
Abstract
This paper proposed a novel data reduction and classification method to analyze high-dimensional and complicated flight data. This method integrated diffusion maps and kernel fuzzy c-means algorithm (KFCM) to recognize two types of simulator modes at different tasks. To optimize the unknown parameters of the KFCM, a hybrid bacterial foraging oriented (BFO) and particle swarm optimization (PSO) algorithm was also presented in this paper. This algorithm increased the possibility of finding the optimal values within a short computational time and avoided to be trapped in the local minima. By using the proposed approach, this paper obtained meaningful clusters respecting the intrinsic geometry of the standard data set, and illustrated the phenomenon that the pilots vestibular influenced pilot performance and control system under the Manual departure task.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
- Flight simulator
- Vestibular
- Diffusion maps
- Bacterial foraging oriented
- Particle swarm optimization
- Kernel fuzzy c-means algorithm
1 Introduction
Recent papers showed that pilots utilized many different cues to control aircraft. Central visual and peripheral visual can help pilots to get flight instruments and position information. Vestibular and cockpit motion also have influences on sensory perception [1]. In some investigations, multi-channel models, shown in Fig. 1, were developed to describe various sensory channels’ affection on pilot control behavior in distinguished conditions.

Block diagram representing the pilot-vehicle-system under manual control
However, the multi-channel models are not unchangeable all the time. Human sensory system should be studied to make sure which sensing path affects human’s behavior under certain circumstance. Whether the pilot performance is different is essential for human sensory model research. This paper aimed to find a reliable method to recognize whether the performance is different when the sensing path has changed. In the experiment, same tasks were carried out at two simulator modes (static and dynamic). Because the flight data was hard to be distinguished by using traditional cluster methods. Our goal was to classify these complicated data precisely and quickly.
2 Feature Extraction and Classifier
2.1 Wavelet Based Feature Extraction
To classify pilot performances of controlling the flight simulator efficiently, features should be extracted from both time-domain and frequency-domain. Wavelets are versatile harmonic analysis tools which combine time and frequency representations into localized waveforms. Given a segment of experimental data, the wavelet transform convolves a selected series of local waveforms with the data to identify correlated features. The resulting set of wavelet coefficients can be interpreted as multidimensional correlation coefficients. Features of shape, size, and location are naturally characterized by these waveforms and related coefficients [2]. As a result, besides common features such as mean value and standard deviation, we extract features using wavelet transform.
2.2 Classifier Based on Hybrid Diffusion Maps and Kernel FCM
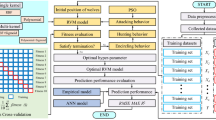
The construction of the proposed classify method based on diffusion maps and KFCM is shown as Fig. 2. First, using diffusion maps, the complicated and high dimensional set turned into an arbitrary set. This obtained arbitrary set represents the distribution of the original data and its inner connection. On the basis of diffusion maps, kernel FCM is used to classify the patterns, which cluster centroid is optimized by the new technique BFO-PSO. After the optimal cluster block the minimum object function are calculated. The final result is the cluster when the object function is minimal.

The process of the hybrid cluster algorithm
Diffusion Distances. The ambition of diffusion distance is to define a distance metric on an arbitrary set that reflects the connectivity of the points within the set. Points within regions of high density (defined as groups of nodes with a high degree in the graph), will have a high connectivity. The connectivity is furthermore decided by the strengths of the weights in the graph. The diffusion framework was put into the context of eigenmaps, dimensionality reduction, and Markov random walk learning on graphs and it first appeared in [3].
Let \(G = (\Omega , W)\) be a finite graph with \(n\) nodes, where the matrix \(W = {\{ w(x,y)\} _{x,y \in \Omega }}\) satisfies the following conditions:
symmetry: \(W = {W^T}\)
and points positivity: \(w(x,y) \ge 0\) for all \(x,y \in \Omega \)
\(w(x,y)\) should represent the degree of similarity or affinity of \(x\) and \(y\).
The graph \(G\) with weights \(W\) represents our knowledge of the local geometry of the set.
