
Abstract
Risk assessment is of high importance when it comes to trading, investments, and other financial activities, as poor risk monitoring could lead to inefficient investments, loss of capital, and penalties by regulatory authorities. Thus, robust risk models, capable of yielding real-time results, are valuable assets for investment banking. This chapter introduces a financial tool that can provide risk assessment on Forex portfolios in (near) real-time and pre-trade analysis at rest. Financial risk is measured in terms of both Value at Risk and the Expected Shortfall, with the respective models utilizing not only statistical but also deep learning techniques that achieve accurate results. Moreover, the proposed application, based on state-of-the-art data management technologies, provides real-time risk assessments, utilizing the latest market data. These features along with the provided pre-trade analysis make this solution a valuable tool for practitioners in high frequency trading (HFT) and investment banking in general.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
Risk assessment refers to the processes required to quantify the likelihood and the scale of loss on an asset, loan, or investment. In investment banking, risk estimation and monitoring are of great importance as invalid models and assumptions could cause substantial capital losses. This was the case for several financial institutions in the 2008 financial crisis and the COVID-19 pandemic as well.
Despite the recent hype for digitization in the financial industry, many companies lack accurate real-time risk assessment capabilities. This is due to the current practice of updating portfolios’ risk estimation only once in a day, usually overnight in a batch mode, which is insufficient for trading in higher frequency markets like Forex (FX) [1]. Surprisingly, this is still an open challenge for various banks and asset management firms, where the risk evaluation is outsourced to third party consulting companies, which are in charge of risk monitoring and regulatory compliance with for an agreed investment strategy. Furthermore, in cases where a real-time overview of the trading positions might be provided, the data needed for computing the risk measures and other relevant indicators are updated only once a day. As a result, the risk exposure from intra-day price fluctuations is not monitored properly, which may lead to both trading and investment inefficiencies [2].
When it comes to HFT, the speed of financial risk calculations (derived from algorithm complexity) is the main barrier towards real-time risk monitoring [3]. Traditionally, there is a trade-off between speed and accuracy of the financial risk calculations, as the less computationally intensive risk models, which might be able to yield their assessments near-instantly, are not considered sufficiently reliable in the financial domain [4]. In addition, real-time risk monitoring is also a regulatory requirement [5] that can be met if risk information is updated timely.
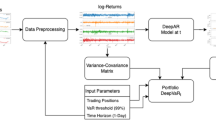
This Chapter introduces a new tool, named AI-Risk-Assessment, which represents a potential key offering within this space. More specifically it addresses the challenge of real-time risk estimation for Forex Trading, in the scope of the European Union’s funded INFINITECH project, under grant agreement no 856632. The primary added-value provided by this tool can be divided into three pillars (components): (1) risk models; (2) real-time management; and (3) pre-trade analysis, which are each described in the following sections along with the tool’s core architecture that allows seamless interaction between these components. The proposed tool follows a containerized micro-service design, consisting of different components that communicate with each other in an asynchronous manner, forming a real-time data processing pipeline, illustrated in Fig. 9.1.

