
Abstract
This work is mainly aimed at evaluating the reasons behind the inefficient execution of Operational Programs (OPs) aimed at promoting research and innovation (R&I), especially in small and medium-sized enterprises (SMEs). To achieve this goal, we employed a three-stage slack-based measure (SBM) data envelopment analysis (DEA) model combined with Stochastic Frontier analysis (SFA), which includes a multiplicity of achievement metrics and environmental factors, to evaluate 53 OPs from 19 countries. Our findings suggest that more developed regions (proxied by a higher Gross Domestic Product (GDP) per capita) do not make an efficient application of European Regional Development Funds (ERDF) aimed at fostering R&I in SMEs. Also, a greater proportion of the population with a university degree does not imply an appropriate use of ERDF devoted to R&I in SMEs. Lifelong learning is positively linked with the performance of the outcomes “Researchers Working in Improved Infrastructures” and “Enterprises Supported”. Research and development (R&D) expenditures in the public sector contribute favorably to the needed improvements in “Researchers Working in Improved Infrastructures” but have the reverse effect on the number of “Enterprises Supported” and “Enterprises Working with Research Institutions”. Furthermore, because R&D expenditures in the business sector have a positive impact on the necessary development of “Enterprises Working with Research Institutions”, these results appear to demonstrate that public R&D has a weaker influence on SME innovation than private R&D. Finally, innovative SMEs collaborating with other sources of knowledge show a positive effect on both the number of “Enterprises” and “Enterprises Working with Research Institutions” supported.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
When it comes to innovation, SMEs have a variety of practical challenges. Accessibility to finance may be challenging to get for SMEs, particularly when risky initiatives are involved (Lee et al., 2010; Romero-Martínez et al., 2010; Van de Vrande et al., 2009). The level to which this is an obstacle differs depending on the age of the organization, the company size, the intensity of the investigation, the growth orientation (Zimmermann & Thomä, 2016), and, in many circumstances, the geographic location (Hölzl & Janger, 2014). Additional hurdles may include problems in hiring highly trained individuals (Belitz & Lejpras, 2016; Bianchi et al., 2010; Dahlander & Gann, 2010; Duarte et al., 2017; Gardocka-Jałowiec & Wierzbicka, 2019), issues with management (Zhou et al., 2021), lower adsorption ability (Müller et al., 2021), and challenges in capturing value (Bouncken et al., 2020). Nonetheless, the most fundamental hurdles to innovation are perceived to be economic (García-Quevedo et al., 2018). Over the 2014–2020 programmatic period, the ERDF provided around 66 billion Euros to boost innovation and productivity, particularly in the European Union (EU) SMEs (Gramillano et al., 2018). Despite the evaluation of the implementation of these funds being mandatory, according to Ortiz and Fernandez (2022), policymakers still face major challenges in their assessment and control stages, owing to the absence of useful information, comparative studies, and organizational qualifications. Moreover, evaluation mechanisms during the 2014–2020 programmatic cycle focused heavily on evaluating procedure results, with hardly any data on the criteria to measure the immediate benefits of the initiatives funded (Ortiz & Fernandez, 2022). Furthermore, in the case of R&I policies, the assessment technique plays an important role in assisting the national/regional authorities in the enhancement of upcoming policy tools by identifying the strengths and weaknesses of previous policy stages (Neto & Santos, 2020). In this context, there are numerous techniques for appraising cohesion policy (Lopez-Rodríguez & Faíña, 2014). Macroeconomic and econometric modeling are commonly used approaches for analyzing the effect of cohesion policy (Henriques et al., 2022a, b). Computable General Equilibrium Models along with input–output models and econometric techniques are normally employed in the context of R&I socioeconomic effect evaluation (e.g., Di Comite et al., 2018; Diukanova et al., 2022; Barbero et al., 2022). Even though these approaches allow for the evaluation and study of the major effects of EU funds on economic growth, they do not allow evaluating management failures (Marzinotto, 2012). Moreover, they ignore the allocation of EU funding within every region to different thematic objectives (TO). The research mainstream is based on econometric studies (see, for example, Stojčić et al., 2020; Radicic & Pugh, 2017; Santos et al., 2019; Thum-Thysen et al., 2019; Fattorini et al., 2020; Sein & Prokop, 2021). Nevertheless, it produces contradictory results (Berkowitz et al., 2019), prompting some experts to dispute its use (Durlauf, 2009; Wostner & Šlander, 2009; Berkowitz et al., 2019). Other methods can also be employed, but with the same intrinsic shortcomings (e.g., Bedu & Vanderstocken, 2020; Gustafsson et al., 2020). The evaluation procedures generally available do not allow comparing any regional or national OP against its peers. These do not enable the identification of the adjustments that should occur to enhance the efficiency of OPs’ execution (Gouveia et al., 2021). Moreover, these methods often require fulfilling statistical hypotheses (namely, normality, absence of multicollinearity, and homoscedasticity). Therefore, the adoption of nonparametric methodologies can be valuable and appropriate, particularly as the data freely available on the European Commission website can be used in conjunction with DEA models. The efficient production frontier is usually derived through stochastic approaches (Gouveia et al., 2021). These, nevertheless, can just accommodate an output level at a time (Gouveia et al., 2021). Contrastingly, DEA can easily handle many inputs (resources) and outputs (outcomes) and can also be applied to determine the efficient production frontier. Furthermore, contrary to stochastic techniques, DEA does not rely on any production function form or error term. According to DEA, the greater the divergence from the production efficient frontier, the greater the inefficiency of the decision-making unit (DMU) (in this case, the OPs) under appraisal. Also, the DEA methodology can be particularly valuable for management authorities (MA) because it enables the detection of best practices, and also identifies the changes that need to occur to improve the performance of the OPs under evaluation.