We are mainly concerned with the following idea: For a fixed but finite value \(t > 0\), we want to define a metric between points of \(\Omega \) which is such that two points \(x\) and \(z\) will be close if the corresponding conditional distributions \({p_t}(x,.)\) and \({p_t}(z,.)\) are close. A similar idea appears in [4], where we consider the \({L^1}\) norm \(\left\| {{p_t}(x,.) - {p_t}(z,.)} \right\| \). However, as shown below, the \({L^2}\) metric between the conditional distributions has the advantage that it allows one to relate distances to the spectral properties of the random walk and thereby connect Markov random walk learning on graphs with data parameterization via eigenmaps. As in [5], we will define the “diffusion distance” \({D_t}\) between \(x\) and \(y\) as the weighted \({L^2}\) distance
where the “weights” \(\frac{1}{{{\phi _0}(x)}}\) penalize discrepancies on domains of low density more than those of high density.
This notion of proximity of points in the graph reflects the intrinsic geometry of the set in terms of connectivity of the data points in a diffusion process. The diffusion distance between two points will be small if they are connected by many paths in the graph.
Kernel FCM. As an enhancement of classical FCM, the KFCM maps the data set \(X\) from the feature space or the data space \(\Xi \subseteq {R^p}\) into a much higher dimensional space \(H\) (a Hilbert space usually called kernel space) by a transform function \(\varphi :\Xi \rightarrow H\). In the new kernel space, the data demonstrate simpler structures or patterns. According to clustering algorithms, the data in the new space show clusters that are more spherical and therefore can be clustered more easily by FCM algorithms [6–8].
3 The Parameters Optimization of the Proposed Classifier
In clustering algorithm, the grouping is identified by randomly placing the cluster centroids and grouping of records with minimum distance. The algorithm faces several challenges in effectiveness and efficiency. Similarly, KFCM algorithm is also modified including spatial information and kernel [9]. Then, optimization algorithms are introduced for clustering parameters setting. Based on the similar kind of procedure, genetic algorithm (GA) [10], Particle Swarm optimization (PSO) [11], bacterial foraging optimization (BFO) [12] and simulated annealing [13] are applied for clustering.
PSO is a stochastic search technique and BFO is a new type of bionic optimization algorithm. In this paper, the random variable of BFO is replaced by the particle swarm algorithm. By this way, the bacteria with poor position could soon gather in a good region, and the bacteria with good position search in the neighborhood region. It also aims to avoid from being trapped in local minima as PSO.
3.1 Bacterial Foraging Optimization
BFO is an evolutionary optimization technique, introduced by Passino, based essentially on the social foraging behavior of Escherichia Coli (E. Coli) bacteria present in human intestine. The selection behavior of bacteria improves successful foraging strategies and suppresses those with poor foraging. A foraging animal seeks to maximize the energy obtained per unit time spent foraging. E. Coli bacteria has a chemotactic action behavior that enables it to search for food and avoid noxious substances. In bacterial foraging process, E. Coli bacteria undergo four stages: chemotaxis, swarming, reproduction, elimination and dispersal.
3.2 Particle Swarm Optimization
PSO is a stochastic computation technique developed by Eberhart and Kennedy, inspired by the social behavior of fish schooling or bird flocking, more exactly, the collective behaviors of simple individuals that interact each other on one hand and with their environment on the other hand. PSO is a population-based optimization technique, in which the system is initialized with a population of random candidate solutions called particles and searches for the best solution by updating generations. Each particle has a position represented by a vector \(X_k^i\) ( \(i\) is the index of the particle) and velocity \(V_k^i\) that directs its flying in the multidimensional search space. Every particle remembers its own best position \(P_{LBest}^i\) corresponding to its lowest fitness value evaluated by the fitness function to be optimized. The best position with the lowest fitness cost among all the particles in the swarm is set to \(P_{GBest}^i\). Particles update their velocities and positions in order to track the optimal particle until a convergence criterion is achieved or a maximum of iterations are attained using the following equations:
where \({R_1}\) and \({R_2}\) are random numbers in interval. A particle decides where to move next, considering its own experience, which is the memory of its best past position, and the experience of the most successful particle in the swarm. Acceleration coefficients, \({C_1}\) influences the cognitive behavior, which means how much the particle will follow its own best position while \({C_2}\) represents the social behavior, which means how much the particle will follow the best position of the swarm. \(w\) is the inertia weight factor.
