significantly solve the problem of data sparsity [23] and, secondly, improve the recommendation quality since the connected users provide different types of information from similar users [10]. The success of social media, especially the SN, is largely due to their open and decentralized nature. However, these characteristics open an horizon for a wide range of perspectives and intentions. Indeed, trust is required to filter the big data about the users and to foster their successful interactions. In fact, how to detect trust [8] relation between the users is a another challenge. In literature, there is no universal definition of trust [21]. However, the majority of research studies agree that trust is a subjective notion which depends on the users’ interactions and reflects their competences, etc. The value of trust was measured in several ways depending on some properties [21, 28]. Global trust is defined as a value representing the reputation of a user. Local trust is defined as a value assigned by a person to another according to his own knowledge of the latter. Direct trust is the result of exclusive direct interactions between two persons. Indirect trust is the fact that the person can complete his knowledge about other persons only by the advice of his trusted friends. Trust is asymmetric [29] which means that is not necessarily identical in both directions. Trust is dynamic [29] in the way that it may decrease and increase, become less important or relevant, and decay with the time. A user trusting another is gradually built up and keeps changing over time. This change may be influenced by very important factors. In what follows, we enumerate some impact factors that we consider very important to deduct the trust level between a couple of users.
-
Social interactions. The SN enables the users to communicate via various social activities (e.g. send message, share photo). These activities are considered a key indicator of the type and the quality of relation between two users. Some studies [19] used this factor to detect the trust relation in a SN.
-
Temporal factor. Any interaction between two users occurs at a given time, in a given situation and in a particular place [21]. Thus, trust depends on the time. [3, 17] is one of the few studies that considered the temporal dimension. [3] affirmed that the old feedback may not always be relevant in order to estimate global trust. Furthermore, in [17], old friends are considered more trustworthy than new friends. From our point of view, this assumption is not necessarily correct because the social relations between friends change over time, and some friends who used to be very close may no longer be.
-
Users’ similarity. There is a strong correlation between trust and similarity [30]. The users prefer the suggestions that come from others with similar tastes and affinities. Likewise, they prefer in priority the recommendations that come from their closest friends [13]. That’s why, the majority of the RS are mainly based on the similarity between users according to their rating to different items (e.g. movie, music, service). However, the recommendation quality is weak due to the data sparsity problem because the users’ rating matrix is still sparse.
To synthesize, the richness of SN, such as the user’s generated content and interaction [9], from our point of view, can be exploited to compute the level of trust between the users. Furthermore, the users’ social networks are represented by their social profiles which describe their characteristics, interests, social activities, etc. Hence, the social information can be used as input to recommendation mechanism. In the next section, we will present our decentralized discovery approach.
3 Decentralized Web Service Discovery Process
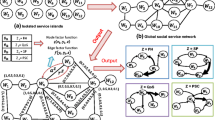
Our current work is an evolution of our previous approach of decentralized web service discovery based on the user’ social profile [11]. In this approach, we have inspired the idea of SOAF model [25] to integrate the users and their satisfactory Web services into the same structure network. We have proposed a SC-WSD system (for Social Context based Web Service Discovery) to analyze and filter the ESN for a given user. we have proposed a social relationship filtering step which is based on the network structure similarity in terms of mutual friends to keep only the user’s closest friends. This step did not rely on the social trust on the one hand. On the other hand, we have not use the recommendation mechanism that is based on the friend’s expertise. Hence, in this paper, we suggest extending our decentralized discovery approach by introducing the concept of social trust and the user’s expertise. We think that if a user knows that the discovered services which are interacting by his trustworthy and expert friends, she will be more confident. As shown in Fig. 1, our novel version of our SC-WSD system is composed of three mechanisms.

A novel architecture of our SC-WSD [11]
-
1.
Social Trust Detection Mechanism (STDM). This step consists, at the first level, in analyzing the user’s social profile in order to extract the useful information. At the second level, computing the social trust level between a couple of users and keeping this level in Trust matrix (\(U \times U\)). We choose to represent the personal and structural data by the semantics profiles with SOAF ontology [25]. Next, we represent the user’s interactions with his friends by a vector which contains the type of each interaction (e.g. send a message, post a comment, share a photo), the date of interaction and the involved friends.
-
2.