In this framework, Athanassopoulos (1996) used DEA to determine the relative geographical weaknesses of the EU’s Level II territories. Gómez-García et al. (2012) assessed the pure and global technical efficiencies regarding Thematic Objective 1 (TO1) in the deployment of EU structural funds from 2000 to 2006. They employed labor and productivity levels as outputs, and the Stochastic Frontier Analysis (SFA) together with the DEA methodology. Anderson & Stejskal, (2019) employed DEA to evaluate the efficiency of innovation diffusion in EU MS based on their European Innovation Scoreboard scores. Furthermore, Gouveia et al. (2021) employed the Value-Based DEA technique, considering the primary elements that can impair the efficient execution of structural funds in different OPs devoted to SMEs’ competitiveness. Henriques et al. (2022a) used the SBM approach in conjunction with cluster analysis to evaluate 102 OPs from 22 EU MS focused on the implementation of a low-carbon economy in SMEs. Finally, Henriques et al. (2022b) evaluated the efficiency of 53 R&I OPs from 19 countries utilizing the Network SBM technique in combination with cluster analysis for appraising the implementation of EU funds devoted to promoting R&I in SMEs. Nevertheless, their work did not accommodate for the influence of contextual variables and random errors in efficiency evaluation. Therefore, this work aims to fill this gap by suggesting an approach that combines a three-stage SBM model and SFA, which to the best of our knowledge has not hitherto been used in this context. Through this method it is possible to further understand if the efficiency results attained are mainly related to management failures or the contextual environment of the OPs or statistical noise, also providing information on the contextual factors with the greatest effect on the OPs’ inefficiencies.
Insofar, the main research questions that we seek to address with this work are given below:
-
RQ1: “Which contextual variables show a relevant effect on the inefficiencies of the OPs committed to boosting R&I in SMEs?”
-
RQ2: “What are the impacts of considering contextual factors on the efficiency of the OPs?”
This article is organized as follows. Section 2 explains the basic assumptions underlying the techniques suggested to assess the execution of the OPs evaluated. Section 3 addresses the key rationale for choosing the inputs and outputs utilized in this study, as well as some statistics on the data that instantiates the SBM and SFA models. Section 4 delves into the major findings. Section 5 summarizes the major results, discusses potential policy recommendations, identifies the main shortcomings, and proposes further work advances.
2 Methodology
Classical DEA techniques, like the CCR (Charnes et al., 1978) and BCC (Banker et al., 1984), are radial, which means that they can simply manage proportional adjustments in the inputs or outputs used in the assessment. Therefore, the CCR and BCC efficiency ratings produced indicate the highest proportionate input (output) contraction (expansion) rates for all inputs (outputs). Nevertheless, owing to factor substitutions, this sort of premise is frequently not met in practice.
As a result, in opposition to the CCR and BCC approaches, we employ the SBM approach (Tone, 2001), which allows for a broader study of efficiency due to its non-radial nature (i.e., inputs and outputs can vary non-radially), also enabling to consider non-oriented models (i.e., address simultaneous variations of the inputs and outputs).
2.1 The SBM Model
The generalized SBM model of Tone (2001) may be presented (by taking m inputs, s outputs, and n DMUs into account) as follows:
where X = [xij, i = 1, 2, …, m, j = 1, 2, …, n] is the (m × n) matrix of inputs, Y = [yrj, r = 1, 2, …, s, j = 1, 2, …, n] is the matrix of outputs (s × n) and the rows of these matrices for DMUk are, respectively, \({\mathbf{x}}_k^T\) and \({\mathbf{y}}_k^T\), where T is the transpose of a vector. Also, we presume a Variable Returns to Scale technology with the imposition of \(\sum_{j = 1}^n {\lambda _j } \) = 1, \(_j\) ≥ 0 (∀j). The value of 0 < ρ < 1 can be seen as the ratio of average inefficiencies of inputs and outputs.
A DMUk is SBM-efficient if \(\rho^* = 1\), , meaning that the slacks (\(s_i^-\) and \( s_i^+\)) are null for all the inputs and outputs.
Problem (1) can be converted into a linear problem, by applying a positive scalar variable t (see Tone (2001)). Further details on this modeling approach can be found in Tone (2001) and regarding SBM superefficiency in Tone (2002).
2.2 Stochastic Frontier Analysis
Fried et al. (2002) proposed a three-stage DEA model. In the first stage, the SBM model is applied to calculate the technical efficiency of each DMU, and the necessary changes required to the inputs and outputs to turn inefficient DMUs into efficient ones (i.e., the slacks). In the second stage, the slacks are grouped into three types: contextual variables, inefficient management, and statistical noise. The slacks are the dependent variables, while the contextual variables are the independent variables. The objective is to remove the influence of contextual factors and random errors. SFA is then used to modify the input and output factors (Aigner et al., 1977; Meeusen & Broeck, 1977).
Therefore, the slack of each input obtained for every inefficient DMUj (\(j = 1, \ldots ,p\)) is:
where \(s_{ij}\) is the slack of input i of DMUj, \(f\left( {X_j ,{ }\beta^i } \right)\) is the slack frontier, and \(\beta^i\) corresponds to the coefficients related to the contextual variables. Expression \(v_{ij} + u_{ij}\) is the mixed error, \(v_{ij}\) is the statistical noise and \(u_{ij}\) is the management inefficiency. Generally, it is presumed that \(v_{ij} \sim N\left( {0;{\text{~}}\sigma _v^2 } \right) \) and \( u_{ij} \sim N^ + \left( {\mu ^i ;\sigma _u^2 } \right), \) where \(v_{ij}\) and \(u_{ij}\) are independent variables.
Consider that \(\gamma = \frac{\sigma_u^2 }{{\sigma_u^2 + \sigma_v^2 }}\). If \(\gamma\) is near 1, it implies that the majority of the adjustment necessary to reach efficiency is related to management inefficiency. If \(\gamma \) is near 0, the random error is the prevalent factor.
