
Abstract
In an Industrie 4.0 (I4.0), rigid structures and architectures applied in manufacturing and industrial information technologies today will be replaced by highly dynamic and self-organizing networks. Today’s proprietary technical systems lead to strictly defined engineering processes and value chains. Interacting Digital Twins (DTs) are considered an enabling technology that could help increase flexibility based on semantically enriched information. Nevertheless, for interacting DTs to become a reality, their implementation should be based on open standards for information modeling and application programming interfaces like the Asset Administration Shell (AAS). Additionally, DT platforms could accelerate development and deployment of DTs and ensure their resilient operation.
This chapter develops a suitable architecture for such a DT platform for I4.0 based on user stories, requirements, and a time series messaging experiment. An architecture based on microservices patterns is identified as the best fit. As an additional result, time series data should not be integrated synchronously and directly into AASs, but rather asynchronously, either via streams or time series databases. The developed DT platform for I4.0 is composed of specialized, independent, loosely coupled microservices interacting use case specifically either syn- or asynchronously. It can be structured into four layers: continuous deployment, shop-floor, data infrastructure, and business services layer. An evaluation is carried out based on the DT controlled manufacturing scenario: AAS-based DTs of products and manufacturing resources organize manufacturing by forming highly dynamic and self-organizing networks.
Future work should focus on a final, complete AAS integration into the data infrastructure layer, just like it is already implemented on the shop-floor and business services layers. Since with the standardized AAS only one interface type would then be left in the DT platform for I4.0, DT interaction, adaptability, and autonomy could be improved even further. In order to become part of an I4.0 data space, the DT platform for I4.0 should support global discovery, data sovereignty, compliance, identity, and trust. For this purpose, Gaia-X Federation Services should be implemented, e.g., as cross-company connectors.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others



Keywords
- Industrie 4.0
- Digital Twin
- Asset Administration Shell
- Platform
- Microservices patterns
- Interprocess communication
- Time series
- Industrie 4.0 data space
- Industrial data economy
- Gaia-X
- Digital Twin controlled manufacturing
- Collaborative condition monitoring
1 Introduction
In this day and age, increasing manufacturing productivity and sustainability faces challenges regarding interoperability and scalability of technical systems [1, 2]. The rigid operational technology (OT) and information technology (IT) architectures widely used today lead to the establishment of equally inflexible value chains and prevent the implementation of highly dynamic and globally connected value networks that could enable new forms of collaboration and business models [3]. It is the vision of Industrie 4.0 (I4.0) to enable this implementation through the establishment of standards, which should be implemented based on highly scalable and sovereign data infrastructure as an environment of trust and the basis for a global I4.0 data space [4, 5]. Major standards evolving in the German initiative “Plattform Industrie 4.0” currently focus on the implementation of one main technological concept that should foster semantic interoperability and autonomy of technical systems: a Digital Twin (DT) for I4.0 [6, 7]. Benefits expected from the DT for I4.0 include efficient re-configuration of production lines and machines for mass customization in application scenarios like “plug-and-produce” or “order-controlled production,” as well as cross-company collaboration across value chains and life cycle stages in order to optimize products and production processes [8,9,10,11,12,13,14,15].
The Reference Architecture Model Industrie 4.0 (RAMI 4.0) includes the concept of an I4.0 component, consisting of asset and Asset Administration Shell (AAS) [16]. The AAS concept “helps implement Digital Twins for I4.0 and create interoperability across the solutions of different suppliers” [17]. The AAS specifies a meta information model for I4.0 that is based on properties standardized according to IEC 61360 [9, 18, 19]. Property specifications in dictionaries like the IEC Common Data Dictionary include formalized semantic descriptions and are an important step toward unambiguous and automatic interpretation of knowledge by I4.0 components [20]. The AAS meta information model is being standardized as IEC 63278 ED1, and first mappings of the meta model to specific technologies, e.g., to the OPC Unified Architecture (OPC UA), exist [21, 22]. In addition to the information model, the first infrastructure components for AAS are being developed as well, e.g., a registry for AAS and runtime environments based on different programming frameworks [23, 24]. AAS services executed in such an environment exchange information via a specified application programming interface (API) or they interact autonomously via a specified language for I4.0 [25, 26]. Additional I4.0 software components and services will be developed within the Industrial Digital Twin Association (IDTA) [27].
This chapter relates to the technical priorities “data management,” “data processing architectures,” “Big Data standardization,” and “engineering and DevOps for Big Data” of the European Big Data Value Strategic Research and Innovation Agenda [28]: It addresses the horizontal concern “IoT, CPS, Edge, and Fog Computing” of the BDV Technical Reference Model as well as the vertical concerns “standards” and “industrial data platforms.” Also, the chapter relates to the “systems, methodologies, hardware, and tools” and “action and interaction” enablers of the AI, Data, and Robotics Strategic Research, Innovation, and Deployment Agenda [29].
Accelerating the development, deployment, and resilient operation of DTs by developing the foundation for a DT platform for I4.0 is the main objective of this chapter. To this end, Sect. 2 presents the user stories of platform architect, chief financial officer, platform operator, manufacturing manager, and data scientist. They all share the vision of I4.0, but face individual challenges leading to specific requirements. Section 3 takes these requirements into account and introduces generic patterns for architectural style and interprocess communication. A time series messaging experiment is conducted in order to evaluate architectural styles and synchronous as well as asynchronous communication paradigms and their applicability for different use cases, for example, DT interaction and time series processing.
Section 4 then proposes a DT platform for I4.0, which is composed of specialized, independent, loosely coupled services and structured into four layers: continuous deployment, shop-floor, data infrastructure, and business services. Finally, Sect. 5 demonstrates how DTs of products to be manufactured and manufacturing resources executed on the proposed DT platform for I4.0 can autonomously organize manufacturing by forming highly dynamic and self-organizing networks. The DT of a product instance, for example, comprises, as a passive part, all its AASs and data contained in the platform related to the product instance and, as an active part, those business services executing services for the specific product instance. It actively takes decisions and interacts with the DTs of the manufacturing resources aiming at an efficient manufacturing of the product instance it represents.
2 User Stories
This section presents user stories describing the functionality the Digital Twin platform for Industrie 4.0 shall provide from the perspective of platform architect, chief financial officer, platform operator, manufacturing manager, and data scientist. What they have in common is that they want to implement Industrie 4.0.
Industrie 4.0 community | |
I40C-S 1 | Industrie 4.0 |
We want to use the platform to implement Industrie 4.0, in which assets across all hierarchy levels of the former automation pyramid and beyond interact autonomously in an Industrie 4.0 environment and data space in order to enable higher efficiency, flexibility, and new data-driven business models |
As a platform architect, my user stories consider encapsulated applications, data transport, storage, sovereignty and discovery, the discovery of services, and the provision of guidelines for development, integration, and consumption of services.