Social Recommendation Mechanism (SRM). At first, we take into account the past invocation history of each trusted friends that is filtered by the user’s query (i.e. is formulated by the items/keywords which are related to a specific domain/category). Secondarily, we compute the level of expertise for each friend by domain or extract it from the Expertise matrix (\(U \times I \times C\)). Thereafter, we predict the score of each recommended Web service according to the Rating matrix (\(U \times S\)). We aim to return for each active user a ranked list of the best Web services by descending order.
-
3.
Management Network and Updating Mechanism (MN and UM). After each interaction between the user and the selected Web service (i.e. invoke and assign a score), SC-WSD system starts to implicitly update the SOAF user’s social profile by the only successful Web services. This mechanism aims also at managing Web services (i.e. service advertisement and removal) in the global SN since this latter is characterized by its dynamic aspect. Thereafter, three possibles cases are presented in this mechanism. In the first case, if a web service and its properties (e.g. name, endpoint) have already existed in the user’s profile, then we don’t add it. Contrarily, we suggest adding this service and updating its assigned score in the Rating matrix (\(U \times S\)). In the second case, if a service is removed from the SN by his provider, then it must be removed from the user’s profile and his corresponding rating from matrix. In the last case, if a service is published and has never been used before by other friends, we suggest notifying them about this service by sending an E-mail.
In the two next sections, we will detail the STDM and SRM.
4 Social Trust Detection Mechanism
The STDM takes as input the social profile of an active user and his vector of social activities/interactions with his friends. This mechanism performs in two steps. The first step consists in analyzing the user’s ESN. The second step consists in applying some measures to compute the social trust level between the users.
4.1 Egocentric Social Network Analysis
This step consists in analyzing the user’s SN in order to extract useful information. In literature, two approaches of the SNA are distinguished [4]. The socio-centric approach (or complete network) focuses on all the actors and the links. The ego-centric approach (or personal network) focuses on the network surrounding one actor (ego) and his links. In this paper, we focus on an egocentric analysis to detect and calculate the social trust from the individual side. In our global SN, each user is described by his SOAF profile [11]. This profile contains various types of data about the user, like his permanent data (e.g. name, age, country), his dynamic data (e.g. interests, preferences, social activities, past invocation history with Web services). In order to detect and evaluate the social trust, we suggest two influential factors of trust. The first factor concerns the time-aware interactions. In fact, the SN sites enable the users to communicate via various social activities. These interactions can provide information of the relationship strength between a pair of users and can reflect how much they are close. The second factor concerns the interest similarity. Trusting someone does not necessarily mean sharing the same preferences or interests with him. Therefore, the similarity between users (in terms of interests, preferences, etc.) proves necessary.
4.2 Level of Trust Computing
In this step, we detect only trustworthy friends who have a direct connection with an ego user. On the one hand, we consider that (i) trust is asymmetric and non-transitive; (ii) a user can not trust strangers who do not have direct links with him; and (iii) trust is dynamic as it changes over time and may decay with time. On the other hand, We adopt a local metric of trust computing which varies from one user to another. Therefore, we compute the social trust level by aggregating the values of two factors (i.e. users’ interests and their interactions). Compared to [18, 19], our level of trust takes into account the temporal factor in order to compute the level of interaction between the users.
Time-Aware Interaction Degree. Based on the analysis step, we represent by a vector all the types of social interactions and we specify for each type of activity (e.g. comment, message) the date of interaction and the involved friends who have direct connection with the ego. Thereafter, we compute the degree of interaction between the users by taking into account the influence of the time factor. Firstly, we suggest calculating the number of interactions (\(NI_f\)) between the ego and his friend \(u_j\) in the period of time \(\varDelta _t\) (i.e. for each year) according to Eq. (1). Secondly, we calculate the total number of interactions (\(NI_{all}\)) of the ego, with all his friends in the same period \(\varDelta _t\) according to Eq. 2. Finally, the time-aware interaction degree measure \(DoI(ego, u_j)\) is calculated according to Eq. 3.
where \(\varDelta _t\) is the period between the date of the first interaction and the current date between ego and \(u_j\) .