Subsequently, the adjusted input and output slacks are obtained by splitting the mixed error. According to Jondrow et al. (1982), the conditional inefficiency is given as:
where \(\delta = \frac{\sigma_u }{{\sigma_v }},{ }\varepsilon_j = v_{ij} + u_{ij},{ }\sigma^2 = \sigma_u^2 + \sigma_v^2 ,{ }\varphi { }\) and \(\emptyset\) are, correspondingly, the density and distribution functions of the standard normal distribution. Hence, the expected value of random error is:
Secondly, the input and output factors of each DMU are changed according to the SFA outcomes by removing the significant contextual effects and statistical noises.
According to Tone and Tsutsui (2009), we begin by employing these formulas:
The input data are adjusted using (5) as follows (Tone & Tsutsui, 2009):
where
Analogously, the outputs are changed using (6) as (Tone & Tsutsui, 2009):
where
Then again, the efficiency scores are computed through SBM by employing the previously adjusted inputs and outputs.
3 Data
3.1 Input and Output Factors
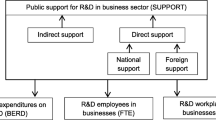
This work is a follow-up of the work published by Henriques et al. (2022b) and, therefore, we have employed mostly the same input and output factors chosen therein for evaluating the efficiency of the execution of ERDF allotted to boost R&I in SMEs—see Table 1 and Fig. 1. All the information regarding these data is obtainable from Henriques et al. (2022b).

3.2 Contextual Factors
The regional GDP at purchasing power parity per capita (GDPPPpc) was considered a contextual variable being used as a proxy to measure economic activity (Barbero et al., 2022; Diukanova et al., 2022; Hervás-Oliver et al., 2021). Besides, Barbero et al. (2022) concluded that the achievement of regional targets related to the ERDF TO1 has a positive impact on all economic indicators, including the GDP, in the selected regions (Greece, Italy, Portugal, and Spain).
According to Diukanova et al. (2022), R&I and low-carbon European structural funds can exert substantial positive effects on the indicator of tertiary education attainment, thus the percentage of the population aged 25–34 who have finished university education was also considered in this set of contextual factors.
Anderson and Stejskal (2019) used variables that fall into the category of human resource (lifelong learning, employment in knowledge-intensive activities), finance (public sector R&D expenditure, private sector R&D expenditure, sales of new-to-market and new-to-firm innovations) and non-financial innovation structures (non-R&D innovation expenditure). Additionally, as referred in Hervás-Oliver et al. (2021), the variation in the development of EU regions affects the innovation capacity of SMEs located in each territory and consequently, it is important to incorporate the variables that better capture innovation in SMEs (e.g., innovation activities like public and private R&D expenditures, non-R&D innovation expenditures, innovative SMEs collaborating with others).
Therefore, we have used similar variables that were reported in the latest European Innovation Scoreboard (Hollanders, 2021). Finally, Sein and Prokop (2021) stress the key role of a firm’s R&D, which has proven to be a mediator of the effects of public funding and triple- and quadruple-helix cooperation on the product and process innovation activities of Norwegian firms. In this study, variables such as SMEs with product innovations and SMEs with business process innovations were used. Therefore, we considered, in this context, sales of new-to-market and new-to-firm innovation. All the contextual variables shown in Table 2 (apart from GDPPPPpc whose data were obtained from the OECD website) were extracted from the European Innovation Scoreboard (Hollanders, 2021), allowing to capture differences in SMEs innovation across regions. All these indicators are normalized between 0 and 1 at origin, to produce a composite indicator integrating variables from different scales. Table 2 shows the main descriptive statistics of the contextual variables.
4 Discussion of Results
The initial results were computed with the help of the Max DEA software and their descriptive statistics are depicted in Table 3.
From Table 3, it can be seen, in general, that the variability of the efficiency scores is bigger for efficient OPs than for inefficient ones (with the standard deviation varying between 0.25 and 0.15, for the first and the latter, respectively). Besides, inefficient OPs present very low mean efficiency scores (with an average potential improvement of efficiency of 94%). Figure 2 illustrates the number of OPs at several subintervals for the efficiency scores.

Source Authors’ own elaboration
Number of OPs at different subintervals of efficiency scores.
The number of OPs classified as efficient is 10 (Fig. 2).
Out of the ten efficient OPs, the three most chosen as benchmarks are “Brussels Capital Region—ERDF” (41 times), “Aragón—ERDF” (17 times), and “Toscana—ERDF” (18 times)—see Table 4. The OP most frequently viewed as a benchmark is characterized as an “Innovation Leader” and manages to score in all the outputs examined in the assessment—see Table 4.
The SBM model also offers an outline of the changes that really should be made to inputs and outputs to convert inefficient OPs into efficient ones—see Fig. 3.

Source Authors’ own elaboration
Average original factors versus their projections for inefficient OPs.
The ‘number of researchers working in improved R&I infrastructures’ has the largest potential for improvement (2174%), followed by ‘total eligible spending’ (−78%), the ‘number of enterprises supported for new-to-the-market products’ (71%), the ‘number of enterprises supported’ (46%) and the ‘number of enterprises working with R&I institutions’—see Fig. 3. All in all, like other studies, our findings also show the importance of the lack of skills as an obstacle to R&I OPs’ implementation (e.g., Belitz & Lejpras, 2016; Duarte et al., 2017; Gardocka-Jałowiec & Wierzbicka, 2019). These results also highlight the need to foster the cooperation and networking of SMEs with research institutions, thus corroborating Hervás-Oliver et al. (2021) findings. Besides, additionally, since there seems to be an overuse of the EU funding (because of the required reduction on eligible spending), our results suggest the validation of the ‘European paradox’ since there seems to exist an ‘innovation gap’ in that supporting innovation inputs through public funding does not necessarily lead to innovation outputs (Hammadou et al., 2014; Radicic & Pugh, 2017).
