
Abstract
We present a system that uses convolutional neural networks (CNNs) to detect wrist fractures (distal radius fractures) in posterioanterior and lateral radiographs. The proposed system uses random forest regression voting constrained local model to automatically segment the radius. The resulting automatic annotation is used to register the object across the dataset and crop patches. A CNN is trained on the registered patches for each view separately. Our automatic system outperformed existing systems with a performance of 96% (area under receiver operating characteristic curve) on cross-validation experiments on a dataset of 1010 patients, half of them with fractures.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
- Medical image analysis with deep learning
- X-ray fracture detection
- Wrist fracture detection
- Computer-aided diagnosis
1 Introduction
Wrist fractures are the commonest type of fractures seen in emergency departments (EDs), They are estimated to be 18% of the fractures seen in adults [1, 2] and of 25% of fractures seen in children [2]. They are usually identified in EDs by doctors examining lateral (LAT) and posterioanterior (PA) radiographs. Yet wrist fractures are one of the most commonly-missed in ED-examined radiographs [3, 4]. Systems that can identify suspicious wrist areas and notify ED staff could reduce the number of misdiagnoses.
In this paper we describe a fully-automated system for detecting radius fractures in PA and LAT radiographs. For each view, a global search [5] is performed for finding the approximate position of the radius. The detailed outline of the bone is then located using a random forest regression voting constrained local model (RFCLM) [6]. Convolutional neural networks (CNNs) are trained on cropped patches containing the region of interest on the task of detecting fractures. The decisions from both views are averaged for better performance. This paper is the first to show an automatic system for identifying fractures from PA and LAT view radiographs of the wrist by using convolutional neural networks, outperforming previously-published works.
2 Previous Work
Early work on fracture detection used non-visual techniques: analysing mechanical vibration [7], analysing acoustic waves travelling along the bone [8], or by measuring electrical conductivity [9]. The first published work on detecting fractures in radiographs was that in [10] where an algorithm is developed to measure the femur neckshaft angle and use it to determine whether the femur is fractured. There is a body of literature on radiographic fracture detection on a variety of anatomical regions, including arm fractures [11], femur fractures [10, 12,13,14,15], and vertebral endplates [16]. Cao et al. [17] worked on fractures in a range of different anatomical regions using stacked random forests to fuse different feature representations (Schmid texture feature, Gabor texture feature, and forward contextual-intensity). They achieved a sensitivity of 81% and precision of 25%. Work on wrist fracture detection from radiographs is still limited. The earliest works [13, 14] used active shape models and active appearance models [18] to locate the approximate contour of the radius and trained support vector machine (SVM) on extracted texture features (Gabor, Markov random field, and gradient intensity). They worked on a small dataset with only 23 fractured examples in their test set and achieved encouraging performance. In previous work [19, 20] we used RFCLMs [21] to segment the radius in PA and LAT views and trained random forest (RF) classifiers on statistical shape parameters and eigen-mode texture features [18]. The fully automated system achieved a performance of 91.4% (area under receiver operating characteristic curve, AUC) on a dataset of 787 radiographs (378 of which were fractured) in cross-validation experiments and was the first to combine the both views. Instead of hand-crafting features Kim et al. [22] re-trained the top layer (i.e. classifier) of inception v3 network [23] to detect fractures in wrist LAT views from features previously-learned from non-radiological images (ImageNet [24]). This was the first work to use deep learning in the task of detecting wrist fractures. The system was tested on 100 images (half of which fractured) and reported an AUC of 95.4%. However, they excluded images where lateral projection was inconclusive for the presence or absence of fracture which would bias the results favourably but contradict the goal of developing such systems (i.e. helping clinicians with difficult usually-missed fractures). Olczak et al. [25] re-trained five common deep networks from Caffe library [26] on dataset of 256,000 wrist, hand, and ankle radiographs, of which 56% of the images contained fractures. The dataset was divided into (70% training, 20% validation, and 10% testing) and used to train the networks for the tasks of detecting fractures, determining which exam view, body part, and laterality (left or right). Labels were extracted by automatically mining reports and DICOMs. The images were rescaled to \(256\,{\times }\,256\) and then cropped into a subsection of the original image with the network’s input size. The pre-processing causes image distortion but they justified that as the nature of tasks does not need non-distorted images. The networks were pre-trained on the ImageNet dataset [24] and then their top layers (i.e. classifier) were replaced with fully connected layers suitable for each task. The best performing network (VGG 16 [27]) achieved a fracture detection accuracy of 83% without reporting false positive rate. The model deals with various views independently but it does not combine them for a decision. Another related work [28] used a very deep CNN-based model (169 trainable layers) for abnormality detection from raw radiographs. Images are labelled as normal or abnormal, where abnormal does not always mean “fractured” - it sometimes means there is metalwork present. Their dataset contains metal hardware in both categories (normal and abnormal) and also contains different age groups. This makes the definition of abnormality is rather unclear as what is considered abnormal for a certain group can be seen as normal for another age group and vice versa.
