
Abstract
We introduce MotionCLIP, a 3D human motion auto-encoder featuring a latent embedding that is disentangled, well behaved, and supports highly semantic textual descriptions. MotionCLIP gains its unique power by aligning its latent space with that of the Contrastive Language-Image Pre-training (CLIP) model. Aligning the human motion manifold to CLIP space implicitly infuses the extremely rich semantic knowledge of CLIP into the manifold. In particular, it helps continuity by placing semantically similar motions close to one another, and disentanglement, which is inherited from the CLIP-space structure. MotionCLIP comprises a transformer-based motion auto-encoder, trained to reconstruct motion while being aligned to its text label’s position in CLIP-space. We further leverage CLIP’s unique visual understanding and inject an even stronger signal through aligning motion to rendered frames in a self-supervised manner. We show that although CLIP has never seen the motion domain, MotionCLIP offers unprecedented text-to-motion abilities, allowing out-of-domain actions, disentangled editing, and abstract language specification. For example, the text prompt “couch” is decoded into a sitting down motion, due to lingual similarity, and the prompt “Spiderman” results in a web-swinging-like solution that is far from seen during training. In addition, we show how the introduced latent space can be leveraged for motion interpolation, editing and recognition (See our project page: https://guytevet.github.io/motionclip-page/.
G. Tevet and B. Gordon—The authors contributed equally.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
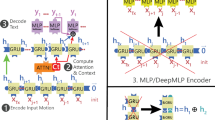

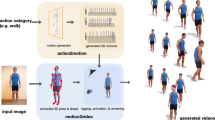
Notes
- 1.
- 2.
30 unique users, each was asked 12 questions.
- 3.
55 unique users, each was asked 4 questions.
References
Aberman, K., Weng, Y., Lischinski, D., Cohen-Or, D., Chen, B.: Unpaired motion style transfer from video to animation. ACM Trans. Graph. (TOG) 39(4), 64-1 (2020)
Ahuja, C., Morency, L.P.: Language2Pose: natural language grounded pose forecasting. In: 2019 International Conference on 3D Vision (3DV), pp. 719–728. IEEE (2019)
Aristidou, A., Yiannakidis, A., Aberman, K., Cohen-Or, D., Shamir, A., Chrysanthou, Y.: Rhythm is a dancer: music-driven motion synthesis with global structure. IEEE Trans. Visual. Comput. Graph. (2022)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: International Conference on Machine Learning, pp. 1597–1607. PMLR (2020)
Cho, K., et al.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078 (2014)
Dilokthanakul, N., et al.: Deep unsupervised clustering with Gaussian mixture variational autoencoders. arXiv preprint arXiv:1611.02648 (2016)
Dinh, L., Krueger, D., Bengio, Y.: Nice: non-linear independent components estimation. arXiv preprint arXiv:1410.8516 (2014)
Edwards, P., Landreth, C., Fiume, E., Singh, K.: Jali: an animator-centric viseme model for expressive lip synchronization. ACM Trans. graph. (TOG) 35(4), 1–11 (2016)
Fang, H., Xiong, P., Xu, L., Chen, Y.: Clip2Video: mastering video-text retrieval via image clip. arXiv preprint arXiv:2106.11097 (2021)
Frans, K., Soros, L., Witkowski, O.: ClipDraw: exploring text-to-drawing synthesis through language-image encoders. arXiv preprint arXiv:2106.14843 (2021)
Gal, R., Patashnik, O., Maron, H., Chechik, G., Cohen-Or, D.: StyleGAN-NADA: clip-guided domain adaptation of image generators. arXiv preprint arXiv:2108.00946 (2021)
Gatys, L.A., Ecker, A.S., Bethge, M.: Image style transfer using convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
Guo, C., et al.: Generating diverse and natural 3D human motions from text. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5152–5161, June 2022
Guo, C., et al.: Action2Motion: conditioned generation of 3D human motions. In: Proceedings of the 28th ACM International Conference on Multimedia, pp. 2021–2029 (2020)
Guzhov, A., Raue, F., Hees, J., Dengel, A.: AudioClip: extending clip to image, text and audio. In: ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 976–980. IEEE (2022)
Hadsell, R., Chopra, S., LeCun, Y.: Dimensionality reduction by learning an invariant mapping. In: 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2006), vol. 2, pp. 1735–1742. IEEE (2006)
He, X., Peng, Y.: Fine-grained image classification via combining vision and language. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5994–6002 (2017)
Holden, D., Saito, J., Komura, T.: A deep learning framework for character motion synthesis and editing. ACM Trans. Graph. (TOG) 35(4), 1–11 (2016)
Hong, F., Zhang, M., Pan, L., Cai, Z., Yang, L., Liu, Z.: AvatarClip: zero-shot text-driven generation and animation of 3d avatars. ACM Trans. Graph. (TOG) 41(4), 1–19 (2022). https://doi.org/10.1145/3528223.3530094
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1501–1510 (2017)
Ji, Y., Xu, F., Yang, Y., Shen, F., Shen, H.T., Zheng, W.S.: A large-scale RGB-D database for arbitrary-view human action recognition. In: Proceedings of the 26th ACM international Conference on Multimedia, pp. 1510–1518 (2018)
Kingma, D.P., Welling, M.: Auto-encoding variational Bayes. arXiv preprint arXiv:1312.6114 (2013)
Li, R., Yang, S., Ross, D.A., Kanazawa, A.: AI choreographer: music conditioned 3D dance generation with AIST++. In: The IEEE International Conference on Computer Vision (ICCV) (2021)