Data pipeline
2 Portfolio Risk
Portfolio risk is the likelihood that the combination of assets that compromise a portfolio fails to meet financial objectives. Each investment within a portfolio carries its own risk, with higher potential return typically meaning higher risk. Towards quantifying this risk, each asset’s future performance (i.e., returns) should be predicted. To this end, various models and theories regarding the nature of the financial time-series have been proposed. Most of these models assume that the underlying assets’ returns follow a known distribution (e.g., Gaussian distribution) and try to estimate its parameters (e.g., mean and variance of asset’s returns) based on their historical performance. Moreover, the portfolio risk depends on the weighted combination of the constituent assets and their correlation as well. For instance, according to Modern Portfolio Theory (MPT) [6], which assumes Normal distribution for the financial returns, one could obtain a portfolio’s risk performance under a known probability portfolio risk calculating the distribution parameters (\(\mu _p,\sigma _p^2\)) from Eqs. 9.1 and 9.2.
where R p is the return on the portfolio, R i is the return on asset i, and w i is the weighting of component asset i (that is, the proportion of asset “i” in the portfolio).
where σ is the (sample) standard deviation of the periodic returns on an asset, and ρ ij is the correlation coefficient between the returns on assets i and j.
Furthermore, the Efficient Market Hypothesis implies that in highly efficient markets, such as the foreign exchange market [7], a financial instrument’s value illustrates all the available information about that instrument [8]. As a result, the utilized risk models should be fed with the latest market data to provide valid portfolio risk estimations. The need for continuous updates in the risk estimates is more evident in HFT where traders usually manage numerous portfolios with different strategies (i.e., holding periods, composition, risk profile, and volume) that are mainly based on algorithmic trading [9]. Thus, there is a need for a risk assessment tool that will handle and process a large volume of market and trading data and, based on them to provide risk estimates. The latter should be updated in (near) real-time capturing intra-day volatility in financial markets that could cause both loss of liquidity and capital.
3 Risk Models
The proposed application leverages two standard risk metrics which are broadly adopted not only in risk management but also in financial control, financial reporting and in computing the regulatory capital of financial institutions, namely: Value at Risk (VaR); and Expected Shortfall (ES), which we discuss in more detail below.
3.1 Value at Risk
The first underlying risk metric is the Value at Risk (VaR), which measures the maximum potential loss of an investment under a confidence probability within a specific time period (typically a single day). There are three fundamentally different methods for calculating VaR; parametric, non-parametric, and semi-parametric [10]. AI-Risk-Assessment offers four VaR models based on these methods to enhance the risk monitoring process.
Parametric
The most popular parametric VaR method (and what is implemented in the tool) is based on the Variance-Covariance (VC) approach [10]. The key assumption here is that the portfolio returns follow the normal distribution, hence the variance of the market data is considered known. Also, a proper history-window (e.g., 250 samples) should be defined, and the variance-covariance matrix of returns should be calculated. The VaR is then obtained by Eq. 9.3.
where z, α, w, Σ are the standard score, the confidence probability of VaR prediction, the portfolio assets weights, and the covariance matrix of the portfolio assets, respectively.
Non-parametric
From the non-parametric category, the well-known Historical Simulation (HS) VaR method [11] was selected. In this approach, the historical portfolio returns are taken into account in the VaR calculation along with a selected confidence level. Under the Historical Simulation approach, the first step is to sort the historical portfolio returns for a given time-window. Then the VaR can be derived by selecting the n-worst portfolio performance that corresponds to the required confidence probability ((100-n)%) of the VaR estimation. For instance, to calculate the 1-day 95% VaR for an portfolio using 100 days of data, the 95% VaR corresponds to the best performing of the worst 5% of portfolio returns. Consequently, HS is a computationally effective risk model with acceptable returns when large historical windows are taken into account. However, the latter results in high VaR estimations that restrict the accepted investment strategies.
Semi-parametric
As for the semi-parametric VaR method, a Monte Carlo (MC) [12] model was developed. In the context of the proposed solution, the mean and the standard deviation of returns are calculated from the available historical data and then these values are used to produce MC random samples from the Gaussian distribution. To calculate VaR, this process draws the distribution of portfolio returns for the next time step (see Eq. 9.4).
where q α is the α-th percentile of the continuously compounded return.
Semi-parametric with RNNs
In addition, this tool introduces a novel semi-parametric VaR model [13] combining deep neural networks with MC simulations. In this approach, the parameters of the returns distribution are initially estimated by a Recurrent Neural Network (RNN) [14] based model, with the network output being used to predict all possible future returns in a MC fashion. VaR based on the input time-series can then be obtained by (Eq. 9.4). The RNN-model in question, named DeepAR, follows the methodology proposed by Salinas et al. [15] and is provided by GluonTS Python libraryFootnote 1 for deep-learning-based time-series modeling [16]. This model is able to capture nonlinear dependencies of the input time-series, such as seasonality, resulting in consistent quantile estimates. Moreover, DeepAR can be fed with several input time-series simultaneously, enabling cross-learning from their historical behavior jointly. As a result, changes in the dynamics of the one time-series may affect the predicted distributions of the other time-series.
3.2 Expected Shortfall
Alternatively, risk assessment can also be performed via Expected Shortfall (ES), also known as Conditional Value at Risk (C-VaR) [17], which is a conservative risk measure calculating portfolio loss with the assumption that this loss is higher than the estimated VaR as illustrated in Fig. 9.2. ES was originally suggested as a practicable and sound alternative to VaR, featuring various useful properties such as sub-additivity that are missing from VaR [18]. This has led many financial institutions to use it as a risk measure internally [19]. Expected Shortfall can be calculated via a parametric equation shown below (see Eq. 9.5) [20].