3.3 The Proposed BFO-PSO Algorithm
In 2008, W. Korani proposed an improved BFO, namely BF-PSO. The BF-PSO combines both algorithms BFO and PSO. The aim is to make use of PSO ability to exchange social information and BF ability in finding a new solution by elimination and dispersal. In BFO, a unit length direction of tumble behavior is randomly generated. The random direction may lead to delay in reaching the global solution. For BF-PSO the global best position and the best position of each bacterium will decide the direction. During the chemotaxis loop, the update of the tumble direction is determined by:
where \(P_{LBest}\) is the best position of each bacteria and \(P_{GBest}\) is the global best bacterial.
4 Experiment
The proposed method was implemented in MATLAB R2014a and executed on a core i3 processor, 3.20 GHz, 2 GB RAM computer.

(a) The original data set; (b) The cluster using FCM

(a) The cluster using GA+DM; (b) The cluster using PSO+DM; (c) The cluster using BFO+PSO+DM
4.1 Classical Data Set
To test the validity of this method, a standard data set, shown in Fig. 3a, was used. The data set which consisted of 2000 spots, distributing in two concentric circles separable in a 2-D feature space. It’s hard to classify this data set with traditional methods because there were many noisy points between two classes. For instance, when we run the FCM algorithm directly, the result did not reflect the natural geometry of the data distribution. As shown in Fig. 3b, the data set was cut to two pieces briefly without showing any geometry in formation of the former graph.
As a comparison, the set was classified into two concentric circle by using diffusion maps, shown in Fig. 4. Some meaningful clusters respecting the intrinsic geometry of the data set were obtained. Genetic algorithm (GA) and PSO algorithm were used to test the better performance of hybrid BF-PSO algorithm. Compared to diffusion maps optimized by GA (Fig. 4a) or PSO (Fig. 4b) only, diffusion maps combined with BFO-PSO algorithm (Fig. 4c) obtained smaller object function representing better classify quality. Each algorithm process run 5 times to classify the standard data set, and results of object function were shown in Table 1. The new algorithm not only calculated well and had a good ability to deal with local extreme and global search capability, but also there were no any requests for the initial cluster centers and the entering order.
4.2 Flight Data Set
To get reliable flight data we did the experiment in flight simulator. There were 5 crews of experienced pilots executed 2 different missions which were Manual departure and Standard instrument departure (SID). Each mission was carried out at two simulator modes, static and dynamic modes.
7 essential flight parameters, such as airspeed, pressure altitude, pitch angle, roll angle, rate of climb, vertical speed and angle of attack were chosen to calculate and study. The sample time of flight data was set to 30 Hz because of the limitation of simulator.
In our work, we extracted 5 features of each flight parameter: mean value, standard deviation, wavelet entropy, wavelet energy entropy and wavelet high/low frequency energy ratio.
Then use the proposed hybrid algorithm to classify features of flight data. Set parameters of the algorithm as follows: clustering categories as 2; diffusion dimension as 5; \({S_b} = 10\), \(P = 10\), \({N_c} = 3\), \({N_s} = 4\),\({N_re} = 2\),\({N_ed} = 2\),\({P_ed} = 0.25\), \({C_1} = {C_2} = 2\); \(r = 150\).
The clustering results were shown in Fig. 5:

(a) The cluster result at Manual departure task; (b) The cluster result at standard instrument departure task
The proposed method was carried out 5 times using flight data, and the results were shown in Table 2. Manual departure was better than standard instrument departure by comparing their correct rates of clustering.
Two different simulator modes were easier to classify at the Manual departure task. The misclassification reached to about 37.63 % lowest, while the other one was only 45.45 %. This difference reflects the influence of the simulator movement, because the sensing path of pilot changed when vestibular system transmitted information for higher brain function showing in Fig. 1.