3 Background
3.1 Shape Modeling and Matching
Statistical shape models (SSMs) [18] are widely used for studying the contours of bones. Shape is the quality left after all differences due to location, orientation, and scale are omitted in a population of same-class objects. SSMs assume that each shape instance is a deformed version of the mean shape describing the object class. The training data is used to identify the mean shape and its possible deformations. The contour of an object is described by a set of model points \((x_i\), \(y_i)\) packed in a 2n-D vector \(\mathbf {x}=(x_{1},\ldots ,x_{n},y_{1},\ldots ,y_{n})^T\). An SSM is a linear model of shape variations of the object across the training dataset built by applying principal component analysis (PCA) to aligned shapes and fitting a Gaussian distribution in the reduced space. A shape instance \(\mathbf {x}\) is represented as:
where \(\bar{\mathbf {x}}\) is the mean shape, \(\mathbf {P}\) is the set of the orthogonal eigenvectors corresponding to the t highest eigenvalues of the covariance matrix of the training data, \(\mathbf {b}\) is the vector of shape parameters and \(T(.:\theta )\) applies a similarity transformation with parameters \(\theta \) between the common reference frame and the image frame. The number of the used eigenvectors t is chosen to represent most of the total variation (i.e. 95–\(98\%\)).
One of the most effective algorithms for locating the outline of bones in radiographs is RFCLM [6]. This uses a collection of RFs to predict the most likely location of each point based on nearby image patches. A shape model is then used to constrain the points and encode the result.
3.2 Convolutional Neural Network
CNNs are a class of deep feed-forward artificial neural networks for processing data that has a known grid-like topology. They emerged from the study of the brain’s visual cortex and benefited from the recent increase in the computational power and the amount of available training data.
A typical CNN (Fig. 1) stacks few convolutional layers, then followed by a subsampling layer (Pooling layer), then another few convolutional layers, then another pooling layer, and so on. At the top of the stack fully-connected layers are added outputing a prediction (e.g. estimated class probabilities). This layer-wise fashion allows CNNs to combine low-level features to form higher-level features (Fig. 2), learning features and eliminating the need for hand crafted feature extractors. In addition, the learned features are translation invariant, incorporating the two-dimensional (2D) spatial structure of images which contributed to CNNs achieving state-of-the-art results in image-related tasks.

A convolutional neural network-based classifier applied to a single-channel input image. Every convolutional layer (Conv) transforms its input to a three-dimensional output volume of neuron activations. The pooling layer (Pool) downsamples the volume spatially, independently in each feature map of its input volume. At the end fully-connected layers (FC) output a prediction.
A convolutional layer has k filters (or kernels) of size \(r\,{\times }\,r\,{\times }\,c\) (receptive field size) where r is smaller than the input width/height, and c is the same as the input depth. Every filter convolves with the input volume in sliding-window fashion to produce feature maps (Fig. 2). Each convolution operation is followed by a nonlinear activation, typically a rectified linear unit (ReLU) which sets any negative values to zero. A feature map can be subsampled by taking the mean or maximum value over \(p\,{\times }\,p\) contiguous regions to produce translation invariant features (Pooling). The value of p usually ranges between 2–5 depending on how large the input is. This reduction in spatial size leads to fewer parameters, less computation, and controls overfitting.
The local connections, tied weights, and pooling result in CNNs have fewer trainable parameters than fully connected networks with the same number of hidden units. The parameters are learned by back propagation with gradient-based optimization to reduce a cost function.

In the convolutional neural network, k neurons receive input from only a restricted subarea (receptive field) of the previous layer output. Convolving the filters with the whole input volume produces k feature maps.
