
Abstract
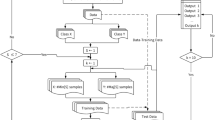
This study discusses the effects of training data size and class imbalance on the performance of classifiers. An empirical study was performed on nine classifiers with twenty benchmark datasets. First, two groups of datasets (those with few variables and those with numerous variables) were prepared. Then we progressively increased the class imbalance of each dataset in each group by under-sampling both classes so that we could clarify to what extent the predictive power of each classifier was adversely affected. Kappa coefficient (kappa) was chosen as the performance metric, and nemenyi post hoc test was used to find significant differences between classifiers. Additionally, the ranks of nine classifiers in different conditions were discussed. The results indicated that (1) Naïve bayes, logistic regression and logit leaf model are less susceptible to class imbalance; (2) It was assumed that using datasets with balanced class distribution and sufficient instances would be the ideal condition to maximize the performance of classifiers; (3) Increasing the number of instances is more effective than using variables for improving the predictive performance of Random Forest. Furthermore, our experiment clarified the optimal classifiers for four types of datasets.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

Notes
- 1.
NFL theorem: If algorithm A outperforms algorithm B on some cost functions, then loosely speaking there must exist exactly as many other functions where B outperforms A.
- 2.
References
Ali, S., Smith, K.A.: On learning algorithm selection for classification. Appl. Soft Comput. 6(2), 119–138 (2006)
Brazdil, P.B., Soares, C., Pinto da Costa, J.: Ranking learning algorithms: using IBL and meta-learning on accuracy and time results. Mach. Learn. 50(3), 251–277 (2003)
Brown, I., Mues, C.: An experimental comparison of classification algorithms for imbalanced credit scoring data sets. Expert Syst. Appl. 39(3), 3446–3453 (2012)
Caigny, A.D., Coussement, K., De Bock, K.W.: A new hybrid classification algorithm for customer churn prediction based on logistic regression and decision trees. Eur. J. Oper. Res. 269(2), 760–772 (2018)
Demšar, J.: Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 7, 1–30 (2006)
Foody, G.M., Mathur, A.: A relative evaluation of multiclass image classification by support vector machine. IEEE Trans. Geosci. Remote Sens. 42(6), 1335–1343 (2004)
Fernández-Delgado, M., Cernadas, E., Barro, S.: Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 15, 3133–3181 (2014)
Halevy, A., Norvig, P., Pereita, F.: The unreasonable effectiveness of data. IEEE Intell. Syst. 24(2), 1541–1672 (2009)
Kalousis, A., Gama, J., Hilario, M.: On data and algorithms: understanding inductive performance. Mach. Learn. 54(3), 275–312 (2004)
Mathur, A., Foody, G.M.: Crop classification by a support vector machine with intelligently selected training data for an operational application. Int. J. Remote Sens. 29(8), 2227–2240 (2008)
Pal, M., Mather, P.M.: An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Environ. 86(4), 554–565 (2003)
Song, Q., Wang, G., Wang, C.: Automatic commendation of classification algorithms based on data set characteristics. Pattern Recogn. 45(2), 1672–2689 (2012)
Smith, K.A., Woo, F., Ciesielski, V., Ibrahim, R.: Matching data mining algorithm suitability to data characteristics using a self-organizing map. In: Abraham, A., Köppen, M. (eds.) Hybrid Information Systems. AISC, vol. 14, pp. 169–179. Physica, Heidelberg (2002). https://doi.org/10.1007/978-3-7908-1782-9_13
Smith, K.A., Woo, F., Ciesielski, V., Ibrahim, R.: Modelling the relationship between problem characteristics and data mining algorithm performance using neural networks. In: Smart Engineering System Design: Neural Networks, Fuzzy Logic, Evolutionary Programming, Data Mining, and Complex Systems, vol. 11, pp. 356–362 (2001)
Sánchez, J.S., Molineda, R.A., Sotoca, K.M.: An analysis of how training data complexity affects the nearest neighbor classifiers. Pattern Anal. Appl. 10, 189–201 (2007)
Wolpert, D.H., Macready, W.G.: No Free Lunch theorem for search. Technical report SFI-TR-05-010, Santa Fe Institute, Santa Fe, NM (1995)
Wainberg, M., Alipanahi, B., Frey, B.J.: Are random forests truly the best classifiers? J. Mach. Learn. Res. 17, 1–5 (2016)
Weiss, G.M., Provost, F.: The effect of class distribution on classifier learning, Technical report ML-TR-43, Department of Computer Science, Rutgers University (2001). https://www.researchgate.net/publication/2364670_The_Effect_of_Class_Distribution_on_Classifier_Learning_An_Empirical_Study
Zhu, X., Vondrick, C., Fowlkes, C., Ramanan, D.: Do we need more training data? Int. J. Comput. Vis. 19(1), 76–92 (2016)
Jeni, L.A., Cohn, J.F., Torre, F.D.L.: Facing imbalanced data-recommendations for the use of performance metrics. In: International Conference on Affective Computing and Intelligent Interaction (2013)
Chawla, N.V., Japkowicz, N., Kotcz, A.: Editorial: special issue on learning from imbalanced data sets. SIGKDD Explor. Newsl. 6(1), 1–6 (2004)
Eitrich, T., Lang, B.: Efficient optimization of support vector machine learning parameters for unbalanced datasets. J. Comput. Appl. Math. 196(2), 425–436 (2006)
Garcia, V., Mollineda, R.A., Sanchez, J.S.: Theoretical analysis of a performance measure for imbalanced data. In: 2010 20th International Conference on Pattern Recognition (ICPR). IEEE (2010)
Tang, Y., Zhang, Y.-Q., Chawla, N.V., Krasser, S.: SVMs modeling for highly imbalanced classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 39(1), 281–288 (2009)
Van Hulse, J., Khoshgoftaar, T.M., Napolitano, A.: Experimental perspectives on learning from imbalanced data. In: Proceedings of the 24th International Conference on Machine Learning. ACM (2007)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Zheng, W., Jin, M. (2019). Effects of Training Data Size and Class Imbalance on the Performance of Classifiers. In: Ustalov, D., Filchenkov, A., Pivovarova, L. (eds) Artificial Intelligence and Natural Language. AINL 2019. Communications in Computer and Information Science, vol 1119. Springer, Cham. https://doi.org/10.1007/978-3-030-34518-1_1
Download citation
DOI: https://doi.org/10.1007/978-3-030-34518-1_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-34517-4
Online ISBN: 978-3-030-34518-1
eBook Packages: Computer ScienceComputer Science (R0)