Platform architect | |
PA-S 1 | Security |
I want the platform to be secure regarding authentication, authorization, and communication as well as integrity, confidentiality, and availability of data | |
PA-S 2 | Encapsulated applications |
I want the platform to use and reuse encapsulated applications that run isolated and that are scalable and effortlessly maintainable | |
PA-S 3 | Data transport |
I want data transported efficiently from, into, and within the platform | |
PA-S 4 | Data storage |
I want the platform to be able to store any kind of data generated either within or outside of the platform | |
PA-S 5 | Data sovereignty |
I want the platform to guarantee sovereignty over data to the respective data provider | |
PA-S 6 | Data and service discovery |
I want the platform to provide a discovery interface providing semantic descriptions and endpoints of any data and service available in the platform, so that data and services can be discovered easily | |
PA-S 7 | Guidelines |
I want the platform to provide an extensive instruction to develop, integrate (also third-party software), or consume services |
My concern as chief financial officer is of course the platform’s ROI.
Chief financial officer | |
CFO-S 1 | Return on investment |
I want the platform to run cost efficiently, increasing the company’s competitiveness |
As a platform operator, the platform shall be easily maintainable, and the software shall be of high quality and scalable.
Platform operator | |
PO-S 1 | Platform management |
I want the platform to be effortlessly maintainable, flexibly manageable, and well-organized | |
PO-S 2 | Service quality |
I want the platform to integrate and offer solely high-quality software guaranteeing effectiveness, efficiency, and reliability | |
PO-S 3 | Service scalability |
I want to be able to offer data portal services to at least 100 data scientists in parallel without performance losses, in order to prevent customer complaints or denial of service |
As a manufacturing manager, I need a dashboard, and, in the spirit of Industrie 4.0, I want the Digital Twins to control the manufacturing. Furthermore, I appreciate easy design and integration of Digital Twins and semantic descriptions.
Manufacturing manager | |
MM-S 1 | Semantics |
I want the platform to suggest semantic identifications based on free-text descriptions or, if not available, to create and publish them automatically in a repository | |
MM-S 2 | Digital Twin design |
I want the design, storage, and deployment of Digital Twins to be effortless | |
MM-S 3 | Digital Twin decision making |
I want Digital Twins of products and manufacturing resources to interact and autonomously make arrangements for their assets | |
MM-S 4 | Digital Twin asset control |
I want a Digital Twin to have sovereignty over the assignment of tasks to the asset it represents | |
MM-S 5 | Digital Twin documentation |
I want Digital Twins of products and manufacturing resources to document manufacturing progresses and the acquisition and execution of assignments | |
MM-S 6 | Dashboard |
I want the manufacturing performance to be evaluated in real time and visualized in a dashboard: at present or at a specific time in the past or future |
As a data scientist, I value capable data portals simplifying data engineering
Data scientist | |
DS-S 1 | Data portal |
I want to efficiently search for, browse, download, annotate, and upload process data and metadata via a standardized (web-)interface and information model, saving time for data analysis |
3 Architectural Style and Interprocess Communication
In Industrie 4.0, assets across all hierarchy levels of the former automation pyramid and beyond interact in order to enable higher efficiency, flexibility, and new data-driven business models. To this end any asset, which according to [16] is any object of value for an organization, is equipped with an Asset Administration Shell (AAS, [16, 19, 25]). The AAS is the core technology for the implementation of I4.0-compliant Digital Twins, i.e., comprising semantically enriched asset descriptions. Both asset and AAS must be globally uniquely identifiable. Together, they constitute an I4.0 component that can become part of an I4.0 system.
I4.0 components can call for and provide services and data. Since supply and demand of the union of all assets will never be constant, I4.0 systems dynamically evolve over time: Digital and physical assets are added, adapted, or removed. Therefore, it seems worth to consider the following two key questions:
-
1.
Which software architecture is best suited for a dynamic DT platform for I4.0?
-
2.
Which communication technologies are appropriate to address the requirements from Sect. 2 like data transport efficiency?
3.1 Architectural Style
According to [30] an architectural style is “formulated in terms of components, the way that components are connected to each other, the data exchanged between components, and finally how these elements are jointly configured into a system.”
Since the DT platform for I4.0 will contain highly distributed and frequently changing components, a monolithic approach, in which components are only logically separated and structured as a single deployable unit [30, 31], is practically impossible. Furthermore, the expected high complexity of the platform, the typically long development and deployment cycles of a monolith, and its limited scalability argue against a monolithic approach.
For distributed systems layered, object-based, data-centered, event-based, and microservice architectures are the most important styles [30, 31]. In a layered architecture, only services of underlying layers can be requested directly via Service Access Points (SAP) [30,31,32]. Since this is in a diametrical opposition to the core idea of I4.0 about the equality of assets and self-organizing networks, the layered architectural style is inept.
In the object-based architecture “components are connected through a (remote) procedure call mechanism,” and data-centered architectures “evolve around the idea that processes communicate through a common (passive or active) repository,” and in event-based architectures “processes essentially communicate through the propagation of events, which optionally also carry data” [30]. In [31] these three styles are combined in a microservice architecture, where “the components are services, and the connectors are the communication protocols that enable those services to collaborate.” “Each service has its own logical view architecture, which is typically a hexagonal architecture” placing “the business logic at the center” and using inbound adapters to “handle requests from the outside by invoking the business logic” and outbound controllers “that are invoked by the business logic and invoke external applications” [31].
For the DT platform for I4.0, significant examples, as depicted in Fig. 1, for inbound adapters would be controllers implementing sets of HTTP/REST (Hypertext Transfer Protocol/Representational State Transfer) or OPC Unified Architecture (OPC UA) endpoints or message broker clients consuming messages of broker topics. On the other hand, major examples for outbound adapters would be data access objects implementing operations to access databases, message broker clients producing messages in broker topics, and service triggers invoking external applications via their HTTP/REST or OPC UA endpoints.

Most significant adapters of shop-floor resources and their Digital Twins in the Digital Twin platform for Industrie 4.0: Inbound adapters are indicated by white rectangles and dark gray rectangles mark outbound adapters. An outbound adapter of component A invokes the business logic of component B by connecting and sending information to B’s inbound adapter. Shop-floor resources and their Digital Twins either interact directly and synchronously via OPC UA or HTTP/REST for Asset Administration Shell (AAS) or indirectly and asynchronously using a message broker as intermediary. Generic OPC UA and message broker clients stream time series data from shop-floor resources via the message broker into databases and Digital Twins
A microservice “is a standalone, independently deployable software component that implements some useful functionality” [31]. Services “have their own datastore and communicate only via APIs” (Application Programming Interfaces), which consist of commands and queries: “A command performs actions and updates data,” and on the other hand “a query retrieves data” [31]. A microservice architecture “functionally decomposes an application into a set of services” enabling “continuous delivery and deployment of applications” and “easily maintainable, independently deployable, and scalable services,” and allows “easy experimenting and adoption of new technologies” [31].
The most significant benefits of the microservice architecture concur with the primary architectural and operational requirements of the DT platform for I4.0: PA-S 2 (“encapsulated applications”) and PO-S 1–3 (“platform management,” “service quality,” and “service scalability”). Consequently, the platform will be developed based upon a microservice architecture.
3.2 Interprocess Communication
In a microservice architecture, in which services address specific challenges, services must collaborate to achieve an overall objective. Suitable interservice or rather interprocess communication (IPC) technologies depend on the use case at hand. According to [31] the various styles can be categorized into two dimensions:
-
One to one/directly vs. one to many/indirectly: Each request is processed by either exactly one vs. many services.
-
Synchronous vs. Asynchronous: A service either expects a timely response from another service and might even block while it waits vs. a service does not block, and the response, if any, is not necessarily sent immediately.