Interests Similarity Degree. In the ESN, each user is usually characterized by his semantic social profile (i.e. RDF/FOAF ontology). By analyzing the SN, we compute the degree of similarity \(DoS_{interest}\) between two users according, particularly, to their interests in order to find the closest friends of the ego-user. We adopted a Jaccard similarity coefficient as a measure of interest similarity which is based on the comparison of the common interests of ego and \(u_j\). Therefore, we count the number of common interests and the total number of interests in both users. For each pair of nodes (\(ego, u_j\)), the degree of similarity \(DoS_{interest}({ego},{u_j})\) can thus be calculated as shown in Eq. 4.
With \(DoS_{interest}({ego},{u_j})\) is in interval of [0,1]. If \(DoS_{interest}({ego},{u_j})\) = 1, it indicates that the user \(u_j\) is similar to his friend ego while \(DoS_{interest}({ego},{u_j})\) = 0 indicates that the user \(u_j\) completely different to his friend ego.
Level of Trust Metric. Based on the analysis of egocentric network, we propose that the trust degree between a user (ego) and his directed friends is a quantified value which is correlated with two main factors: time-aware interaction degree \(DoI(ego, {u_j})_{\varDelta _t}\) and interest similarity \(DoS_{interest}\). We proposed that the Level of social Trust \(LoT(ego, {u_j})\) denotes the trust value that user ego assigns implicitly to friend \(u_j\). This level is in interval of [0, 1] and which is calculated by Eq. 5.
where \(DoI(ego,{u_j})_{\varDelta _t}\) is the interaction degree over time, and \(DoS_{interest}(ego,{u_j})\) is the interest similarity degree, with \(\alpha \) and \(\beta \) are in the interval of [0, 1] and \(\beta \) = 1 \(-\,\alpha \) . If \(LoT(ego, {u_j})\) = 0, it indicates that the user ego completely distrusts his friend \(u_j\) while \(LoT(ego, {u_j})\) = 1 indicates that the user ego completely trusts his friend \(u_j\) .
Once the level of social trust applied to all the friends of the active user (ego), the obtained values of trust will be stored in a Trust matrix (U \(\times \) U). In addition, the trust between two friends is dynamic because it depends on the change of their interaction frequency in time. In the recommendation purpose, the list of trusted friends differs from a user to another. In our STDM, we choose a dynamic trust threshold \(\gamma \) that adapts to each user instead of using the one static threshold that will be used for all the users in order to select their trusted friends like in [11]. In this case, the trust dynamicity is not detected. However, in our current research work, the best trusted friends of the user ego will be recommended where the level of social trust \(LoT(ego, {u_j}) \ge \gamma \), and the dynamic trust threshold \(\gamma \) is calculated according to Eq. 6.
with \(T_i\) is the list of trust levels of \(u_i\) to all his friends and distinct(\(t_j\)) is the list of distinct values in \(T_i\) .
In the next section, we will detail the steps of our Web service social recommendation mechanism which is based on the expertise concept.
5 Expertise– Based Social Recommendation Mechanism
Our social recommendation mechanism (SRM) enables to the user, on the basis of his query, to recommend a ranked list of the best services based on the trusted network which was generated in the previous step. We will present, in this section, the steps of our recommendation mechanism which is the enhancement of our previous discovery process [11]. This mechanism is performed in six steps as follows.
-
1.
Trustworthy friends extraction. We consider the trustworthy friend who are all the users connected to the user ego via a particular type of relation, such as the trust. This relation is detected by the previous mechanism (STDM). The list of extracted friends constitutes the main input of our SRM.
-
2.
Level of expertise computing. We consider that the friends who have frequently used the Web services in a specific domain are able to provide a recommendation with better quality. For this objective, we proposed a measure to compute the level of expertise LoE for each trusted friend \(U_i\), who is extracted in the previous step, in a particular domain \(dom_j\) of the user’s query. This level is calculated after each user’s interaction with a recommended Web service in the past according to the next Eq. 7. The obtained values recorded in the Expertise matrix (\(U \times C \times I\)).
$$\begin{aligned} LoE({u_i},{dom_j})=\frac{Nb_{invok}({u_i}, {dom_j})}{\sum _{{dom_k} \in C } Nb_{invok}({u_i}, {dom_k})} \end{aligned}$$(7)where \(Nb_{invok}({u_i}, {dom_j})\) is the number of service invocation in the domain \({dom_j}\) of the current user’s query, and \(\sum _{{dom_k} \in C} Nb_{invok}({u_i}, {dom_k})\) is the sum of the service invocation number in the list of domains C in our system.
