
Abstract
We present several improvements to the framework of differential-linear attacks with a special focus on ARX ciphers. As a demonstration of their impact, we apply them to Chaskey and ChaCha and we are able to significantly improve upon the best attacks published so far.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Symmetric cryptographic primitives play major roles in virtually any cryptographic scheme and any security-related application. The main reason for this massive deployment of symmetric primitives, i.e. (tweakable) block ciphers, stream ciphers, hash functions, or cryptographic permutations, is their significant performance advantage. Symmetric primitives usually outperform other cryptographic schemes by order(s) of magnitude.
One class of design of symmetric primitives that is inherently motivated by (software) efficiency is an ARX-based design. ARX is short for addition (modulo a power of two), word-wise rotation and XOR. Indeed, ciphers following this framework are composed of those operations and avoid the computation of smaller S-boxes through look-up tables. As most CPUs have hardware support for all those operations, in particular an addition unit and a barrel shifter implemented directly in hardware, executing them on such CPUs based on a suitable register size is inherently fast.
The block cipher FEAL [27] was probably the first ARX cipher presented in the literature and by now there are several state-of-the-art ciphers that follow this approach. One of the most important (family) of ARX ciphers is certainly the one formed by Salsa20, ChaCha and their variants (see [6, 7]). Designed by Bernstein, those ciphers are now the default replacement for RC4 in TLS due to the high efficiency and simplicity of their implementations and are thus one of the most widely-used ciphers in practice. Besides being used in TLS, ChaCha is also deployed in several other products and in particular used as a building block in the popular hash functions Blake and Blake2 [2, 3].
Clearly, the ARX-based design approach is not restricted to only stream-ciphers, but also allows the design of efficient block ciphers (e.g., Sparx [15]), cryptographic permutations (e.g., Sparkle [5]), and message authentication codes (MACs). For the latter, Chaskey [24] is among the most prominent examples.
Besides the advantage of having efficient implementations, there are also good reasons for ARX-based designs when it comes to security. The algebraic degree of ARX ciphers is usually high after only a very few rounds, as the carry bit within one modular addition already reaches almost maximal degree. Structural attacks like integral [18] or invariant attacks [28] are less of a concern and rotational cryptanalysis [17], originally invented for ARX ciphers, is in most cases very efficiently prevented by the XOR of constants.
When it comes to differential [9] and linear attacks [23], ARX-based designs often show a peculiar behaviour. For a small number of rounds, i.e., only very few modular additions, the differential probabilities (resp., absolute linear correlations) are very high. In particular for a single modular addition, those are equal to 1 due to the linear behaviour of the most and least significant bits. Moreover, for a single modular addition, the differential probabilities and linear correlations are well understood and we have at hand nice and efficient formulas for their computation [21, 29]. In the case of (dependent) chains of modular additions and XORs, the situation is different and often checking the probabilities experimentally is the best way to evaluate the behaviour.
Thus, while a few rounds are very weak, for a well-crafted ARX scheme, the probabilities of differentials and the absolute correlations of linear approximations decrease very quickly with increasing the number of rounds. Indeed, this property led to the long-trail strategy for designing ARX-based ciphers [15].
Now, for symmetric primitives, the existence of strong differentials and linear approximations for a few rounds with a rapid decrease of probabilities (resp. absolute correlations) is exactly the situation in which considering differential-linear attacks [19] is promising. In a nutshell, differential-linear attacks combine a differential with probability p for the first r rounds of the cipher and a linear approximation with correlation q for the next t rounds into a linear approximation for \(r+t\) rounds with correlation \(pq^2\) that can be turned into an attack with data complexity of roughly \(p^{-2}q^{-4}\).
Indeed, that said, it is not surprising that the best attacks against many ARX constructions, including ChaCha and Chaskey, are differential-linear attacks [11, 14, 20]. Our work builds upon those ideas and improves differential-linear attacks on ARX ciphers along several dimensions.
1.1 Our Contribution
In this paper we present the best known attacks on ChaCha and Chaskey. Our improvements over prior work are based on improvements in the differential, as well as the linear part and the key-recovery part of differential-linear attacks.
Differential Part. For the differential part, our observation is both simple and effective. Recall that for a differential-linear attack, one needs many (roughly \(q^{-4}\)) pairs to fulfill the difference in the first part of the cipher, that is many right pairs for the differential. Now, imagine that an attacker could construct many right pairs with probability (close to) one, given only a single right pair. This would immediately reduce the data complexity of the attack by a factor of \(p^{-1}\). As we will see, this situation is rather likely to occur for a few rounds of many ARX ciphers and in particular occurs for ChaCha and Chaskey. The details of those improvements are presented in Sect. 3.
Linear Part. For the linear part, our first observation is that often it is beneficial to not restrict to a single mask but rather consider multiple linear approximations. As we detail in Sect. 4, this nicely combines with an improved version of the partitioning technique for ARX ciphers [8, 20], that splits the space of ciphertexts into subsets in order to increase the correlation of linear approximations. The starting point of our attacks is a new way of partitioning the ciphertexts, summarized in Lemma 3. Note that, although we use multiple linear masks in the attack, because of partitioning the ciphertexts, we use only a single linear mask for each ciphertext. In this way we avoid possible dependencies that would be hard to analyze otherwise.
Key Recovery. Related to the improvement in the linear part, we present a significant speed-up in the key recovery part. Here, the main observation is that after considering multiple masks and the partitioning technique, several key bits actually appear only linearly in the approximations. In particular, their value does not affect the absolute value of the correlation but rather the sign only. This observation allows us to, instead of guessing those keys as done in previous attacks, recover them by applying the Fast Walsh-Hadamard Transform (FWHT). Similar ideas have already been described in [12]. Details of this approach are given in Sect. 4.
Putting those improvements into one framework and applying the framework to round-reduced variants of ChaCha and Chaskey results in significantly reduced attack complexities. Our attacks with the corresponding complexities are summarized in Table 1, together with a comparison to the best attacks published so far.Footnote 1 In particular for ChaCha it is important to add that, as those attacks are on round-reduced variants of the ciphers only, they do not pose any threat on the full-round version of the ciphers. Rather, those attacks strengthen our trust in the design. We expect that our improvements have applications to other ciphers as well, especially ARX-based designs.
2 Preliminaries
By \(\oplus \) we denote the XOR operation, i.e., addition in \(\mathbb {F}_2^n\) and by \(+\) we either denote the addition in \(\mathbb {Z}\), or the modular addition \(\mod 2^n\) for elements in \(\mathbb {F}_2^n\), depending on the context. For \(x \in \mathbb {F}_2^n\), we denote by \(\bar{x}\) the bitwise complement of x. Given a set \(\mathcal {S} \subseteq \mathbb {F}_2^n\) and a Boolean function \(f :\mathbb {F}_2^n \rightarrow \mathbb {F}_2\), we define
We denote the i-th unit vector of a binary vector space by [i] and the sum of unit vectors \([i_1] \oplus [i_2] \oplus \dots \oplus [i_t]\) by \([i_1,i_2,\dots ,i_t]\). Given a vector \(x \in \mathbb {F}_2^n\), x[i] denotes the i-th bit of x, and \(x[i_1,i_2,\dots ,i_t]\) denotes \(\bigoplus _{j=1}^t x[i_j]\). For \(\gamma ,x \in \mathbb {F}_2^n\), we define the inner product by \(\langle \gamma , x \rangle = \bigoplus _{i=0}^{n-1} \gamma [i]x[i] \mod 2\). In particular, \(x[i_1,i_2,\dots ,i_t]=\langle x, [i_1,i_2,\dots ,i_t] \rangle \).
In the remainder of this paper we assume that, when \(\mathcal {S} \subseteq \mathbb {F}_2^n\) is a (sufficiently large) subset of \(\mathbb {F}_2^n\) of random samples, \(\mathbf {Cor}_{x \in \mathcal {S}}\left[ f(x) \right] \) is a good approximation for \(\mathbf {Cor}_{x \in \mathbb {F}_2^n}\left[ f(x) \right] \). In other words, we assume that the empirical correlations obtained by sampling for a sufficiently large number of messages closely match the actual correlations.
We denote by \(\mathcal {N}(\mu ,\sigma ^2)\) the normal distribution with mean \(\mu \) and variance \(\sigma ^2\). By \(\varPhi \) we denote the cumulative distribution function of the standard normal distribution \(\mathcal {N}(0,1)\). Thus if \(X \sim \mathcal {N}(\mu ,\sigma ^2)\), it holds that

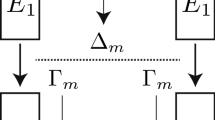
The structure of a classical differential-linear distinguisher.

