
Abstract
Weakly-supervised temporal action localization has attracted much attention among researchers in video content analytics, thanks to its relaxed requirements of video-level annotations instead of frame-level labels. However, many current weakly-supervised action localization methods depend heavily on naive feature combination and empirical thresholds to determine temporal action boundaries, which is practically feasible but could still be sub-optimal. Inspired by the momentum term, we propose a general-purpose action recognition criterion that replaces explicit empirical thresholds. Based on such criterion, we analyze different combination of streams and propose the Action Sensitive Extractor (ASE) that produces action sensitive features. Our ASE sets temporal stream as main stream and extends with complementary spatial streams. We build our Action Sensitive Network (ASN) and evaluate on THUMOS14 and ActivityNet1.2 with different selection method. Our network yields state-of-art performance in both datasets.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Temporal action localization (TAL) in untrimmed videos has attracted more and more attention in recent years, many methods [9, 11, 14, 23, 28, 38, 41, 43] that greatly enhanced performance have been developed. Because labeling action boundary in untrimmed video is expensive, some researchers [25, 26, 30, 33, 38] proposed to use video-level action annotation to produce snippet level action localization results, which greatly reduced demand for human laboring and yield comparable performance. These studies combine Multiple Instance Learning (MIL) [7] and attention mechanism [25, 26, 38] with Deep Convolutional Neural Networks (DCNN) to produce clip presentations. Then, action detection criterions maps clip presentations to Class Activation Sequence (CAS) which determines which snippet includes action.
However, these weakly-supervised methods share two convenient assumptions that might be too optimistic in the real world. The first assumption is empirical thresholds to determine temporal action boundaries could be obtained in a trivial manner. This implicit assumption could be far from reality, given the diversity of datasets and applications. The second assumption is that straightforward fusion strategies are adequate in weakly-supervised TAL because of the prevailing two-stream networks [3, 32, 39], where CAS is either generated separately and fused by weighted average [25, 30, 38], or generated by concatenated features [26] and [30] regression methods. With the two-stream network, each stream is independently trained via backpropagation and no interactions happen between streams. These two strategies are straightforward to implemented but we argue that there could possibly be a better alternative.
To address these challenges, we design a general-purpose action detection criterion and an alternative stream fusion strategy. Specifically, we design the action detection criterion based on attention mechanism with momentum-inspired threshold generated in training stage. An analysis in stream combination options results in the proposed Action Sensitive Extractor (ASE) as shown in Fig. 1. Inspired by recent literature in spatial and temporal interaction [10, 35], the proposed ASE prudently selects action sensitive features between two streams and produces activations. In the ASE, we handle spatial and temporal stream asymmetrically with respect to different sensitivities in actions. With our action detection criterion and the ASE, we build Action Sensitive Network (ASN) for Weakly-supervised TAL.

Illustration of different strategies to combine two-stream features. (a) Lateral fusion of two-stream features. (b) Concatenating two-stream features for processing. (c) Our action sensitive extractor.
Main contributions of this paper include (1) a comparative analysis on stream fusion strategies with the proposed Action Sensitive Extractor (ASE), and (2) a new flexible action localization criterion which generates high quality CAS. The performance gains of the proposed ASN algorithm are verified on two challenging public datasets.
2 Related Works
Video Action analyze has been wildly discussed in several years. Most studies focus on action recognition in trimmed videos. Many novel structures have been proposed for videos [3, 8, 15, 19] based on DCNN neural networks [16, 17, 37]. Two-stream network [32] was one design which employs RGB images and optical Flow with lateral fusion. Based on two-stream network, temporal segment network (TSN) [39] was proposed to analyze long-term temporal data. TSN has been used as backbone in different tasks [38, 43] with good performance. To further leverage optical Flow, [35] proposed a novel structure for optical Flow. Recent proposed SlowFast Network [10] uses two path way to process videos similar to two-stream network. In SlowFast, a fast pathway handles wide temporal motions and a slow pathway handles rich local details.
