
Abstract
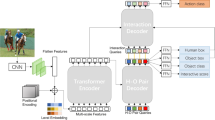
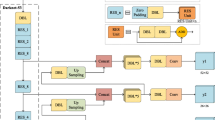
Human-object interaction detection is one of the key issues of scene understanding. It has widespread applications in advanced computer vision technology. However, due to the diversity of human postures, the uncertainty of the shape and size in objects, as well as the complexity of the relationship between people and objects. It is very challenging to detect the interaction relationship between people and objects. To solve this problem, this paper proposes a multi-scale attention fusion method to adapt to people and objects of different sizes and shapes. This method increases the range of attention which can more accurately judge the relationships between people and objects. Besides, we further propose a weighting mechanism to better characterize the interaction between people and close objects and express people’s intention of interaction. We evaluated the proposed method on HICO-DET and V-COCO datasets, which has verified its effectiveness and flexibility as well as has achieved a certain improvement in accuracy.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Tian, Y., Ruan, Q., An, G., et al.: Action recognition using local consistent group sparse coding with spatio-temporal structure. In: Proceedings of the 24th ACM International Conference on Multimedia, pp. 317–321 (2016)
Gkioxari, G., Girshick, R., Malik, J.: Contextual action recognition with r* cnn. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1080–1088 (2015)
Xu, B., Ye, H., Zheng, Y., et al.: Dense dilated network for few shot action recognition. In: Proceedings of the ACM on International Conference on Multimedia Retrieval, pp. 379–387 (2018)
Gao, C., Zou, Y., Huang, J.B.: ican: Instance-centric attention network for human-object interaction detection. arXiv preprint arXiv:1808.10437 (2018)
Li, Y.L., Zhou, S., Huang, X., et al.: Transferable interactiveness knowledge for human-object interaction detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3585–3594 (2019)
Redmon, J., Divvala, S., Girshick, R., et al.: You only look once: unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 779–788 (2016)
Liu, W., Anguelov, D., Erhan, D., et al.: SSD: Single shot multibox detector. In: European Conference on Computer Vision, pp. 21–37. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_2
Li, Y., Qi, H., Dai, J., et al.: Fully convolutional instance-aware semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2359–2367 (2017)
Law, H., Deng, J.: Cornernet: detecting objects as paired keypoints. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 734–750 (2018)
Ren, S., He, K., Girshick, R., et al.: Faster R-CNN: towards real-time object detection with region proposal networks. arXiv preprint arXiv:1506.01497 (2015)
He, K., Gkioxari, G., Dollár, P., et al.: Mask R-CNN. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2961–2969 (2017)
Chen, K., Pang, J., Wang, J., et al.: Hybrid task cascade for instance segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4974–4983 (2019)
Cai, Z., Vasconcelos, N.: Cascade R-CNN: high quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 43, 1483–1498 (2019)
Girshick, R., Donahue, J., Darrell, T., et al.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 580–587 (2014)
Lin, T.Y., Dollár, P., Girshick, R., et al.: Feature pyramid networks for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2117–2125 (2017)
Chéron, G., Laptev, I., Schmid, C.: P-CNN: pose-based cnn features for action recognition. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 3218–3226 (2015)
Lu, C., Krishna, R., Bernstein, M., Fei-Fei, L.: Visual relationship detection with language priors. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9905, pp. 852–869. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_51
Mallya, A., Lazebnik, S.: Learning models for actions and person-object interactions with transfer to question answering. In: European Conference on Computer Vision, pp. 414–428. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_25
Girdhar, R., Ramanan, D.: Attentional pooling for action recognition. arXiv preprint arXiv:1711.01467 (2017)
Jetley, S., Lord, N.A., Lee, N., et al.: Learn to pay attention. arXiv preprint arXiv:1804.02391 (2018)
Gupta, S., Malik, J.: Visual semantic role labeling. arXiv preprint arXiv:1505.04474 (2015)
Gkioxari, G., Girshick, R., Dollár, P., et al.: Detecting and recognizing human-object interactions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8359–8367 (2018)
Qi, S., Wang, W., Jia, B., Shen, J., Zhu, S.-C.: Learning human-object interactions by graph parsing neural networks. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11213, pp. 407–423. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01240-3_25
Chao, Y.W., Liu, Y., Liu, X., et al.: Learning to detect human-object interactions. In: 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 381–389. IEEE (2018)
Wang, T., Anwer, R.M., Khan, M.H., et al.: Deep contextual attention for human-object interaction detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5694–5702 (2019)
Liang, Z., Liu, J., Guan, Y., et al.: Visual-semantic graph attention networks for human-object interaction detection. arXiv e-prints: arXiv: 2001.02302 (2020)
Xu, B., Li, J., Wong, Y., et al.: Interact as you intend: intention-driven human-object interaction detection. IEEE Trans. Multimedia 22(6), 1423–1432 (2019)
Fang, H.S., Xie, S., Tai, Y.W., et al.: RMPE: regional multi-person pose estimation. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2334–2343 (2017)
Li, J., Wang, C., Zhu, H., et al.: Crowdpose: efficient crowded scenes pose estimation and a new benchmark. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10863–10872 (2019)
Xu, K., Ba, J., Kiros, R., et al.: Show, attend and tell: neural image caption generation with visual attention. In: International Conference on Machine Learning. PMLR, pp. 2048–2057 (2015)
You, Q., Jin, H., Wang, Z., et al.: Image captioning with semantic attention. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4651–4659 (2016)
Ji, Z., Fu, Y., Guo, J., et al.: Stacked semantics-guided attention model for fine-grained zero-shot learning. In: Advances in Neural Information Processing Systems, pp. 5995–6004 (2018)
Chu, X., Yang, W., Ouyang, W., et al.: Multi-context attention for human pose estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1831–1840 (2017)
Chao, Y.W., Wang, Z., He, Y., et al.: Hico: A benchmark for recognizing human-object interactions in images. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1017–1025 (2015)
Kuang, H., Zheng, Z., Liu, X., et al.: A human-object interaction detection method inspired by human body part information. In: 2020 12th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), pp. 342–346. IEEE (2020)
Zhou, T., Wang, W., Qi, S., et al.: Cascaded human-object interaction recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4263–4272 (2020)
Wan, B., Zhou, D., Liu, Y., et al.: Pose-aware multi-level feature network for human object interaction detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9469–9478 (2019)
Wang, T., Yang, T., Danelljan, M., et al.: Learning human-object interaction detection using interaction points. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4116–4125 (2020)
Zhao, W., Lu, H., Wang, D.: Multisensor image fusion and enhancement in spectral total variation domain. IEEE Trans. Multimedia 20(4), 866–879 (2017)
Lan, R., Sun, L., Liu, Z., et al.: MADNet: a fast and lightweight network for single-image super resolution. IEEE Trans. Cybern. 51, 1443–1453 (2020)
Acknowledgments
This work was supported by the National Natural Science Foundation of China (No. 61672268).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Wu, Q., Zhan, Y. (2021). Human-Object Interaction Detection Based on Multi-scale Attention Fusion. In: Peng, Y., Hu, SM., Gabbouj, M., Zhou, K., Elad, M., Xu, K. (eds) Image and Graphics. ICIG 2021. Lecture Notes in Computer Science(), vol 12888. Springer, Cham. https://doi.org/10.1007/978-3-030-87355-4_24
Download citation
DOI: https://doi.org/10.1007/978-3-030-87355-4_24
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-87354-7
Online ISBN: 978-3-030-87355-4
eBook Packages: Computer ScienceComputer Science (R0)