Within the I4.0 community certain technologies and systems promise to become major standards and should be taken into account.
-
Services of shop-floor machines can be invoked by OPC UA, via which the machines also provide data access. OPC UA provides a service-oriented architecture, consisting of several features like security, communication, and information model. In OPC UA the communication is either organized according to the client/server or publish/subscribe paradigm. Clients can establish a connection to a server and interact with its information model, e.g., to read/write data or call methods. Subscribers can subscribe to certain information model elements, e.g., published cyclically by a corresponding publisher.
-
The bidding procedure [26, 33] standardizes interactions between I4.0 components bringing together providers and users of physical shop-floor services: These standardized messages are exchanged in a standardized sequence via MQTT [34].
-
Server applications host AASs that can be accessed via HTTP/REST- or OPC UA-APIs [24, 25, 35]. REST operates on textual represented resources, e.g., JavaScript Object Notation (JSON) or Extensible Markup Language (XML). Within the I4.0 community the AAS meta model is typically represented in such a format [19, 25].
-
The AAS meta model standardizes the invocation of operations or services of the administered asset, i.e., the “executable realization of a function,” which can, e.g., be shop-floor or IT services [19]. While, according to [25], an AAS server’s resources can only be manipulated synchronously, operations can also be invoked asynchronously using an operation handle to retrieve the results.
The previous considerations lead to additional requirements for the DT platform for I4.0: An MQTT message broker shall be provided and services of I4.0 components shall be invoked via AAS-APIs of AAS servers (see Fig. 1), either synchronously or asynchronously. AAS or asset data shall be manipulated and queried synchronously.
3.3 Time Series Integration
Data is produced continuously by the assets within the platform, e.g., during operation of shop-floor machines or IT services. In general, an AAS is supposed to be the virtual representation of an asset and consequently would have to contain all asset data. To a certain degree it might be feasible to integrate time series data into an asset’s AAS directly. However, there is reasonable doubt that Big Data is manageable in such a structure. As mentioned above, adding data to an AAS in a server has to be done synchronously. Considering that an asset could produce data in nanosecond intervals, it seems unfeasible to integrate it synchronously. Besides this, an AAS server’s capacity and performance objectives limit the amount of data that can be integrated: How to deal with unbounded time series data?
For this time series use case asynchronous messaging suits best. A message is a container for data “in either text or binary format” and “metadata that describes the data being sent,” such as “a unique message id” or “an optional return address, which specifies the message channel that a reply should be written to” [31].
Messages are exchanged over channels: point-to-point or publish-subscribe. “A point-to-point channel delivers a message to exactly one of the consumers that is reading from the channel. Services use point-to-point channels for the one-to-one interaction styles” [31], like the invocation of operations. On the other hand, a “publish-subscribe channel delivers each message to all of the attached consumers. Services use publish-subscribe channels for the one-to-many interaction styles” [31].
Publish-subscribe messaging enables decoupling of publisher and subscriber in three dimensions: time, space, and synchronicity [36]. Consequently, publisher and subscriber do not need to know each other, do not have to be active at the same time, and do not have to block.
In particular, publish-subscribe channels are suitable for the time series use case. For example, a shop-floor machine might produce drinking cups. One quality requirement might be that the injection molding temperature during production is continuously within a given temperature range. Sensors in the machine measure temperature in nanosecond intervals and publish the time series data to a publish-subscribe channel. Why one-to-many interaction? Because there is most likely more than one consumer service:
-
A service integrating the data into a time series database for persistence
-
A service monitoring the condition of the machine
-
A service deciding whether or not a specific drinking cup meets the quality requirements or must be sorted out
Consequently, in the DT platform for I4.0, Big Data and time series will be exchanged via asynchronous messaging. Endpoints for retrieving the data from a channel or a time series database are added to the AASs of the assets generating the data. The results of the following time series messaging experiment substantiate the previous argumentation.
3.4 Time Series Messaging Experiment
Let us assume that energy consumption data is recorded in second intervals in order to determine peak loads of a machine consuming up to 1 kW power. During an 8-h shift a sensor produces 28,800 records, each consisting of a measurement (the data type is double in the range from 0 to 1000 with 1 digit) and a timestamp (the format is unix timestamp in seconds). The peak loads are defined as the greatest one percent of measurements.
In seven setups the time it took to read the data from the source and to determine the peak loads was measured. In line with the previous considerations regarding architectural styles and interprocess communication schemes, these setups are entitled as:
-
[Monolith] a monolithic approach, in which a software program decodes a compressed file (AASX package format, [19]), deserializes the content as in-memory object, and queries the object, where the file contains an AAS with only one submodel containing:
-
[-SMC] per record a submodel element collection consisting of two properties: the record’s measurement and timestamp
-
[-Array] just two properties: arrays of the measurements and timestamps
-
-
[Micro] a microservice architecture
-
[-Sync] with synchronous one-to-one communication, in which a software program requests from an HTTP-API server a submodel, deserializes the JSON as in-memory object, and queries the object, where the submodel is equal:
-
[-SMC] to the submodel of case Monolith-SMC
-
[-Array] to the submodel of case Monolith-Array
-
-
[-Async] with asynchronous one-to-many communication, in which a software program:
-
[-Stream] consumes a data stream containing the records and queries the records in-memory
-
[-TSDB-ext] extracts the records from a time series database and queries the records in-memory
-
[-TSDB-int] applies a built-in function of a time series database to query the records
-
-
Table 1 specifies the sizes of the consumed data in the seven setups. This data is consumed, decoded, and deserialized by a software program before the peak load determination begins. For the Monolith setups the data is provided in files, embedded in serialized AAS meta models, and compressed as AASX package format with JSON: In the SMC case the file’s size is 672 kB and 139 kB in the Array case. The HTTP-API server in the SMC case returns a JSON of size 19,448 kB and of size 757 kB in the Array case. Please note that the significant difference in sizes of Array and SMC cases results from the duplication of metadata in the SMC cases: Each property containing a measurement or timestamp also contains metadata.
In the Micro-Async-Stream setup data of size 1266 kB is consumed from Apache Kafka [37], and in the case of Micro-Async-TSDB-ext, the consumed data from InfluxDB [38] sizes up to 157 kB. For the execution of Micro-Async-TSDB-int no data must be consumed by an external software program, since InfluxDB determines the peak load internally.
The experiment was executed 1000 times per setup by a computer with an 11th Gen Intel(R) Core(TM) i7-1165G7 processor, 32 GB LPDDR4x 4267 MHz memory, and a 64-bit system architecture. To perform the experiment as close as possible to laboratory conditions, this one computer processed the setups one after the other and ran all their components. It was ensured that no disturbing other network or data traffic biased the results and garbage collection was executed before each iteration. Times were measured in microseconds, separately for data reading (consuming, decoding, deserializing) and top percentile determination. The client software programs executed highly optimized built-in C# and Python functions to determine the top percentile without performance losses, i.e., a built-in function from C# in the case of the Monolith and Micro-Sync setups and Python in the case of the external Micro-Async setups.
Figure 2 and Table 2 display the runtime results. What must be considered is that in the case of setup Micro-Async-TSDB-int, the time could only be measured for the complete process. By far, this setup achieved the best runtime results.