Action localization has been greatly improved based on video action analyze. Many neural architectures and methods [9, 13, 21, 24] have been developed for supervised learning. However, those studies heavy rely on data annotations of action sequences, which are expensive to acquire. To incorporate more data in training, Sun et al. [34] proposed to use web images and video-level annotation to handle TAL. Moreover, hide and seek [33] discovered how to force network focus on most discriminating part. UntrimmedNet [38] designed a novel structures that trains high-quality network on untrimmed videos and proposed a method which efficiently selects action segments. UntrimmedNet not only provide a good solution for Localization but is also a good baseline model that generates local representation. Based on extracted feature representation, AutoLoc [30] discovered an anchor generation and selection standard on feature sequences. W-TALC [26] and Nguyen et al. [25] discovered feature based networks with different auxiliary loss functions and attention mechanism.
3 Action Sensitive Network
In this section, our proposed Action Sensitive Network will be introduced. Section 3.1 describes the ASE we proposed. Section 3.2 describes our momentum-inspired action detection criterion. In the last section, we introduce details of ASN.
3.1 Action Sensitive Extractor
In this section, we propose models to extract action sensitive features. Our proposal is to train a network that maximally leverage action sensitive features in two streams. Because actions are described in moving image in videos, spatial stream with only one frame perception unlikely to recognize action directly. While temporal stream have wider temporal perception and inherently sensitive at motion boundary [27]. Detial analysis can be found in our experiment section. Inspired by SlowFast network [10], where spatial (slow) and temporal (fast) are fed into different network architectures with different channels and different temporal perception, we propose our models that treat temporal and spatial asymmetrically.
In general, we use learned action sensitive knowledge (inherit from temporal stream) as main stream. We discover different structures to extract beneficial features to reinforce main stream. We adopt strategy in DenseNet [17] that we concatenate our main stream and reinforce stream together for classification and attention calculation. We call our extraction model Action Sensitive Extractor (ASE), different settings of ASE are shown in Fig. 2. For simplicity, we still use single fully-connected layer for classification or attention branch. ASE with classification and attention branch is referred as ASE model.

Data flow of different ASE settings. We set temporal stream as main stream and spatial stream as reinforce stream. Reinforced streams are fed into classification and activation branch then. (a) Fusion model. (b) Bottleneck model. (c) Bilinear bottleneck model.
Fusion with Temporal Knowledge. To leverage temporal features that are related to actions, we propose to build a network that initialized with temporal features and extended with spatial features. To achieve this goal, we adopt methods from [4], our network on fusion (concatenated) features is initiated with pretrained temporal weights and zero spatial weights. For example, Eq. 1 shows the classification branch for fusioned features. To inherit knowledge in temporal classifier, we set \(\mathbf {W}^{t}\) and \(\mathbf {b}^{t}\) to pretrained temporal weights, while \(\mathbf {W}^{s}\) and \(\mathbf {b}^{s}\) are set to 0. We also apply same method to attention branch.
Bottleneck Model. To limit overfitting with spatial features, we further study on limiting and distilling spatial features. Different from former studies that enforce loss [26], we simply use special designed network architecture. As a naive attempt, we use a bottleneck layer to extract knowledge from spatial features. The bottleneck layer includes a dropout, a fully-connected layer and ReLU activation. The features extracted from bottleneck layer are concatenated with temporal features and feed to classification and attention branch. Our bottleneck layer extracts most expressive spatial features that help to identify actions.
Bilinear Bottleneck Model. Bottleneck model will remove unnecessary spatial feature but can’t introduce interactions. In recent works [5, 40], bilinear layers are proposed to aggregate spatial-temporal features. To make use of connection between streams, we propose to use bilinear block to aggregate features. In our work, we propose to use two fully-connected bottleneck layer to aggregate features in each stream and use bilinear layer to combine temporal and spatial features. We use 0.5 dropout before bottleneck layer and bilinear layer. We use ReLU activation after fc layers and bilinear layer. The aggregated features are concatenated with temporal features as in bottleneck model. Hidden layer size of bottleneck layer and bilinear layer are set to same for simplicity.
3.2 Action Detection Criterion
Here we represent our action detection criterion. In our study, we propose to trim fixed proportion of clips as background, since proportion of background frames is relative stable in each dataset. We set our threshold as quantile of attention values during training, similar to batch normalization [18], where mean and standard deviation in each batch is recorded and reused, to deal with fluctuation.