Comparison between value at risk and expected shortfall
where \(\phi \left (x\right )\ =\frac {1}{\sqrt {2\pi }}e^{\frac {-x^2}{2}}\), \(\Phi \left (x\right )\) is the standard normal c.d.f., so \(\Phi ^{-1}\left (a\right )\) is the standard normal quantile, and μ p, σ p the mean and standard deviation of portfolio returns, respectively.
The user interface of the application offers a page for analysis and back-testing of the provided risk assessments (Fig. 9.3). In this way the user is able to compare the true performance of various VAR/ES models in both 95 and 99% confidence level.

Analysis and Back-Testing application page: The green line is the actual portfolio returns. The dense lines are for 95% confidence probability, while the dash lines for 99%
4 Real-Time Management
Delivering the aforementioned risk assessments while leveraging the latest available data is a challenging task, as FX market prices are updated at inconsistent high frequency time intervals (e.g., 1–8 seconds). Moreover, even small price fluctuations can have a significant impact on portfolios’ value, particularly in cases where an high-risk/return investment strategy is being employed. Thus, additional technologies are required that can provide seamless data management with online analytical processing capabilities.
Within Infinitech, this is accomplished via a new data management platform referred to as the InfiniSTORE. The InfiniSTORE extends a state-of-the-art database platformFootnote 2 and incorporates two important innovations that enable real-time analytical processing over operational data. Firstly, its hybrid transactional and analytical processing engine allows ingesting data at very high rates and perform analytics on the same dataset in parallel, without having to migrate historical data into a data temporary warehouse (which is both slow and by its nature batch-orientated). Secondly, its online aggregates function enables efficient execution of aggregate operations, which improves the response time for queries by an order of magnitude. Additional details can be found in Chap. 2.
The AI-Risk-Assessment requires the datastore to firstly store the raw input ticker data along with the risk estimations and secondly to enable online data aggregation and integrated query processing for data in-flight and at rest. These requirements are enabled by the InfiniSTORE and underlying LeanXcale database via its dual interface, allowing it to ingest operational data at any rate and also to perform analytical query processing on the live data that have been added in parallel.
In order for the application to achieve its main objective of measuring intra-day risk in a timely fashion (e.g., updating VaR/ES approximately every 15-minutes), the input tick data (with rate 1–8 second per instrument) should be resampled for the required frequency. LeanXcale provides online aggregates that enables real-time data analysis in a declarative way with standard SQL statements. In this way, only the definition of the required aggregate operations, such as average price per FX instrument per quarter-hour, is required and the result of the execution is pre-calculated on the fly, ensuring consistent transactional semantics. As a result, the typically long-lasting query can be transformed into a very light operation that requires the read-access to a single value, thus removing the need to scan the whole dataset.
Additionally, an interface between the data provider (e.g., a bank’s data API) and the datastore is required to handle the real-time data streams ingested. As these microservices need to communicate asynchronously ensuring high availability and fault-tolerance, the most popular intermediate is the use of data queues [21]. Apache Kafka [22] is the most dominant solutions when it comes to data queues [23]. Using Kafka, external components can send data feeds to a specified queue, by subscribing to a specific topic and then sending the data in a common format. Infinitech provides a pre-built container image that contains a Kafka data queue, while the datastore has a built-in Kafka connector which enables interconnection between the LeanXcale datastore and Kafka. The data injection process along with the online data aggregation are illustrated in Fig. 9.4.