Boxplots displaying the time it took to read the energy consumption data and determine the peak loads in the seven setups of the time series messaging experiment. Each setup was executed 1000 times. The light gray boxplot figures the reading data part runtime results of a setup, in dark gray the runtime results of the peak load determination, and black displays the complete process runtime results. Lower resp. upper whisker represent the minimum resp. maximum of the measurements. In the case of setup Micro-Async-TSDB-int, the time could only be measured for the complete process
In the other six setups the peak load determination runtimes are approximately on the same low level. The runtimes of their complete processes are, however, dominated by the reading parts, in which their runtimes differ considerably. Surprisingly, Monolith-Array and Micro-Sync-Array are significantly faster than, in ascending order, Micro-Async-TSDB-ext, Micro-Async-Stream, Monolith-SMC, and Micro-Sync-SMC. As the sizes of the consumed data sources could suggest, Monolith-SMC and Micro-Sync-SMC performed worst.
In each run of the Monolith setups a compressed AASX file is decoded and its content is deserialized as in-memory object before the peak load determination begins. The file in the Array case is approximately five times smaller than in the SMC case; reading, however, is on average even approximately 28 times faster. Similar observations can be made for the Micro-Sync setups: While the size in the Array case is approximately 26 times smaller than in the SMC case, reading is on average approximately 53 times faster. For reasons of efficiency, time series data should therefore, if actually stored directly in AASs, be highly compressed avoiding duplication of metadata.
Please note that except for the Monolith setups, data provider and consumer in I4.0 are usually executed on separate machines connected via a network. Consequently, time losses at network layer would most likely extend the reading runtimes of the Micro setups.
The payload in the Micro-Sync setups could be compressed, as it is standardized for HTTP, so that the consuming runtime would decrease. Additionally, an HTTP-API server could provide server-side execution of queries, as is typically done by databases like in the Micro-Async-TSDB-int setup. So far, though, such services are not implemented for the AAS meta model.
A monolithic architecture in general and a microservice architecture with synchronous messaging are, due to the requirements of Sect. 2 and as deduced in the previous subsections, not eligible for the DT platform for I4.0 and highly dynamic interprocess communication. However, the runtime results show that such constructs are suitable for end-user applications aggregating, for example, in low-frequency data from AASs in the platform for reporting or documentation purposes.
The competitive runtime results in the three Micro-Async setups, with either data stream or time series database, justify the decision to integrate and consume Big Data or time series via asynchronous messaging in the Digital Twin platform for Industrie 4.0.
4 A Digital Twin Platform for Industrie 4.0
The Digital Twin platform for Industrie 4.0 (DT platform for i4.0) is based on the architectural deductions from Sect. 3 and meets the user requirements formulated in Sect. 2. It facilitates efficient development, deployment, and operation of I4.0 business services (user stories PA-S 2 and PA-S 7: “encapsulated applications” and “guidelines”). To account for scalability, robustness, performance, maintainability, and security (user stories PA-S 1 and PO-S 1–3: “security,” “platform management,” “service quality,” and “service scalability”), I4.0 business services are implemented based on a set of data infrastructure microservices, e.g., for discovery, connectivity, synchronicity, and storage.
A continuous development and integration pipeline facilitates the release of robust microservices that are deployed to and orchestrated by a Kubernetes cluster as a backbone of the DT platform for I4.0 [39]. The main features of the cluster include load balancing and fault management, e.g., by scaling and restarting service instances automatically. Moreover, the operational phase of the platform is supported by monitoring and logdata collection services. Here, Fluentd collects logs and ingests them in Elasticsearch, a scalable search and analytics suite [40,41,42].
Figure 3 depicts the platform’s architecture comprising the following four layers:
-
Business Services Layer: As value-added services, I4.0 services are located on the business services layer of the platform, utilizing the data infrastructure microservices on the layer below. I4.0 services are accessible and interact via an API (application programming interface). Additionally, the data portal provides a graphical user interface (GUI).
Fig. 3 
A Digital Twin platform for Industrie 4.0. It is composed of specialized, independent, loosely coupled services structured into four layers: continuous deployment, shop-floor, data infrastructure, and business services layer. Connectors enable cross-company collaboration
-
Data Infrastructure Layer: The data infrastructure layer contains the microservices supporting the business services layer. They are accessible via an API and some of them are interacting. These services are implemented as generic as possible.
-
Shop-Floor Layer: The shop-floor layer contains each component, machine, and manufacturing facility on the physical shop-floor. Each of them is equipped with an OPC UA server.
-
Continuous Deployment Layer: The continuous deployment (CD) layer holds the base software for a continuous deployment of microservices into the data infrastructure and business services layers.

Furthermore, the platform comprises two components crossing these layers:
-
A Kubernetes cluster orchestrates and monitors the microservices in the data infrastructure and business services layers.
-
Cross-company connectors enable cross-company access to all four layers of the platform and can connect to the platforms of collaborating business partners.
The following subsections describe the CD, data infrastructure, and business services layer in detail and discuss how the platform will become part of an I4.0 data space. A deeper insight into the interoperation of business and data infrastructure microservices and the shop-floor assets will follow in Sect. 5.
4.1 The Continuous Deployment Layer
The CD layer contains a pipeline based on GitLab, a container registry, and Kubernetes [43, 44]. Through this pipeline new versions of microservices are developed, tested, built, tagged, registered, and deployed to either the data infrastructure or business services layer of the platform. For each microservice a separate GitLab project exists. Triggered by developments in these GitLab projects, the CD pipeline performs the following tasks [43]:
-
Build: Following an update to a project’s master branch, a container image is built. In particular, the master branch contains the corresponding container configuration file providing all necessary settings. Each new image is tagged with a version number and registered in the GitLab container registry.
-
Deployment: As soon as an updated container image is registered in the registry, the corresponding containerized microservice in the data infrastructure or business services layer is also updated by the deployment service.
4.2 The Data Infrastructure Layer
The data infrastructure layer contains the microservices that support the I4.0 business services. The knowledge base is a document-based database storing all relevant metadata of known AAS (Asset Administration Shell) and OPC UA servers as JSON (JavaScript Object Notation) in a predefined mapping (user stories PA-S 6, MM-S 1, and DS-S 1: “data and service discovery,” “semantics,” and “data portal”). Here, Elasticsearch is used [41]. Furthermore, the knowledge base contains semantic descriptions of the data contained in the platform. A free-text search can be used to find information relevant for the use case at hand. Please find more metadata and knowledge-specific orchestration details in [45, 46].
Data from AAS, in particular submodel templates, as the usual semantic description of submodel instances, as well as those descriptions of semantic identifications of submodel elements that had to be defined manually since no public repository contained proper descriptions, are included in the knowledge base. Parts of this database are accessible from the Internet, so that the authorized partners can, for example, find semantic descriptions for the submodels and elements contained in AASs shared with them.
To ensure that the available data is always in sync, the OPC UA Local Discovery Service (LDS) automatically discovers each available OPC UA server in the edge-cloud ecosystem. Some assets hosting a local OPC UA server, e.g., on a programmable logic controller (PLC), possess additional AASs in AAS servers in the cloud that provide corresponding metadata. In such a case, the knowledge synchronizer service is responsible for linking and collecting AASs and OPC UA servers or rather metadata and data sources and storing them in the knowledge base.