4.1 Results Obtained with SFA
To remove the potential effects of contextual factors and random errors, the functional forms given in (4) were estimated. The slacks of the outputs were considered as dependent variables, originating four regressions models. The multicollinearity was evaluated through the variance inflation factor (VIF), which measures the strength of correlation between the independent variables. This indicator is always greater than or equal to 1. Table 5 illustrates the values of VIF considering three sets of variables. When VIF is higher than 10, there is significant multicollinearity that needs to be corrected, thus, in the first step, we began by removing the four contextual variables that verify such condition. Afterward, the VIF values for the remaining variables were calculated (see Table 5, second step). Usually, values within 1 and 5 are not deemed relevant to cause concern (Belsley, 1991; James et al., 2013), but it seemed prudent to recalculate the VIF values without the variables “Non-R&D innovation expenditures” and “Innovation expenditures per person employed” and “PCT patent applications”. The small values of VIF presented in Table 5 reveal that, when considering these variables, there is no problem of collinearity.
To run the SFA regression models, the R software, version 4.0.5 (RStudio Team, 2021), particularly, the sfaR package version 0.1.1 was used (Dakpo et al., 2022). The final regression models are shown in Table 6.
In model (1), the value of γ is very close to zero, thus the statistical noise is in a dominant position. Furthermore, statistical noise and the contextual variables GDPPPPpc, Lifelong learning, and R&D expenditures of the public sector explain virtually all the variation that occurred in the slack of the output “Researchers working in improved infrastructures”. For the models (2), (3), and (4), the values of γ are near one and statistically significant (1%), this means that management problems are the principal cause of the achieved technical (in)efficiency. The contextual variables considered in model (2) cause a relevant effect on the slack since all the regression coefficients associated are significant (at the 1% level). Likewise, in model (3), we found statistically significant variables to explain the required adjustments in “Enterprises Working with Research Institutions.” Concerning model (4), since there are no statistically significant variables, no adjusted values are required for this output.
According to Table 6, a rise in GDPPPPpc contributes to a larger necessary increase of “Researchers Working in Improved Infrastructures”, “Enterprises Supported” and “Enterprises Working with Research Institutions”. On the one hand, regarding the two latter indicators, these findings seem to suggest that richer regions do not show a better use of ERDF targeted to strengthen R&I in SMEs. Bukvić et al. (2021) arrived at similar conclusions regarding the underuse of ERDF by SMEs in the Information and Communication Technologies sector in Croatia from 2014–2020. They ascertained that the difficulties and time required to submit, produce, and assess project proposals were a probable justification for these findings. Furthermore, Martinez-Cillero et al. (2020) reported that SMEs’ investments are poorer than would be anticipated by standard economic models, proposing that these firms are particularly sensitive to funding difficulties. Another possible explanation might be related to the use of further financing opportunities in the framework of other funding programs (outside ERDF). On the other hand, regarding the first indicator, these outcomes also highlight the need to handle the lack of skilled researchers, a major hurdle to innovation also identified in more developed regions (Hölzl & Janger, 2014).
Additionally, a higher percentage of the population with tertiary education does not lead to an efficient number of “Enterprises Supported” and “Enterprises Working with Research Institutions” supported. These results might suggest that higher education institutions should be further contributing to the actual needs of the economy. In this framework, initiatives should be promoted to increase the relationship of SMEs with higher education institutions, since this type of linkage can be beneficial for the innovation environment (Kobarg et al., 2018; Rajalo & Vadi, 2017).
Lifelong learning seems to be positively associated with a better performance of the outputs “Researchers Working in Improved Infrastructures” and “Enterprises Supported” because it is negatively related to their required improvements. These outcomes may be explained by the abundance of the population involved in lifelong learning activities in the generality of MS (Anderson & Stejskal, 2019). Besides, these findings also suggest that coordinated lifelong learning policies play a pivotal role in propelling innovation and progress among MS and regions.
R&D expenditures within the public sector seem to have a positive contribution to the required enhancement of the adjustments on “Researchers Working in Improved Infrastructures”, with the opposite effect on the number of “Enterprises Supported” and “Enterprises Working with Research Institutions”. On the one hand, these results highlight the positive effect of public R&D spending on education attainment (i.e., a higher number of skilled researchers) since these are also linked with expenses in the higher education public sector. However, the two latter findings may imply that increased R&D expenditures within the public sector are not a viable strategy to mitigate SMEs’ inability to engage in R&D (Hervás-Oliver et al., 2021). This might also suggest that EU SMEs cannot absorb the spillover effects from public R&D (Rodríguez-Pose & Wilkie, 2019). Furthermore, since the R&D expenditures within the business sector show a positive effect on the required enhancement of “Enterprises Working with Research Institutions” (i.e., a reduction of the necessary adjustment to become efficient), these findings appear to demonstrate the lesser influence of public R&D in SME innovation compared to private R&D. Similarly, results were also attained by Hervás-Oliver et al. (2021).
In what concerns the innovative SMEs collaborating with others as a percentage of SMEs, there is a positive effect both on the number of “Enterprises Supported” and the “Enterprises Working with Research Institutions” (the enhancement required in these two outputs is negative). In a similar context, Hervás-Oliver et al. (2021) concluded that SME collaboration with exterior sources of knowledge (either supply-chain actors and competitors or universities or other sources of research) is positively related to regional SME innovation.
Finally, sales of new-to-market and new-to-firm innovations require a further enhancement of the number of “Enterprises Working with Research Institutions” (the enhancement required in this output is positive). These findings might be influenced by the fact that this contextual variable does not make a distinction between incremental and radical innovation, also considering non-technological innovations (Apa et al., 2021).