4 Methods
4.1 Patch Preparation
Because most parts of a radiograph are either background or irrelevant to the task, we chose to train CNNs on cropped patches rather than raw images. The steps of the automated system are shown in Fig. 3. Following our previous work [20] we used a global search with a random forest regression voting (RFRV) technique to find the approximate radius location (red dots in Fig. 3) followed by a local search performed by a sequence of RFCLM models with an increasing resolution to find its contour. The automatic point annotation gives information on the position, orientation and scale of the distal radius accurately. This is used to transfer the bone to a standardized coordinate frame before cropping a patch of size (\(n_i\,{\times }\,n_i\) pixels) containing the bone. We used the resulting patches to train and test a CNN. This process is completely automatic. Figure 4 shows examples of radiographs and extracted patches.

Fully automated system for detecting wrist fractures. (Color figure online)

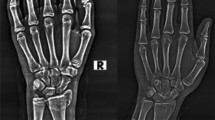
Example of pairs of radiographs for four subjects with (a) a normal radius, (b)–(d) fracture radiuses. The first and third rows show the posterioanterior and lateral views respectively. The corresponding cropped patches appear below each view.
4.2 Network Architecture
We trained a CNN for each view. The two CNNs were classical stacks of CP layers (CP refers to one ReLU-activated convolutional layer followed by a pooling layer) with two consecutive fully-connected (FC) layers. No padding was used. Weights were initialised with the Xavier uniform kernel initializer [29] and biases initialised to zeros. The loss function was binary cross entropy optimised with Adam [30] (default parameter values used). An input patch size of \(121\,{\times }\,121\), and of \(151\,{\times }\,151\) were used for PA, and LAT networks respectively. Architecture details are summarised in Table 1. In our experiments we gradually increased the number of CP layers and chose the network with the best performance. Figure 5 shows an example network with three CP layers followed by two FC layers.

Fully automated system for detecting wrist fractures.
5 Experiments and Results
5.1 Data
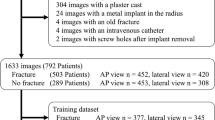
We collected a wrist dataset containing 1010 pairs of wrist radiographs (PA and LAT) for 1010 adult patients, 505 of whom had fractures (Fig. 4). Images for 787 patients, 378 of whom had fractures, were gathered from two local EDs while the rest were gathered from the MURA dataset [28] with fractures as abnormality. Fractured examples do not contain any plaster casts or metalware to make sure the network learns features for detecting fracture not hardware.
5.2 Fracture Detection
We carried out 5-fold cross validation experiments. During each fold 802 radiographs were used as training set, 102 as validation set, and 102 as testing set. The validation and testing sets were then swapped so that all the data were tested exactly once. Every time a network was trained from scratch for 20 epochs with batch size\(\,{=}\,32\) and the model with the lowest validation loss was selected. Training data was randomly shuffled at the start of each epoch to produce different batches each time. We found the architectures with three CP layers, and with four CP layers performed the best for the LAT view, and PA view respectively. Having trained the two CNNs, one for each view, their outputs are combined by averaging (Fig. 6). Figure 7 shows the average performance and learning curves. We achieved an average performance of AUC\(\,{=}\,95\)% for PA view, 93% for LAT view, and 96% from both views combined.

During testing the outputs for both views are combined by averaging.

Fracture detection. (a) Receiver operating characteristic (ROC) curve for posterioanterior view. (b) ROC curve for lateral view. (c) ROC curve for both views combined. (d) Example of learning curves for a model.
Kim et al. [22] used features originally learned to classify non-radiological images [24] and used them to detect fractures in LAT views and reported an AUC of 95.4%. Unlike their work we have not excluded images where lateral projection was inconclusive for the presence or absence of fracture which would bias the results favourably. In our case, we performed 5-fold cross-validation and reported an overall AUC of 96%. For the sake of comparison with our previous RF-based technique in [20] we repeated all experiments in [20] on the current dataset with the same fold divisions and found an AUC of 92% from two views combined, 89% and 91% for PA view, and LAT view respectively (Table 2 and Fig. 8). The CNN-based technique clearly outperforms the RF-based one.