In the case that an asset is equipped with an OPC UA server but not yet with an AAS, neither locally in its OPC UA server nor in the cloud, an OPC UA AAS aggregation server automatically migrates the asset server’s information model to the OPC UA companion specification for AAS and serves it [22, 47]. Consequently, the OPC UA AAS aggregation server ensures that all assets with an OPC UA server possess at least one AAS.
AAS servers like [23, 24] with an HTTP/REST- or an OPC UA-CRUD-API (create, read, update, delete) host AASs in the intranet. AAS and submodel registries contain descriptors of AASs and submodels [25]. Each descriptor includes at least identification and endpoint of either AAS or submodel.
An MQTT broker is used for the execution of the bidding procedure for I4.0 [26, 33]. This procedure standardizes the interactions between I4.0 components and brings together providers and requesters of physical manufacturing services, e.g., drilling, transportation, or storage.
On request, the data and service portal on the business services layer establishes or cuts off Apache Kafka data streams (user story PA-S 3: “data transport”) [37] from, e.g., OPC UA or AAS servers to the data lake, to the business microservices, or to the cross-company connectors. To this end generic OPC UA and Kafka clients are instantiated and deployed. Fieldbus protocols can be integrated using, e.g., Internet of Things (IoT) gateways.
The data lake contains databases for any kind of (raw) data (user story PA-S 4: “data storage”): structured like rows and columns in a relational database, semi-structured like JSON, or unstructured like files. Due to the knowledge base, the search for process and metadata in streams and lake is quick and efficient. Via the connectors to cross-company data-sharing systems, data can be exchanged and collaboratively enriched with, e.g., partners in a value-adding chain, where data sovereignty (user stories PA-S 1 and 5: “security” and “data sovereignty”) is ensured. Please find use case-specific details in Sect. 5.
4.3 The Business Services Layer
The business services layer finally contains the I4.0 business microservices. For example, the data and service portal enable a user to search—freely or using tags—for relevant data and its sources in the platform (user stories PA-S 6 and DS-S 1: “data and service discovery” and “data portal”), including AAS and OPC UA servers, data streams, and lake. The portal provides suitable results and optionally, as mentioned before, sets up data pipelines from selected sources. Please find a detailed description in [45].
Within the data and service portal AASs for assets and dashboards, aggregating data can be designed (user stories MM-S 2 and 6: “Digital Twin design” and “dashboard”). Furthermore, the portal shows the user which Artificial Intelligence (AI) services could be applied to which shop-floor assets, e.g., anomaly detection for conveyor belt drives. For this purpose, the portal automatically matches the semantic identifications of the offered data of a shop-floor asset and the required data of an AI service [15]. Subsequent to the user’s design of an AAS or dashboard or the selection of an AI service for a shop-floor asset, the portal deploys the new I4.0 component and sets up necessary data streams from shop-floor asset to AI service and back.
4.4 The Cross-Company Connectors
The DT platform for I4.0 enables cross-company data and service access by adding connector components which cross all four platform layers vertically.
In addition to the obvious need for extended security, e.g., regarding authentication and access control, a cross-company collaboration requires additional solutions, such as a global and well-known AAS registry that synchronizes with the company’s internal registries. Strict firewall rules and sub-networks that cannot be reached from the outside make it impossible to establish a connection to the dedicated AAS-API endpoints. Inevitably, such a connector must not only carry the registry to the outside but also establish a kind of AAS gateway at the same time.
Gaia-X [5] anticipates many of these challenges to build a trustful environment, e.g., an I4.0 data space to leverage industrial data economy. The use case “collaborative condition monitoring” (CCM), for example, describes a shift from a bilateral data exchange to a multilateral relationship [48]. The leading idea is that by sharing and using data in a collaborative way, insights can be gained and thus processes and products can be optimized. In Fig. 4 three potential stakeholders of such a use case are depicted: a component supplier, a machine integrator, and a manufacturer, who operates the integrators’ machines.

The three-point fractal sketches the minimum of a multilateral data exchange
Please find a detailed description in [14] on how the DT platform for I4.0 can be used for CCM. The paper addresses the challenges of interoperability, self-describing and managed data flow, authorization and access control, authentication, and usage control. In perspective, the DT platform for I4.0 shall become part of an I4.0 data space based on the Federation Services of the European cloud initiative Gaia-X.
5 Digital Twin Controlled Manufacturing
The DT Platform for I4.0 presented in Sect. 4 facilitates the implementation of the main application scenarios for I4.0: mass customization, the resulting need for increased autonomy of manufacturing execution services. Using standardized I4.0 services enables cross-company collaboration of partners in a value chain consisting of, e.g., product developers, manufacturers, vendors, as well as their customers. Vendors could request manufacturers’ services to manufacture product instances of certain types, e.g., to cope with high-order volume or to handle product orders that require specific manufacturing services or machinery.
Additionally, the DT platform for I4.0 facilitates product and process optimization by utilizing a peer-to-peer sharing system to collaboratively enrich AASs (Asset Administration Shells) of products with data from specific life cycle stages, e.g., product type development, customization of product instances, documentation of manufacturing processes, or product usage data. This system combines a blockchain for booking who changed an AAS and when, a peer-to-peer distributed file system for encrypting and storing versions of AASs, and a version control system for tracking changes in detail. In combination, these technologies ensure the sovereignty of the collaborators’ data, i.e., integrity, confidentiality, and availability. Please find details in [13].
A manufacturer’s factory houses working stations and warehouses, each with specific capabilities. These physical assets process their individual work orders successively according to the order in a queue. They, as well as the company’s business microservices, all comprise an AAS [19] as standardized interface for I4.0 via which they can interact, offer their capabilities, and trigger each other’s services. AASs are either implemented based on OPC UA or AAS server technologies (see Sect. 4) [22,23,24].
In contrast to the assets of the physical world, the assets of the information world can execute multiple instances of their services in parallel. Also, these I4.0 business microservices each serve their corresponding AAS on their own, enabling authorized consumers HTTP/REST-read access and the triggering of their specific service. For example, the order taking service serves its AAS via the Internet. It can be accessed by collaborating vendors in order to trigger the manufacturing of product instances.
The microservices discover and trigger each other via registries [25], in which they register descriptors of their specific services and endpoints for triggering. Figure 5 visualizes the registering, finding, and triggering process.

The mutual discovery and triggering of I4.0 business microservices
In the spirit of I4.0, product types and manufactured instances are themselves considered as assets as well. Here, their corresponding AASs are made available via AAS servers with AAS-APIs (application programming interfaces) for creating, reading, updating, and deleting complete AASs as well as submodels and submodel elements. These product types’ and instances’ AASs provide submodels containing data necessary for the manufacturing of the product instances and submodels for process documentation. In addition to the collaboration use case described before, an instance’s AAS facilitates product optimization based on manufacturing data and enables vendors and customers to track manufacturing progresses.
What the business services of the information world have in common with the working stations and warehouses of the physical world is that they only consider the data contained in their own AAS, as well as the data contained in the AASs of the product instance and its type they are currently working on. This distributed knowledge enables fast decision making and flexible manufacturing management.
Based on the following four business microservices, manufacturing can be executed: order taking service (OTS), manufacturing driving service (MDS), bidding request service (BRS), and recording and notification service (RNS). Authorized vendors can trigger the execution of a manufacturing process run via the OTS.