Data injection and online aggregation
5 Pre-trade Analysis
Besides risk monitoring, traders, asset, and risk managers are seeking tools that enable pre-trade analysis. Such a tool could serve as a trader’s digital twin, allowing the filtering of potential trading positions based on their risk. In addition, this feature provides direct information to the trader about the change in the risk of his portfolio in case the trader approves the simulated position.
The AI-Risk-Assessment incorporates another important feature which is based on what-if-analysis focusing on pre-trade risk assessment. In this way, if a trader sees an opportunity for a trade, they may enter this trade into the provided application (platform) and request a calculation of the risk measures with this new trade added to the portfolio as if it were done already. The pre-trade analysis is a useful tool for traders in order to understand how a potential new trade position may affect the portfolio and its risk Fig. 9.5.

Pre-Trade analysis application page: The user enters (left) the desirable risk parameters (i.e. confidence level and time horizon) along with the positions on the financial instruments of the portfolio to be simulated. The application updates its risk estimations (right) on the fly
However, in order to enable this feature, the developed risk models should be optimized to yield results instantly using the latest input data (i.e., asset prices). To this end, portfolio risk estimation follows a two-step procedure. Initially, both VaR and ES are calculated for each portfolio instrument separately as a univariate time-series based on the latest market prices available from the real-time management tools described in Sect. 4. It is noted that these calculations are performed under the hood and are updated as new data is made available. The second step is related to the user inputs. For instance, when the user is experimenting with new trading positions, the weight of each asset is obtained, with univariate risk assessments being used to calculate the portfolio VaR/ES. This procedure can be completed very quickly as it requires only simple matrix algebra, as illustrated in Eq. 9.6 [10].
where V is the vector of VaR estimates per instrument,
and R is the correlation matrix,

where ρ 1,2 is the correlation estimate between instruments’ 1 and 2 returns. This process, described by Algorithm 1 also applies to portfolio ES calculation.
6 Architecture
This section focuses on technical details regarding the deployment of the proposed application in a production environment following the reference architecture described in Chap. 1. Each component is deployed as a docker container in an automated manner, using the Kubernetes container orchestration system. In this way, all software artefacts of the integrated solution are given a common namespace, and they can interact with each other inside the namespace as a sandbox. This deployment method allows for portability of the sandbox, as it can be deployed in different infrastructures.
A high-level overview of the Infinitech implementation is illustrated in Fig. 9.6. Each component runs within a Pod, which is the smallest compute unit within Kubernetes. A Pod encapsulates one (or more) containers, has its own storage resources, a unique network IP, access port and options related to how the container should run. This setup enables the auto-scaling of the underlying services according to the volume of external requests. For instance, in case of influx of clients (i.e., traders) requiring risk assessment of their portfolios, the corresponding (red) Pod will automatically scale-out as needed.

Application deployment scheme
It is also noted that as each service is accessed via a REST API, they are able to communicate as required by client requests, while additional features (e.g., financial news sentiment analysis) could be added as a separate component without requiring modification to the existing services.
Algorithm 1 Portfolio risk estimation

