
Abstract
This chapter demonstrates the potential of tuna fishing fleets to reduce their fuel oil consumption. In the “Oceanic tuna fisheries, immediate operational choices” pilot, the data monitoring system on vessels periodically upload data to the server for shore analysis. The data analytics employs fuel oil consumption equations and propulsion engine fault detection models. The fuel consumption equations are being used to develop immediate operational decision models. The fault detection models are used to plan maintenance operations and to prevent unexpected engine malfunctions. The data-driven planning software allows probabilistic forecasting of tuna biomass distribution and analysing changes in fishing strategies leading to fuel consumption reduction. These changes in fishing strategies can be summarized as a transition from hunting to harvesting. Vessels do not search for fish, but instread take less risks and fish, where it is more likely that the fish can be found and is easier to capture. Buoy data are increasingly used to improve stock assessments and have the potential to allow better monitoring and planning of fish quotas fulfilment.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
- Tuna fisheries
- Fisheries digitalization
- Fuel consumption reduction
- Operational choices
- Fisheries planning
- Machine learning
- Species distribution forecasting
1 Introduction
As the catches of tropical tunas have almost reached their limit, this fishery needs to reduce its costs and carbon footprint to achieve objectives such as improved margins and less environmental impact. Fuel consumption may represent up to 50% of a tuna vessel’s total operational costs, thus, representing one of the main concerns for fishing companies [1, 2]. Moreover, world fishing industry emissions per landed fish tonnes have increased by 21% recently [3]. Large pelagic fish, such as tuna species, is highly migratory. Because of this, vessels targeting tuna species tend to have higher and more variable fuel consumption costs than others fishing for coastal species [4]. However, it is also worthwhile highlighting that this sector provides 25,000 direct jobs and 54,000 indirect jobs in the European Union while contributing to food security.
The tropical tuna fishing industry uses Earth observation (EO) data, to characterize the environmental conditions of the surrounding areas to locate fishing grounds with less effort (i.e. time, fuel and consequent costs). High digitalization of tuna vessels means that their capacity to record and to use existing EO data has increased [5]. However, due to the large volume, diversity of sources and quality of recorded data, they are rarely used for further analysis and remain intact and unstructured. Big data methodologies seem to be the solution to deal with such large volume of heterogeneous data and turn it into useful information. Solving these problems demands new system architectures for data acquisition, transmission, storage and large-scale data processing mechanisms [6]. Big data processing techniques, enhanced by machine learning methods, can increase the value of such data and their applicability for industry and management challenges. Machine learning has already proved its potential in marine sciences applied to fisheries forecasting [7,8,9]. However, big data use by the fishing industry is behind the state-of-the-art and day-to-day applications when compared with the other shipping industries [10,11,12].
The aim of oceanic tuna fisheries pilots is to improve economic sustainability of oceanic tuna fisheries while reducing their emission footprint. This double objective can be achieved through reducing fuel use and therefore economic costs. Visualization of historical environmental and vessel behaviour will help tuna companies detect improvement strategies. The system aims also to provide advice on potential strategies companies can follow. Purse seine is the fishing gear that contributes the most to yellowfin and skipjack tuna catches globally.
2 Oceanic Tuna Fisheries Immediate Operational Choices
The pilot’s main targets are on onboard energy efficiency to reduce fuel consumption and on condition-based maintenance of the propulsion system to reduce ship downtime and increase safety on board. This is done via optimization of the propulsion system operation to minimize fuel consumption. To reach these goals, ships are recording energy performance data with onboard systems and uploading the data periodically to cloud services. The data are available for analysis by onshore services, like company machinery superintendents. Data analytics have been used to analyse the recorded data and obtain ships’ energy consumption equations that are used for operational decision-making. The propulsion engine performance data have been analysed with machine learning techniques to develop models that inform of engine condition deviation from a healthy state. This deviation information is used to proactively participate in engine maintenance and inform in advance the ship’s technical staff about forthcoming problems or undetected problems. In this way, minor faults can be detected in advance and be solved without compromising vessel safety and operation before potentially becoming big failures.
Different solutions have been developed in this pilot for the technical staff on shore and the crew on board. IBM has implemented their event-based prediction (PROTON, PROactive Technology Online) component onboard two ships on a dedicated computer. VTT has employed their OpenVA component to develop the user interface (UI) for IBM PROTON onboard ships and for onshore analysis of data collected onboard. VTT has developed and implemented a server-based visualization and analysis tool to be used by fishing company technical staff on shore. EXUS has used their analytics framework to develop an engine fault detection tool based on historical engine performance data. EXUS has also developed the UI of the software and applied some of the solutions developed by VTT for the data collection and processing from Google Drive. The solutions have been tested by Echebastar Fleet on their vessels, while EHU (University of Basque Country) has coordinated the partner work in the pilot and also developed the fuel oil consumption equations based on the historical vessel performance data (fuel consumption model). The equations developed have been implemented in the pilot “Oceanic tuna fisheries planning” for energy saving decision-making.
The energy efficiency target has been pursued through a ship fuel consumption model that is used together with weather models to provide an efficient route from point A to point B. The energy efficiency model also assists the crew in deciding which propulsion mode (constant speed or variable speed) and which ship speed are most suitable from an energy efficiency perspective to get from point A to point B. The developed models use common parameters but have specific coefficients for each ship and offer great accuracy in fuel consumption prediction depending on ship speed. Skippers use this information for decision-making when deciding where to go next during fishing operations. Offline software for monitoring ship performance has been developed and implemented. The offline monitoring software is used by the ship owner’s technical staff from shore to collaborate with the crew on board for a more efficient fishing operation.
VTT has worked with their OpenVA platform to develop useful and user-friendly visualization tools for the recorded data (ship owner technical staff). The ships are uploading a daily file with operational data to Google Drive. The visualization tool opens these files, makes necessary calculations and obtains several performance indicators (Fig. 29.1).