Figure 6 visualizes the manufacturing process flow.
-
A customer customizes and orders a product instance in a vendor’s webshop. For each product instance to be manufactured, the vendor creates an AAS containing the product instance’s and type’s identification, customization details, as well as an endpoint via which the vendor wants to be notified of manufacturing progresses. The vendor shares its AAS with the manufacturer via the peer-to-peer sharing system.
Fig. 6 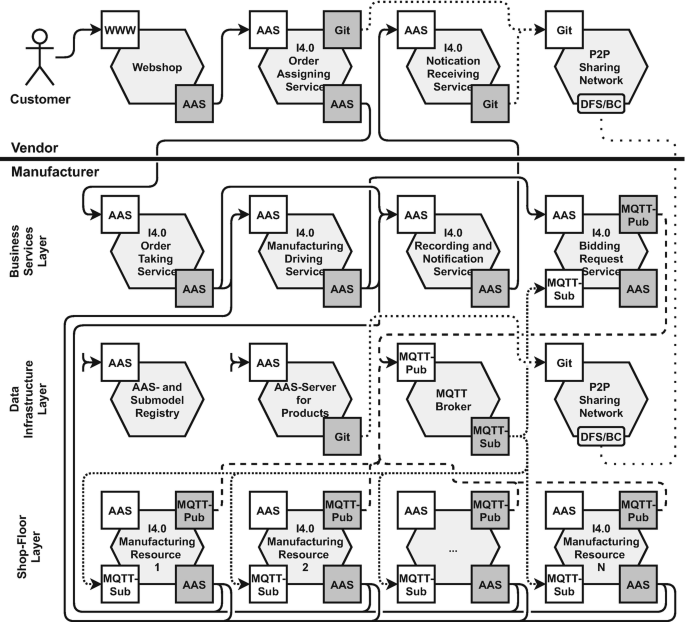
Digital Twin controlled manufacturing in the manufacturer’s Digital Twin platform for Industrie 4.0. Each manufacturing process run begins with a trigger of the manufacturer’s order taking service via its AAS-API by an order assigning service of a vendor, which itself can be triggered by, e.g., a customer order in a webshop. The components’ inbound adapters are indicated by white rectangles, dark gray rectangles mark outbound adapters, and the rounded light gray rectangles in the peer-to-peer sharing network components identify the distributed file system via which AASs are exchanged securely across the value-adding chain. For the sake of a clearer view, Apache Kafka and the data lake are not shown in the data infrastructure layer. Please add mentally also that every business service and every manufacturing resource interact with the AAS and submodel registry and the AAS server for manufactured products: either to register or find business services and AASs and submodels of product types and instances, to write or read manufacturing instructions, or to document manufacturing progresses
-
When triggered, OTS (order taking service)—the starting point of each manufacturing process run—puts the vendor’s AAS of a product instance into an AAS server, extends it with submodels providing information required for the execution and submodels for the documentation of the manufacturing process, and adds descriptors of AAS and submodels to the registries. OTS completes with triggering RNS (recording and notification service) and MDS (manufacturing driving service) providing each with the identification of the AAS and, in addition, RNS with “Manufacturing accepted.”
-
RNS, when triggered, records the respective AAS’s current server state in the peer-to-peer sharing system, notifies the corresponding vendor transmitting the status message, and terminates.
-
MDS drives the manufacturing process of a product instance. It is triggered either by OTS for the first manufacturing step or by a working station or warehouse that completed a step. It determines, from the process documentation in a product instance’s AAS, the step to be executed next, triggers BRS (bidding request service) providing as parameter the identification of the submodel describing this step, and terminates.
-
BRS publishes a call for proposal, using the interaction element from the specified submodel [26, 33] in the designated MQTT brokers. It collects the received proposals and selects the one suiting the manufacturer’s guidelines—top priority instances, as soon as possible; lowest priority instances, as inexpensive as possible—best, confirms it to the proposer, documents it in the respective submodel, triggers RNS with the message “Manufacturing step < step-number> scheduled,” and terminates.
-
The winning proposer (working station or warehouse) of a bidding procedure is responsible for the completion of the respective manufacturing step. Its responsibility also includes the picking up of the product instance and the documentation of the step in the corresponding submodel. When completed, it triggers RNS with “Manufacturing step < step-number> completed” and, again, MDS.
-
When MDS determines that the manufacturing of a product instance is completed, it adds to the corresponding AAS a submodel describing the instance’s nameplate [49], triggers RNS with “Manufacturing completed,” and terminates—the endpoint of each manufacturing process run.

The bottom line is that the Digital Twin of a product instance in the DT platform for I4.0 can be identified, as visualized in Fig. 7, as the union:
-
Of a passive part composed of all data contained in the platform related to the product instance, that is, all AAS versions as well as process and metadata contained, e.g., in AAS servers, data streams, data lake, and peer-to-peer sharing network
Fig. 7 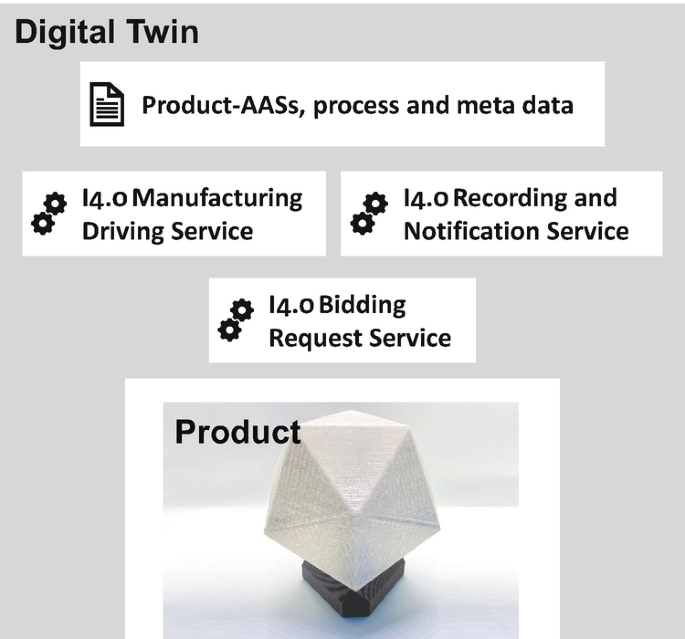
A Digital Twin of a manufactured product instance
-
Of an active part comprising those instances of the I4.0 manufacturing driving, I4.0 recording and notification, and I4.0 bidding request services that execute services (in past, present, or future) for the product instance

Jointly, a product instance and its Digital Twin compose an active composite I4.0 component: The Digital Twin actively takes decisions and interacts with I4.0 manufacturing resources aiming at an efficient manufacturing of the product instance.
6 Conclusion and Outlook
This chapter developed a Digital Twin (DT) platform for Industrie 4.0 (I4.0) enabling efficient development, deployment, and resilient operation of DTs and I4.0 business microservices, each of which comprises a software asset and an Asset Administration Shell (AAS).