A differential-linear distinguisher with experimental evaluation of the correlation r.
2.1 Differential-Linear Attacks
We first recall the basic variant of differential-linear cryptanalysis as introduced by Langford and Hellman [19]. Figure 1 shows the overview of the distinguisher. An entire cipher E is divided into two sub ciphers \(E_1\) and \(E_2\), such that \(E = E_2 \circ E_1\), and a differential distinguisher and a linear distinguisher are applied to the first and second parts, respectively.
In particular, assume that the differential \(\varDelta _{\mathrm{in}}\overset{E_1}{\rightarrow } \varDelta _m\) holds with probability
Let us further assume that the linear approximation \(\varGamma _m \overset{E_2}{\rightarrow } \varGamma _{\mathrm{out}}\) is satisfied with correlation \(\mathbf {Cor}_{x \in \mathbb {F}_2^n}\left[ \langle \varGamma _m, x\rangle \oplus \langle \varGamma _{\mathrm{out}}, E_2(x)\rangle \right] = q\). The differential-linear distinguisher exploits the fact that, under the assumption that \(E_1(x)\) and E(x) are independent random variables, we have
Therefore, by preparing \(\epsilon p^{-2}q^{-4}\) pairs of chosen plaintexts \((x, \tilde{x})\), for \(\tilde{x} = x\,\oplus \,\varDelta _{\mathrm{in}}\), where \(\epsilon \in \mathbb {N}\) is a small constant, one can distinguish the cipher from a PRP.
In practice, there might be a problem with the assumption that \(E_1(x)\) and E(x) are independent, resulting in wrong estimates for the correlation. To provide a better justification of this independence assumption (and in order to improve attack complexities) , adding a middle part is a simple solution and usually done in recent attacks (as well as in ours). Here, the cipher E is divided into three sub ciphers \(E_1, E_m\) and \(E_2\) such that \(E = E_2\,\circ \,E_m\,\circ \,E_1\) and the middle part \(E_m\) is experimentally evaluated. In particular, let
where \(\mathcal {S}\) denotes the set of samples over which the correlation is computed. Then, the total correlation in Eq. 1 can be estimated as \(p rq^2\). Recently, as a theoretical support for this approach the Differential-Linear Connectivity Table (DLCT) [4] has been introduced. The overall attack framework is depicted in Fig. 2 and we will use this description in the remainder of the paper.
2.2 Partitioning Technique for ARX-Based Designs
Partitioning allows to increase the correlation of the differential-linear distinguisher by deriving linear equations that hold conditioned on ciphertext and key bits. We first recall the partitioning technique as used in [20]. Let \(a,b \in \mathbb {F}_2^m\) and let \(s = a + b\). When \(i=0\) (lsb), the modular addition for bit i becomes linear, i.e., \(s[0] = a[0] \oplus b[0]\). Of course, for \(i>0\), computing the i-th output bit of modular addition is not linear. Still, by restricting (a, b) to be in a specific subset, we might obtain other linear relations. In previous work, the following formula on s[i] was derived.
Lemma 1
([20]). Let \(a,b \in \mathbb {F}_2^m\) and \(s = a+b\). For \(i \ge 2\), we have
Let us now consider two m-bit words \(z_0\) and \(z_1\) and a modular addition operation
as depicted in Fig. 5. F might correspond to a single branch of a wider ARX-based design. In the attacks we present later, we are interested in the value \(z_0[i]\). For this, we cannot apply Lemma 1 directly since \(z_0[i]\) is obtained by modular subtraction. However, for that case the following formula can be derived.
Lemma 2
Let \(i \ge 2\) and let \(\mathcal {S}_1 {:}{=} \{ (x_1,x_0) \in \mathbb {F}_2^{2m} \mid x_0[i-1] \ne x_1[i-1] \}\) and \(\mathcal {S}_2 {:}{=} \{ (x_1,x_0) \in \mathbb {F}_2^{2m} \mid x_0[i-1] = x_1[i-1] \text { and } x_0[i-2] \ne x_1[i-2]\}\). Then,
Clearly, \(\mathcal {S}_1\) and \(\mathcal {S}_2\) are disjoint sets. Note that Eq. 2 only holds for \(\frac{3}{4}\) of the data, since \(|\mathcal {S}_1| = 2^{-1}2^{2m}\) and \(|\mathcal {S}_2|=2^{-2}2^{2m}\).

Two linear trails with correlation \(2^{-1}\).
Due to the propagation rules for linear trails over modular addition, we may end up with multiple linear trails that are closely related to each other. As an example, Fig. 3 shows two possible trails, where [i] and \([i-1,i]\) denote the corresponding linear masks. The partitioning technique described above evaluates \(z_0[i]\), but we can expect that there is a highly-biased linear trail in which \(z_0[i-1] \oplus z_0[i]\) needs to be evaluated instead of \(z_0[i]\). In the trivial method, we apply the partitioning technique of Lemma 2 for \(z_0[i]\) and \(z_0[i-1]\) separately, which requires the knowledge of 3 bits of information from y in total. Our new partitioning method allows us to determine the partition only by knowing the same 2 bits of information as needed for evaluating the case of \(z_0[i]\), namely \((y_0[i-1] \oplus y_1[i-1])\) and \((y_0[i-2] \oplus y_1[i-2])\). This is especially helpful if y consists of the ciphertext XORed with the key, so we need to guess less key bits to evaluate the partition. In particular, the following relation holds, which is straightforward to proof. The intuition is that \(z_0[i-1]\) corresponds to the carry bit \(c[i-1]\) in the case of \((y_1,y_0) \in \mathcal {S}_3\) and \((y_1[i-2],y_1[i-1]) = (c[i-2],c[i-1])\) for \((y_1,y_0) \in \mathcal {S}_4\).
Lemma 3
Let \(i\ge 2\) and let \(\mathcal {S}_3 = \{ (x_1,x_0) \in \mathbb {F}_2^{2m} \mid x_0[i-1] = x_1[i-1] \}\) and \(\mathcal {S}_4 = \{ (x_1,x_0) \in \mathbb {F}_2^{2m} \mid x_0[i-1] \ne x_1[i-1] \text { and } x_0[i-2] \ne x_1[i-2]\}\). Then,
Again, \(\mathcal {S}_3\) and \(\mathcal {S}_4\) are disjoint and the equation above holds for \(\frac{3}{4}\) of the data.
3 The Differential Part – Finding Many Right Pairs
Let us be given a permutation \(E_1:\mathbb {F}_2^n \rightarrow \mathbb {F}_2^n\) and a differential \(\varDelta _{\mathrm{in}}\overset{E_1}{\rightarrow } \varDelta _m\) that holds with probability p. In other words,
In a usual differential-linear attack on a permutation \(E = E_2 \circ E_m \circ E_1\) as explained in Sect. 2.1, the internal structure of \(E_1\) could be in general arbitrary and we would consider randomly chosen \(x \in \mathbb {F}_2^n\) to observe the ciphertexts of the plaintext pairs \((x,x \oplus \varDelta _{\mathrm{in}})\). For each of those pairs, the differential over \(E_1\) is fulfilled with probability p, which results in a data complexity of roughly \(\epsilon p^{-2}r^{-2}q^{-4}\) for the differential-linear attack. In other words, we did not exploit the particular structure of \(E_1\). In particular, it would be helpful to know something about the distribution of right pairs \((x,x\oplus \varDelta _{\mathrm{in}}) \in \mathbb {F}_2^n \times \mathbb {F}_2^n\) that fulfill the above differential.
Let us denote by \(\mathcal {X}\) the set of all values that define right pairs for the differential, i.e.,
To amplify the correlation of a differential-linear distinguisher, instead of choosing random plaintexts from \(\mathbb {F}_2^n\), we would consider only those that are in \(\mathcal {X}\). In particular, we haveFootnote 2
Since the set \(\mathcal {X}\) might have a rather complicated structure, and is moreover key-dependent, we cannot use this directly for an arbitrary permutation \(E_1\). However, if \(\mathcal {X}\) employs a special structure such that, given one element \(x \in \mathcal {X}\), we can generate many other elements in \(\mathcal {X}\) for free,Footnote 3 independently of the secret key, we can use this to reduce the data complexity in a differential-linear attack. For example, if \(\mathcal {X}\) contains a large affine subspace \(\mathcal {A} = \mathcal {U} \oplus a\), given \(x \in \mathcal {A}\), we can generate (roughly) \(2^{|\dim \mathcal {U}|}\) elements in \(\mathcal {X}\) for free, namely all elements \(x \oplus u\), for \(u \in \mathcal {U}\). In order to obtain an effective distinguisher, we must be able to generate enough plaintext pairs to observe the correlation of the differential-linear approximation. In particular, we need to require \(|\mathcal {U}| > \epsilon r^{-2}q^{-4}\).
This will be exactly the situation we find in ChaCha. Here the number of rounds covered in the differential part is so small that it can be described by the independent application of two functions (see Sect. 3.1).
If \(|\mathcal {U}|\) is smaller than the threshold of \(\epsilon r^{-2}q^{-4}\), we can’t generate enough right pairs for free to obtain a distinguisher by this method and we might use a probabilistic approach, see Sect. 3.2.
3.1 Fully Independent Parts
Let \(E_1 :\mathbb {F}_2^n \rightarrow \mathbb {F}_2^n\) with \(n=2m\) be a parallel application of two block ciphers \(E_1^{(i)}:\mathbb {F}_2^m \rightarrow \mathbb {F}_2^m\), \(i \in \{0,1\}\) (for a fixed key), i.e.,
Suppose that, \(E_1^{(0)}\) employs a differential \(\alpha \overset{E_1^{(0)}}{\rightarrow }\beta \) with probability p. We consider the differential \(\varDelta _{\mathrm{in}}\overset{E_1}{\rightarrow } \varDelta _m\) with \(\varDelta _{\mathrm{in}}= (0,\alpha )\) and \(\varDelta _m = (0,\beta )\), which also holds with probability p. Given one element \((x^{(1)},x^{(0)}) \in \mathcal {X}\), any \((x^{(1)} \oplus u, x^{(0)})\) for \(u \in \mathbb {F}_2^m\) is also contained in \(\mathcal {X}\), thus we can generate \(2^m\) right pairs for free.
If \(2^m > \epsilon r^{-2}q^{-4}\), a differential-linear distinguisher on \(E = E_2 \circ E_m \circ E_1\) would work as follows:
-
1.
Choose \(a = (a^{(1)},a^{(0)}) \in \mathbb {F}_2^n\) uniformly at random.
-
2.
Empirically compute
$$\begin{aligned} \mathbf {Cor}_{x \in a \oplus (\mathbb {F}_2^m \times \{0\})}\left[ \langle \varGamma _{\mathrm{out}}, E(x) \rangle \oplus \langle \varGamma _{\mathrm{out}}, E(x \oplus \varDelta _{\mathrm{in}}) \rangle \right] . \end{aligned}$$ -
3.
If we observe a correlation of \(rq^2\) using \(\epsilon r^{-2}q^{-4}\) many x, the distinguisher succeeded. If not, start over with Step 1.
With probability p, we choose an element \(a \in \mathcal {X}\) in Step 1. In that case, the distinguisher succeeds in Step 3. Therefore, the data complexity of the distinguisher is \( \epsilon p^{-1}r^{-2}q^{-4}\), compared to \(\epsilon p^{-2}r^{-2}q^{-4}\) as in the classical differential-linear attack.
3.2 Probabilistic Independent Parts
We are also interested in the situations in which the differential part cannot be simply written as the parallel application of two functions. Again, the goal is, given one element \(x \in \mathcal {X}\), to be able to generate \(\epsilon r^{-2} q^{-4}\) other elements in \(\mathcal {X}\), each one with a much lower cost than \(p^{-1}\). Suppose that \(\mathcal {U} \subseteq \mathbb {F}_2^n\) is a subspace with \(|\mathcal {U}| > \epsilon r^{-2} q^{-4}\) and suppose that \(\mathbf {Pr}_{u \in \mathcal {U}}(x \oplus u \in \mathcal {X} \mid x \in \mathcal {X}) = p_1\), where \(p_1\) is much larger than p. The data complexity of the improved differential-linear distinguisher would then be \( \epsilon p^{-1}p_1^{-2}r^{-2}q^{-4}\). Note that the probability \(p_1\) also depend on x. In particular, there might be \(x \in \mathcal {X}' \subseteq \mathcal {X}\) for which \(p_1\) is (almost) 1, but the probability to draw such an initial element x from \(\mathbb {F}_2^n\) is \(p'\), which is smaller than p. Then, the data complexity would be \(\epsilon p'^{-1} p_1^{-2} r^{-2} q^{-4}\). For instance, this will be the case for the attack on Chaskey (Sect. 5), where we have \(p_1 \approx 1\) and \(p' = p \times 222/256\).
In such situations, we propose an algorithmic way to experimentally detect suitable structures in the set of right pairs. This idea of the algorithm, see Algorithm 1 for the pseudo code, is to detect canonical basis vectors within the subspace \(\mathcal {U}\). Running this algorithm for enough samples will return estimates of the probability \(\gamma _j\) that a right pair \(x \in \mathcal {X}\) stays a right pair when the j-th bit is flipped, i.e.,
When applied to a few rounds of ARX ciphers it can be expected that there are some bits that will always turn a right pair into a right pair, i.e. \(\gamma _i=1\). Moreover, due to the property of the modular addition that the influence of bits on distant bits degrades quickly, high values of \(\gamma _j\ne 1\) can also be expected. As we will detail in Sect. 5 this will be the case for the application to Chaskey.