4.2 Results Obtained with the Adjusted Factors
Table 7 shows that efficient OPs hardly change their average efficiency scores with the adjusted factors (the standard deviation is the same, i.e., 0.27). Besides, the efficiency scores are bounded within the same interval, i.e., [1.04, 1.88], demonstrating efficiency scores bigger than 1.24 for more than 50% of the efficient OPs. Also, inefficient OPs decrease the variability of their efficiency scores (with a standard deviation of 0.11 against the previous 0.15, with more than 50% of inefficient OPs having efficiency values just under 0.06) and increased their average efficiency from 0.06 to 0.10 (underlining the importance of the contextual variables).
Figure 4 depicts the difference in the technical efficiency of the OPs with and without adjusted factors.

Source Authors’ own elaboration
Efficiency scores for the efficient OPs obtained with adjusted and non-adjusted factors.
Figure 5 illustrates the greatest efficiency gains attained with the adjusted factors. When contrasted with the first step of the analysis, “Competitiveness and Cohesion–HR—ERDF/CF” demonstrated the greatest gain in efficiency, with values going from 0.0003 to 0.0676. Overall, these outcomes suggest that the inefficiencies originally computed for these OPs were not solely the result of their low technical level but were also related to their contextual factors.

Source Authors’ own elaboration
Efficiency scores for the efficient OPs with the greatest efficiency gains obtained with adjusted and non-adjusted factors.
Then again, out of the ten efficient OPs, the three most chosen as benchmarks are “Brussels Capital Region—ERDF” (39 times), “Aragón—ERDF” (20 times), and “Toscana—ERDF” (17 times) and “Extremadura—ERDF” (15 times).
5 Conclusions and Further Research
The primary purpose of this article was to evaluate the reasons behind the inefficiency of the OPs devoted to boosting R&I in SMEs. With this aim, we assessed 53 OPs within TO1 from 19 EU MS. To begin with, the SBM modeling approach is utilized to calculate the technical efficiency of every OP. At this stage, important data about the overall adjustments that should be made to reduce any disparities between inefficient OPs and their corresponding benchmarks are obtained.
Unlike other commonly used techniques applied in comparable situations, such as reference cases, econometric and statistical methods, and macroeconomic and microeconomic analyses, the SBM model can be particularly useful for MA, as it enables them to identify the references of best practices and the required changes to improve the OPs’ implementation performance, also contemplating their performance in two different stages. The second phase consists of employing SFA to the slacks of inefficient OPs to change the inputs and outputs after removing environmental effects and statistical noise. At this stage, information is extracted about how environmental factors may influence the efficiency of ERDF deployment in distinct OPs devoted to the promotion of R&I in SMEs, as well as the magnitude of management flaws. Finally, the previously corrected factors are employed in the SBM model to obtain new efficiency ratings.
Our main conclusions are discussed next.
RQ1: “Which contextual variables show a relevant effect on the inefficiencies of the OPs committed to boosting R&I in SMEs?”
Our results indicate that more developed regions do not make efficient use of ERDF aimed at promoting R&I in SMEs. The difficulty and time necessary to submit, develop and evaluate the project proposals, and the higher vulnerability of these types of enterprises to financial issues are possible explanations for these poor results. Alternatively, these findings can also be attributed to the utilization of additional financing options within the context of other funding programs. Furthermore, these results also demonstrate the need of addressing the shortage of trained researchers, which has been recognized as a key barrier to innovation in more developed regions. Besides, a larger percentage of the population with university education does not result in an adequate number of “Enterprises” and “Enterprises Working with Research Institutions” supported. These findings may imply that higher education institutions should contribute more to the economy's genuine demands. Initiatives should be pushed in this framework to strengthen SMEs’ relationships with higher education institutions since this form of collaboration can be advantageous to the innovation environment.
Lifelong learning appears to be favorably correlated with the higher performance of the outputs “Researchers Working in Improved Infrastructures” and “Enterprises Supported”. Hence, our results indicate that integrated lifelong learning strategies are critical in accelerating innovation among MS and regions.
R&D expenditures in the public sector appear to contribute positively to the needed enhancement of the adjustments on “Researchers Working in Improved Infrastructures” but have the opposite effect on the number of “Enterprises Supported” and “Enterprises Working with Research Institutions”. On the one hand, these findings indicate the favorable impact of these expenditures on educational attainment because they are also connected to expenditures in the public higher education sector. The two latter findings, however, may suggest that greater R&D expenditures in the public sector are not a realistic option for mitigating SMEs’ incapacity to engage in R&D. This might also imply that SMEs cannot absorb spillover effects from governmental R&D.
Additionally, because R&D expenditures in the business sector have a beneficial impact on the required improvement of “Enterprises Working with Research Institutions”, these findings appear to show that public R&D has a lesser influence on SME innovation compared to private R&D.
Concerning innovative SMEs cooperating with others as a proportion of SMEs, there is a favorable influence of this contextual variable both on the number of “Enterprises” and on “Enterprises Working with Research Institutions” supported. Therefore, it might be ascertained that the collaboration of SMEs with external sources of knowledge is positively connected to regional SME innovation.
Finally, sales of new-to-market and new-to-firm innovations have a negative effect on the number of “Enterprises Working with Research Institutions” (the enhancement required in this output is positive). These findings might be impacted by the fact that this contextual variable does not distinguish between incremental and radical innovation, as well as non-technological breakthroughs.
RQ2: “What are the impacts of considering contextual factors on the efficiency of the OPs?”