Lin, A.S., Wu, L., Corona, R., Tai, K., Huang, Q., Mooney, R.J.: Generating animated videos of human activities from natural language descriptions. Learning 2018, 1 (2018)
Liu, J., Shahroudy, A., Perez, M., Wang, G., Duan, L.Y., Kot, A.C.: NTU RGB+D 120: a large-scale benchmark for 3D human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 42(10), 2684–2701 (2019)
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: a skinned multi-person linear model. ACM Trans. Graph. (TOG) 34(6), 1–16 (2015)
Luo, H., et al.: CLIP4Clip: an empirical study of clip for end to end video clip retrieval. arXiv preprint arXiv:2104.08860 (2021)
Maheshwari, S., Gupta, D., Sarvadevabhatla, R.K.: MUGL: large scale multi person conditional action generation with locomotion. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 257–265 (2022)
Mahmood, N., Ghorbani, N., Troje, N.F., Pons-Moll, G., Black, M.J.: AMASS: archive of motion capture as surface shapes. In: International Conference on Computer Vision, pp. 5442–5451, October 2019
Michel, O., Bar-On, R., Liu, R., Benaim, S., Hanocka, R.: Text2Mesh: text-driven neural stylization for meshes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13492–13502 (2022)
Patashnik, O., Wu, Z., Shechtman, E., Cohen-Or, D., Lischinski, D.: StyleClip: text-driven manipulation of styleGAN imagery. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2085–2094 (2021)
Pavlakos, G., et al.: Expressive body capture: 3D hands, face, and body from a single image. In: Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 10975–10985 (2019)
Petrovich, M., Black, M.J., Varol, G.: Action-conditioned 3D human motion synthesis with transformer VAE. In: International Conference on Computer Vision (ICCV), pp. 10985–10995, October 2021
Petrovich, M., Black, M.J., Varol, G.: TEMOS: generating diverse human motions from textual descriptions. In: European Conference on Computer Vision (ECCV) (2022)
Plappert, M., Mandery, C., Asfour, T.: The kit motion-language dataset. Big Data 4(4), 236–252 (2016)
Plappert, M., Mandery, C., Asfour, T.: Learning a bidirectional mapping between human whole-body motion and natural language using deep recurrent neural networks. Robot. Auton. Syst. 109, 13–26 (2018)
Punnakkal, A.R., Chandrasekaran, A., Athanasiou, N., Quiros-Ramirez, A., Black, M.J.: BABEL: bodies, action and behavior with English labels. In: Proceedings IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 722–731, June 2021
Radford, A., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning, pp. 8748–8763. PMLR (2021)
Ramesh, A., et al.: Zero-shot text-to-image generation. In: International Conference on Machine Learning, pp. 8821–8831. PMLR (2021)
Sanghi, A., et al.: Clip-forge: towards zero-shot text-to-shape generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18603–18613 (2022)
Shi, L., Zhang, Y., Cheng, J., Lu, H.: Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12026–12035 (2019)
Sohn, K., Lee, H., Yan, X.: Learning structured output representation using deep conditional generative models. In: Advances in Neural Information Processing Systems, vol. 28 (2015)
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Vinker, Y., et al.: ClipASSO: semantically-aware object sketching. arXiv preprint arXiv:2202.05822 (2022)
Wang, C., Chai, M., He, M., Chen, D., Liao, J.: Clip-NERF: text-and-image driven manipulation of neural radiance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3835–3844 (2022)
Wang, J., Xu, H., Narasimhan, M., Wang, X.: Multi-person 3D motion prediction with multi-range transformers. In: Advances in Neural Information Processing Systems, vol. 34 (2021)
Wen, Y.H., Yang, Z., Fu, H., Gao, L., Sun, Y., Liu, Y.J.: Autoregressive stylized motion synthesis with generative flow. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13612–13621 (2021)
Yamada, T., Matsunaga, H., Ogata, T.: Paired recurrent autoencoders for bidirectional translation between robot actions and linguistic descriptions. IEEE Robot. Autom. Lett. 3(4), 3441–3448 (2018)
Youwang, K., Ji-Yeon, K., Oh, T.H.: Clip-Actor: text-driven recommendation and stylization for animating human meshes (2022)
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation representations in neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5745–5753 (2019)
Acknowledgements
We thank and appreciate the early collaboration on the problem with our colleagues Nefeli Andreou, Yiorgos Chrysanthou and Nikos Athanasiou, that fueled and motivated our research. We thank Sigal Raab, Rinon Gal and Yael Vinker for their useful suggestions and references. This research was supported in part by the Israel Science Foundation (grants no. 2492/20 and 3441/21), Len Blavatnik and the Blavatnik family foundation, and The Tel Aviv University Innovation Laboratories (TILabs).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Tevet, G., Gordon, B., Hertz, A., Bermano, A.H., Cohen-Or, D. (2022). MotionCLIP: Exposing Human Motion Generation to CLIP Space. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds) Computer Vision – ECCV 2022. ECCV 2022. Lecture Notes in Computer Science, vol 13682. Springer, Cham. https://doi.org/10.1007/978-3-031-20047-2_21
Download citation
DOI: https://doi.org/10.1007/978-3-031-20047-2_21
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-20046-5
Online ISBN: 978-3-031-20047-2
eBook Packages: Computer ScienceComputer Science (R0)