Quantile level describes desired proportion of clips. Level of quantile defines how much proportion the quantile divide, e.g. quantile at 30% means around 30% of clips in each batch have lower attention than the quantile. For each batch in training, we sort attentions of each clip in this batch and sample a attention value at desired level. Current quantile is updated by a momentum factor according to Eq. 2. Quantile is fixed during testing.
Our method is simple and cross modality, it is easy to apply our action detection criterion to any attention based localization problem across different settings. Note that the quantile maybe different across datasets, since proportion of background frames maybe different.

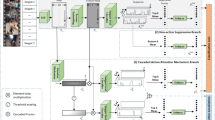
Our full network for action recognition and detection. We use our ASE model to produce frame activations and attentions. Video-level classification activations are optimized with video-level annotations. CAS is generated by action detection criterion. Action segments are selected based on CAS.
3.3 Network Details
Having explained key components, now we introduce details of our ASN as shown in Fig. 3. To efficiently look over long video, we break videos into different levels. In bottom level, each frame is represented separately as frame. We use features from our two-stream pretrained DCNN model as representation. Then the middle level, which is clip level. We average our features sampled in short temporal period as clip representation since close frames in videos should be correlated. To distill key knowledge and trim noise, we use Action Sensitive Extractor to extract features and feed to classification and attention branch. The highest level is video-level, which is aggregated by attention mechanism. This level is symmetrical to annotations.
In our study, we discover a setting based on extracted features from UntrimmedNet [38]. Following UntrimmedNet [38], we randomly sample 7 clips for untrimmed videos, 1 clips for video clips. For each clip, 3 frames are sparsely sampled as in TSN [39] and averaged as clip representation. Two fully-connected layers are used to produce classification and attention respectively. Dropout of 0.5 is used only before classification layer. To fuse clip level activations, we apply softmax operation on attentions x from clip 1 to t. The normalized attentions \(\bar{x_i^a} = \frac{exp(x_i^a)}{\sum _{j=1}^t{exp(x_j^a)}}\) are used to fuse clip level classifications into video level prediction \(\mathbf {x}^c\), where \(\mathbf {x}^c = \sum _{i=1}^t {\bar{x_i^a} \mathbf {x}_i^c}\). Next, we apply softmax operations among each dimension of prediction and optimize with multi-label cross-entropy loss.
During testing, we use strategy similarly to [38] and [30]. Each clip is aggregated every 15 frames. ASE model produces classification and attention activations for each clip. For video recognition, we soften our attentions by a factor (sets to 3) at first. Then, clips are fused to video representation according to their attentions as in training. For video detection, we generate CAS of size \(clip\_number \times class\_number\) and feed it into selection method. Firstly, we apply softmax operation on clip classification activations. Then, we apply threshold on video-level prediction, clip activations of video unrelated class are set to 0 in CAS. Thirdly, we apply attention level threshold, clips with attentions lower than threshold are set to 0 in CAS. Finally we feed our CAS into selection method to generate action segments.
4 Experiments
4.1 Dataset
THUMOS14 [20] has 101 classes for recognition and 20 classes out of 101 for action detection. THUMOS14 includes training set, validation set and testing set. Training set includes action video clips, validation and testing set includes untrimmed videos. In THUMOS14, 15 instances of actions covers 29% of video on average [28]. We train our model on training set and validation set, we test our model on testing set.
ActivityNet1.2 [2] has 100 classes for both detection and recognition. It is divided into training set, validation set and test set. In ActivityNet, 1.5 instances of actions covers 64% of video on average [28]. We train our model on training set and test on validation set.
4.2 Implementation Details
We train our ASN using features extracted by UntrimmedNet pretrained model, which trained on same dataset and subsets as UntrimmedNet. We train our network with Nestrov momentum [36] of 0.9, weights decay of 0.0005. Batch size is set to 512 for THUMOS14 validation set and 8192 for THUMOS14 training set. Batch size is set to 512 for ActivityNet1.2. On THUMOS14 [20], we train 80 epochs jointly on training set and validation set. Our learning rate is set to 0.1 and decay 10 times on 40th and 60th epoch. On ActivityNet1.2 [2], we train 160 epochs jointly on training set. Learning rate is set to 0.1 and decay on 80th and 120th epoch.