VTT OpenVA visualization for vessel key performance indicator (KPI) comparisons
The propulsion system has been modelled by EXUS to define a machinery healthy state condition (i.e. the model provides engine parameters based on some inputs defining engine condition). This baseline condition is used as a reference to monitor changes of the engine’s condition and predict faults in advance, prior to their occurrence. In this way, machinery fault chances will be reduced along with main engine downtime. Note that the main engine is the ship’s only propulsion engine. Hence, with reduced main engine downtime and machinery failures, the overall safety on board will increase. Energy efficiency will also improve with a good condition of the engine. IBM has used their PROTON system to develop an event-driven application for main engine predictive monitoring. The system has been installed on two ships on dedicated computers. IBM PROTON receives engine operation and performance data from the ship’s data logger. When the engine is operating in a steady condition, performance data (i.e. pressures and temperatures) are processed in order to detect possible deviations from normal operation conditions. If an event is detected (i.e. deviation from normal condition in engine) a warning will be issued to inform crew. If the event remains and the condition gets worse, an alarm is issued to the crew to be aware and check the evolution of the faulty variable. VTT has implemented a user-friendly visualization interface for the crew on board. The interface enables the vessel crew to assess machinery performance and improve maintenance planning (Fig. 29.2).

IBM PROTON Dashboard visualization implemented by VTT
3 Oceanic Tuna Fisheries Planning
An important element of this pilot is improving the computational capacity to accommodate the data acquisition, processing, analysis and visualization components. Our solution is divided into three parts (Fig. 29.3). The first part is dedicated to the storage of data and components (software) making up this platform solution. This first part provides not only the storage, but also the computational capacity to run these components. Modelling and analysis are the second part of the solution, with existing and new algorithms for advice on species distribution and vessel behaviour. Finally, the third part deals with results from previous parts to visualize them and provide fisheries operators and managers with user-friendly advice.

