
Abstract
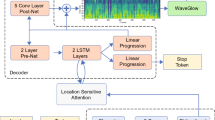
Speech synthesis is the artificial production of human speech. A typical text-to-speech system converts a language text into a waveform. There exist many English TTS systems that produce mature, natural, and human-like speech synthesizers. In contrast, other languages, including Arabic, have not been considered until recently. Existing Arabic speech synthesis solutions are slow, of low quality, and the naturalness of synthesized speech is inferior to the English synthesizers. They also lack essential speech key factors such as intonation, stress, and rhythm. Different works were proposed to solve those issues, including the use of concatenative methods such as unit selection or parametric methods. However, they required a lot of laborious work and domain expertise. Another reason for such poor performance of Arabic speech synthesizers is the lack of speech corpora, unlike English that has many publicly available corpora (LjSpeech, https://keithito.com/LJ-Speech-Dataset/., Blizzard 2012, http://www.cstr.ed.ac.uk/projects/blizzard/2012/phase_one/.) and audiobooks. This work describes how to generate high quality, natural, and human-like Arabic speech using an end-to-end neural deep network architecture. This work uses just \(\langle \)text, audio\(\rangle \) pairs with a relatively small amount of recorded audio samples with a total of 2.41 h. It illustrates how to use English character embedding despite using diacritic Arabic characters as input and how to preprocess these audio samples to achieve the best results.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
Notes
- 1.
Distinct speech sound or gesture, regardless of whether the exact sound is critical to the meanings of words.
- 2.
Consists of two connected half phones that start in the middle of the first phone and end in the middle of the second phone.
- 3.
A spectrogram is a visual representation of the spectrum of frequencies of a signal as it varies with time.
- 4.
Orthogonal matrix is a square matrix whose columns and rows are orthogonal unit vectors.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
References
Hunt, A.J., Black, A.W.: Unit selection in a concatenative speech synthesis system using a large speech database. In: 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings, pp. 373–376 (1996)
Hamon, C., Mouline, E., Charpentier, F.: A diphone synthesis system based on time-domain prosodic modifications of speech. In: International Conference on Acoustics, Speech, and Signal Processing, pp. 238–241 (1989)
Tokuda, K., Nankaku, Y., Toda, T., Zen, H., Yamagishi, J., Oura, K.: Speech synthesis based on hidden Markov models. In: Proceedings of the IEEE, pp. 1234–1252 (2013)
Yu, K., Young, S.: Continuous F0 modeling for HMM based statistical parametric speech synthesis. In: IEEE Transactions on Audio, Speech, and Language Processing, pp. 1071–1079 (2011)
van den Oord, A., et al.: WaveNet: a generative model for raw audio. CoRR arXiv:1609.03499 (2016)
van den Oord, A., Kalchbrenner, N., Kavukcuoglu, K.: Pixel recurrent neural networks. CoRR arXiv:1601.06759 (2016)
Arik, S.O., et al.: Deep voice: real-time neural text-to-speech. CoRR arXiv:1702.07825 (2017)
Wang, Y., et al.: Tacotron: a fully end-to-end text-to-speech synthesis model. CoRR arXiv:1703.10135 (2017)
Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. In: Advances in Neural Information Processing Systems, pp. 3104–3112 (2014)
Bengio, S., Vinyals, O., Jaitly, N., Shazeer, N.: Scheduled sampling for sequence prediction with recurrent neural networks. In: Advances in Neural Information Processing Systems, pp. 1171–1179 (2015)
Shen, J., et al.: Natural TTS synthesis by conditioning WaveNet on Mel Spectrogram predictions. CoRR arXiv:1712.05884 (2017)
Chorowski, J.K., Bahdanau, D., Serdyuk, D., Cho, K., Bengio, Y.: Attention-based models for speech recognition. In: Advances in Neural Information Processing Systems, vol. 28, pp. 577–585 (2015)
El-Imam, Y.A.: An unrestricted vocabulary Arabic speech synthesis system. In: IEEE Transactions on Acoustics, Speech, and Signal Processing, pp. 1829–1845 (1989)
Abdel-Hamid, O., Abdou, S., Rashwan, M.: Improving Arabic HMM based speech synthesis quality. In: INTERSPEECH 2006 and 9th International Conference on Spoken Language Processing, INTER- SPEECH 2006 - ICSLP (2006)
Rebai, I., BenAyed, Y.: Arabic speech synthesis and diacritic recognition. Int. J. Speech Technol. 19, 485–494 (2016)
Halabi, N., Wald, M.: Phonetic inventory for an Arabic speech corpus. In: Proceedings of the Tenth International Conference on Language Resources and Evaluation, LREC’16, pp. 734–738 (2016)
Zangar, I., Mnasri, Z., Colotte, V., Jouvet, D., Houidhek, A.: Duration modeling using DNN for Arabic speech synthesis. In: 9th International Conference on Speech Prosody (2018)
Prenger, R., Valle, R., Catanzaro, B.: WaveGlow: a flowbased generative network for speech synthesis. CoRR arXiv:1811.00002 (2018)
Ioffe, S., Szegedy, C.: Batch normalization: accelerating deep network training by reducing internal covariate shift. In: International Conference on Machine Learning (ICML) (2015)
Li, Y., Yuan, Y.: Convergence analysis of two-layer neural networks with ReLU activation. In: Advances in Neural Information Processing Systems, vol. 30, pp. 597–607 (2017)
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958 (2014)
Krueger, D., et al.: Zoneout: regularizing RNNs by randomly preserving hidden activations. In: International Conference on Learning Representations (ICLR) (2016)
Kingma, D.P., Dhariwal, P.: Glow: generative flow with invertible 1 \(\times \) 1 convolutions. CoRR arXiv:1807.03039 (2018)
Dinh, L., Sohl-Dickstein, J., Bengio, S.: Density estimation using Real NVP. CoRR arXiv:1605.08803 (2016)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. In: Bengio, Y., LeCun, Y. (eds.) 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015, Conference Track Proceedings (2015)
Ali, A.H., Magdy, M., Alfawzy, M., Ghaly, M., Abbas, H.: Arabic speech synthesis using deep neural networks. In: Proceedings of the International Conference on Communications, Signal Processing and their Applications, ICCSPA’ 20 (2020, to appear)
Acknowledgment
The authors would like to thank The Bibliotheca Alexandrina for providing the computing resources through their Supercomputing Facility https://hpc.bibalex.org.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Fahmy, F.K., Khalil, M.I., Abbas, H.M. (2020). A Transfer Learning End-to-End Arabic Text-To-Speech (TTS) Deep Architecture. In: Schilling, FP., Stadelmann, T. (eds) Artificial Neural Networks in Pattern Recognition. ANNPR 2020. Lecture Notes in Computer Science(), vol 12294. Springer, Cham. https://doi.org/10.1007/978-3-030-58309-5_22
Download citation
DOI: https://doi.org/10.1007/978-3-030-58309-5_22
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-58308-8
Online ISBN: 978-3-030-58309-5
eBook Packages: Computer ScienceComputer Science (R0)