4 The Linear Part – Advanced Partitioning and WHT-based Key-Recovery
In this section, we describe our improvements over the linear part of the attack which consists in exploiting multiple linear approximations and an advanced key-recovery technique using the partitioning technique and the fast Walsh-Hadamard transform. The overall structure of the advanced differential-linear attack is depicted in Fig. 4. Here F corresponds to the part of the cipher that we are going to cover using our improved key-guessing. Our aim is to recover parts of the last whitening key k by using a differential-linear distinguisher given by s (multiple) linear approximations \(\langle \varGamma _{\mathrm{out}}^{(p_i)},z \rangle \oplus \langle \varGamma _{\mathrm{out}}^{(p_j)},\tilde{z} \rangle \). In the following, we assume that the ciphertext space \(\mathbb {F}_2^n\) is split into a direct sum \(\mathcal {P}\oplus \mathcal {R}\) with \(n_{\mathcal {P}} {:}{=} \dim \mathcal {P}\) and \(n_{\mathcal {R}}\,{:}{=}\,\dim \mathcal {R}= n-n_{\mathcal {P}}\). Therefore, we can uniquely express intermediate states z as \(z_{\mathcal {P}} \oplus z_{\mathcal {R}}\), where \(z_{\mathcal {P}} \in \mathcal {P}\) and \(z_{\mathcal {R}} \in \mathcal {R}\). The precise definition of \(\mathcal {P}\) and \(\mathcal {R}\) depends on the particular application of the attack.

The general structure of the attack.
4.1 Multiple Linear Approximations and Partitioning
The idea is to identify several tuples \((\mathcal {T}_{p_i},\varGamma _{\mathrm{out}}^{(p_i)},\gamma ^{(p_i)})\), \(i \in \{1,\dots ,s\}\), where \(\mathcal {T}_{p_i} = \mathcal {R}\oplus p_i\) is a coset of \(\mathcal {R}\subseteq \mathbb {F}_2^n\), \(\varGamma _{\mathrm{out}}^{(p_i)}\in \mathbb {F}_2^n\) and \(\gamma ^{(p_i)} \in \mathcal {R}\), for which we can observe a high absolute correlation
In the simplest case, we would have \(\varepsilon _{i} = 1\), i.e.,
In other words, by considering only a specific subset of the ciphertexts (defined by \(\mathcal {T}_{p_i}\)) we obtain linear relations in the key with a high correlation.
Note that \(y \in \mathcal {T}_{p_i} \Leftrightarrow c \in \mathcal {T}_{p_i} \oplus k_{\mathcal {P}}\), so we need to guess \(n_{\mathcal {P}}\) bits of k to partition the ciphertexts into the corresponding \(\mathcal {T}_{p_i}\). Note that there might be ciphertexts that are discarded,Footnote 4 i.e., there might be y which do not belong to any \(\mathcal {T}_{p_i}\), for \(i \in \{1,\dots ,s\}\). Note also that, since we require \(\gamma ^{(p_i)} \in \mathcal {R}\), we obtain linear relations only on \(k_{\mathcal {R}}\).
By definingFootnote 5
we obtain
For \(r \in \mathbb {R}\), let us define \(\text{ sgn }(r) = {\left\{ \begin{array}{ll} 0 &{} \text {if } r \ge 0 \\ 1 &{} \text {if } r< 0 \end{array}\right. }\). If we define
we have \(h_{i,j} = (-1)^{\langle \gamma ^{(p_i)}\oplus \gamma ^{(p_j)},k\rangle } | \varepsilon _i \varepsilon _j q_{i,j}|\). Let us further assume that
is of equal size \(\sigma \) for all (i, j) and consider the scaled version of \(h_{i,j}\), i.e.,
For each \(\gamma \in W\,{:}{=}\,\mathrm{Span}\{ \gamma ^{(p_i)} \oplus \gamma ^{(p_j)} \mid i,j \in \{1,\dots ,s\}\}\), we define
This function \(\beta \) now allows to efficiently recover \(\dim W\) bits of information on \(k_{\mathcal {R}}\). In other words, \(k_{\mathcal {R}}\) can be uniquely expressed as \(k_{\mathcal {L}} \oplus k_{\mathcal {R}'}\), where \(k_{\mathcal {L}}\) is the part of the key that can be obtained from \(\beta \). Finally, using the Fast Walsh-Hadamard transform on \(\beta \), we compute for each tuple \((k_{\mathcal {P}},k_{\mathcal {L}})\) a cumulative counter
Whenever this counter \(\mathcal {C}\) is larger than some threshold \(\varTheta \), we store the tuple \((k_{\mathcal {P}},k_{\mathcal {L}})\) in the list of key candidates. Note that the idea of applying the Fast Walsh-Hadamard transform to gain a speed-up in the key-recovery phase of linear cryptanalysis has already been used before, see [12].

The attack is presented in Algorithm 2. Note that the actual correlations are approximated by sampling over N pairs of plaintexts, resp., ciphertexts.
A Note on the Walsh-Hadamard Transform. Given a real-valued function \(f :\mathbb {F}_{2}^n \rightarrow \mathbb {R}\), the Walsh-Hadamard transform evaluates the function
A naive computation needs \(\mathcal {O}(2^{2n})\) steps (additions and evaluations of f), i.e., for each \(\alpha \in \mathbb {F}_{2}^n\), we compute \((-1)^{\langle \alpha , y \rangle }f(y)\) for each \(y \in \mathbb {F}_2^n\). The Fast Walsh-Hadamard transform is a well-known recursive divide-and-conquer algorithm that evaluates the Walsh-Hadamard transform in \(\mathcal {O}(n 2^n)\) steps. We refer to e.g., [10, Section 2.2] for the details.
Running Time and Data Complexity of Algorithm 2. Clearly, Algorithm 2 needs 2N queries to E as the data complexity. For the running time, the dominant part is the loop over the key guesses for \(k_{\mathcal {P}}\), the collection of N data samples, and the Walsh-Hadamard transform. The overall running time can be estimated as \(2^{n_{\mathcal {P}}}(2N+\dim W\cdot 2^{\dim W})\).
Success Probability of Algorithm 2. Two questions remain to be discussed here: (i) what is the probability that the right key is among the candidates and (ii) what is the expected size of the list of candidates? To answer those questions, we have to first establish a statistical model for the counter values \(\mathcal {C}(k_{\mathcal {P}},k_{\mathcal {L}})\).
For a key guess \(k'_{\mathcal {L}}\), we first note that