7 Summary
This chapter addresses one of the major challenges in the financial sector which is real-time risk assessment. In particular, the chapter covers risk models implemented within Infinitech and their integration with associated technological tooling to enable processing of large amounts of input data. The provided Infinitech application leverages several well-established risk models, in addition to introducing a new one based on deep learning techniques. These assessments can be updated in (near) real-time using streaming financial data, and used to drive what-if analysis for portfolio modification. The Infinitech solution can be a valuable asset for practitioners in high frequency trading where consistent risk assessment is required in real-time. It is worth mentioning that the underlying architecture can also be used with different risk models, optimized for different types of financial portfolios, while additional features could be integrated as microservices following Infinitech reference architecture.
Notes
References
Andersen, T. G., Bollerslev, T., Diebold, F. X., & Vega, C. (2007). Journal of international Economics, 73(2), 251.
Mengle, D. L., Humphrey, D. B., & Summers, B. J. (1987). Economic Review 73, 3.
Kearns, M., & Nevmyvaka, Y. (2013). High frequency trading: New realities for traders, markets, and regulators.
Bredin, D., & Hyde, S. (2004). Journal of Business Finance & Accounting, 31(9–10), 1389.
Préfontaine, J., Desrochers, J., & Godbout, L. (2010). The Analysis of comments received by the BIS on principles for sound liquidity risk management and supervision. International Business & Economics Research Journal (IBER), 9(7). https://doi.org/10.19030/iber.v9i7.598
Markowitz, H. (1955). The optimization of a quadratic function subject to linear constraints. Technkcal Report. RAND CORP SANTA MONICA CA.
Nguyen, J. (2004). The efficient market hypothesis: Is it applicable to the foreign exchange market? Department of Economics, University of Wollongong. https://ro.uow.edu.au/commwkpapers/104
Fama, E. F. (2021). Efficient capital markets II. University of Chicago Press.
Gomber, P., & Haferkorn, M. (2015). Encyclopedia of information science and technology (3rd ed., pp. 1–9). IGI Global.
Longerstaey, J., & Spencer, M. (1996). Morgan Guaranty Trust Company of New York, 51, 54.
Chang, Y. P., Hung, M. C., & Wu, Y. F. (2003). Communications in Statistics-Simulation and Computation, 32(4), 1041.
Hong, L. J., Hu, Z., & Liu, G. (2014). ACM Transactions on Modeling and Computer Simulation (TOMACS), 24(4), 1.
Bingham, N. H., & Kiesel, R. (2002). Quantitative Finance, 2(4), 241.
Gers, F. A., Schmidhuber, J., & Cummins, F. (2000). Neural Computation, 12(10), 2451.
Salinas, D., Flunkert, V., Gasthaus, J., & Januschowski, T. (2020). International Journal of Forecasting, 36(3), 1181.
Alexandrov, A., Benidis, K., Bohlke-Schneider, M., Flunkert, V., Gasthaus, J., Januschowski, T., Maddix, D. C., Rangapuram, S., Salinas, D., Schulz, J., Stella, L., Türkmen, A. C., & Wang, Y. (2019). Preprint arXiv:1906.05264.
Rockafellar, R. T., & Uryasev, S. (2000). Optimization of conditional value-at-risk. Journal of Risk, 2, 21–42.
Tasche, D. (2002). Journal of Banking & Finance, 26(7), 1519.
Sarykalin, S., Serraino, G., & Uryasev, S. (2008). State-of-the-art decision-making tools in the information-intensive age (pp. 270–294). Informs.
Khokhlov, V. (2016). Evropskỳ časopis ekonomiky a managementu, 2(6), 70.
Dinh-Tuan, H., Beierle, F., & Garzon, S. R. (2019). 2019 IEEE International Conference on Industrial Cyber Physical Systems (ICPS) (pp. 23–30). IEEE.
Kreps, J., Narkhede, N., & Rao, J. (2011). Kafka: A distributed messaging system for log processing. In Proceedings of the NetDB (Vol. 11).
John, V., & Liu, X. (2017) Preprint arXiv:1704.00411.
Acknowledgements
The research leading to the results presented in this Chapter has received funding from the European Union’s funded Project INFINITECH under grant agreement no 856632.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this chapter

Cite this chapter
Fatouros, G., Makridis, G., Soldatos, J., Ristau, P., Monferrino, V. (2022). Addressing Risk Assessments in Real-Time for Forex Trading. In: Soldatos, J., Kyriazis, D. (eds) Big Data and Artificial Intelligence in Digital Finance. Springer, Cham. https://doi.org/10.1007/978-3-030-94590-9_9
Download citation
DOI: https://doi.org/10.1007/978-3-030-94590-9_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-94589-3
Online ISBN: 978-3-030-94590-9
eBook Packages: EngineeringEngineering (R0)