If the factors are adjusted according to Tone and Tsutsui (2009), 19% of OPs (10) manage to attain technical efficiency in any case, indicating that the effects of contextual factors are more visible on inefficient OPs. The biggest gap in efficiency was found in inefficient OPs that showed an average efficiency gain of 67%. The most efficient regions regardless of the adjustments were “Competitiveness Entrepreneurship and Innovation—GR—ERDF/ESF”, “England—ERDF” and “Multi-regional Spain—ERDF”, with values of efficiency ranging between 1.25 and 1.88. In general, it can be concluded that the technical efficiency of the OPs classified as efficient was mostly driven by good management practices.
Although this work gave new perspectives on the evaluation of OPs dedicated to R&I in EU SMEs, it had limitations. Though the performance framework made available by the European Commission includes a set of procedural indicators, there is no full correspondence between the data collected for the OPs’ accomplishments and their financial execution. Secondly, since the data available is often sparse, our evaluation was applied to a reduced number of OPs.
Whereas our work focused on an assessment technique for use throughout the reporting phases of the programmatic cycle, future work should address ex-post assessment, with a special emphasis on the spillover effects of the OPs under TO1.
References
Aigner, D., Lovell, C. K., & Schmidt, P. (1977). Formulation and estimation of stochastic frontier production function models. Journal of Econometrics, 6(1), 21–37. https://doi.org/10.1016/0304-4076(77)90052-5
Anderson, H. J., & Stejskal, J. (2019). Diffusion efficiency of innovation among EU member states: A data envelopment analysis. Economies, 7(2), 34. https://doi.org/10.3390/economies7020034
Apa, R., De Marchi, V., Grandinetti, R., & Sedita, S. R. (2021). University-SME collaboration and innovation performance: The role of informal relationships and absorptive capacity. The Journal of Technology Transfer, 46(4), 961–988. https://doi.org/10.1007/s10961-020-09802-9
Athanassopoulos, A. D. (1996). Assessing the comparative spatial disadvantage (CSD) of regions in the European Union using non-radial data envelopment analysis methods. European Journal of Operational Research, 94(3), 439–452. https://doi.org/10.1016/0377-2217(95)00114-X
Banker, R. D., Charnes, A., & Cooper, W. W. (1984). Some models for estimating technical and scale inefficiencies in data envelopment analysis. Management Science, 30(9), 1078–1092. https://doi.org/10.1287/mnsc.30.9.1078
Barbero, J., Diukanova, O., Gianelle, C., Salotti, S., & Santoalha, A. (2022). Economic modelling to evaluate smart specialisation: An analysis of research and innovation targets in Southern Europe. Regional Studies, 1–14. https://doi.org/10.1080/00343404.2021.1926959
Bedu, N., & Vanderstocken, A. (2020). Do regional R&D subsidies foster innovative SMEs’ development: Evidence from Aquitaine SMEs. European Planning Studies, 28(8), 1575–1598. https://doi.org/10.1080/09654313.2019.1651828
Belitz, H., & Lejpras, A. (2016). Financing patterns of R&D in small and medium-sized enterprises and the perception of innovation barriers in Germany. Science and Public Policy, 43(2), 245–261. https://doi.org/10.1093/scipol/scv027
Belsley, D. A. (1991). Conditioning diagnostics: Collinearity and weak data in regression (p. 1991). Wiley.
Berkowitz, P., Monfort, P., & Pieńkowski, J. (2019). Unpacking the growth impacts of European Union Cohesion Policy: Transmission channels from Cohesion Policy into economic growth. Regional Studies. https://doi.org/10.1080/00343404.2019.1570491
Bianchi, M., Campodall’Orto, S., Frattini, F., & Vercesi, P. (2010). Enabling open innovation in small-and medium-sized enterprises: How to find alternative applications for your technologies. R&D Management, 40(4), 414–431. https://doi.org/10.1111/j.1467-9310.2010.00613.x
Bouncken, R. B., Fredrich, V., & Kraus, S. (2020). Configurations of firm-level value capture in coopetition. Long Range Planning, 53(1), 101869. https://doi.org/10.1016/j.lrp.2019.02.002
Bukvić, I. B., Babić, I. Ɖ., & Starčević, D. P. (2021). Study on the Utilization of National and EU Funds in Financing Capital Investments of ICT Companies. In 2021 44th International Convention on Information, Communication and Electronic Technology (MIPRO) (pp. 1282–1287). IEEE. https://doi.org/10.23919/MIPRO52101.2021.9597077.
Charnes, A., Cooper, W. W., & Rhodes, E. (1978). Measuring the efficiency of decision-making units. European Journal of Operational Research, 2(6), 429–444. https://doi.org/10.1016/0377-2217(78)90138-8
Dahlander, L., & Gann, D. M. (2010). How open is innovation? Research Policy, 39(6), 699–709. https://doi.org/10.1016/j.respol.2010.01.013
Dakpo, K. H., Desjeux, Y., & Latruffe L. (2022). sfaR: Stochastic Frontier Analysis using R. R Package Version 0.1.1.