which implies that if \(k'_{\mathcal {L}}=k_{\mathcal {L}}\) the partial counters add up, while if \(k_{\mathcal {L}} \ne k'_{\mathcal {L}}\), the partial counters can be expected to cancel each other partially.
In the following, we assume that the distributions involved can be well estimated by normal approximations. This significantly simplifies the analysis. Note that we opted for a rather simple statistical model ignoring in particular the effect of the wrong key distribution and the way we sample our plain-texts (i.e. known vs. chosen vs. distinct plaintext). Those effects might have major impact on the performance of attacks when the data complexity is close to the full code-book and the success probability and the gain are limited. However, none of this is the case for our parameters. In our concrete applications, we have verified the behaviour experimentally wherever possible.
For the statistical model for the right key, this implies that the counter can be expected to approximately follow a normal distribution with parameters
where
is the average correlation over all partitions and \(N^{*}\) is the effective data complexity, i.e. the data complexity N reduced by the invalid partitions. The wrong key counters (under the simple randomization hypothesis) is approximately normal distributed with parameters
With this we can deduce the following proposition.
Proposition 1
After running Algorithm 2 for \(p^{-1}\)-times, the probability that the correct key is among the key candidates is
The expected number of wrong keys is \(\frac{2^{n}}{p}\times \left( 1-\varPhi \left( \frac{\varTheta }{\sqrt{N^*}} \right) \right) \).
4.2 A Simple Toy Example
We transfer the above terminology on the simple toy example given in Fig. 5 and already discussed earlier in Sect. 2.2. In this example, for a fixed \(i\ge 2\), we want to evaluate \(z_0[i]\) or \(z_0[i]\oplus z_0[i-1]\) by using the partitioning rules as expressed in Lemma 2 and Lemma 3. For this, we say that \((z_0[i],z_0[i]\oplus z_0[i-1])\) defines a partition point \(\zeta \). This partition point gives rise to a 2-dimensional subspace \(\mathcal {P}\) which can be defined by two parity check equations, i.e., \(\mathcal {P}\) is a complement space of the space
For example, \(\mathcal {P}\) can be chosen as \(\{([],[]),([i-1],[]),([i-2],[]),([i-2,i-1],[])\}\).

A simple toy example.

A consecutive case.
To demonstrate the attack from the previous section, we split \(\mathbb {F}_2^{2m}\) into the direct sum \(\mathcal {P}\oplus \mathcal {R}\). By the isomorphism between \(\mathcal {P}\) and \(\mathbb {F}_2^2\), we can identify the elements \(p \in \mathcal {P}\) by two-bit values \(p \cong b_0b_1\), where \(b_0\) indicates the parity of \(\bar{x}_0[i-1] \oplus x_1[i-1]\) and \(b_1\) indicates the parity of \(\bar{x}_0[i-2] \oplus x_1[i-2]\). We then consider the following four tuples \((\mathcal {T}_{b_0b_1},\varGamma _{\mathrm{out}}^{(b_0b_1)},\gamma ^{(b_0b_1)})\) and corresponding \(\varepsilon _{b_0b_1}\), whose definition come from the properties presented in Lemma 2 and Lemma 3:

For example, to give an intuition for the choice of the first tuple,Footnote 6 when \((y_1,y_0) \in \mathcal {S}_4\), Lemma 3 tells us that  , i.e.,
, i.e.,  .
.
We further have
and we could recover the two bits \(k_0[i-1]\) and \(k_0[i-2]\) by the last step using the fast Walsh-Hadamard transform.
4.3 Another Toy Example Using Multiple Partition Points
Let us now look at another example which consists of two branches of the structure depiced in Fig. 5 in parallel, i.e., \((y_3,y_2,y_1,y_0) = (F(z_3,z_2),F(z_1,z_0))\) and \(c_i = y_i \oplus k_i\). By using a single partition point as done in the above example, we can only evaluate the parity of at most two (consecutive) bits of \(z = (z_3,z_2,z_1,z_0)\). Instead of just one single partition point, we can also consider multiple partition points. For example, if we want to evaluate the parity involving three non-consecutive bits of \(z = (z_3,z_2,z_1,z_0)\), we can use three partition points, i.e.

where \(i,j,\ell \ge 2\). In a specific attack, the choice of the partition points depends on the definition of the linear trail. Those partition points give rise to three subspaces \(\mathcal {P}_1\), \(\mathcal {P}_2\), and \(\mathcal {P}_3\), defined by two parity-check equations each, i.e., \(\mathcal {P}_i\) is a complement space of \(\mathcal {R}_i\), where

By definingFootnote 7 \(\mathcal {P}= \mathcal {P}_1 \oplus \mathcal {P}_2 \oplus \mathcal {P}_3\) and \(\mathcal {R}\) to be a complement space of \(\mathcal {P}\), we split \(\mathbb {F}_2^{4m}\) into the direct sum \(\mathcal {P}\oplus \mathcal {R}\).
We can identify the elements \(p \in \mathcal {P}\) by \(n_{\mathcal {P}}\)-bit values \(p \cong b_0b_1\dots b_{n_{\mathcal {P}}-1}\). We can then again define tuples
by using the properties presented in Lemma 2 and Lemma 3. For example, if \(n_{\mathcal {P}} = 6\), we can define

 , and
, and  by using the first case of Lemma 2.
by using the first case of Lemma 2.
We can also use the three partition points to compute the parity of more than three bits of z. For example, if \(n_{\mathcal {P}} = 6\), by using Lemma 2 and 3, we can define

and

which evaluates the parity of five bits of z. Again, several choices for the definition of the tuples in Eq. 3 are possible.
4.4 Analysis for Two Consecutive Modular Additions
To avoid the usage of long linear trails and to reduce the data complexity, we may use the partition technique for the more complicated structure of two consecutive modular additions. Inspired by the round function of Chaskey, we consider the case depicted in Fig. 6.
Suppose that we have the partition point \(\zeta =(z_1[i],z_1[i] \oplus z_1[i-1])\), i.e., we want to compute the parity \(z_1[i]\) and \(z_1[i,i-1]\) from \(c_2\), \(c_1\), and \(c_0\) (see Fig. 6). This partition point gives rise to a 5-dimensional subspace \(\mathcal {P}\) which can be defined by five parity check equations, i.e., \(\mathcal {P}\) is a complement space of the space
where \(i_a = i + a\), \(i_b = i + b\), and \(i_c = i + a + b\). Then, if \(n_{\mathcal {P}}=5\), we can identify the elements \(p_i \in \mathcal {P}\) by five-bit values \(p_i \cong b_0b_1b_2b_3b_4\), where \((b_0b_1b_2b_3b_4) = (y_2[i_a-1] \oplus y_1[i_b-2] \oplus y_1[i_c-2], s[i_b-1], s[i_b-2], s[i_c-1], s[i_c-2])\) with \(s = \bar{y}_0 \oplus y_1\). The whole \(\mathbb {F}_2^{3m}\) is partitioned into \(2^5\) cosets \(\mathcal {T}_{p_i} = \mathcal {R}\oplus p_i\) and these partitions can be constructed by guessing 5 bit of key information. The tuples as in Eq. 3 can be defined by \(\varGamma _{\mathrm{out}}^{(p_i)} \in \{ ([],[i],[]),([],[i,i-1],[]) \}\), and the corresponding linear mask \(\gamma ^{(p_i)}\) involves the bits
When \(i_a-2\), \(i_b-2\), and \(i_c-2\) is not extremely close to 0, for each possible choice of \(\varGamma \in \{ ([],[i],[]),([],[i,i-1],[]) \}\), we have 4 tuples corresponding to correlation \(\varepsilon = \pm 1\), 8 tuples corresponding to correlation \(\varepsilon = \pm 2^{-1}\), and 12 tuples corresponding to correlation \(\varepsilon = \pm 2^{-0.263}\). In other words, a fraction of \(24/32=3/4\) tuples with non-zero correlation is available, and the average absolute correlation is \((4 \times 1) + (8 \times 2^{-1}) + (12 \times 2^{-0.263}) \approx 2^{-0.415}\).