4.3 Ablation Study
In this section, we explore our action detection criterion at different levels of quantiles and different model settings. For simplicity and efficiency, we use naive approach in UntrimmedNet [38] as selection method in ablation study on THUMOS14. This method only selects consecutive activated frames in CAS. For a selected snippet from clip timestamp n to \(k+n\) with label v, confidence scores s are evaluated by video-level activation \(c_{v}\) and average activation as shown in Eq. 4. Where we use \(\lambda = 0.2\) in our experiment.
Evaluation of Action Detection Criterion. To demonstrate efficiency of our action detection criterion, we train our network 10 times and record performance on testing set under different quantiles. As baseline, spatial (RGB) and temporal (Flow) models are treated separately. Different levels of quantiles are recorded and tested on localization task. We train our network 10 times and quantiles are recorded at level 10%, 20%, 30% to 90%. To compare with former studies, we also apply our methods on pretrained weights provided by [38], the quantiles of pretrained models are recorded by running on THUMOS14 validation set. CAS of two-stream model in localization are generated by two steps. First, clip level classifications after softmax are averaged. Second, attention scores of each stream are normalized by each threshold and averaged. Video-level recognition results are set to average of two streams.

Localization mAP of flow and rgb model under different quantiles on THUMOS14. mAP is recorded under 0.5 IoU threshold.
Results of spatial and temporal model under IoU threshold of 0.5 are shown in Fig. 4. The performance of pretrained model on different quantiles are shown in Fig. 5. For different models, performance peaks locate near 50% quantiles. During training, we find attention quantiles are fluctuating but performances are generally stable. Notably, spatial performances are worse and more unstable than temporal. We also compare our methods with original UntrimmedNet [38]. Performances of our best models under different settings are shown in Table 1. Our action detection criterion can achieve high performance with only temporal stream.
Evaluation of Streams. We evaluate different combination of streams as shown in Table 1. We evaluate on spatial (RGB), temporal (Flow), two-stream and fusion stream (concatenated features of RGB and Flow). We also discover attention quality of each stream.
Surprisingly, temporal stream yield the best localization performance. Streams with spatial features perform poorly. The bad behavior of spatial related streams may because of trivial details in spatial features cause overfitting. In addition, we analyze attention in each stream. For two-stream model, we fix CAS and apply only temporal or spatial attention to our criterion. We find two-stream with temporal attentions yield high performance similar to temporal stream and two-stream with spatial attentions yield low performance similar to fusion stream.
Our experiment shows differences in action sensitivity between two streams. Combining with temporal and spatial information usually yield higher performance in action recognition but lower in localization. We also find commonly used two-stream or fusion strategies are inefficient in weakly-supervised localization task, which are worse than single temporal stream.
Evaluation of ASE. We evaluate different ASE model settings. For inherit strategy, we our best flow model as initial weight. For fusion model, bottleneck model and bilinear bottleneck model, we compare training from scratch and inherit strategy with feature size of 64. We compare inherit strategy of feature size of 64 and 128 in bottleneck model and bilinear bottleneck model. Our results are shown in Table 2.

Localization mAP of pretrained model under different quantiles on THUMOS14. mAP is recorded under 0.5 IoU threshold.
Compare with training from scratch, inherit strategy greatly improves recognition and localization except for bottleneck model. For bottleneck model, only localization is slightly improved. This phenomenon may denotes that our bottleneck model has already restrained overfitting. For bottleneck models and bilinear bottleneck models, feature size from 64 to 128 slightly improves performance.
In recognition tasks, fusion model has the highest performance because it can access full information, it also proves that our bottleneck structure does restrain information. For localization, bottleneck model and bilinear bottleneck model performs much higher than fusion model. Bilinear bottleneck models perform slightly higher than bottleneck model, which denotes that bilinear layer does improve interaction. High performance of our proposed ASE models shows its ability to extract action sensitive features.