Comparison between receiver operating characteristics curves for the proposed convolutional neural network-based technique and the relevant random forest-based work in [20] on: (a) posteroanterior view, (b) lateral view, and (c) both views combined for the same dataset in terms of area under the curve ± standard deviation.
5.3 Conclusions
We presented a system for automatic wrist fracture detection from plain PA and LAT X-rays. The CNN is trained from scratch on radiographic patches cropped around the joint after automatic segmentation and registration. This directed preprocessing ensures meaningful learning from only the targeted region in scale which in turn reduces the noise a CNN is exposed to compared to when trained on full images containing parts that are not relevant to the task. Radiographs, unlike photos, have predictable contents that allow model-based techniques to work well and therefore they can provide CNNs with an input that dispense with the need to: (1) perform any data augmentation and (2) unnecessarily complicate the deep architecture and its learning process. Our work was the first to train CNNs from scratch on the task of detecting wrist fractures and to combine the two views for a decision. The experiments showed that combining the results from both views leads to an improvement in overall classification performance, with an AUC of 96% compared to 95% for PA view and 93% for LAT view.
References
Court-Brown, C., Caesar, B.: Epidemiology of adult fractures: a review. Injury 37(8), 691–697 (2006). https://doi.org/10.1016/j.injury.2006.04.130
Goldfarb, C., Yin, Y., Gilula, L., Fisher, A., Boyer, M.: Wrist fractures: what the clinician wants to know. Radiology 219(1), 11–28 (2001). https://doi.org/10.1148/radiology.219.1.r01ap1311
Guly, H.: Injuries initially misdiagnosed as sprained wrist (beware the sprained wrist). Emerg. Med. J. 19(1), 41–42 (2002). https://doi.org/10.1136/emj.19.1.41
Petinaux, B., Bhat, R., Boniface, K., Aristizabal, J.: Accuracy of radiographic readings in the emergency department. Am. J. Emerg. Med. 29(1), 18–25 (2011). https://doi.org/10.1016/j.ajem.2009.07.011
Lindner, C., Thiagarajah, S., Wilkinson, J., Wallis, G., Cootes, T., The arcOGEN Consortium: Fully automatic segmentation of the proximal femur using random forest regression voting. IEEE Trans. Med. Imaging 32(8), 1462–1472 (2013). https://doi.org/10.1109/TMI.2013.2258030
Cootes, T.F., Ionita, M.C., Lindner, C., Sauer, P.: Robust and accurate shape model fitting using random forest regression voting. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012. LNCS, vol. 7578, pp. 278–291. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33786-4_21
Kaufman, J., et al.: A neural network approach for bone fracture healing assessment. IEEE Eng. Med. Biol. Mag. 9(3), 23–30 (1990). https://doi.org/10.1109/51.59209
Ryder, D., King, S., Oliff, C., Davies, E.: A possible method of monitoring bone fracture and bone characteristics using a noninvasive acoustic technique. In: Proceedings of International Conference on Acoustic Sensing and Imaging, pp. 159–163. IEEE (1993)
Singh, V., Chauhan, S.: Early detection of fracture healing of a long bone for better mass health care. In: Proceedings of 20th International Conference of the Engineering in Medicine and Biology Society – EMBC 1998, vol. 6, pp. 2911–2912. IEEE (1998). https://doi.org/10.1109/IEMBS.1998.746096
Tian, T.P., Chen, Y., Leow, W.K., Hsu, W., Howe, T.S., Png, M.A.: Computing neck-shaft angle of femur for X-ray fracture detection. In: Petkov, N., Westenberg, M.A. (eds.) CAIP 2003. LNCS, vol. 2756, pp. 82–89. Springer, Heidelberg (2003). https://doi.org/10.1007/978-3-540-45179-2_11
Jia, Y., Jiang, Y.: Active contour model with shape constraints for bone fracture detection. In: Proceedings of 3rd International Conference on Computer Graphics, Imaging and Visualisation – CGIV 2006, pp. 90–95. IEEE (2006). https://doi.org/10.1109/CGIV.2006.16