The round function of Chaskey.
5 Application to Chaskey
Chaskey [24] is a lightweight MAC algorithm whose underlying primitive is an ARX-based permutation in an Even-Mansour construction, i.e., Chaskey-EM. The permutation operates on four 32-bit words and employs 12 rounds of the form as depicted in Fig. 7. The designers’ claim security up to \(2^{80}\) computations as long as the data is limited to \(2^{48}\) blocks.
5.1 Overview of Our Attack
We first show the high-level overview of our attack. Similarly to the previous differential-linear attack from [20], we first divide the cipher into three sub ciphers, i.e, \(E_1\) covering 1.5 rounds, \(E_m\) covering 4 rounds, and \(E_2\) covering 0.5 rounds. The key-recovery is done over 1 round, thus the function F is covering 1 round to attack 7 rounds in total. The differential characteristic and the linear trail are applied to \(E_1\) and \(E_2\), respectively, while the experimental differential-linear distinguisher is applied to the middle part \(E_m\). Note that, since the differential-linear distinguisher over \(E_m\) is constructed experimentally, its correlation must be high enough to be detectable by using a relatively small sampling space. Moreover, since it is practically infeasible to check all input difference and all output linear mask, we restricted ourselves to the case of an input difference of Hamming weight 1 and linear masks of the form [i] or \([i,i+1]\), i.e., 1-bit or consecutive 2-bit linear masks. As a result, when there is a non-zero difference only in the 31st bit (msb) of \(w^1_0\), i.e.,
we observed the following two differential-linear distinguishers with correlations \(2^{-5.1}\):
These correlationsFootnote 8 are estimated using a set \(\mathcal {S}\) consisting of \(2^{26}\) random samples of \(w^1\). This is significant enough since the standard deviation assuming a normal distribution is \(2^{13}\). For simplicity, only the first differential-linear distinguisher is exploited in our 7-round attack. That is
Note that we do not focus on the theoretical justification of this 4-round experimental differential-linear distinguisher in this paper and we start the analysis for \(E_1\) and \(E_2\) from the following subsection.
5.2 Differential Part
We need to construct a differential distinguisher \(\varDelta _{\mathrm{in}}\rightarrow \varDelta _m\) over \(E_1\), where the output difference is equal to the 1-bit difference \(\varDelta _m = (([]),([]),([31]),([]))\). We have 1.5-round differential characteristic of highest probability under this restriction and its probability is \(2^{-17}\), where
If this differential characteristic is directly used in the differential-linear attack, the impact on the data complexity is \(p^{-2}=2^{34}\), which is quite huge given the restriction on the data complexity for Chaskey. In order to reduce the data complexity, we employ the new technique described in Sect. 3. Note that the previous analysis shown in [20] also employs the same differential characteristic, but the technique for reducing the data complexity is completely different. We will compare our technique to the previous technique at the end of this subsection.
Detecting an Appropriate Subspace \(\mathcal {U}\). As described in Sect. 3, we want to detect a subspace \(\mathcal {U}\) of the input space such that \(E_1(v^0 \oplus u) \oplus E_1(v^0 \oplus u \oplus \varDelta _{in}) = \varDelta _{m}\) for all \(u \in \mathcal {U}\) if \(E_1(v^0) \oplus E_1(v^0 \oplus \varDelta _{in}) = \varDelta _{m}\). Then, for our attack to be effective, the condition is that \(2^{|\dim \mathcal {U}|} > \epsilon r^{-2}q^{-4}\), where r and q denote the correlation of the differential-linear distinguisher over \(E_m\) and the linear distinguisher over \(E_2\), respectively. If this condition is satisfied, we can reduce the total data complexity from \(\epsilon p^{-2} r^{-2} q^{-4}\) to \(\epsilon p^{-1} r^{-2} q^{-4}\).

Probability that flipping \(v_{j/32}^0[j~\mathrm{mod}~32]\) affects the output difference.
Since the four branches are properly mixed with each other within 1.5 rounds, there is no trivial subspace as in the simple example in Sect. 3.1. However, the diffusion obtained by the modular addition, XOR and rotation is heavily biased. For example, let us focus on \(v_2^0[31]\). This bit is independent of the 1.5-round differential trail. Thus, we will experimentally detect bits that do not, or only very rarely, effect the differential trail, as explained in Sect. 3 in Algorithm 1. We used this algorithm with a sampling parameter \(T=2^{32}\). Due to the differential probability of \(2^{-17}\), we find on average \(2^{32} \times 2^{-17} = 2^{15}\) values of X such that \(E_1(X) \oplus E_1(X \oplus \varDelta _{in}) = \varDelta _m\).
Figure 8 summarizes the result of the search. When the basis of the linear subspace \(\mathcal {U}\) is chosen from the 18 indices i corresponding to a probability \(\gamma _i=1\), we are exactly in the setting as explained in Sect. 3 and the factor on the data complexity corresponding to the differential part would be \(p^{-1}\). Unfortunately, 18 indices are not always sufficient to attack 7-round Chaskey. Therefore, we additionally add 7 indices, i.e., \(v_0[19], v_0[20], v_0[31], v_1[19], v_1[20], v_3[24],\) and \(v_3[25]\) to define the basis of \(\mathcal {U}\). We then randomly picked 256 pairs \((X, X \oplus \varDelta _{in})\) that result in the output difference \(\varDelta _m\) after \(E_1\) and checked for how many of those pairs, the equation \(E_1(X \oplus u) \oplus E_1(X \oplus u\oplus \varDelta _{in}) = \varDelta _m\) is satisfied for all \(u \in \mathcal {U}\). As a result, this holds for 222 out of 256 pairs \((X, X \oplus \varDelta _{in})\). In other words, we can estimate the factor on the data complexity corresponding to the differential part to be \((p \times 222/256)^{-1}\).
Comparison with the Technique of Leurent. In [20], Leurent applied the partitioning technique to the same 1.5-round differential characteristic. For applying the partitioning technique, 14 bit of key information need to be guessed and the impact on the data complexity from the differential part was estimated as \(\left( \frac{17496}{2^{23}} \times 2^{10} \times 2^{-2 \times 11})\right) ^{-1} \approx 2^{20.9}\) in [20]. In contrast, our technique does not need to guess any key bit and the impact on the data complexity from the differential part is estimated as \((p \times \frac{222}{256})^{-1} \approx 2^{17.2}\) when the size of \(\mathcal {U}\) is \(2^{25}\).
5.3 Linear Part
In order to attack 7-round Chaskey, we consider as \(E_2\) 0.5-rounds of Chaskey and as F 1.5-rounds of Chaskey. For \(E_2\) we consider two trails for the mask \( \varGamma _m=(([]),([20]),([]),([])) \), namely
That is computing \(\langle \varGamma _{out}^{p_i},z \rangle \) corresponds to either \(\psi ^{(1)}\) or \(\psi ^{(0)}\)

Two 0.5-round linear trails and corresponding partition points.
Similarly, we denote by \(\tilde{\psi }^{(1)}\) and \(\tilde{\psi }^{(0)}\) the corresponding parity bits for \(\tilde{c}\). As discussed in Sect. 4, our attack uses only one of them (with highest absolute correlation) for each partition. For example, let us assume that \(\psi ^{(1)}\) is preferable for the partition belonging to c and \(\psi ^{(0)}\) is preferable for the partition belonging to \(\tilde{c}\). Then, we compute \(\psi ^{(1)}\) and \(\tilde{\psi }^{(0)}\) from c and \(\tilde{c}\), respectively, and evaluate the probability satisfying \(\psi ^{(1)} = \tilde{\psi }^{(0)}\). We experimentally evaluated the correlations of any combination, i.e., the correlation of \(2 \times 2\) differential-linear distinguishers. Similarly to the experiments in Sect. 5.1, we computed those correlations over a set \(\mathcal {S}\) consisting of random samples of \(w^1\), but the size of \(\mathcal {S}\) had to be increased to \(2^{28}\) because of the lower correlation. As a result, these empirical correlations are \(\approx \pm 2^{-6.4}\).
For Chaskey, we use three partition points as shown in the right table of Fig. 9. The dimension of W for the FWHT is increased by 1 but it does not affect the size of partitions. As already presented in Sect. 4, the corresponding subspaces \(\mathcal {P}_1\) can be defined by the bits summarized in Fig. 9, where \(s^L\,{:}{=}\,\bar{v}_1 \oplus v_2\) and \(s^R\,{:}{=}\,\bar{v}_3 \oplus v_0\). The same table also summarizes the linear bits that can be involved to a linear combination in the corresponding \(\gamma ^{(p_1)}\).
For \(\zeta _2\) and \(\zeta _3\), the situation is different since we have to evaluate two consecutive modular additions instead of just one. The major difference is that the corresponding subspace is now of dimension 5, i.e., the condition is defined by a 5-bit value. Further, the corresponding \(\varepsilon _i\) are not always \(\pm 1\).
Note that because there is a 1-bit interception in the defining bits for \(\mathcal {P}_2\) and \(\mathcal {P}_3\), we have \(n_{\mathcal {P}} = \dim \mathcal {P}= \dim (\mathcal {P}_1 \oplus \mathcal {P}_2 \oplus \mathcal {P}_3) = {2+5+5-1}={11}\). Namely, the index \(p_i\) of the partition \(\mathcal {T}_{p_i}\) is defined by the 11-bit value
It is difficult to evaluate the actual correlations of all \(q_{i,j}, i,j \in \{1,\dots ,2^{11}\}\) experimentally with a high significance. Therefore, we simply assume that these correlations are common for each partition, i.e., \(q_{i,j}=2^{-6.4}\) for all i and j.
Since we have two choices \( \psi ^{(0)}\) or \( \psi ^{(1)}\) for the linear mask \(\varGamma _{\mathrm{out}}^{(p_i)}\) that we use in each partition, we evaluated every correlation of possible \(\varGamma _{\mathrm{out}}^{(p_i)}\) and took the one with the highest absolute correlation. More precisely, we evaluated each subspace \(\mathcal {P}_i\) step by step. We start our analysis from \(\mathcal {P}_1\). For this, the condition is based on \(s^R[15]\) and \(s^R[14]\) and the available linear masks can be immediately determined as follows.
In other words, the number of available linear masks decreases from 2 to 1 for \(2^{10}\) partitions, and the number is preserved for the other \(2^{10}\) partitions. We next focus on \(\mathcal {P}_2\), but it is more complicated because the index bit \(s^L[10]\) also appears in the index for \(\mathcal {P}_3\). Since \(\dim (\mathcal {P}_2 \oplus \mathcal {P}_3) = 9\) is not large, we exhaustively evaluated the correlation of each partition. As a result, 1472 out of \(2^{11}\) partitions show a significant correlation and the average of the absolute value of those correlations is \(2^{-0.779}\). In the differential-linear attack, this partition analysis must be executed for both texts in each pair. Thus, when N pairs are used, the number of available pairs is \(N^*= N \times (\frac{1472}{2048})^2 \approx N \times 2^{-0.953}\) and the correlation is \(h = 2^{-6.4 - 0.779 \times 2} = 2^{-7.958}\).
We also need to evaluate the dimension of \(W\,{:}{=}\,\mathrm{Span}\{ \gamma ^{(p_i)} \oplus \gamma ^{(p_j)} \mid i,j \in \{1,\dots ,s\}\}\) to evaluate the time complexity for the FWHT. Note that \(\gamma \in W\) is always generated by XORing two linear masks. Therefore, bits that are always set to 1 in the linear masks \(\gamma ^{(p_i)}\) and \(\gamma ^{(p_j)}\) do not increase the dimension of \(W\). For example, since both \(\psi ^{(1)}\) and \(\psi ^{(0)}\) involves \(v_1[0]\), it does not increase the dimension of \(W\). On the other hand, since \(v_1[31]\) is involved only in \(\psi ^{(1)}\), it increases the dimension of \(W\) by 1. The same analysis can be applied to each partition point. For example, partition point \(\zeta _1\) involves four bits \(v_3[16]\), \(v_0[16]\), \(v_0[15]\), and \(v_0[14]\) in the key mask \(\gamma ^{(p_i)}\), but both \(v_3[16]\) and \(v_0[16]\) are always involved. As a result, the 10 bits
are enough to construct any \(\gamma \in W\), i.e., \(\dim (W) \le 10\).
Experimental Reports. To verify our technique, we implemented the attack and estimated the experimental correlation if the linear masks are appropriately chosen for each partition. Then, for a right pair \((X, X \oplus \varDelta _{in})\), we used \(2^{28}\) pairs \((X \oplus u, X \oplus u \oplus \varDelta _{in})\) for \(u \in \mathcal {U}\). As a result, the number of available pairs is \(2^{27.047}\), and the number well fits our theoretical estimation. On the other hand, there is a small (but important) gap between our theoretical analysis and experimental analysis. While this correlation was estimated as \(2^{-7.958}\) in our theoretical analysis, the experimental correlation is \(2^{-7.37}\), which is much higher than our theoretical estimation. We expect that this gap comes from linear-hull effect between \(q_{i,j}\) and \((\epsilon _i, \epsilon _j)\). The linear masks \(\lambda ^{(0)}\) and \(\lambda ^{(1)}\) are fixed in our theoretical estimation, but it allows to use multiple linear masks similarly to the conventional linear-hull effect. Moreover, as a consecutive modular addition causes much higher absolute correlation, we expect that our case also causes much higher absolute correlation. However, its detailed theoretical understanding is left as a open question in this paper.
Data and Time Complexities and Success Probability. We use the formula in Proposition 1 to estimate the data complexity and corresponding success probability. To find a right pair, we repeat Algorithm 2 for \((p \times 222/256)^{-1} = 2^{17.206}\) times, and we expect to find a right pair with probability 1/2. For each iteration of Algorithm 2, we use \(N = 2^{22}\) pairs, and \(N^*= 2^{21.047}\). By using the threshold \(\varTheta = \sqrt{N^*} \times \varPhi ^{-1}( 1 - \frac{p \times 222/256}{2^{n}})\), the expected number of wrong keys is 1, whileFootnote 9 \(p_\mathrm{success} = 0.489\), where correlation \(2^{-7.37}\) is used in this estimation. On this success probability, the data complexity is \(2^{1+22+17.206} = 2^{40.206}\) and the time complexity is \(2^{17.206} \times 2^{11} \times (2 \times 2^{22} + 10 \times 2^{10} ) \approx 2^{51.208}\).
6 Application to ChaCha
The internal state of ChaCha is represented by a \(4 \times 4\) matrix whose elements are 32-bit vectors. In this section, the input state for the r-th round function is represented as
In odd and even rounds, the QR function is applied on every column and diagonal, respectively. We also introduce the notion of a half round, in which the QR function is divided into two sub function depicted in Fig. 10. Let \(w^r\) be the internal state after the application of a half round on \(v^r\). Moreover, we use the term branches for a, b, c and d, as shown in Fig. 10.
In the initial state of ChaCha, a 128-bit constant is loaded into the first row, a 128- or 256-bit secret key is loaded into the second and third rows, and a 64-bit counter and 64-bit nonce are loaded into the fourth row. In other words, the first three rows in \(v^0\) are fixed. For r-round ChaCha, the odd and even round functions are iteratively applied, and the feed-forward values \(v^0_i \boxplus v^r_i\) is given as the key stream for all i. Note that we can compute \(v^r_i\) for \(i \in \{0,1,2,3,12,13,14,15\}\) because corresponding \(v^0_i\) is known.

