
Abstract
In this work we propose a novel method for supervised, keyshots based video summarization by applying a conceptually simple and computationally efficient soft, self-attention mechanism. Current state of the art methods leverage bi-directional recurrent networks such as BiLSTM combined with attention. These networks are complex to implement and computationally demanding compared to fully connected networks. To that end we propose a simple, self-attention based network for video summarization which performs the entire sequence to sequence transformation in a single feed forward pass and single backward pass during training. Our method sets a new state of the art results on two benchmarks TvSum and SumMe, commonly used in this domain.
This research was funded by the H2020 MONICA European project 732350 and by the NATO within the WITNESS project under grant agreement number G5437 and within the MIDAS G5381. We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan Xp GPU used for this research.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
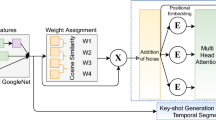


Notes
- 1.
- 2.
- 3.
- 4.
References
Argyriou, V.: Sub-hexagonal phase correlation for motion estimation. IEEE Trans. Image Process. 20(1), 110–120 (2011)
Athiwaratkun, B., Kang, K.: Feature representation in convolutional neural networks. arXiv preprint arXiv:1507.02313 (2015)
Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint arXiv:1607.06450 (2016)
Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014)
Cheng, J., Dong, L., Lapata, M.: Long short-term memory-networks for machine reading. In: Proceedings of the EMNLP, pp. 551–561 (2016)
Cho, K., Merrienboer, B., Gulcehre, C., Bougares, F., Schwenk, H., Bengio, Y.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Proceedings of the EMNLP (2014)
De Avila, S.E.F., Lopes, A.P.B., da Luz Jr., A., de Albuquerque Araújo, A.: VSUMM: a mechanism designed to produce static video summaries and a novel evaluation. Pattern Recogn. Lett. 32(1), 56–68 (2011)
Fajtl, J., Argyriou, V., Monekosso, D., Remagnino, P.: AMNet: memorability estimation with attention. In: Proceedings of the IEEE CVPR, pp. 6363–6372 (2018)
Fei, M., Jiang, W., Mao, W.: Memorable and rich video summarization. J. Vis. Commun. Image Represent. 42(C), 207–217 (2017)
Gehring, J., et al.: Convolutional sequence to sequence learning. In: Proceedings of the ICML, pp. 1243–1252, 06–11 August 2017
Graves, A., et al.: Hybrid computing using a neural network with dynamic external memory. Nature 538(7626), 471 (2016)
Gygli, M., Grabner, H., Riemenschneider, H., Van Gool, L.: Creating summaries from user videos. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8695, pp. 505–520. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10584-0_33
Gygli, M., et al.: Video summarization by learning submodular mixtures of objectives. In: Proceedings of the IEEE CVPR, pp. 3090–3098 (2015)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Ji, Z., Xiong, K., Pang, Y., Li, X.: Video summarization with attention-based encoder-decoder networks. arXiv preprint arXiv:1708.09545 (2017)
Khosla, A., Raju, A.S., Torralba, A., Oliva, A.: Understanding and predicting image memorability at a large scale. In: Proceedings of the IEEE ICCV, pp. 2390–2398 (2015)
Kingma, D., Ba, J.: Adam: a method for stochastic optimization. In: Proceedings of the ICLR, vol. 5 (2015)
Larkin, K.G.: Reflections on Shannon information: in search of a natural information-entropy for images. CoRR abs/1609.01117 (2016)
Lin, C.Y.: ROUGE: a package for automatic evaluation of summaries. In: Text Summarization Branches Out: Proceedings of the ACL-2004 Workshop, pp. 74–81. Association for Computational Linguistics, Barcelona, July 2004
Lin, Z., et al.: A structured self-attentive sentence embedding. In: Proceedings of the ICLR (2017)
