
Abstract
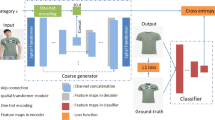
Clothing parsing has been actively studied in the vision community in recent years. Inspired by the color coherence for clothing and the self-attention mechanism, this paper proposes a Triple Attention Network (TANet) equipped with a color attention module, a position attention module and a channel attention module, to facilitate fine-grained segmentation of clothing images. Concretely, the color attention module is introduced for harvesting color coherence, which selectively aggregates the color feature of clothing. The position attention module and the channel attention module are designed to emphasize the semantic interdependencies in spatial and channel dimensions respectively. The outputs of the three attention modules are incorporated to further improve feature representation which contributes to more precise clothing parsing results. The proposed TANet has achieved 69.54\(\%\) mIoU - a promising clothing parsing performance on ModaNet, the latest large-scale clothing parsing dataset. Especially, the color attention module is also demonstrated to bring semantic consistency and precision improvement obviously. The source code is made available in the public domain.
Supported by National Natural Science Foundation of China (No. 61170093).
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Tangseng, P., Wu, Z., Yamaguchi, K.: Looking at outfit to parse clothing. CoRR abs/1703.01386 (2017). http://arxiv.org/abs/1703.01386
Yamaguchi, K., Kiapour, M.H., Ortiz, L.E., Berg, T.L.: Retrieving similar styles to parse clothing. IEEE Trans. Pattern Anal. Mach. Intell. 37(5), 1028–1040 (2015). https://doi.org/10.1109/TPAMI.2014.2353624
Simo-Serra, E., Fidler, S., Moreno-Noguer, F., Urtasun, R.: A high performance CRF model for clothes parsing. In: Cremers, D., Reid, I., Saito, H., Yang, M.-H. (eds.) ACCV 2014. LNCS, vol. 9005, pp. 64–81. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-16811-1_5
Liu, S., et al.: Fashion parsing with video context. IEEE Trans. Multimed. 17(8), 1347–1358 (2015). https://doi.org/10.1109/TMM.2015.2443559
Ge, Y., Zhang, R., Wang, X., Tang, X., Luo, P.: DeepFashion2: a versatile benchmark for detection, pose estimation, segmentation and re-identfication of clothing images. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
Yang, W., Luo, P., Lin, L.: Clothing co-parsing by joint image segmentation and labeling. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2014
Liu, Z., Luo, P., Qiu, S., Wang, X., Tang, X.: DeepFashion: powering robust clothes recognition and retrieval with rich annotations. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
Hsiao, W.L., Grauman, K.: Creating capsule wardrobes from fashion images. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018
Yamaguchi, K., Kiapour, M.H., Ortiz, L.E., Berg, T.L.: Parsing clothing in fashion photographs. In: 2012 IEEE Conference on Computer Vision and Pattern Recognition, pp. 3570–3577, June 2012. https://doi.org/10.1109/CVPR.2012.6248101
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015
Fu, J., et al.: Dual attention network for scene segmentation. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
Fan, X., Luo, H., Zhang, X., He, L., Zhang, C., Jiang, W.: SCPNet: spatial-channel parallelism network for joint holistic and partial person re-identification. In: ACCV (2018)
Su, K., Yu, D., Xu, Z., Geng, X., Wang, C.: Multi-person pose estimation with enhanced channel-wise and spatial information. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
Chu, X., Yang, W., Ouyang, W., Ma, C., Yuille, A.L., Wang, X.: Multi-context attention for human pose estimation. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017
Zheng, S., Yang, F., Kiapour, M.H., Piramuthu, R.: ModaNet: a large-scale street fashion dataset with polygon annotations. In: Proceedings of the 26th ACM International Conference on Multimedia, MM 2018, pp. 1670–1678. ACM, New York (2018). https://doi.org/10.1145/3240508.3240652
Liu, S., et al.: Fashion parsing with weak color-category labels. IEEE Trans. Multimed. 16(1), 253–265 (2014). https://doi.org/10.1109/TMM.2013.2285526
Chen, L., Papandreou, G., Schro, F., Adam, H.: Rethinking atrous convolution for semantic image segmentation. CoRR abs/1706.05587 (2017). http://arxiv.org/abs/1706.05587
Zheng, S., et al.: Conditional random fields as recurrent neural networks. In: International Conference on Computer Vision (ICCV) (2015)
Zhao, H., Shi, J., Qi, X., Wang, X., Jia, J.: Pyramid scene parsing network. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017
Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018
Huang, Z., Wang, X., Huang, L., Huang, C., Wei, Y., Liu, W.: CCNet: criss-cross attention for semantic segmentation. In: The IEEE International Conference on Computer Vision (ICCV), October 2019
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
Huang, Z., Wei, Y., Wang, X., Liu, W.: A pytorch semantic segmentation toolbox (2018). https://github.com/speedinghzl/pytorch-segmentation-toolbox
Bulò, S.R., Porzi, L., Kontschieder, P.: In-place activated batchnorm for memory-optimized training of DNNs. CoRR abs/1712.02616 (2017). http://arxiv.org/abs/1712.02616
Chen, L., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 40(4), 834–848 (2018). https://doi.org/10.1109/TPAMI.2017.2699184
Chen, L.C., Zhu, Y., Papandreou, G., Schro, F., Adam, H.: Encoder-decoder with atrous separable convolution for semantic image segmentation. In: The European Conference on Computer Vision (ECCV), September 2018
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
He, R., Cheng, M., Xiong, M., Qin, X., Liu, J., Hu, X. (2020). Triple Attention Network for Clothing Parsing. In: Yang, H., Pasupa, K., Leung, A.CS., Kwok, J.T., Chan, J.H., King, I. (eds) Neural Information Processing. ICONIP 2020. Lecture Notes in Computer Science(), vol 12532. Springer, Cham. https://doi.org/10.1007/978-3-030-63830-6_49
Download citation
DOI: https://doi.org/10.1007/978-3-030-63830-6_49
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-63829-0
Online ISBN: 978-3-030-63830-6
eBook Packages: Computer ScienceComputer Science (R0)