
Abstract
The rapid growth of the scientific literature makes text classification essential specially in the biomedical research domain to help researchers to focus on the latest findings in a fast and efficient way.
The potential benefits of using text semantic enrichment to enhance the biomedical document classification is presented in this study. We show the importance of enriching the corpora with semantic information to improve the full-text classification.
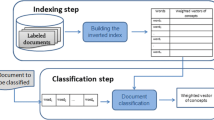
The approach involves the semantic enrichment of a Medline corpus with a Semantic Repository (SemRep) which extracts semantic predications from biomedical text. The study also addresses the problem of treating highly dimensional data while maintaining the semantic structure of the corpus.
Experimental results lead to the sustained conclusion that better results are achieved with full-text instead of using only abstracts and titles. We also conclude that the application of enriched techniques to full-texts significantly improves the task of text classification providing a significant contribution for the biomedical text mining research.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Rindflesch, T.C., Fiszman, M.: The interaction of domain knowledge and linguistic structure in natural language processing: interpreting hypernymic propositions in biomedical text. J. Biomed. Inform. 36(6), 462–477 (2003)
Rindflesch, T.C., Fiszman, M., Libbus, B.: Semantic interpretation for the biomedical research literature. In: Chen, H., Fuller, S.S., Friedman, C., Hersh, W. (eds.) Medical Informatics Integrated Series in Information Systems. ISIS, vol. 8, pp. 399–422. Springer, Boston (2005). https://doi.org/10.1007/0-387-25739-X_14
Hersh, W., Buckley, C., Leone, T.J., Hickam, D.: OHSUMED: an interactive retrieval evaluation and new large test collection for research. In: Croft, B.W., van Rijsbergen, C.J. (eds.) SIGIR 1994, pp. 192–201. Springer, London (1994). https://doi.org/10.1007/978-1-4471-2099-5_20
Škrlj, B., Kralj, J., Lavrač, N., Pollak, S.: Towards robust text classification with semantics-aware recurrent neural architecture. Mach. Learn. Knowl. Extr. 1(2), 575–589 (2019)
Albitar, S., Espinasse, B., Fournier, S.: Semantic enrichments in text supervised classification: application to medical domain. In: The Twenty-Seventh International Flairs Conference, pp. 425–430 (2014)
Zhang, R., Hristovski, D., Schutte, D., Kastrin, A., Fiszman, M., Kilicoglu, H.: Drug repurposing for COVID-19 via knowledge graph completion. J. Biomed. Inform. 115, 103696 (2021)
Kilicoglu, H., Shin, D., Fiszman, M., Rosemblat, G., Rindflesch, T.C.: SemMedDB: a PubMed-scale repository of biomedical semantic predications. Bioinformatics 28(23), 3158–3160 (2012)
Du, J., Li, X.: A knowledge graph of combined drug therapies using semantic predications from biomedical literature: algorithm development. JMIR Med. Inform. 8(4), e18323 (2020)
Ben Abacha, A., Zweigenbaum, P.: A hybrid approach for the extraction of semantic relations from MEDLINE abstracts. In: Gelbukh, A. (ed.) CICLing 2011. LNCS, vol. 6609, pp. 139–150. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-19437-5_11
Avram, A., Matei, O., Pintea, C.-M., Pop, P.: Context quality impact in context-aware data mining for predicting soil moisture. Cybern. Syst. 51(7), 668–684 (2020)
Avram, A., Matei, O., Pintea, C.-M., Pop, P.C.: Influence of context availability and soundness in predicting soil moisture using the context-aware data mining approach. Logic J. IGPL 31, 762–774 (2023)
Sammut, C., Webb, G.I. (eds.): Encyclopedia of Machine Learning and Data Mining, 2nd edn. Springer, New York (2017). https://doi.org/10.1007/978-1-4899-7687-1
Gonçalves, C., Iglesias, E.L., Borrajo, L., Camacho, R., Vieira, A.S., Gonçalves, C.T.: LearnSec: a framework for full text analysis. In: de Cos Juez, F., et al. (eds.) HAIS 2018. LNCS, vol. 10870, pp. 502–513. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-92639-1_42
Gonçalves, C.A.O., Camacho, R., Gonçalves, C.T., Seara Vieira, A., Borrajo Diz, L., Iglesias, E.L.: Classification of full text biomedical documents: sections importance assessment. Appl. Sci. 11(6), 2674 (2021)
Rebholz-Schuhmann, D., et al.: BioLexicon: towards a reference terminological resource in the biomedical domain. In: Proceedings of the of the 16th Annual International Conference on Intelligent Systems for Molecular Biology (ISMB 2008) (2008)
Forman, G., et al.: An extensive empirical study of feature selection metrics for text classification. J. Mach. Learn. Res. 3, 1289–1305 (2003)
Wolpert, D.H.: Stacked generalization. Neural Netw. 5(2), 241–259 (1992)
Acknowledgement
This work was financially supported by Base Funding - UIDB/00027/2020 of the Artificial Intelligence and Computer Science Laboratory - LIACC - funded by national funds through the FCT/MCTES (PIDDAC) and by Portuguese national funds through FCT - Fundação para a Ciência e Tecnologia, under the project UIDB/05422/2020.
We acknowledge the SoftCPS - Software Cyber-Physical Systems Group (ISEP) for their assistance and resources.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Gonçalves, C.A., Seara Vieira, A., Gonçalves, C.T., Borrajo, L., Camacho, R., Iglesias, E.L. (2023). To Enhance Full-Text Biomedical Document Classification Through Semantic Enrichment. In: García Bringas, P., et al. Hybrid Artificial Intelligent Systems. HAIS 2023. Lecture Notes in Computer Science(), vol 14001. Springer, Cham. https://doi.org/10.1007/978-3-031-40725-3_47
Download citation
DOI: https://doi.org/10.1007/978-3-031-40725-3_47
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-40724-6
Online ISBN: 978-3-031-40725-3
eBook Packages: Computer ScienceComputer Science (R0)