Conceptual diagram of oceanic tuna fisheries planning
The big data cluster is designed specifically for storing and analysing huge structured and unstructured data volumes in a distributed environment. All the servers are virtual machines, which allow to change the number of processors, RAM memory and disk space for the work assigned. In the case of repetitive high workload jobs, like merging spatially data, an HPC cluster configured with the Rocks Cluster distribution is employed if the Postgres SQL server lacks enough computation power.
The data processing scheme is shown in Fig. 29.4. Each data processing step is represented by a rectangle, within which the main steps and their programming language are detailed. Two data sources were processed: environmental variables and tuna fisheries data. Previously developed and tested scripts were used when possible. Then, both data sources were merged into a geographical grid, and to do so different grid templates were created by varying the cell resolution (i.e. 0.5°, 0.25°, 0.1°). The first step was to download the environmental data from Copernicus and JPL at the time frames needed and in daily steps for the studied geographical area. After that, two derived variables were calculated (i.e. fronts of chlorophyll concentration (CHL) and fronts in sea surface temperature (SST)). Finally, the environmental variables were merged with the grid template in a daily time step.

Data processing flow scheme
Tuna fisheries data processing also started with the raw data collection. Due to the different sources of fisheries data, different formats and errors were present, making it necessary to clean and reformat the different raw data sets. VMS and logbook data were combined to calculate the fishing and cruising effort by vessel. Observer data came in two parts: vessel activity and set information. The former has trip information such as trip start and end date, speed, and latitude and longitude, among others. The latter has catch information, in our case species and kg fished. The last source of data comes from the echo-sounder buoys attached to fishing aggregating devices (FADs), these data sets provide accurate information on buoy geo-location and rough estimates of fish biomass aggregated underneath.
Finally, environmental variables and tuna fisheries data were merged with the possibility of using different time scales such as daily, weekly or monthly intervals.
For the historical retrieval of environmental data the APIs provided by the data providers (motu-Python for Copernicus and Python script using OPeNDAP) invoked from bash scripts were used. These products provided environmental variables (i.e. temperature, salinity, currents, nutrients and chlorophyll) at resolutions that ranged from 4 km2 to 50 km2 (Fig. 29.5).

Example of Copernicus data catalogue for a model projection covering all the world’s oceans
Each product was chosen based on its temporal and spatial resolution, choosing those covering the tropical areas where these fleets operate, and the level of observational data processing focusing on the processed data, i.e. Level 3 and 4 if available, and environmental parameters provided in each catalogue. Each catalogue provides several variables or potential predictors for identified areas with high probability of tuna occurrence. Chlorophyll (Chl-a), sea surface height (SSH) and sea surface temperature (SST) have been identified as good potential tuna distribution predictors as they enable detection of oceanic fronts and productivity changes (i.e. available food for fish). While these indicators focus on tuna distribution based on their feeding behaviour, oxygen, thermocline depth and gradient or subsurface temperature are good predictors of fish physiology vertical and horizontal constraints (i.e. oxygen availability for efficient energy use). On the other hand, weather forecasts limit fleet distribution by avoiding areas with strong winds and swell where fishing operations are unviable (Fig. 29.6).

Example of Copernicus data downloaded using SPACEBEL component from a catalogue. Chlorophyll in the left and Oxygen in the right
Ocean fronts are the interfaces between water masses. These hydrographic features have been recognized to enhance primary and secondary production and promote the aggregation of commercial pelagic fish species. The ocean fronts for SST and chlorophyll were calculated with the Belkin and O’Reilly algorithm (Belkin and O'Reilly, 2009) implemented in the grec R library (R Core Team, 2018) (Fig. 29.7).