4.4 Experiments on AutoLoc
To evaluate our final Action Sensitive Network, we use AutoLoc [30] as selection methods and compare with state-of-art results. AutoLoc incorporate Outer-Inter-Contrastive (OIC) loss that evaluate action snippet accurately. To further adjust performance, we increase weights for outer boundary in OIC as follow:
On THUMOS14, we set \(\lambda \) to 2. We also increase boundary inflation rate to 0.35. These settings help AutoLoc select most distinguishable action snippets. We add more offset anchors to AutoLoc and only use AutoLoc as a selection method over CAS. We show performance of our bilinear bottleneck model with feature size 128 and inherit strategy in Table 4. For ActivityNet1.2 [2], we set \(\lambda \) to 5 and boundary inflation to 0.7. We use quantile at 10% for ActivityNet1.2. Our results are shown in Table 3. Compare with other weakly-supervised TAL methods, our method have advantage especially under higher IoU and reach state-of-art level in both datasets.
5 Conclusion
We propose a general action detection criterion which can generate high quality CAS and can apply to different modalities. Based on this thresholding method, we analyze performance of different combinations of streams. According to our experiments, spatial and temporal stream contains different information and have different sensitivity in actions. To combine two streams properly, we propose our novel Action Sensitive Network. Two-stream features are treated asymmetry to produce accurate representation without losing sensitivity in actions. We use ASE model to produce clip features and CAS that can be applied to different selection methods. Our network yields state-of-art performance with AutoLoc as selection method. In the future, we can investigate higher level relationship between different streams and apply our method to more modalities.
References
Buch, S., Escorcia, V., Ghanem, B., Fei-Fei, L., Niebles, J.: End-to-end, single-stream temporal action detection in untrimmed videos. In: BMVC (2017)
Caba Heilbron, F., Escorcia, V., Ghanem, B., Carlos Niebles, J.: Activitynet: a large-scale video benchmark for human activity understanding. In: CVPR (2015)
Carreira, J., Zisserman, A.: Quo Vadis, action recognition? A new model and the kinetics dataset. In: CVPR (2017)
Chen, T., Goodfellow, I., Shlens, J.: Net2Net: accelerating learning via knowledge transfer. arXiv preprint arXiv:1511.05641 (2015)
Chen, Y., Kalantidis, Y., Li, J., Yan, S., Feng, J.: A\(^2\)-Nets: double attention networks. In: NIPS (2018)
Dai, X., Singh, B., Zhang, G., Davis, L.S., Qiu Chen, Y.: Temporal context network for activity localization in videos. In: ICCV (2017)
Dietterich, T.G., Lathrop, R.H., Lozano-Pérez, T.: Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell. 89, 31–71 (1997)
Donahue, J., et al.: Long-term recurrent convolutional networks for visual recognition and description. In: CVPR (2015)
Escorcia, V., Caba Heilbron, F., Niebles, J.C., Ghanem, B.: DAPs: deep action proposals for action understanding. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9907, pp. 768–784. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46487-9_47
Feichtenhofer, C., Fan, H., Malik, J., He, K.: SlowFast networks for video recognition. arXiv preprint arXiv:1812.03982 (2018)
Gao, J., Yang, Z., Nevatia, R.: Cascaded boundary regression for temporal action detection. arXiv preprint arXiv:1705.01180 (2017)
Gao, J., Yang, Z., Sun, C., Chen, K., Nevatia, R.: TURN TAP: temporal unit regression network for temporal action proposals. In: ICCV (2017)
Gkioxari, G., Malik, J.: Finding action tubes. In: CVPR (2015)
Gudi, A., van Rosmalen, N., Loog, M., van Gemert, J.: Object-extent pooling for weakly supervised single-shot localization. arXiv preprint arXiv:1707.06180 (2017)
He, K., Zhang, X., Ren, S., Sun, J.: Spatial pyramid pooling in deep convolutional networks for visual recognition. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8691, pp. 346–361. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10578-9_23
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: CVPR (2017)
Ioffe, S., Szegedy, C.: Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167 (2015)
Ji, S., Xu, W., Yang, M., Yu, K.: 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 31, 221–231 (2013)
Jiang, Y.G., et al.: THUMOS challenge: action recognition with a large number of classes (2014). http://crcv.ucf.edu/THUMOS14/
Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., Fei-Fei, L.: Large-scale video classification with convolutional neural networks. In: CVPR (2014)
Lin, T., Zhao, X., Shou, Z.: Single shot temporal action detection. In: Proceedings of the 2017 ACM on Multimedia Conference (2017)
Lin, T., Zhao, X., Su, H., Wang, C., Yang, M.: BSN: boundary sensitive network for temporal action proposal generation. arXiv preprint arXiv:1806.02964 (2018)
Ma, S., Sigal, L., Sclaroff, S.: Learning activity progression in LSTMs for activity detection and early detection. In: CVPR (2016)
Nguyen, P., Liu, T., Prasad, G., Han, B.: Weakly supervised action localization by sparse temporal pooling network. In: CVPR (2018)
Paul, S., Roy, S., Roy-Chowdhury, A.K.: W-TALC: weakly-supervised temporal activity localization and classification. arXiv preprint arXiv:1807.10418 (2018)
Sevilla-Lara, L., Liao, Y., Guney, F., Jampani, V., Geiger, A., Black, M.J.: On the integration of optical flow and action recognition. arXiv preprint arXiv:1712.08416 (2017)
Seybold, B., Ross, D., Deng, J., Sukthankar, R., Vijayanarasimhan, S., Chao, Y.W.: Rethinking the faster R-CNN architecture for temporal action localization (2018)
Shou, Z., Chan, J., Zareian, A., Miyazawa, K., Chang, S.F.: CDC: convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos. In: CVPR (2017)
Shou, Z., Gao, H., Zhang, L., Miyazawa, K., Chang, S.-F.: AutoLoc: weakly-supervised temporal action localization in untrimmed videos. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11220, pp. 162–179. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01270-0_10
Shou, Z., Wang, D., Chang, S.F.: Temporal action localization in untrimmed videos via multi-stage CNNs. In: CVPR (2016)
Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recognition in videos. In: Advances in Neural Information Processing Systems (2014)
Singh, K.K., Lee, Y.J.: Hide-and-seek: forcing a network to be meticulous for weakly-supervised object and action localization. In: ICCV (2017)
Sun, C., Shetty, S., Sukthankar, R., Nevatia, R.: Temporal localization of fine-grained actions in videos by domain transfer from web images. In: Proceedings of the 23rd ACM International Conference on Multimedia (2015)
Sun, S., Kuang, Z., Sheng, L., Ouyang, W., Zhang, W.: Optical flow guided feature: a fast and robust motion representation for video action recognition. In: CVPR (2018)
Sutskever, I., Martens, J., Dahl, G., Hinton, G.: On the importance of initialization and momentum in deep learning. In: ICML (2013)
Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A.A.: Inception-v4, inception-ResNet and the impact of residual connections on learning. In: AAAI, vol. 4, p. 12 (2017)
Wang, L., Xiong, Y., Lin, D., Van Gool, L.: UntrimmedNets for weakly supervised action recognition and detection. In: CVPR (2017)
Wang, L., et al.: Temporal segment networks: towards good practices for deep action recognition. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 20–36. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_2
Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: CVPR (2018)
Xu, H., Das, A., Saenko, K.: R-C3D: region convolutional 3D network for temporal activity detection. In: ICCV (2017)
Yuan, J., Ni, B., Yang, X., Kassim, A.A.: Temporal action localization with pyramid of score distribution features. In: CVPR (2016)
Zhao, Y., Xiong, Y., Wang, L., Wu, Z., Tang, X., Lin, D.: Temporal action detection with structured segment networks. In: ICCV, October 2017
Acknowledgement
This work was supported partly by National Key R&D Program of China Grant 2017YFA0700800, National Natural Science Foundation of China Grants 61629301 and 61773312, Young Elite Scientists Sponsorship Program by CAST Grant 2018QNRC001.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 IFIP International Federation for Information Processing
About this paper

Cite this paper
Kang, Z., Wang, L., Liu, Z., Zhang, Q., Zheng, N. (2019). Extracting Action Sensitive Features to Facilitate Weakly-Supervised Action Localization. In: MacIntyre, J., Maglogiannis, I., Iliadis, L., Pimenidis, E. (eds) Artificial Intelligence Applications and Innovations. AIAI 2019. IFIP Advances in Information and Communication Technology, vol 559. Springer, Cham. https://doi.org/10.1007/978-3-030-19823-7_15
Download citation
DOI: https://doi.org/10.1007/978-3-030-19823-7_15
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-19822-0
Online ISBN: 978-3-030-19823-7
eBook Packages: Computer ScienceComputer Science (R0)