
Abstract
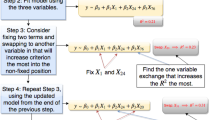
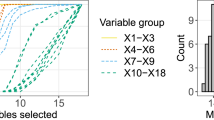
In recent years, statistical analyses, algorithms, and modeling have been constrained due to computational complexity. Further, the added complexity of relationships among response and explanatory variables, such as higher-order interaction effects, makes identifying predictors using standard statistical techniques difficult. These difficulties are only exacerbated in the case of small sample sizes in some studies. Recent analyses have targeted the identification of interaction effects in big data, but the development of methods to identify higher-order interaction effects has been limited by computational concerns. One recently studied method is the feasible solutions algorithm (FSA), a fast, flexible method that aims to find a set of statistically optimal models via a stochastic search algorithm. Although FSA has shown promise, its current limits include that the user must choose the number of times to run the algorithm. Here, we provide statistical guidance for this number of iterations by deriving a lower bound on the probability of obtaining the statistically optimal model in a number of iterations of FSA. For example, when considering a two-way interaction model, if you would like the probability of obtaining the statistically optimal solution to be at least 80%, then you would need to choose the number of random starts of FSA to be 40% of the number of possible explanatory variables in your data set. The performance of this bound is then tested on both simulated and real data. This work allows FSA users to make statistically informed choices about FSA that can improve data analysis techniques.
Electronic Supplementary Material The online version of this chapter (https://doi.org/10.1007/978-3-030-11431-2_5) contains supplementary material, which is available to authorized users.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Friedman, J., Hastie, T., Tibshirani, R.: glmnet: Lasso and elastic-net regularized generalized linear models. R package version 1(4) (2009)
Gemperline, P.J.: Computation of the range of feasible solutions in self-modeling curve resolution algorithms. Anal. Chem. 71(23), 5398–5404 (1999)
Goudey, B., Abedini, M., Hopper, J.L., Inouye, M., Makalic, E., Schmidt, D.F., Wagner, J., Zhou, Z., Zobel, J., Reumann, M.: High performance computing enabling exhaustive analysis of higher order single nucleotide polymorphism interaction in genome wide association studies. Health Inf. Sci. Syst. 3(1), 1 (2015)
Hawkins, D.M.: The feasible set algorithm for least median of squares regression. Comput. Stat. Data Anal. 16(1), 81–101 (1993)
Hawkins, D.M.: A feasible solution algorithm for the minimum volume ellipsoid estimator in multivariate data. Comput. Stat. 8, 95–95 (1993)
Hawkins, D.M.: The feasible solution algorithm for least trimmed squares regression. Comput. Stat. Data Anal. 17(2), 185–196 (1994)
Hawkins, D.M.: The feasible solution algorithm for the minimum covariance determinant estimator in multivariate data. Comput. Stat. Data Anal. 17(2), 197–210 (1994)
Hawkins, D.M., Olive, D.J.: Improved feasible solution algorithms for high breakdown estimation. Comput. Stat. Data Anal. 30(1), 1–11 (1999)
Lambert, J., Gong, L., Elliot, C.F., Thompson, K., Stromberg, A.: rFSA: an R package for finding best subsets and interactions. R J. 10(2), 295–308 (2018)
Lumley, T., Miller, A.: Leaps: regression subset selection. R package version 2 (2004)
Miller, A.J.: Selection of subsets of regression variables. J. R. Stat. Soc. Ser. A Gen. 147(3), 389–425 (1984)
Moore, J.H., Williams, S.M.: Epistasis and its implications for personal genetics. Am. J. Hum. Genet. 85(3), 309–320 (2009)
Zhang, W., Korstanje, R., Thaisz, Staedtler, F., Harttman, N., Xu, L., Feng, M., Yanas, L., Yang, H., Valdar, W., et al.: Genome-wide association mapping of quantitative traits in outbred mice. G3: Genes Genomes Genetics 2(2), 167–174 (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Janse, S.A., Thompson, K.L. (2019). Properties of the Number of Iterations of a Feasible Solutions Algorithm. In: Diawara, N. (eds) Modern Statistical Methods for Spatial and Multivariate Data. STEAM-H: Science, Technology, Engineering, Agriculture, Mathematics & Health. Springer, Cham. https://doi.org/10.1007/978-3-030-11431-2_5
Download citation
DOI: https://doi.org/10.1007/978-3-030-11431-2_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-11430-5
Online ISBN: 978-3-030-11431-2
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)