Di Comite, F., Lecca, P., Monfort, P., Persyn, D., & Piculescu, V. (2018). The impact of Cohesion Policy 2007–2015 in EU regions: Simulations with the RHOMOLO Interregional Dynamic General Equilibrium Model (No. 03/2018). JRC Working Papers on Territorial Modelling and Analysis. Retrieved April 11, 2022, from https://www.econstor.eu/bitstream/10419/202268/1/jrc-wptma201803.pdf
Diukanova, O., Mandras, G., & Di Comite, F. (2022). Modelling the effects of R&I and low-carbon european structural funds: The case of Apulia, Italy. Scienze Regionali, 21(Speciale), 9–38. https://doi.org/10.14650/103213
Duarte, F. A., Madeira, M. J., Moura, D. C., Carvalho, J., & Moreira, J. R. M. (2017). Barriers to innovation activities as determinants of ongoing activities or abandoned. International Journal of Innovation Science, 9, 244–264. https://doi.org/10.1108/IJIS-01-2017-0006
Durlauf, S. N. (2009). The rise and fall of cross-country growth regressions. History of Political Economy, 41(Suppl_1), 315–333. https://doi.org/10.1215/00182702-2009-030
Fattorini, L., Ghodsi, M., & Rungi, A. (2020). Cohesion policy meets heterogeneous firms. JCMS: Journal of Common Market Studies, 58(4), 803–817. https://doi.org/10.1111/jcms.12989
Fried, H. O., Lovell, C. K., Schmidt, S. S., & Yaisawarng, S. (2002). Accounting for environmental effects and statistical noise in data envelopment analysis. Journal of Productivity Analysis, 17(1), 157–174. https://doi.org/10.1023/A:1013548723393
García-Quevedo, J., Segarra-Blasco, A., & Teruel, M. (2018). Financial constraints and the failure of innovation projects. Technological Forecasting and Social Change, 127, 127–140. https://doi.org/10.1016/j.techfore.2017.05.029
Gardocka-Jałowiec, A., & Wierzbicka, K. (2019). Barriers to creating innovation in the polish economy in the years 2012–2016. Studies in Logic, Grammar and Rhetoric, 59(1). https://doi.org/10.2478/slgr-2019-0038
Gómez-García, J., Enguix, M. D. R. M., & Gómez-Gallego, J. C. (2012). Estimation of the efficiency of structural funds: A parametric and nonparametric approach. Applied Economics, 44(30), 3935–3954. https://doi.org/10.1080/00036846.2011.583224
Gouveia, M. C., Henriques, C. O., & Costa, P. (2021). Evaluating the efficiency of structural funds: An application in the competitiveness of SMEs across different EU beneficiary regions. Omega, 101, 102265. https://doi.org/10.1016/j.omega.2020.102265
Gramillano, A., Celotti, P., Familiari, G., Schuh, B., & Nordstrom, M. (2018). Development of a system of common indicators for European Regional Development Fund and Cohesion Fund interventions after 2020. Study for the DG for Regional and Urban Policy, European Commission. Gen. Reg. Urban Policy Eur. Comm., 10, 279688. Retrieved April 11, 2022, from https://ec.europa.eu/regional_policy/sources/docgener/studies/pdf/indic_post2020/indic_post2020_p2_en.pdf
Gustafsson, A., Tingvall, P. G., & Halvarsson, D. (2020). Subsidy entrepreneurs: An inquiry into firms seeking public grants. Journal of Industry, Competition and Trade, 20(3), 439–478. https://doi.org/10.1007/s10842-019-00317-0
Hammadou, H., Paty, S., & Savona, M. (2014). Strategic interactions in public R&D across European countries: A spatial econometric analysis. Research Policy, 43(7), 1217–1226. https://doi.org/10.1016/j.respol.2014.01.011
Henriques, C., Viseu, C., Neves, M., Amaro, A., Gouveia, M., & Trigo, A. (2022b). How efficiently does the EU support research and innovation in SMEs? Journal of Open Innovation: Technology, Market, and Complexity, 8(2), 92. https://doi.org/10.3390/joitmc8020092
Henriques, C., Viseu, C., Trigo, A., Gouveia, M., & Amaro, A. (202a). How efficient is the cohesion policy in supporting small and mid-sized enterprises in the transition to a low-carbon economy? Sustainability, 14(9), 5317. https://doi.org/10.3390/su14095317
Hervás-Oliver, J. L., Parrilli, M. D., Rodríguez-Pose, A., & Sempere-Ripoll, F. (2021). The drivers of SME innovation in the regions of the EU. Research Policy, 50(9), 104316. https://doi.org/10.1016/j.respol.2021.104316
Hollanders, H. (2021). Regional Innovation Scoreboard 2021. European Commission. https://doi.org/10.2873/674111
Hölzl, W., & Janger, J. (2014). Distance to the frontier and the perception of innovation barriers across European countries. Research Policy, 43(4), 707–725. https://doi.org/10.1016/j.respol.2013.10.001
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An introduction to statistical learning (Vol. 112, p. 18). New York: Springer. https://doi.org/10.1007/978-1-4614-7138-7
Jondrow, J., Lovell, C. K., Materov, I. S., & Schmidt, P. (1982). On the estimation of technical inefficiency in the stochastic frontier production function model. Journal of Econometrics, 19(2–3), 233–238. https://doi.org/10.1016/0304-4076(82)90004-5
Kobarg, S., Stumpf-Wollersheim, J., & Welpe, I. M. (2018). University-industry collaborations and product innovation performance: The moderating effects of absorptive capacity and innovation competencies. The Journal of Technology Transfer, 43(6), 1696–1724. https://doi.org/10.1007/s10961-017-9583-y
Lee, S., Park, G., Yoon, B., & Park, J. (2010). Open innovation in SMEs—An intermediated network model. Research Policy, 39(2), 290–300. https://doi.org/10.1016/j.respol.2009.12.009
Lopez-Rodríguez, J., & Faíña, A. (2014). Rhomolo and other methodologies to assess The European Cohesion Policy. Investigaciones Regionales-Journal of Regional Research, (29), 5–13. Retrieved April 11, 2022, from https://www.redalyc.org/pdf/289/28932224001.pdf
Martinez-Cillero, M., Lawless, M., O’Toole, C., & Slaymaker, R. (2020). Financial frictions and the SME investment gap: New survey evidence for Ireland. Venture Capital, 22(3), 239–259. https://doi.org/10.1080/13691066.2020.1771826