-
3.
Past experience extraction. We extract for each expert and trustworthy friend form his SOAF profile the information related to his Web services (e.g. name, description, operation, endpoint) which was invoked or published in the past. This extraction is performed by using the SPARQLFootnote 1 query. The result of this step is a list of Web services without redundancy.
-
4.
Web service filtering based on user query. An active user formulates his needs in terms of Web services by selecting the domain (dom) of his query (e.g. travel, medical, food, education) and expressing a set of keywords (I). In this step, SRM filters according to the user’s query the list of Web services which are extracted from the previous step. The purpose is to select only those that correspond the user’s query.
-
5.
Rating prediction. SRM predicts the score for each selected Web service in the previous step according to Eq. 8. This prediction is based, on the one hand, on the expertise of trusted friends who have invoked these Web services, and, on the other hand, on their attributed ratings to them which is recorded in the Rating matrix (\(U \times S\)). Finally, the SRM selects only the best Web services that have a predicted scores above a threshold.
$$\begin{aligned} Rating_{pred}({ws_i}, {dom_k})=\frac{\sum _{{u_j} \in R} LoE({u_j}, {dom_k}) \times Rating({u_j}, {ws_i})}{\sum _{{u_j} \in R} LoE({u_j}, {dom_k})} \end{aligned}$$(8)where \(LoE({u_j}, {dom_k})\) is expertise level of the user \({u_j}\) which is calculated in Eq. 7 , and \(Rating({u_j}, {ws_i})\) is the service’s score attributed by the user \({u_j}\) to the service \({ws_i}\) .
-
6.
Web service ranking. in this last step, SRM ranks the list of Web services will be recommended by descending order. This ranking is based on the predicted rating of each Web service which is calculated according to the Eq. 8.
In the next section, we will present an example that clarify more our motivation.
6 Illustrative Example
To better illustrate our service discovery proposition, let us consider a case study on a medical scenario. Suppose that Bob, a service requester, connected in his Facebook social network and he wants to look for a Web services related to his query Q. Q is defined by a domain \(dom= medical\) and a list of Keywords nameDoctor, meetingpoint. By exploring his ESN, Bob has five friends which are represented in the weighted sub-graph of his network as shown in Fig. 2–(a). The weights indicate the LoT which is deduced by our STDM (See Eq. 5) and recorded in the Trust matrix (See Fig. 1). Based on our STDM, the dynamic trust threshold \(\gamma = (0.35+0.65+0.83+0.4)/4= 0.545\) (See Eq. 6). Indeed, SRM filters in the first step the social relationships of Bob according to the LoT measure and the dynamic threshold \(\gamma \). It selects only the friends \(F_2\) and \(F_4\) as trusted friends of Bob (See Fig. 2–(b)).

(a)–Oriented and Weighted Sub-Graph from egocentric Social Network, (b)–Trusted Sub-Graph and (c)–Expertise and Trusted Sub-Graph
In the second step, SRM select only from the list trusted friends only who is an expert in the same domain of the Bob’s query according to the Eq. 7 in order to provide a better recommendation quality. According to the Expertise matrix, suppose that the expertise in the different domains of \(F_2\) = {medical = 0.6, food = 0.37} and \(F_4\) = {medical = 0.45, travel = 0.7, food = 0.56}. Based on these values, \(F_2\) tends to use the Web services related to the medical domain (e.g. FindDoctorService, ClinicInformationService, MeetingService, etc.) and the food domain (e.g. FindRestaurantService, getReceipeService, etc.). Moreover, \(F_4\) frequently used the services related to the medical domain (e.g. FindDoctorService, ClinicInformationService, FindCommunityService, etc.), the travel domain (e.g. WSCountryHotel, WSCityHotel, etc.) and the food domain (e.g. FindRestaurantService, BookPizzaService, etc.). Hence, \(F_2\) is more expert in medical domain than \(F_4\). Consequently, SRM selects \(F_2\) as the most trusted and expert friend of Bob. In the next step, SRM extracts from the SOAF profile of \(F_2\) the information (e.g. name, operation, endpoint) of his medical Web services and selects only those correspond to the Bob’s query Q. SRM predicts the score for each selected Web services (FindDoctorService and MeetingService) according to the expertise of \(F_2\) and their assigned ratings which is extracted from the Rating matrix (e.g. Rating\((FindDoctorService)=0.5\) and Rating\((MeetingService=0.7)\). Finally, SRM recommends those services with predicted rating (See Eq. 8) in descending order. In the next section, we will detail the experiments and the obtained results for each mechanism.