User stories of platform architect, chief financial officer, platform operator, manufacturing manager, and data scientist laid the foundation for a comprehensive analysis and evaluation of architectural styles. Based on the result of analysis and evaluation, the DT platform for I4.0 was developed applying microservices patterns. A time series messaging experiment conducted in the course of this evaluation led to the conclusion that specialized, independent, and loosely coupled DTs, I4.0 microservices, and I4.0 manufacturing resources on the platform should in general communicate asynchronously via their AAS-APIs, channels, streams, or time series databases. Particularly, time series integration, consumption, and processing should be implemented in an asynchronous fashion via streams or time series databases. Besides higher performance, blocking and crashed services can be prevented this way. Seldom executed end-user applications, like reporting or documentation services, could consume time series directly from AASs in files or API servers in the platform. In this case, however, time series should be highly compressed avoiding, e.g., duplication of metadata.
The platform consists of four layers: continuous deployment (CD), shop-floor, data infrastructure, and business services layer. The services in the CD layer, the backbone of the platform, ensure that the data infrastructure and business services are highly available and can be deployed continuously. Data infrastructure services integrate and manage data from the I4.0 manufacturing resources on the shop-floor layer in order to provide semantically enriched information to I4.0 business services.
In a manufacturer’s actual application of the DT platform for I4.0, I4.0 business microservices accept manufacturing orders from trusted vendors, control manufacturing processes, dynamically interact with I4.0 manufacturing resources to schedule manufacturing execution, record the manufacturing of product instances, and notify vendors about the progress. Each I4.0 business microservice hosts its own AAS. They discover and trigger one another by submitting proper input parameters to proper AAS endpoints found in AAS and submodel registries. The DT of, e.g., a manufactured product instance can be identified as the union of a passive part comprising all data related to the product instance contained in the platform (AASs in files and servers, process data and metadata in streams and data lake) and of an active part composed of those instances of I4.0 microservices executing services (in past, present, and future) for the considered product instance.
For each physical manufacturing step that must be executed, a call for proposals is issued and the received proposals from I4.0 manufacturing resources are evaluated by the product instance’s DT. Subsequently, the DT assigns the step to the capable working station proposing the best execution—priority-dependent this might either be the fastest or the most economic proposal. After the execution and documentation of an assigned step, the working station in charge hands back the responsibility to the product instance’s DT. Step by step this DT takes decisions, where only data from its passive part and from the interactions with other DTs is taken into account. This decentralized decision-making process results in a manufacturing system that is efficient and highly adaptable, e.g., with regard to customer requests, deviations from schedules, and the integration of new manufacturing resources.
The presented platform comprises some similarities to the cloud manufacturing platform (CMfg) as both represent manufacturing resources and tasks by digital representations in platforms in order to organize manufacturing [50, 51]. Whereas a central service allocates and schedules in CMfg, this paper’s platform, in the spirit of Industrie 4.0 and based on the conviction that the determination of global optima is too complex to cope with rapidly changing manufacturing environments, enables resources, tasks, and their Digital Twins to autonomously build highly dynamic networks and flexibly negotiate the scheduling among themselves.
Future research and development of the DT platform for I4.0 focuses on further optimization and enhancements like recovery mechanisms for process states in crashed business microservices. Taking into account the distributed knowledge in the decentralized platform, how can a product instance’s manufacturing be resumed loss-free in the right process step?
Furthermore, every data infrastructure service should be equipped, like I4.0 business microservices and I4.0 manufacturing resources, with an AAS composing an I4.0 data infrastructure service. This would achieve one of the main goals of I4.0, one standardized interface in the form of the Asset Administration Shell (AAS). This way, DT interaction, adaptability, and autonomy would be improved even further. Every DT and I4.0 microservice would only require a free port for serving its own AAS and one endpoint of an AAS and submodel registry for, on the one hand, registering and promoting its own service and, on the other, for finding and interacting with every other I4.0 service present in the Digital Twin platform for Industrie 4.0. Finally, I4.0 services could be used globally in an Industrie 4.0 data space based on Gaia-X Federation Services.
References
Panetto, H., Iung, B., Ivanov, D., Weichhart, G., & Wang, X. (2019). Challenges for the cyber-physical manufacturing enterprises of the future. Annual Reviews in Control, 47, 200–213.
Al-Gumaei, K., Müller, A., Weskamp, J. N., Longo, C. S., Pethig, F., & Windmann, S. (2019). Scalable analytics platform for machine learning in smart production systems. In 24th IEEE ETFA, 2019. https://doi.org/10.1109/ETFA.2019.8869075
Asset Administration Shell Reading Guide (11/2020). https://www.plattform-i40.de/PI40/Redaktion/DE/Downloads/Publikation/Asset_Administration_Shell_Reading_Guide.html
2030 Vision for Industrie 4.0—Shaping Digital Ecosystems Globally. https://www.plattform-i40.de/PI40/Navigation/EN/Industrie40/Vision/vision.html
Gaia-X—A Federated Data Infrastructure for Europe. https://www.data-infrastructure.eu
Bitkom e.V. and Fraunhofer-Institut für Arbeitswirtschaft und Organisation IAO. (2014). Industrie 4.0 – Volkswirtschaftliches Potenzial für Deutschland
Deuter, A., & Pethig, F. (2019). The digital twin theory—Eine neue Sicht auf ein Modewort. Industrie 4.0 Management 35.
Jasperneite, J., Hinrichsen, S., Niggemann, O. (2015). Plug-and-Produce für Fertigungssysteme. Informatik-Spektrum, 38(3), 183–190.
Pethig, F., Niggemann, O., Walter, A. (2017). Towards Industrie 4.0 compliant configuration of condition monitoring services. In 15th IEEE INDIN.
Lang, D., Friesen, M., Ehrlich, M., Wisniewski, L., & Jasperneite, J. (2018). Pursuing the vision of industrie 4.0: Secure plug-and-produce by means of the asset administration shell and blockchain technology. In 16th IEEE INDIN.
Heymann, S., Stojanovci, L., Watson, K., Nam, S., Song, B., Gschossmann, H., Schriegel, S., & Jasperneite, J. (2018). Cloud-based plug and work architecture of the IIC testbed smart factory web. In 23rd IEEE ETFA.
Stock, D., Bauernhansl, T., Weyrich, M., Feurer, M., & Wutzke, R. (2018). System architectures for cyber-physical production systems enabling self-X and autonomy. In 25th IEEE ETFA. https://doi.org/10.1109/ETFA46521.2020.9212182
Redeker, M., Volgmann, S., Pethig, F., & Kalhoff, J. (2020). Towards data sovereignty of asset administration shells across value added chains. In 25th IEEE ETFA. https://doi.org/10.1109/ETFA46521.2020.9211955
Redeker, M., Weskamp, J. N., Rössl, B., & Pethig, F. (2021). Towards a digital twin platform for industrie 4.0. In 4th IEEE ICPS. https://doi.org/10.1109/ICPS49255.2021.9468204
Redeker, M., Klarhorst, C., Göllner, D., Quirin, D., Wißbrock, P., Althoff, S., & Hesse, M. (2021). Towards an autonomous application of smart services in industry 4.0. In 26th IEEE ETFA. https://doi.org/10.1109/ETFA45728.2021.9613369
DIN SPEC 91345: Reference Architecture Model Industrie 4.0 (RAMI4.0), DIN (2016). https://doi.org/10.1109/10.31030/2436156
The Asset Administration Shell: Implementing Digital Twins for use in Industrie 4.0—a starter kit for developers. https://www.plattform-i40.de/PI40/Redaktion/EN/Downloads/Publikation/VWSiDV2.0.html
International Electrotechnical Commission (IEC). (2002). IEC 61360 -1 to 4- Standard data element types with associated classification scheme for electric components.