The odd and even round functions of ChaCha.
6.1 Overview of Our Attack
We use the same attack strategy as for Chaskey. The cipher is divided into the sub ciphers \(E_1\) covering 1 round, \(E_m\) covering 2.5 rounds, and \(E_2\) covering 1.5 rounds to attack 6 rounds, and F the key recovery is applied to the last one round. One difference to Chaskey is the domain space that can be controlled by the attacker. In particular, we cannot control branches a, b, and c because fixed constants and the fixed secret key is loaded into these states. Thus, only branch d can be varied. It implies that active bit positions for input differences are limited to branch d and a difference \(\varDelta _m\) after \(E_1\) with Hamming weight is 1 will not be available due to the property of the round function. Therefore, we first need to generate consistent \(\varDelta _m\) whose Hamming weight is minimized. The following shows such differential characteristics over one QR function.
The probability that pairs with input difference \(\varDelta _{\mathrm{in}}\) satisfy this characteristic is \(2^{-5}\) on average. We discuss the properties of this differential characteristic in Sect. 6.2 in more detail.
We next evaluate an experimental differential-linear distinguisher for the middle part \(E_m\). When the Hamming weight of \(\varGamma _m\) is 1 and the active bit is in the lsb, it allows the correlation of linear trails for \(E_2\) to be lower. For \(i=6\), i.e., \(\varDelta _{m} = (([2]),([5,29,17,9]),([30,22,10]),([30,10]))\), we find the following four differential-linear distinguishers.
for \(j \in \{0,1,2,3\}\). When this experimental distinguisher is combined with the differential characteristic for \(E_1\), it covers 3.5 rounds with a 1-bit output linear mask \(\varGamma _m\). This differential-linear distinguisher is improved by 0.5 rounds from the previous distinguisher with 1-bit output linear mask (see [1, 11]).
6.2 Differential Part
The QR function is independently applied to each column in the first round. Therefore, when the output difference of one QR function is restricted by \(\varDelta _m\), the input of other three QR functions are trivially independent of the output difference. It implies that we have 96 independent bits, and we can easily amplify the probability of the differential-linear distinguisher. On the other hand, we face a different problem, namely that the probability of the differential characteristic \((\varDelta _{in}, \varDelta _m)\) highly depends on the value of the secret key. For example, for \(\varDelta v_{12}^0[6] = 1\), we expect that there is a pair \((v_{12}^0, v_{12}^0 \oplus \mathtt {0x00000020})\) satisfying \(\varDelta (v_0^1, v_4^1, v_8^1, v_{12}^1) = \varDelta _m\), but it depends on the constant \(v_{0}^0\) and the key values \(v_{4}^0\) and \(v_{8}^0\). In our experiments, we cannot find such a pair for 292 out of 1024 randomly generated keys. On the other hand, when we can find it, i.e., on 732 out of 1024 keys, the average probability satisfying \(\varDelta (v_0^1, v_4^1, v_8^1, v_{12}^1) = \varDelta _m\) is \(2^{-4.5}\). This experiment implies the existence of “strong keys” against our attack. However, note that we can vary the columns in which we put a difference, which involve different key values. Since the fraction of “strong keys” is not so high, i.e., 292/1024, we can assume that there is at least one column in which no “strong key” is chosen with very high probability.
To determine the factor p, for 1024 randomly generated keys, we evaluated \(p^{-1}\) randomly chosen iv and counter, where the branch that we induce the difference is also randomly chosen. As a result, we can find a right pair on 587 keys with \(p^{-1}=2^5\) iterations. Therefore, with \(p=2^{-5}\), we assume that we can find a right pair with probability 1/2 in this stage of the attack.
In the following, we explain our attack for the case that \(v_{12}^{0}\) is active and \(\varDelta (v^1_0, v^1_4, v^1_8, v^1_{12}) = \varDelta _m\). Note that the analysis for the other three cases follows the same argument.
6.3 Linear Part for 6-Round Attack
To attack 6-round ChaCha, we first construct a 5-round differential-linear distinguisher, where 1.5-round linear trails are appended (i.e. the \(E_2\) part) to the 3.5-round experimental differential-linear distinguisher from the previous section. We have two 1.5-round linear trails given by
where \(\psi ^{(1)} = \psi \oplus v_{10}^5[6]\) and \(\psi ^{(0)} = \psi \oplus v_{14}^5[6]\), and
Since their correlations are \(\pm 2^{-1}\), we have \(2 \times 2\) differential-linear distinguishers on 5 rounds whose correlations are \(\pm 2^{-10.3}\). Note that the sign of each correlation is deterministic according to the output linear mask.