Luong, M.T., Pham, H., Manning, C.D.: Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025 (2015)
Luong, T., Pham, H., Manning, C.D.: Effective approaches to attention-based neural machine translation. In: Proceedings of the EMNLP (2015)
Mahasseni, B., Lam, M., Todorovic, S.: Unsupervised video summarization with adversarial LSTM networks. In: Proceedings of the IEEE CVPR, pp. 2982–2991 (2017)
Mnih, V., Heess, N., Graves, A., et al.: Recurrent models of visual attention. In: Proceedings of the NIPS, pp. 2204–2212 (2014)
Novak, C.L., Shafer, S.A.: Anatomy of a color histogram. In: Proceedings of the IEEE CVPR, pp. 599–605. IEEE (1992)
Otani, M., et al.: Video summarization using deep semantic features. In: Proceedings of the ACCV, pp. 361–377 (2016)
Parikh, A., et al.: A decomposable attention model for natural language inference. In: Proceedings of the EMNLP, pp. 2249–2255 (2016)
Potapov, D., Douze, M., Harchaoui, Z., Schmid, C.: Category-specific video summarization. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8694, pp. 540–555. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10599-4_35
Rochan, M., Wang, Y.: Learning video summarization using unpaired data. arXiv preprint arXiv:1805.12174 (2018)
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M.: Others: imagenet large scale visual recognition challenge. Int. J. Comput. Vision 115(3), 211–252 (2015)
dos Santos Belo, L., Caetano Jr., C.A., do Patrocínio Jr., Z.K.G., Guimarães, S.J.F.: Summarizing video sequence using a graph-based hierarchical approach. Neurocomputing 173, 1001–1016 (2016)
Song, Y., Vallmitjana, J., Stent, A., Jaimes, A.: TVSum: summarizing web videos using titles. In: Proceedings of the IEEE CVPR, pp. 5179–5187 (2015)
Szegedy, C., et al.: Going deeper with convolutions. In: Proceedings of the IEEE CVPR, pp. 1–9 (2015)
Vaswani, A., et al.: Attention is all you need. In: Proceedings of the NIPS, pp. 5998–6008. Curran Associates, Inc. (2017)
Wei, H., Ni, B., Yan, Y., Yu, H., Yang, X., Yao, C.: Video summarization via semantic attended networks. In: Proceedings of the AAAI (2018)
Williams, R.J.: Simple statistical gradient-following algorithms for connectionist reinforcement learning. In: Sutton, R.S. (ed.) Reinforcement Learning, pp. 5–32. Springer, Boston (1992). https://doi.org/10.1007/978-1-4615-3618-5_2
Xu, K., et al.: Show, attend and tell: neural image caption generation with visual attention. In: Proceedings of the ICML, pp. 2048–2057 (2015)
Yao, L., et al.: Describing videos by exploiting temporal structure. In: Proceedings of the IEEE ICCV, pp. 4507–4515 (2015)
Yuan, Y., Mei, T., Cui, P., Zhu, W.: Video summarization by learning deep side semantic embedding. IEEE Trans. Circuits Syst. Video Technol. 29(1), 226–237 (2017). https://doi.org/10.1109/TCSVT.2017.2771247
Zhang, K., Chao, W.-L., Sha, F., Grauman, K.: Video summarization with long short-term memory. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9911, pp. 766–782. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46478-7_47
Zhao, B., Li, X., Lu, X.: Hierarchical recurrent neural network for video summarization. In: Proceedings of the ACM Multimedia Conference, pp. 863–871 (2017)
Zhou, K., Qiao, Y., Xiang, T.: Deep reinforcement learning for unsupervised video summarization with diversity-representativeness reward. In: Proceedings of the AAAI (2018)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Fajtl, J., Sokeh, H.S., Argyriou, V., Monekosso, D., Remagnino, P. (2019). Summarizing Videos with Attention. In: Carneiro, G., You, S. (eds) Computer Vision – ACCV 2018 Workshops. ACCV 2018. Lecture Notes in Computer Science(), vol 11367. Springer, Cham. https://doi.org/10.1007/978-3-030-21074-8_4
Download citation
DOI: https://doi.org/10.1007/978-3-030-21074-8_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-21073-1
Online ISBN: 978-3-030-21074-8
eBook Packages: Computer ScienceComputer Science (R0)