7 Experimentation and Discussion
Our Web service decentralized discovery process is performed in two mechanisms:(i) the Social Trust Detection Mechanism (STDM) and (ii) the Expertise– based Social Recommendation Mechanism (SRM). In the fist section, we evaluate the first mechanism by evaluating the Level of Trust (LoT) measure that we proposed. In the second section, we focus on the second mechanism by evaluating the recommendation quality in terms of rating prediction.
7.1 First evaluation: STDM
Through the evaluation step, we propose to validate the following points: the importance of considering the time factor in the trust measure and the use of dynamic trust threshold rather than the static threshold. Furthermore, we choose the Facebook, a real-world social network, as an example just in order to evaluate our proposed trust metric. In addition, we have the opportunity to collect the social profile for each user. The Facebook social network contains 1326 nodes of users. We selected a sample of 20 users from this data where each user is represented by his RDF profiles. At the first level, we invited each user to connect into our SC-WSD system to select and save his Real trusted friends. At the second level, we conducted a comparison by using three popular metrics, such as the recall, the precision and the F-measure. The recall corresponds to the number of trustworthy friends who are returned by the system compared to the total number of real trustworthy friends who are identified by each user as shown in Eq. 9.
The precision is the number of real trustworthy friends who are returned by the system compared to the total number of returned friends as shown in Eq. 10.
The F-measure is a combination of the two previous metrics as shown in Eq. 11.
Impact of parameters \(\alpha \) and \(\beta \) . Our proposed level of social trust (LoT) is based on the time-aware interaction degree (DoI) and the interest similarity degree (DoS) between the users (See Eq. 5). In Fig. 3 (a), we found that the best value of F-measure is the one with parameters: \(\alpha =0,8\) and \(\beta =0,2\). In addition, it seems that if parameter \(\alpha \) is closer to 0 and parameter \(\beta \) is closer to 1, the level of social trust decrease over time. Consequently, the temporal factor of the users’ interactions has an important influence on social trust.

(a)–Obtained results of F-measure with variation of \(\alpha \) and \(\beta \) parameters, and (b)–Obtained results of F-measure with variation of static threshold (\(\lambda =0,5, 0,6\) and 0,7) compared to the dynamic threshold \(\gamma \)
Effect of Dynamic Trust Threshold \(\gamma \) . We suggest that the accuracy of the returned results depends highly on the chosen threshold. In our STDM, we used three static thresholds (\(\lambda =0,5, 0,6\) and 0,7) and the proposed dynamic threshold \(\gamma \) to filter the user’s friends. In Fig. 3 (b), we observe that every time we increase \(\lambda \) (=0.6 or 0.7), the chance of selection of trusted friends (i.e. number of friends) is reduced. Otherwise, if we decrease \(\lambda \) (=0.5), some friends will be chosen and recommended to the ego user. According to these results, we observe that, for the majority of the users, the selection of trusted friends by \(\gamma \) is much better than by \(\lambda \). In addition, we note that static threshold has better results for some users and less for others. Thus, we proved with this assessment the interest of using a dynamic threshold in order to select the trusted friends from a large number of users in the social network.
Comparison with other Trust metrics. We compared the obtained results of our level of social trust metric with two other metrics. The first, which is called Temporal Trust [17], is proposed to rank the user’ friends according to the age of their relationship by considering the newest friends as the most trustworthy. The second measure, which is called Closest Friends [19], is based on social interactions between friends without considering the time factor. In general, the results obtained in terms of precision and recall show better results by taking into account the temporal factor on the users’ interactions and the interest similarity. In Fig. 4 (c), we found that the precision of the obtained results by the Closest Friend metric is very low (precision average = 25,85 %) than our LoT metric (=76,94 %) and Temporal Trust metric (=62,72 %). This justifies our hypothesis that the non-consideration of the time factor may recommend to the user ego the friends who are considered trusted in the past and they are no longer. In addition, our metric gives better precision values than those obtained by the Temporal Trust with a difference of 14,22 % of the average precision. This first justifies that our measure detects and recommends for each user the real trusted friends who are identified by each user, and second, the time aware of the social interaction degree has a very strong impact than the age of relation (newest or oldest) which is taken into account in Temporal Trust metric. In Fig. 4 (d), we found that the recall average of the obtained results by our metric is much better (=66,17 %) than the Closest Friend (=50.71 %) and Temporal Trust (=48.58 %). This justifies that our metric detects and recommends the trusted friends from the real trusted friends who are identified by each user. In the next section, we will evaluate the accuracy of our recommendation mechanism of web services.