Key recovery for 6-round ChaCha.
Our 6-round attack uses these 5-round differential-linear distinguishers, and the 1-round key recovery is shown in Fig. 11. Let \(\mathbf {c} = (c_0, \ldots , c_{15})\) be the corresponding output, and let \(\mathbf {v} = (v_0, \ldots , v_{15})\) be the sixteen 32-bit values before the secret key is added. Note that the secret key is only added with half of the state and public values are added with the other state. Therefore, we simply regard \(v_i = c_i\) for \(i \in \{0,15,1,12,2,13,3,14\}\).
First, we partially extend two linear masks for the last round so that it can be linearly computed. Figure 11 summarizes the extended linear masks, where we need to compute the bits labeled by a red color. Moreover, for simplicity, we introduce \(t_0\), \(t_{10}\), \(t_{11}\), and \(t_3\) as depicted in Fig. 11.
Each bit in \(\mathbf {v}\) in which the secret key is not added can be computed for free. For the other bits, we need to guess some key bits first. We first explain the simple case, i.e., we compute \(v_i[j]\) from \(c_i\). As an example, we focus on \(v_7[7]\), which involves \(k_7\) nonlinearly. We apply the partition technique to compute this bit, where (3/4) data is available by guessing \(k_7[6]\) and \(k_7[5]\) (remember that \(k_7[7]\) cancels out in the differential-linear approximation). Since \(v_i[0]\) is linearly computed by \(c_i[0]\), there are 13 simple partition points in which we need to guess key bits. In total, we need to guess a 26-bit key and \((3/4)^{13}\) data is available.
Computing bits in \(\mathbf {v}^5\) and \(\mathbf {t}\) is a bit more complicated than the simple case above. For example, let us consider \(v_9^5[12]\), and this bit can be computed as
Since we can compute \((c_9 \boxminus c_{14} \boxminus (c_3 \oplus (v_{14} \ggg 8)))\) for free, this case is equivalent to the simple case. We also use this equivalent transformation for \(t_{10}\), \(t_{11}\), and \(v_{10}[19]\). In total, we have 6 such partition points, and some partition points can share the same key, e.g., 2-bit key \(k_{10}[18]\) and \(k_{10}[17]\) is already guessed to compute \(v_{10}[19]\). Guessing 4 bits of additional key is enough to compute each bit. Since we have two linear masks \(\psi ^{(0)}\) and \(\psi ^{(1)}\), the number of available partitions does not decrease for \(v_{10}^5[7]/v_{10}^5[7,6]\). Therefore, \((3/4)^5\) data is available.
We cannot use the equivalent transformation to compute bits in \(t_0\) and \(t_3\). Then, we further extend this linear mask with correlation \(2^{-1}\). For example, we have the following approximations
for \(t_0[8]\) with correlation \(2^{-1}\), and we can use preferable approximations depending on the data. Namely, we first guess \(k_{10}[7]\) and determine which linear approximations are available. Then, we guess \(k_{5}[14]\) and \(k_{5}[13]\) and compute \(v_5[15]\) (resp. \(v_5[15,14]\)) with the fraction of available partitions 3/4. In order words, we guess 3-bit key and 3/4 data is available. We also use the same technique for \(t_0[7]/t_0[7,6]\). Therefore, 6-bit additional key is required, \((3/4)^2\) data is available, but the correlation is \(\pm 2^{-10.3 - 2 \times 2} = \pm 2^{-14.3}\).
In summary, the fraction of available partitions is \((3/4)^{13+5+2} \approx 2^{-8.3}\). We need to guess 36-bit key in total.
We finally estimate the data and time complexities. When we use N pairs, the number of available pairs is \(N^*= N \times 2^{2 \times -8.3} \approx N 2^{-16.6}\), and the average correlation is \(\pm 2^{-14.3}\). Note that unlike Chaskey, once these key bits are correctly guessed, all linearly involved bits are either determined or cancelled out by XORing another text. It implies \(\dim (W)=0\) and we do not need to proceed with the FWHT.
Data and Time Complexities and Success Probability. We use the formula in Proposition 1 to estimate the data complexity and corresponding success probability. To find a right pair, we repeat Algorithm 2 for \(2^{5}\) times. For each pair, we use \(N = 2^{52}\) pairs, and \(N^*= 2^{35.4}\). For the threshold \(\varTheta = \sqrt{N^*} \times \varPhi ^{-1}( 1 - \frac{2^{-5}}{2^{36}})\), the expected number of wrong keys is 1, butFootnote 10 \(p_\mathrm{success} = 0.499\). For this success probability, the data complexity is \(2^{1+52+5} = 2^{58}\).
If we guess \(2^{36}\) keys for each texts, the required time complexity is \(2^{58+36}=2^{94}\). However, note that once we get a pair, we can immediately compute those \(k_\mathcal {P}\) values that correspond to valid partitions. Consequently, we only iterate through those \(k_\mathcal {P}\) values for every pair. The time complexity is estimated as \(1/p \times (2N + 2N^{*} \times 2^{n_{\mathcal {P}}}) \approx 2^{77.4}\).
6.4 The 7-Round Attack
Unfortunately, 7-round ChaCha is too complicated to apply our technique for the linear part. On the other hand, thanks to our other contribution for the differential part, we find a new differential-linear distinguisher which is improved by 0.5 rounds. Therefore, to confirm the effect of our contribution for the differential part, we use the known technique, i.e., the probabilistic neutral bits (PNB) approach, for the key-recovery attack against 7-round ChaCha. The PNB-based key recovery is a fully experimental approach. We refer to [1] for the details and simply summarize the technique as follows:
-
Let the correlation in the forward direction (a.k.a, differential-linear distinguisher) after r rounds be \(\epsilon _d\).
-
Let n be the number of PNBs given by a correlation \(\gamma \). Namely, even if we flip one bit in PNBs, we still observe correlation \(\gamma \).
-
Let the correlation in the backward direction, where all PNB bits are fixed to 0 and non-PNB bits are fixed to the correct ones, is \(\epsilon _a\).
Then, the time complexity of the attack is estimated as \(2^{256-n} N + 2^{256 - \alpha }\), where the data complexity N is given as
where \(\alpha \) is a parameter that the attacker can choose.
In our case, we use a 4-round differential-linear distinguisher with correlation \(\epsilon _d = 2^{-8.3}\). Under pairs generated by the technique shown in Sect. 6.2, we experimentally estimated the PNBs. With \(\gamma =0.35\), we found 74 PNBs, and its correlation \(\epsilon _a = 2^{-10.6769}\). Then, with \(\alpha =36\), we have \(N=2^{43.83}\) and the time complexity is \(2^{225.86}\). Again, since we need to repeat this procedure \(p^{-1}\) times, the data and time complexity is \(2^{48.83}\) and \(2^{230.86}\), respectively.
7 Conclusion and Future Work
We presented new ideas for differential-linear attacks and in particular the best attacks on ChaCha, one of the most important ciphers in practice. We hope that our framework finds more applications. In particular, we think that it is a promising future work to investigate other ARX designs with respect to our ideas.
Besides the plain application of our framework to more primitives, our work raises several more fundamental questions. As explained in the experimental verification, we sometimes observe absolute correlations that are higher than expected, which in turn make the attacks more efficient than estimated. Explaining those deviations from theory, likely to be caused by linear-hull effects, is an interesting question to tackle. Related to this, we feel that – despite interesting results initiated by [25] – the impact of dependent chains of modular additions on the correlations is not understood sufficiently well and requires further study.
Finally, we see some possible improvements to our framework. First, it might be beneficial to use multiple linear mask per partition, while we used only one in our applications. This of course rises the question of independence, but maybe a multidimensional approach along the lines of [16] might be possible. Second, one might improve the results further if the estimated values for \(\beta (\gamma )\) are replaced by a weighted sum, where partitions and masks with higher correlations are given more weight than partitions and masks with a comparable low correlation.
Notes
- 1.
After the submission of this paper, the authors of [13] independently found the same distinguisher without applying the technique for improving over the differential part, and the presented attack complexities are very close to ours.
- 2.
Under the assumption that the sets \(\{\langle \varGamma _{\mathrm{out}}, E(x) \rangle \oplus \langle \varGamma _{\mathrm{out}}, E(x \oplus \varDelta _{\mathrm{in}}) \rangle \mid x \in \mathcal {X}\}\) and \(\{\langle \varGamma _{\mathrm{out}}, E(x) \rangle \oplus \langle \varGamma _{\mathrm{out}}, E(x \oplus \varDelta _{\mathrm{in}}) \rangle \mid x \in \mathcal {S}\}\) are indistinguishable, where \(\mathcal {S}\) denotes a set of uniformly chosen samples of the same size as \(\mathcal {X}\).
- 3.
Or at least with a cost much lower than \(p^{-1}\), see Sect. 3.2.
- 4.
Of course, the discarded data has to be considered in the data complexity of the attack.
- 5.