Marzinotto, B. (2012). The growth effects of EU cohesion policy: A meta-analysis (No. 2012/14). Bruegel Working Paper. Retrieved April 12, 2022, from https://www.econstor.eu/bitstream/10419/78011/1/728570688.pdf
Meeusen, W., & van Den Broeck, J. (1977). Efficiency estimation from Cobb-Douglas production functions with composed error. International Economic Review, 435–444. https://doi.org/10.2307/2525757
Müller, J. M., Buliga, O., & Voigt, K. I. (2021). The role of absorptive capacity and innovation strategy in the design of industry 4.0 business Models-A comparison between SMEs and large enterprises. European Management Journal, 39(3), 333–343. https://doi.org/10.1016/j.emj.2020.01.002
Neto, P., & Santos, A. (2020). Guidelines for territorial impact assessment applied to regional research and innovation strategies for smart specialisation. In Territorial Impact Assessment (pp. 211–230). Springer. https://doi.org/10.1007/978-3-030-54502-4_12
Ortiz, R., & Fernandez, V. (2022). Business perception of obstacles to innovate: Evidence from Chile with pseudo-panel data analysis. Research in International Business and Finance, 59, 101563. https://doi.org/10.1016/j.ribaf.2021.101563
R Core Team. (2021). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. Retrieved from https://www.R-project.org
Radicic, D., & Pugh, G. (2017). R&D programmes, policy mix, and the ‘European paradox’: Evidence from European SMEs. Science and Public Policy, 44(4), 497–512. https://doi.org/10.1093/scipol/scw077
Rajalo, S., & Vadi, M. (2017). University-industry innovation collaboration: Reconceptualization. Technovation, 62–63, 42–54. https://doi.org/10.1016/j.technovation.2017.04.003
Rodríguez-Pose, A., & Wilkie, C. (2019). Innovating in less developed regions: What drives patenting in the lagging regions of Europe and North America. Growth and Change, 50(1), 4–37. https://doi.org/10.1111/grow.12280
Romero-Martínez, A. M., Fernández-Rodríguez, Z., & Vázquez-Inchausti, E. (2010). Exploring corporate entrepreneurship in privatized firms. Journal of World Business, 45(1), 2–8. https://doi.org/10.1016/j.jwb.2009.04.008
Santos, A., Cincera, M., Neto, P., & Serrano, M. M. (2019). Which projects are selected for an innovation subsidy? The Portuguese case. Portuguese Economic Journal, 18(3), 165–202. https://doi.org/10.1007/s10258-019-00159-y
Sein, Y. Y., & Prokop, V. (2021). Mediating role of firm R&D in creating product and process innovation: Empirical evidence from Norway. Economies, 9(2), 56. https://doi.org/10.3390/economies9020056
Stojčić, N., Srhoj, S., & Coad, A. (2020). Innovation procurement as capability-building: Evaluating innovation policies in eight Central and Eastern European countries. European Economic Review, 121, 103330. https://doi.org/10.1016/j.euroecorev.2019.103330
Thum-Thysen, A., Voigt, P., Bilbao-Osorio, B., Maier, C., & Ognyanova, D. (2019). Investment dynamics in Europe: Distinct drivers and barriers for investing in intangible versus tangible assets? Structural Change and Economic Dynamics, 51, 77–88. https://doi.org/10.1016/j.strueco.2019.06.010
Tone, K., & Tsutsui, M. (2009). Tuning regression results for use in multi-stage data adjustment approach of DEA (<Special Issue> Operations Research for Performance Evaluation). Journal of the Operations Research Society of Japan, 52(2), 76–85. https://doi.org/10.15807/jorsj.52.76
Tone, K. (2001). A slacks-based measure of efficiency in data envelopment analysis. European Journal of Operational Research, 130(3), 498–509. https://doi.org/10.1016/S0377-2217(99)00407-5
Tone, K. (2002). A slacks-based measure of super-efficiency in data envelopment analysis. European Journal of Operational Research, 143(1), 32–41. https://doi.org/10.1016/S0377-2217(01)00324-1
Van de Vrande, V., De Jong, J. P., Vanhaverbeke, W., & De Rochemont, M. (2009). Open innovation in SMEs: Trends, motives and management challenges. Technovation, 29(6–7), 423–437. https://doi.org/10.1016/j.technovation.2008.10.001
Wostner, P., & Šlander, S. (2009). The effectiveness of EU cohesion policy revisited: are EU funds really additional? University of Strathclyde. Retrieved April 12, 2022, from https://strathprints.strath.ac.uk/70313/1/EPRP_69.pdf
Zhou, X., Rasool, S. F., Yang, J., & Asghar, M. Z. (2021). Exploring the relationship between despotic leadership and job satisfaction: The role of self-efficacy and leader–member exchange. International Journal of Environmental Research and Public Health, 18(10), 5307. https://doi.org/10.3390/ijerph18105307
Zimmermann, V., & Thomä, J. (2016). SMEs face a wide range of barriers to innovation-support policy needs to be broad-based. KfW Research Focus on Economics, 130, 1–8.
Acknowledgements
This work has been funded by European Regional Development Fund in the framework of Portugal 2020—Programa Operacional Assistência Técnica (POAT 2020), under project POAT-01-6177-FEDER-000044 ADEPT: Avaliação de Políticas de Intervenção Co-financiadas em Empresas. INESC Coimbra and CeBER are supported by the Portuguese Foundation for Science and Technology funds through Projects UID/MULTI/00308/2020 and UIDB/05037/2020, respectively.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this paper

Cite this paper
Henriques, C., Viseu, C. (2023). Evaluating the Reasons Behind the Inefficient Implementation of ERDF Devoted to R&I in SMEs. In: Henriques, C., Viseu, C. (eds) EU Cohesion Policy Implementation - Evaluation Challenges and Opportunities. EvEUCoP 2022. Springer Proceedings in Political Science and International Relations. Springer, Cham. https://doi.org/10.1007/978-3-031-18161-0_1
Download citation
DOI: https://doi.org/10.1007/978-3-031-18161-0_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-18160-3
Online ISBN: 978-3-031-18161-0
eBook Packages: Political Science and International StudiesPolitical Science and International Studies (R0)