
Abstract
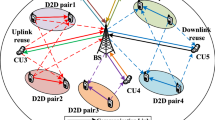
Device-to-Device (D2D) communication is a potential technology that efficiently reuses spectrum resources with CMUs in a fifth-generation (5G) underlay and even beyond the network. It improves network capacity and spectral efficiency at the cost of co-channel interference. Moreover, massive connectivity has not been fully exploited for efficient spectral efficiency usage in the existing solutions. To resolve the aforementioned issues, we combine non-orthogonal multiple access (NOMA) approaches with cellular mobile users (CMUs) in order to improve their throughput while preserving the signal-to-interference noise ratio (SINR) offered by CMUs and D2D mobile pairs (DMPs). The problem of power allocation is formulated as mixed-integer non-linear programming, which is then transformed to machine learning using the markov decision process (MDP). Then, a deep reinforcement learning (DRL) approach is proposed for solving the continuous optimisation problem in a centralised fashion. Furthermore, to achieve better performance and a faster convergence rate, the higher proximal policy optimization (PPO) scheme is employed. Numerical results reveal that the proposed algorithm outperformed state-of-the-art schemes in terms of throughput.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Shafi, M., et al.: 5G: a tutorial overview of standards, trials, challenges, deployment, and practice. IEEE J. Sel. Areas Commun. 35(6), 1201–1221 (2017)
Budhiraja, I., et al.: A systematic review on NOMA variants for 5G and beyond. IEEE Access 9, 85573–85644 (2021)
Budhiraja, I., et al.: ISHU: interference reduction scheme for D2D mobile groups using uplink NOMA. IEEE Trans. Mob. Comput. (2021)
Goodfellow, I., et al.: Deep Learning. MIT Press, Cambridge (2016)
Luong, N.C., et al.: Applications of deep reinforcement learning in communications and networking: a survey. IEEE Commun. Surv. Tutor. 21(4), 3133–3174 (2019)
Budhiraja, I., Kumar, N., Tyagi, S., Tanwar, S., Han, Z.: An energy efficient scheme for WPCN-NOMA based device-to-device communication. IEEE Trans. Veh. Technol. 70(11), 11935–11948 (2021)
Nguyen, K.K., et al.: Non-cooperative energy efficient power allocation game in D2D communication: a multi-agent deep reinforcement learning approach. IEEE Access 7, 100480–100490 (2019)
Bi, Z., et al.: Deep reinforcement learning based power allocation for D2D network. In: 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), pp. 1–5, March 2020
Ji, Z., et al.: Power optimization in device-to-device communications: a deep reinforcement learning approach with dynamic reward. IEEE Wirel. Commun. Lett. 10(3), 508–511 (2021)
Zhang, T., et al.: Energy-efficient mode selection and resource allocation for D2D-enabled heterogeneous networks: a deep reinforcement learning approach. IEEE Trans. Wirel. Commun. 20(2), 1175–1187 (2021)
Chen, M., et al.: Continuous incentive mechanism for D2D content sharing: a deep reinforcement learning approach. In: 2020 IEEE International Conference on Communications Workshops (ICC Workshops), pp. 1–6, June 2020
Tan, J., et al.: Deep reinforcement learning for joint channel selection and power control in D2D networks. IEEE Trans. Wirel. Commun. 20(2), 1363–1378 (2021)
Budhiraja, I., et al.: Deep-reinforcement-learning-based proportional fair scheduling control scheme for underlay D2D communication. IEEE Internet Things J. 8(5), 3143–3156 (2021)
Tang, J., et al.: Energy minimization in D2D-assisted cache-enabled Internet of Things: a deep reinforcement learning approach. IEEE Trans. Ind. Inf. 16(8), 5412–5423 (2020)
Mnih, V., et al.: Asynchronous methods for deep reinforcement learning. In: International Conference on Machine Learning, pp. 1928–1937, June 2016
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 Springer Nature Switzerland AG
About this paper

Cite this paper
Vishnoi, V., Malik, P.K., Budhiraja, I., Yadav, A. (2022). Deep Reinforcement Learning Based Throughput Maximization Scheme for D2D Users Underlaying NOMA-Enabled Cellular Network. In: Garg, D., Jagannathan, S., Gupta, A., Garg, L., Gupta, S. (eds) Advanced Computing. IACC 2021. Communications in Computer and Information Science, vol 1528. Springer, Cham. https://doi.org/10.1007/978-3-030-95502-1_25
Download citation
DOI: https://doi.org/10.1007/978-3-030-95502-1_25
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-95501-4
Online ISBN: 978-3-030-95502-1
eBook Packages: Computer ScienceComputer Science (R0)