If \(|q_{i,j}|\) is not too small and if the number s of approximations is not too huge, we can empirically compute \(q_{i,j}\) for all i, j. In other cases, we estimate \(q_{i,j} = \mathbf {Cor}_{x \in \mathcal {X} }\left[ \langle \varGamma _{\mathrm{out}}^{(p_i)},z \rangle \oplus \langle \varGamma _{\mathrm{out}}^{(p_j)},\tilde{z} \rangle \right] \) by assuming indistinguishability of the sets \(\{\langle \varGamma _{\mathrm{out}}^{(p_i)},z \rangle \oplus \langle \varGamma _{\mathrm{out}}^{(p_j)},\tilde{z} \rangle \mid x \in \mathcal {X} \text { s.t. } (y,\tilde{y}) \in \mathcal {T}_{p_i} \times \mathcal {T}_{p_j}\}\) and \(\{\langle \varGamma _{\mathrm{out}}^{(p_i)},z \rangle \oplus \langle \varGamma _{\mathrm{out}}^{(p_j)},\tilde{z} \rangle \mid x \in \mathcal {S}\}\), where \(\mathcal {S}\) is a set of uniformly random samples of \(\mathcal {X}\) of suitable size.
- 6.
Note that we might choose different \((\varGamma _{\mathrm{out}}^{(b_0b_1)},\gamma ^{(b_0b_1)})\) for \(\mathcal {T}_{b_0b_1}\). For example, for
 , we might alternatively choose
, we might alternatively choose 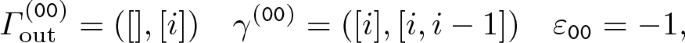
which is obtained from Lemma 2. To verify, note that \(\mathcal {S}_4 \subseteq \mathcal {S}_1\).
- 7.
Note that \(\mathcal {P}\) is not necessarily a direct sum of \(\mathcal {P}_1\), \(\mathcal {P}_2\), and \(\mathcal {P}_3\). In other words, the dimension of \(\mathcal {P}\) might be smaller than 6, for instance if \(i=j\), i.e., \(\zeta _1 = \zeta _2\).
- 8.
The first case is the exactly same as the one shown in [20], but its correlation was reported as \(2^{-6.1}\). We are not sure the reason of this gap, but we think that \(2^{-6.1}\) refers to the bias instead of the correlation.
- 9.
It means that the success probability is \(0.489 \times 2 = 0.978\) under the condition that the right pair is successfully obtained during \(2^{17.206}\) iterations.
- 10.
Note that it means that the success probability is \(0.499 \times 2 = 0.999\) under the condition that the right pair is successfully obtained during \(2^{7}\) iterations.
 , we might alternatively choose
, we might alternatively choose 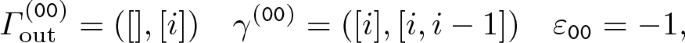
References
Aumasson, J.-P., Fischer, S., Khazaei, S., Meier, W., Rechberger, C.: New features of latin dances: analysis of Salsa, ChaCha, and Rumba. In: Nyberg, K. (ed.) FSE 2008, Revised Selected Papers. LNCS, vol. 5086, pp. 470–488. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-71039-4_30
Aumasson, J.P., Henzen, L., Meier, W., Phan, R.C.W.: SHA-3 proposal Blake. In: Submission to NIST (2008)
Aumasson, J.-P., Neves, S., Wilcox-O’Hearn, Z., Winnerlein, C.: BLAKE2: simpler, smaller, fast as MD5. In: Jacobson, M., Locasto, M., Mohassel, P., Safavi-Naini, R. (eds.) ACNS 2013. LNCS, vol. 7954, pp. 119–135. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-38980-1_8
Bar-On, A., Dunkelman, O., Keller, N., Weizman, A.: DLCT: a new tool for differential-linear cryptanalysis. In: Ishai, Y., Rijmen, V. (eds.) EUROCRYPT 2019, Part I. LNCS, vol. 11476, pp. 313–342. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-17653-2_11
Beierle, C., et al.: Lightweight AEAD and Hashing using the sparkle permutation family. IACR Trans. Symm. Cryptol. 2020(S1), 208–261 (2020)
Bernstein, D.J.: ChaCha, a variant of Salsa20 (2008). http://cr.yp.to/chacha.html
Bernstein, D.J.: The Salsa20 family of stream ciphers. In: Robshaw, M., Billet, O. (eds.) New Stream Cipher Designs. LNCS, vol. 4986, pp. 84–97. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-68351-3_8
Biham, E., Carmeli, Y.: An improvement of linear cryptanalysis with addition operations with applications to FEAL-8X. In: Joux, A., Youssef, A. (eds.) SAC 2014, Revised Selected Papers. LNCS, vol. 8781, pp. 59–76. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-13051-4_4
Biham, E., Shamir, A.: Differential cryptanalysis of DES-like cryptosystems. In: Menezes, A.J., Vanstone, S.A. (eds.) CRYPTO 1990. LNCS, vol. 537, pp. 2–21. Springer, Heidelberg (1991). https://doi.org/10.1007/3-540-38424-3_1
Carlet, C.: Boolean functions for cryptography and error correcting codes. In: Crama, Y., Hammer, P. (eds.) Boolean Methods and Models. Cambridge University Press (2007)
Choudhuri, A.R., Maitra, S.: Significantly improved multi-bit differentials for reduced round Salsa and ChaCha. IACR Trans. Symm. Cryptol. 2016(2), 261–287 (2016)
Collard, B., Standaert, F.-X., Quisquater, J.-J.: Improving the time complexity of Matsui’s linear cryptanalysis. In: Nam, K.-H., Rhee, G. (eds.) ICISC 2007. LNCS, vol. 4817, pp. 77–88. Springer, Heidelberg (2007). https://doi.org/10.1007/978-3-540-76788-6_7
Coutinho, M., Neto, T.C.S.: New multi-bit differentials to improve attacks against ChaCha. IACR Cryptology ePrint Archive 2020/350 (2020). https://eprint.iacr.org/2020/350
Dey, S., Sarkar, S.: Improved analysis for reduced round Salsa and ChaCha. Discrete Appl. Math. 227, 58–69 (2017)
Dinu, D., Perrin, L., Udovenko, A., Velichkov, V., Großschädl, J., Biryukov, A.: Design strategies for ARX with provable bounds: Sparx and LAX. In: Cheon, J.H., Takagi, T. (eds.) ASIACRYPT 2016, Part I. LNCS, vol. 10031, pp. 484–513. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-53887-6_18
Hermelin, M., Cho, J.Y., Nyberg, K.: Multidimensional linear cryptanalysis. J. Cryptol. 32(1), 1–34 (2019)
Khovratovich, D., Nikolić, I.: Rotational cryptanalysis of ARX. In: Hong, S., Iwata, T. (eds.) FSE 2010, Revised Selected Papers. LNCS, vol. 6147, pp. 333–346. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-13858-4_19
Knudsen, L., Wagner, D.: Integral cryptanalysis. In: Daemen, J., Rijmen, V. (eds.) FSE 2002, Revised Papers. LNCS, vol. 2365, pp. 112–127. Springer, Heidelberg (2002). https://doi.org/10.1007/3-540-45661-9_9
Langford, S.K., Hellman, M.E.: Differential-linear cryptanalysis. In: Desmedt, Y.G. (ed.) CRYPTO 1994. LNCS, vol. 839, pp. 17–25. Springer, Heidelberg (1994). https://doi.org/10.1007/3-540-48658-5_3
Leurent, G.: Improved differential-linear cryptanalysis of 7-round Chaskey with partitioning. In: Fischlin, M., Coron, J.-S. (eds.) EUROCRYPT 2016, Part I. LNCS, vol. 9665, pp. 344–371. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-49890-3_14
Lipmaa, H., Moriai, S.: Efficient algorithms for computing differential properties of addition. In: Matsui, M. (ed.) FSE 2001, Revised Papers. LNCS, vol. 2355, pp. 336–350. Springer, Heidelberg (2002). https://doi.org/10.1007/3-540-45473-X_28
Maitra, S.: Chosen IV cryptanalysis on reduced round ChaCha and Salsa. Discrete Appl. Math. 208, 88–97 (2016)
Matsui, M.: Linear cryptanalysis method for DES cipher. In: Helleseth, T. (ed.) EUROCRYPT 1993. LNCS, vol. 765, pp. 386–397. Springer, Heidelberg (1994). https://doi.org/10.1007/3-540-48285-7_33
Mouha, N., Mennink, B., Van Herrewege, A., Watanabe, D., Preneel, B., Verbauwhede, I.: Chaskey: an efficient MAC algorithm for 32-bit microcontrollers. In: Joux, A., Youssef, A. (eds.) SAC 2014, Revised Selected Papers. LNCS, vol. 8781, pp. 306–323. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-13051-4_19
Nyberg, K., Wallén, J.: Improved linear distinguishers for SNOW 2.0. In: Robshaw, M. (ed.) FSE 2006, Revised Selected Papers. LNCS, vol. 4047, pp. 144–162. Springer, Heidelberg (2006). https://doi.org/10.1007/11799313_10
Shi, Z., Zhang, B., Feng, D., Wu, W.: Improved key recovery attacks on reduced-round Salsa20 and ChaCha. In: Kwon, T., Lee, M.-K., Kwon, D. (eds.) ICISC 2012, Revised Selected Papers. LNCS, vol. 7839, pp. 337–351. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-37682-5_24
Shimizu, A., Miyaguchi, S.: Fast data encipherment algorithm FEAL. In: Chaum, D., Price, W.L. (eds.) EUROCRYPT 1987. LNCS, vol. 304, pp. 267–278. Springer, Heidelberg (1988). https://doi.org/10.1007/3-540-39118-5_24
Todo, Y., Leander, G., Sasaki, Yu.: Nonlinear invariant attack. In: Cheon, J.H., Takagi, T. (eds.) ASIACRYPT 2016, Part II. LNCS, vol. 10032, pp. 3–33. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-53890-6_1
Wallén, J.: Linear approximations of addition modulo 2\(^{ {n}}\). In: Johansson, T. (ed.) FSE 2003, Revised Papers. LNCS, vol. 2887, pp. 261–273. Springer, Heidelberg (2003). https://doi.org/10.1007/978-3-540-39887-5_20
Acknowledgments
We thank the anonymous reviewers for their detailed and helpful comments. We further thank Lukas Stennes for checking the application of our framework to ChaCha in a first version of this paper. This work was funded by Deutsche Forschungsgemeinschaft (DFG), project number 411879806 and by DFG under Germany’s Excellence Strategy - EXC 2092 CASA - 390781972.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 International Association for Cryptologic Research
About this paper

Cite this paper
Beierle, C., Leander, G., Todo, Y. (2020). Improved Differential-Linear Attacks with Applications to ARX Ciphers. In: Micciancio, D., Ristenpart, T. (eds) Advances in Cryptology – CRYPTO 2020. CRYPTO 2020. Lecture Notes in Computer Science(), vol 12172. Springer, Cham. https://doi.org/10.1007/978-3-030-56877-1_12
Download citation
DOI: https://doi.org/10.1007/978-3-030-56877-1_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-56876-4
Online ISBN: 978-3-030-56877-1
eBook Packages: Computer ScienceComputer Science (R0)