It illustrated that the performance at Manual departure was influenced by pilot’s movement sensation. Compared to that at standard instrument departure which based on auto departure procedures, simulator movement has little impression on pilot sensory system.
5 Conclusion
This paper proposed a new hybrid algorithm to reduce high feature-dimension and recognize nonlinear flight data from different simulator modes. Hybrid diffusion maps and KFMC method could classify complicated data set and reflect the connectivity of the points within it. The proposed method was used to cluster the standard data set. The results indicated that the proposed method was robust to noise and had better performance compared to traditional ones. Then the flight data which was obtained from simulator was classified by this method. The cluster stated that the control performance of pilots was more sensible to the simulator movement at Manual departure task. It proved that the method was valuable to analysis whether the pilot performances had relationship with certain human sensing path.
References
Allerton, D.: Principles of Flight Simulation. Wiley, UK (2009)
Torrence, C., Compo, G.P.: A practical guide to wavelet analysis. Bull. Am. Meteorol. Soc. 79(1), 61–78 (1998)
Coifman, R.R., Lafon, S., Lee, A.B., Maggioni, M., Nadler, B., Warner, F., Zucker, S.W.: Geometric diffusions as a tool for harmonic analysis and structure definition of data: diffusion maps. Proc. Nat. Acad. Sci. U.S.A. 102(21), 7426–7431 (2005)
Jaakkola, M.S.T., Szummer, M.: Partially labeled classification with markov random walks. Adv. Neural Inform. Proc. Syst. (NIPS) 14, 945–952 (2002)
Nadler, B., Lafon, S., Coifman, R.R., Kevrekidis, I.G.: Diffusion maps, spectral clustering and reaction coordinates of dynamical systems. Appl. Comput. Harmonic Anal. 21(1), 113–127 (2006)
Kim, D.-W., Lee, K.Y., Lee, D., Lee, K.H.: Evaluation of the performance of clustering algorithms in kernel-induced feature space. Pattern Recogn. 38(4), 607–611 (2005)
Graves, D., Pedrycz, W.: Performance of kernel-based fuzzy clustering. Electron. Lett. 43(25), 1445–1446 (2007)
Graves, D., Pedrycz, W.: Kernel-based fuzzy clustering and fuzzy clustering: a comparative experimental study. Fuzzy Sets Syst. 161(4), 522–543 (2010)
Zhang, D.-Q., Chen, S.-C.: A novel kernelized fuzzy c-means algorithm with application in medical image segmentation. Artif. Intell. Med. 32(1), 37–50 (2004)
Maulik, U., Bandyopadhyay, S.: Genetic algorithm-based clustering technique. Pattern Recogn. 33(9), 1455–1465 (2000)
Premalatha, K., Natarajan, A.: A new approach for data clustering based on pso with local search. Comput. Inform. Sci. 1(4), p. 139 (2008)
Wan, M., Li, L., Xiao, J., Wang, C., Yang, Y.: Data clustering using bacterial foraging optimization. J. Intell. Inf. Syst. 38(2), 321–341 (2012)
Selim, S.Z., Alsultan, K.: A simulated annealing algorithm for the clustering problem. Pattern Recognit. 24(10), 1003–1008 (1991)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Bo, J., Zhang, YB., Ding, L., Yu, BT., Wu, Q., Fu, S. (2015). Hybrid BFO-PSO and Kernel FCM for the Recognition of Pilot Performance Influenced by Simulator Movement Using Diffusion Maps. In: Duffy, V. (eds) Digital Human Modeling. Applications in Health, Safety, Ergonomics and Risk Management: Ergonomics and Health. DHM 2015. Lecture Notes in Computer Science(), vol 9185. Springer, Cham. https://doi.org/10.1007/978-3-319-21070-4_24
Download citation
DOI: https://doi.org/10.1007/978-3-319-21070-4_24
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-21069-8
Online ISBN: 978-3-319-21070-4
eBook Packages: Computer ScienceComputer Science (R0)