Comparison of obtained results of our LoT metric with two metrics: temporal trust and closest friends in terms of recall (c) and precision (d)
7.2 Second Evaluation: Expertise–Based SRM
In this section, we aim to validate the recommendation accuracy by evaluating the metric of rating prediction according to the user’s expertise (See Eq. 8). The majority of research works like [5] which interested to Web service recommendation have used the EpinionsFootnote 2 dataset from which they have considered each item corresponds a Web service. In general, the Epinions dataset includes (i) a trust matrix which contains the trust values that are explicitly provided by the users, (ii) a rating matrix which is attributed to different products and (iii) a category matrix which contains the category of each item. In our context, we can not use this dataset to evaluate our STDM since it has no personal or social information provided for each user. However, we choose the trust values which are provided by Epinions and apply our SRM. We have used the popular metric to measure the error rate such as RMSE (Root Mean Squared Error). It calculates the difference between the predicted rate and the real rate as indicated by the following formula 12.
with \(R_{u,i}\) is a Boolean variable equal to 1 if the user u evaluates the item i,
\(r_{u,i}\) the real rate which is attributed by the user u to an item i and
\(\widehat{r}_{u,i}\) the predicted rate
Rating prediction based on the user’s expertise Versus without expertise. We compared the prediction measure taht we used in our SC-WSD system with other RS like TidalTrust [8], MoleTrust [16] and TrustWalker [10]. The obtained results (See Table 1) showed that the gap between the real rate and the predicted rate in our proposed system is lower than in others. This result is explained by the importance of the consideration of the expertise which improves the recommendation quality.
8 Related Work
Web service recommendation approach has become a research directive for enhancing Web service discovery and help the users out of the service overload [22]. With the advent of social media, some SR approach [7, 15, 24], which are based on users’ SNs, emerged to reduce the problems of FC approach such as the cold-start and data sparsity [22]. Moreover, with a prevalence of users’ social networks, a great number of data were generated. Thus, the social trust [9] has been studied in different levels such as between (i) the web services (or applications) [7], (ii) the providers (e.g. Web sites, organizations, governments) [2, 12], (iii) service consumers (e.g. organizations or individuals) [5, 6, 24], or (iv) recently between the Social Internet of Things [1]. [2] proposed a RS of composed Web services. This recommendation is based partly on the trust of service providers; and secondly, on the non-functional characteristics (e.g. response time, cost) of services. Trust between providers is global and implicit and measured on the basis of their position in the SN. To classify Web services, Bansal et al. suggested representing each Web service by its QoS which is calculated with the trust value of the service provider. [12] proposed a RS of Web services based on trust of the provider in a SN. The trust value is considered as local and transitive. It is implicitly calculated based on two measures, such as, the sociability of provider (i.e. position, social proximity and similarity). The second measure is the expertise of an agent (i.e. reliability, usability and quality score). The authors did not offer a specific formula to predict the service’s rating, but, they proposed to classify these services according to the trust level of their providers. [5] proposed a RelevantTrustWalker RS in which the trust measure is local and non-transitive. This measure combines two values, the first value is an explicit trust provided by the user to another, the second value is the similarity between the users which is calculated by applying the cosine measure on the rating vectors which are assigned by two users. The rating prediction for web service is realized randomly by browsing the network in search for a trustworthy user who evaluated a service.
