
Abstract
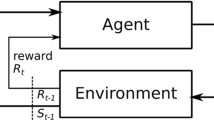
Reinforcement Learning formalises an embodied agent’s interaction with the environment through observations, rewards and actions. But where do the actions come from? Actions are often considered to represent something external, such as the movement of a limb, a chess piece, or more generally, the output of an actuator. In this work we explore and formalize a contrasting view, namely that actions are best thought of as the output of a sequence of internal choices with respect to an action model. This view is particularly well-suited for leveraging the recent advances in large sequence models as prior knowledge for multi-task reinforcement learning problems. Our main contribution in this work is to show how to augment the standard MDP formalism with a sequential notion of internal action using information-theoretic techniques, and that this leads to self-consistent definitions of both internal and external action value functions.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Bertsekas, D.P., Tsitsiklis, J.N.: Neuro-Dynamic Programming. Athena Scientific, Belmont (1996)
Brown, T.B., et al.: Language models are few-shot learners. arXiv preprint arXiv:2005.14165 (2020)
Catt, E., Hutter, M., Veness, J.: Reinforcement learning with information-theoretic actuation. arXiv preprint arXiv:2109.15147 (2021)
Cover, T.M.: Elements of Information Theory. Wiley, New York (1999)
Ecoffet, A., Huizinga, J., Lehman, J., Stanley, K.O., Clune, J.: Go-explore: a new approach for hard-exploration problems (2021)
Hutter, M.: On the existence and convergence of computable universal priors. In: Gavaldá, R., Jantke, K.P., Takimoto, E. (eds.) ALT 2003. LNCS (LNAI), vol. 2842, pp. 298–312. Springer, Heidelberg (2003). https://doi.org/10.1007/978-3-540-39624-6_24
Janner, M., Li, Q., Levine, S.: Reinforcement learning as one big sequence modeling problem (2021)
Milan, K., et al.: The forget-me-not process. In: Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 29. Curran Associates, Inc. (2016)
Mnih, V., et al.: Human-level control through deep reinforcement learning. Nature 518(7540), 529–533 (2015)
Ortega, P., et al.: Meta-learning of sequential strategies (2019)
Rissanen, J., Langdon, G.G.: Arithmetic coding. IBM J. Res. Dev. 23(2), 149–162 (1979)
Strehl, A., Li, L., Littman, M.: Reinforcement learning in finite MDPs: PAC analysis. J. Mach. Learn. Res. 10, 2413–2444 (2009). https://doi.org/10.1145/1577069.1755867
Sutton, R.S., Barto, A.G.: Reinforcement Learning: An Introduction. MIT Press, Cambridge (2018)
Szepesvári, C.: Algorithms for reinforcement learning. Synth. Lect. Artif. Intell. Mach. Learn. 4(1), 1–103 (2010)
Veness, J., et al.: Gated linear networks. arXiv preprint arXiv:1910.01526 (2019)
Witten, I.H., Neal, R.M., Cleary, J.G.: Arithmetic coding for data compression. Commun. ACM 30(6), 520–540 (1987)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Catt, E., Hutter, M., Veness, J. (2023). Reinforcement Learning with Information-Theoretic Actuation. In: Goertzel, B., Iklé, M., Potapov, A., Ponomaryov, D. (eds) Artificial General Intelligence. AGI 2022. Lecture Notes in Computer Science(), vol 13539. Springer, Cham. https://doi.org/10.1007/978-3-031-19907-3_18
Download citation
DOI: https://doi.org/10.1007/978-3-031-19907-3_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-19906-6
Online ISBN: 978-3-031-19907-3
eBook Packages: Computer ScienceComputer Science (R0)