Example of sea fronts. Chlorophyll in the left and sea surface temperature in the right
In order to store, access and process non-raster data sets the PostgreSQL with PostGIS spatial extension was used. This database was fed with all the fishery and vessel data for use in the machine learning pipeline. Machine learning approaches that are characterized by having an explicit underlying probability model (i.e. provides a probability of the outcome, rather than simply a forecast without uncertainty) are being evaluated for application in Indian Ocean tuna fisheries. Bayesian networks (BNs) are a paradigm suitable to deal with uncertainty, providing an intuitive interface to data. These intuitive properties of Bayesian networks and their explicit consideration of uncertainties enhance domain experts’ confidence in their forecasts [7,8,9, 13]. This machine learning approach was used here to forecast the likelihood of finding high tuna biomass.
A pipeline of supervised classification methods which include selection and discretization of features, and the learning of a Naïve Bayes classifier (i.e. a type of Bayesian network) was applied [7]. The application of this methodology selected the following features or predictors: Chl-a, net primary production, temperature, salinity, oxygen, nutrients and current velocity. It was first applied only to past captures from public sources yielding poor results. However, the results improved significantly when additional data from a tuna company were used. This highlights the importance of working in close partnership with industry. The final model could correctly forecast the areas lacking tuna 80% of times (i.e. helps to identify areas to be avoided that would waste fuel). The model was also able to forecast areas of high biomass with only a 25% of false positives, so it was right 75% of the times. The model was validated using tenfold stratified cross-validation (Fig. 29.8).

Map showing areas of higher probability of finding high tuna biomass. Green circles show successful fishing attempts and red circles failed fishing attemps. Thin black lines show exclusive economic zones (EEZs) territorial waters where only country fleets and other authorized fleets can fish
The historical vessel performance data have been collected and analysed to calculate key performance indicator (KPI) values and obtain the vessel sailing energy consumption model. The vessels analysed started operation in years 2014 and 2015, and historical data since the start of operations have been used for KPI calculation. The data used for KPI calculation correspond to the period 2015–2018 (Table 29.1).
All three ships used as a reference to obtain the KPIs have undergone repairs during the period analysed (2017–2018), which had an impact on KPIs estimations. When vessels go for repair work, they are usually stopped for a 30- to 60-day period. During the repair period the vessel is not sailing. Hence, variables like fuel consumption and sailed nautical miles suffer a reduction in years when repair works take place. When analysing the KPIs it is necessary to consider impacts from regulatory changes in the Indian Ocean during the period analysed. For example, during 2017 new regulations by the Indian Ocean Tuna Commission (IOTC) entered into force regarding tuna fishing. Quotas for yellowfin tuna were established and ships had to stop temporarily fishing during the year. This means that years with quotas are very different from an energy expenditure viewpoint compared with the rest of unrestricted fishing years. Due to this, a clear decline in total fishing days and total sailed nautical miles was observed after 2016.
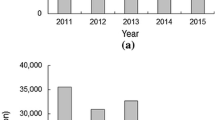
Although a marked decline in sailed miles and sailed days is clearly observed in Fig. 29.9, there is no parallel tendency in catches. Instead, catches have increased even considering that sailing days and consumed fuel has been reduced. Thus, fuel oil consumed per kilogram of catch has been noticeable reduced. All five ships of this fleet reduced their fuel consumption in 2017 by an average 19% (range 4–30% reduction). However, it is not possible to distinguish how much of this improvement in the ratio of catch to fuel consumption is due to DataBio technologies or other continuous and ongoing initiatives to improve their operations and sustainability such as the MSC certification, bioFADs or new Indian Ocean fisheries management regulations (Fig. 29.10).

Total sailed nautical miles and fishing days (three vessels)