To summarize, the majority of the previous mentioned studies have used only the rating in the prediction step. Thus, in our real life, some users prefer the advice not only of their trusted friends but also of their expertise. In literature, some expertise -based recommendation [26] proposed to recommend a list of experts which combines the SNA and semantic concept to improve the effectiveness of personalized recommendation in the document retrieval context. In service computing, some RS have introduced the idea of expertise to make their service recommendation more accurate. For example, [27] proposed to quantify the user’s expertise in terms of how many times the user has used the required web service. [15] computed the user’s expertise in in particular area in the purpose of composition. [12] compute the trust in the expertise of providers in terms of QoS (e.g. usability, reliability). In fact, our work is different of other works in two levels. The first contribution is related to the temporal based- computing social trust that we have given an importance of the temporal factor to calculate the trust between users. The second contribution is related to the expertise based- SR from which the majority of research studies dont exploited the context of the user query and the expertise of trusted friends in the recommendation purpose.
9 Conclusion and Future Work
In this paper, we considered the social trust relation in the objective of Web service recommendation in order to enhance Web service discovery. We have proposed a new measure to compute the trust level between two users by taking into account semantic social information which are extracted from the egocentric network for a given user. Our proposed social trust is a local score which is computed from values of two measures: Time-aware interaction degree and Social interest similarity degree. According to the social trust level computation, the outcome of trust detection mechanism is a weighted directed graph of the user’s egocentric network. With this relation, we were able to select trusted user’s friends. The empirical results show that our proposed metric produces satisfactory results. In fact, the consideration of time has a positive influence on the detection of trusted friends. In addition, the use of a dynamic threshold to discriminate between the users’ friends produces more results than the what of a static threshold. At the second level, we have integrate a social recommendation mechanism in our previous works. This mechanism exploits not only the social trust metric but also the expertise level of the trusted users’ friends in the domain of the user’s query. Our idea is to recommend to a given user a ranked web services which were used in the past by his experts and trusted friends. In our future work, we will be interested in reducing the cold start problem.
References
Abdelghani, W., Zayani, C.A., Amous, I., Sèdes, F.: Trust management in social internet of things: a survey. In: The 15th IFIP Conference on e-Business, e-Services and e-Society (I3E) (2016, To appear)
Bansal, S.K., Bansal, A.: Reputation-based web service selection for composition. In: World Congress on Services, SERVICES 2011, Washington, DC, USA, 4–9 July 2011, pp. 95–96 (2011)
Jsang, A., Ismail, R.: The beta reputation system. In: Proceedings of the 15th Bled Electronic Commerce Conference (2002)
D’Andrea, A., Ferri, F., Grifoni, P.: An overview of methods for virtual social networks analysis. In: Abraham, A., Hassanien, A.E., Sná, V. (eds.) Computational Social Network Analysis: Trends, Tools and Research Advances, pp. 3–25. Springer, London (2010)
Deng, S., Huang, L., Xu, G.: Social network-based service recommendation with trust enhancement. Expert Syst. Appl. 41(18), 8075–8084 (2014)
Deng, S., Huang, L., Yinand, Y., Tang, W.: Trust-based service recommendation in social network. Appl. Math. Inf. Sci. 9(3), 1567–1574 (2015)
Fallatah, H., Bentahar, J., Asl, E.K.: Social network-based framework for web services discovery. In: 2014 International Conference on Future Internet of Things and Cloud, FiCloud 2014, Barcelona, Spain, 27–29 August 2014, pp. 159–166 (2014)
Golbeck, J.: Trust on the world wide web: a survey. Found. Trends Web Sci. 1(2), 131–197 (2006)
Golbeck, J. (ed.): Computing with Social Trust. Human-Computer Interaction Series. Springer, Berlin (2009)
Jamali, M., Ester, M.: Trustwalker: a random walk model for combining trust-based and item-based recommendation. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009, pp. 397–406 (2009)