Platform Industrie 4.0: Details of the Asset Administration Shell—Part 1—The exchange of information between partners in the value chain of Industrie 4.0 (V3.0), Federal Ministry for Economic Affairs and Energy (2020). https://www.plattform-i40.de/IP/Redaktion/EN/Downloads/Publikation/Details_of_the_Asset_Administration_Shell_Part2_V1.html
International Electrotechnical Commission (IEC). (2016). IEC 61360—Common Data Dictionary (CDD—V2.0014.0014).
International Electrotechnical Commission (IEC): IEC 63278-1 ED1 Asset administration shell for industrial applications—Part 1: Administration shell structure. https://industrialdigitaltwin.org/
OPC Foundation: OPC 30270: OPC UA for Asset Administration Shell (AAS), Release 1.00. https://reference.opcfoundation.org/v104/I4AAS/v100/docs/
AASX Server. https://github.com/admin-shell-io/aasx-server
Eclipse BaSyx. https://wiki.eclipse.org/BaSyx
Platform Industrie 4.0: Details of the Asset Administration Shell—Part 2—Interoperability at Runtime (V1.0), Federal Ministry for Economic Affairs and Energy (2020). https://www.plattform-i40.de/IP/Redaktion/EN/Downloads/Publikation/Details_of_the_Asset_Administration_Shell_Part2_V1.html
VDI/VDE 2193 Blatt 1:2020-04: Language for I4.0 Components—Structure of messages. https://www.beuth.de/de/technische-regel/vdi-vde-2193-blatt-1/318387425
Industrial Digital Twin Association (IDTA). https://industrialdigitaltwin.org/
Zillner, S., Curry, E., Metzger, A., Auer, S., & Seidl, R. (Eds.). (2017). European big data value strategic research & innovation agenda. Big Data Value Association. https://www.bdva.eu/sites/default/files/BDVA_SRIA_v4_Ed1.1.pdf
Zillner, S., Bisset, D., Milano, M., Curry, E., García Robles, A., Hahn, T., Irgens, M., Lafrenz, R., Liepert, B., O’Sullivan, B., & Smeulders, A. (Eds.). (2020). Strategic research, innovation and deployment agenda—AI, data and robotics partnership. Third release. Big Data Value Association, euRobotics, ELLIS, EurAI and CLAIRE. https://ai-data-robotics-partnership.eu/wp-content/uploads/2020/09/AI-Data-Robotics-Partnership-SRIDA-V3.0.pdf
Tanenbaum, A.S., van Steen, M. (2006). Distributed systems: Principles and paradigms, 2nd ed. Prentice-Hall, Inc., USA.
Richardson, C. (2018). Microservices patterns: With examples in Java. Manning Publications. https://books.google.de/books?id=UeK1swEACAAJ
Oxford Reference: Service Access Point. https://www.oxfordreference.com/view/10.1093/oi/authority.20110803100456475
VDI/VDE 2193 Blatt 2:2020-01: Language for I4.0 components—Interaction protocol for bidding procedures. https://www.beuth.de/de/technische-regel/vdi-vde-2193-blatt-2/314114399
ISO/IEC 20922:2016. Information technology—Message Queuing Telemetry Transport (MQTT) v3.1.1. https://www.iso.org/standard/69466.html
AASX Package Explorer, Server and Registry. https://github.com/admin-shell-io
Eugster, P. T., Felber, P. A., Guerraoui, R., & Kermarrec, A.-M. (2003). The many faces of publish/subscribe. ACM Computing Surveys, 35(2), 114–131.
Apache Kafka. https://kafka.apache.org
InfluxDB. https://www.influxdata.com
Kubernetes. https://kubernetes.io
Fluentd. https://www.fluentd.org
Elasticsearch. https://www.elastic.co/elasticsearch
OpenSearch. https://opensearch.org
GitLab. https://about.gitlab.com
Chen, L. (2015). Continuous delivery: Huge benefits, but challenges too. IEEE Software, 32, 2.
Weskamp, J. N., Chowdhury, A., Pethig, F., Wisniewski, L. (2020). Architecture for knowledge exploration of industrial data for integration into digital services. In 3rd IEEE ICPS. https://doi.org/10.1109/ICPS48405.2020.9274700
Ghosh Chowdhury, A., Illian, M., Wisniewski, L., Jasperneite, J. (2020). An approach for data pipeline with distributed query engine for industrial applications. In 25th IEEE ETFA.
Weskamp, J. N., & Tikekar, J. (2021). An Industrie 4.0 compliant and self-managing OPC UA Aggregation Server. In 26th IEEE ETFA. http://dx.doi.org/10.1109/ETFA45728.2021.9613365
Collaborative data-driven business models: Collaborative Condition Monitoring—How cross-company collaboration can generate added value. https://www.plattform-i40.de/PI40/Redaktion/EN/Downloads/Publikation/collaborative-data-driven-business-models.html
Submodel Templates of the Asset Administration Shell—ZVEI Digital Nameplate for industrial equipment (Version 1.0). https://www.plattform-i40.de/PI40/Redaktion/DE/Downloads/Publikation/Submodel_Templates-Asset_Administration_Shell-digital_nameplate.html
Tao, F., Zhang, L., Venkatesh, V. C., Luo, Y., & Cheng, Y. (2011). Cloud manufacturing: A computing and service-oriented manufacturing model. Proceedings of the Institution of Mechanical Engineers, Part B: Journal of Engineering Manufacture, 225(10), 1969–1976. https://doi.org/10.1177/0954405411405575
Zhang, L., Luo, Y., Tao, F., Li, B. H., Ren, L., Zhang, X., Guo, H., Cheng, Y., Hu, A., Liu, Y. (2014). Cloud manufacturing: A new manufacturing paradigm. Enterprise Information Systems, 8(2), 167–187. https://doi.org/10.1080/17517575.2012.683812
Acknowledgements
The research and development projects “Technical Infrastructure for Digital Twins” (TeDZ) and “Industrial Automation Platform” (IAP) are funded by the Ministry of Economic Affairs, Innovation, Digitalization and Energy (MWIDE) of the State of North Rhine-Westphalia within the Leading-Edge Cluster “Intelligent Technical Systems OstWestfalenLippe” (it’s OWL) and managed by the Project Management Agency Jülich (PTJ). The research and development project “KI-Reallabor für die Automation und Produktion” initiated by the German initiative “Platform Industrie 4.0” is funded by the German Federal Ministry for Economic Affairs and Energy (BMWi) and managed by the VDI Technologiezentrum (VDI TZ). The authors are responsible for the content of this publication.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this chapter

Cite this chapter
Redeker, M., Weskamp, J.N., Rössl, B., Pethig, F. (2022). A Digital Twin Platform for Industrie 4.0. In: Curry, E., Scerri, S., Tuikka, T. (eds) Data Spaces . Springer, Cham. https://doi.org/10.1007/978-3-030-98636-0_9
Download citation
DOI: https://doi.org/10.1007/978-3-030-98636-0_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-98635-3
Online ISBN: 978-3-030-98636-0
eBook Packages: Computer ScienceComputer Science (R0)