Total consumed fuel oil and fuel oil consumed per kg of catch (three vessels)
References
Basurko, O. C., Gabiña, G., & Uriondo, Z. (2013). Energy performance of fishing vessels and potential savings. Journal of Cleaner Production, 54, 30–40. https://doi.org/10.1016/j.jclepro.2013.05.024.
Suuronen, P., Chopin, F., Glass, C., Løkkeborg, S., Matsushita, Y., Queirolo, D., & Rihan, D. (2012). Low impact and fuel efficient fishing—looking beyond the horizon. Fisheries Research, 119, 135–146. https://doi.org/10.1016/j.fishres.2011.12.009.
Parker, R. W., Blanchard, J. L., Gardner, C., Green, B. S., Hartmann, K., Tyedmers, P. H., & Watson, R. A. (2018). Fuel use and greenhouse gas emissions of world fisheries. Nature Climate Change, 8(4), 333–337. https://doi.org/10.1038/s41558-018-0117-x.
Parker, R. W., & Tyedmers, P. H. (2014). Fuel consumption of global fishing fleets: Current understanding and knowledge gaps. Fish and Fisheries, 16(4), 684–696. https://doi.org/10.1111/faf.12087.
McCauley, D. J., Woods, P., Sullivan, B., Bergman, B., Jablonicky, C., Roan, A., Hirshfield, M., Boerder, K., & Worm, B. (2016). Ending hide and seek at sea. Science, 351(6278), 1148–1150. https://doi.org/10.1126/science.aad5686
Hu, H., Wen, Y., Chua, T. S., & Li, X. (2014). Toward scalable systems for Big Data analytics: A technology tutorial. IEEE Access, 2, 652–687. https://doi.org/10.1109/ACCESS.2014.2332453.
Fernandes, J. A., Irigoien, X., Goikoetxea, N., Lozano, J. A., Inza, I., Pérez, A., & Bode, A. (2010). Fish recruitment prediction, using robust supervised classification methods. Ecological Modelling, 221(2), 338–352. https://doi.org/10.1016/j.ecolmodel.2009.09.020.
Fernandes, J. A., Lozano, J. A., Inza, I., Irigoien, X., Pérez, A., & Rodríguez, J. D. (2013). Supervised pre-processing approaches in multiple class variables classification for fish recruitment forecasting. Environmental Modelling & Software, 40, 245–254. https://doi.org/10.1016/j.envsoft.2012.10.001.
Fernandes, J. A., Irigoien, X., Lozano, J. A., Inza, I., Goikoetxea, N., & Pérez, A. (2015). Evaluating machine-learning techniques for recruitment forecasting of seven North East Atlantic fish species. Ecological Informatics, 25, 35–42. https://doi.org/10.1016/j.ecoinf.2014.11.004.
Agra, A., Christiansen, M., Delgado, A., & Hvattum, L. M. (2015). A maritime inventory routing problem with stochastic sailing and port times. Computers & Operations Research, 61, 18–30. https://doi.org/10.1016/j.cor.2015.01.008.
Christiansen, M., Fagerholt, K., Nygreen, B., & Ronen, D. (2013). Ship routing and scheduling in the new millennium. European Journal of Operational Research, 228(3), 467–483. https://doi.org/10.1016/j.ejor.2012.12.002.
Fagerholt, K. (2004). Designing optimal routes in a liner shipping problem. Maritime Policy & Management, 31(4), 259–268. https://doi.org/10.1080/0308883042000259819.
Granado, I., Basurko, O. C., Rubio, A., Ferrer, L., Hernández-González, J., Epelde, I., & Fernandes, J. A. (2019). Beach litter forecasting on the south-eastern coast of the Bay of Biscay: A Bayesian networks approach. Continental Shelf Research, 180, 14–23. https://doi.org/10.1016/j.csr.2019.04.016.
Acknowledgements
The authors would like to thank the tuna fisheries company Echebastar S.L, for providing access to important data and for participating in discussions. VTT, IBM, EXUS have contributed to the development of the fuel consumption and engine failure software. These contributions have been valuable for the presented work and for this chapter. Jefferson Murua (AZTI) has provided significant feedback for the improvement and quality of this chapter. The work leading to this chapter has been possible mainly through the DataBio project funded from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 732064.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2021 The Author(s)
About this chapter

Cite this chapter
Fernandes, J.A., Uriondo, Z., Granado, I., Quincoces, I. (2021). Tuna Fisheries Fuel Consumption Reduction and Safer Operations. In: Södergård, C., Mildorf, T., Habyarimana, E., Berre, A.J., Fernandes, J.A., Zinke-Wehlmann, C. (eds) Big Data in Bioeconomy. Springer, Cham. https://doi.org/10.1007/978-3-030-71069-9_29
Download citation
DOI: https://doi.org/10.1007/978-3-030-71069-9_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-71068-2
Online ISBN: 978-3-030-71069-9
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)