Kalai, A., Zayani, C.A., Amous, I.: User’s social profile -based web services discovery. In: 8th IEEE International Conference on Service-Oriented Computing and Applications, SOCA, Rome, Italy, 19–21 October 2015, pp. 2–9 (2015)
Louati, A., Haddad, J.E., Pinson, S.: A distributed decision making and propagation approach for trust-based service discovery in social networks. In: Group Decision and Negotiation. A Process-Oriented View - Joint INFORMS-GDN and EWG-DSS International Conference, GDN 2014, Toulouse, France, 10–13 June 2014, pp. 262–269 (2014)
Ma, H., Zhou, D., Liu, C., Lyu, M.R., King, I.: Recommender systems with social regularization. In: Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, WSDM’11, pp. 287–296 (2011)
Maamar, Z., Wives, L.K., Badr, Y., Elnaffar, S., Boukadi, K., Faci, N.: Linkedws: a novel web services discovery model based on the metaphor of “social networks”. Simul. Model. Pract. Theory 19(1), 121–132 (2011)
Maaradji, A., Hacid, H., Skraba, R., Lateef, A., Daigremont, J., Crespi, N.: Social-based web services discovery and composition for step-by-step mashup completion. In: IEEE International Conference on Web Services, ICWS 2011, Washington, DC, USA, 4–9 July 2011, pp. 700–701 (2011)
Massa, P., Avesani, P.: Trust-aware recommender systems. In: Proceedings of the 2007 ACM Conference on Recommender Systems, RecSys 2007, Minneapolis, MN, USA, 19–20 October 2007, pp. 17–24 (2007)
Moghaddam, M.G., Elahian, A.: A novel temporal trust-based recommender system. In: 2014 22nd Iranian Conference on Electrical Engineering (ICEE), pp. 1142–1146, May 2014
Nepal, S., Sherchan, W., Paris, C.: Strust: a trust model for social networks. In: IEEE 10th International Conference on Trust, Security and Privacy in Computing and Communications, TrustCom 2011, Changsha, China, 16–18 November 2011, pp. 841–846 (2011)
Podobnik, V., Striga, D., Jandras, A., Lovrek, I.: How to calculate trust between social network users? In: 20th International Conference on Software, Telecommunications and Computer Networks, SoftCOM 2012, Split, Croatia, 11–13 September 2012, pp. 1–6 (2012)
Resnick, P., Varian, H.R.: Recommender systems - introduction to the special section. Commun. ACM 40(3), 56–58 (1997)
Sherchan, W., Nepal, S., Paris, C.: A survey of trust in social networks. ACM Comput. Surv. 45(4), 47 (2013)
Su, X., Khoshgoftaar, T.M.: A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 421425:1–421425:19 (2009)
Tang, J., Hu, X., Liu, H.: Social recommendation: a review. Soc. Netw. Anal. Min. 3(4), 1113–1133 (2013)
Tang, M., Xu, Y., Liu, J., Zheng, Z., Liu, X.F.: Trust-aware service recommendation via exploiting social networks. In: 2013 IEEE International Conference on Services Computing, Santa Clara, CA, USA, 28 June–3 July 2013, pp. 376–383 (2013)
Treiber, M., Truong, H.L., Dustdar, S.: SOAF - design and implementation of a service-enriched social network. In: 9th International Conference on Web Engineering, ICWE 2009, San Sebastián, pp. 379–393 (2009)
Xu, Y., Guo, X., Hao, J., Ma, J., Lau, R.Y.K., Xu, W.: Combining social network and semantic concept analysis for personalized academic researcher recommendation. Decis. Support Syst. 54(1), 564–573 (2012)
Yuan, Z., Shuai, Z., Yan, W., Yanhong, C., Wenyu, Z., Xin, C.: A social network-based expertise-enhanced collaborative filtering method for e-government service recommendation. Adv. Inf. Sci. Serv. Sci. 5(10), 724–735 (2013)
Zeng, J., Gao, M., Wen, J., Hirokawa, S.: A hybrid trust degree model in social network for recommender system. In: 2014 IIAI 3rd International Conference on Advanced Applied Informatics (IIAIAAI), pp. 37–41, August 2014
Zhou, X., Xu, Y., Li, Y., Jøsang, A., Cox, C.: The state-of-the-art in personalized recommender systems for social networking. Artif. Intell. Rev. 37(2), 119–132 (2012)
Ziegler, C., Golbeck, J.: Investigating interactions of trust and interest similarity. Decis. Support Syst. 43(2), 460–475 (2007)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Kalaï, A., Zayani, C.A., Amous, I., Sedès, F. (2016). Expertise and Trust –Aware Social Web Service Recommendation. In: Sheng, Q., Stroulia, E., Tata, S., Bhiri, S. (eds) Service-Oriented Computing. ICSOC 2016. Lecture Notes in Computer Science(), vol 9936. Springer, Cham. https://doi.org/10.1007/978-3-319-46295-0_32
Download citation
DOI: https://doi.org/10.1007/978-3-319-46295-0_32
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-46294-3
Online ISBN: 978-3-319-46295-0
eBook Packages: Computer ScienceComputer Science (R0)