Yap, D.H., Chen, Y., Leow, W., Howe, T., Png, M.: Detecting femur fractures by texture analysis of trabeculae. In: Proceedings of 17th International Conference on Pattern Recognition – ICPR 2004, vol. 3, pp. 730–733. IEEE (2004). https://doi.org/10.1109/ICPR.2004.1334632
Lim, S., Xing, Y., Chen, Y., Leow, W., Howe, T., Png, M.: Detection of femur and radius fractures in X-ray images. In: Proceedings of 2nd International Conference on Advances in Medical Signal and Information Processing, pp. 249–256 (2004)
Lum, V., Leow, W., Chen, Y., Howe, T., Png, M.: Combining classifiers for bone fracture detection in X-ray images. In: Proceedings of International Conference on Image Processing – ICIP 2005, p. I-1149. IEEE (2005). https://doi.org/10.1109/ICIP.2005.1529959
Bayram, F., Çakiroğlu, M.: DIFFRACT: DIaphyseal Femur FRActure Classifier SysTem. Biocybern. Biomed. Eng. 36(1), 157–171 (2016). https://doi.org/10.1016/j.bbe.2015.10.003
Roberts, M., Oh, T., Pacheco, E., Mohankumar, R., Cootes, T., Adams, J.: Semi-automatic determination of detailed vertebral shape from lumbar radiographs using active appearance models. Osteoporos. Int. 23(2), 655–664 (2012). https://doi.org/10.1007/s00198-011-1604-3
Cao, Y., Wang, H., Moradi, M., Prasanna, P., Syeda-Mahmood, T.: Fracture detection in X-ray images through stacked random forests feature fusion. In: Proceedings of 12th International Symposium on Biomedical Imaging – ISBI 2015, pp. 801–805. IEEE (2015). https://doi.org/10.1109/ISBI.2015.7163993
Cootes, T., Edwards, G., Taylor, C.: Active appearance models. IEEE Trans. Pattern Anal. Mach. Intell. 23(6), 681–685 (2001). https://doi.org/10.1109/34.927467
Ebsim, R., Naqvi, J., Cootes, T.: Detection of wrist fractures in X-ray images. In: Shekhar, R., et al. (eds.) CLIP 2016. LNCS, vol. 9958, pp. 1–8. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46472-5_1
Ebsim, R., Naqvi, J., Cootes, T.: Fully automatic detection of distal radius fractures from posteroanterior and lateral radiographs. In: Cardoso, M.J., et al. (eds.) CARE/CLIP - 2017. LNCS, vol. 10550, pp. 91–98. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-67543-5_8
Lindner, C., Bromiley, P., Ionita, M., Cootes, T.: Robust and accurate shape model matching using random forest regression-voting. IEEE Trans. Pattern Anal. Mach. Intell. 37(9), 1862–1874 (2015). https://doi.org/10.1109/TPAMI.2014.2382106
Kim, D., MacKinnon, T.: Artificial intelligence in fracture detection: transfer learning from deep convolutional neural networks. Clin. Radiol. 73(5), 439–445 (2018). https://doi.org/10.1016/j.crad.2017.11.015
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the inception architecture for computer vision. In: Proceedings of 29th IEEE Conference on Computer Vision and Pattern Recognition – CVPR 2016, pp. 2818–2826. IEEE (2016). https://doi.org/10.1109/CVPR.2016.308
Russakovsky, O., et al.: ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 115(3), 211–252 (2015). https://doi.org/10.1007/s11263-015-0816-y
Olczak, J., et al.: Artificial intelligence for analyzing orthopedic trauma radiographs: deep learning algorithms—are they on par with humans for diagnosing fractures? Acta Orthop. 88(6), 581–586 (2017). https://doi.org/10.1080/17453674.2017.1344459
Jia, Y., et al.: Caffe: convolutional architecture for fast feature embedding. In: Proceedings of 22nd International Conference on Multimedia – MM 2014, pp. 675–678. ACM (2014). https://doi.org/10.1145/2647868.2654889
Zhong, S., Li, K., Feng, R.: Deep convolutional hamming ranking network for large scale image retrieval. In: Proceedings of 11th World Congress on Intelligent Control and Automation – WCICA 2014, pp. 1018–1023. IEEE (2014). https://doi.org/10.1109/WCICA.2014.7052856
Rajpurkar, P., et al.: MURA large dataset for abnormality detection in musculoskeletal radiographs. arXiv:1712.06957v1 (2017)
Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks. In: Teh, Y., Titterington, M. (eds.) Proceedings of 13th International Conference on Artificial Intelligence and Statistics – AISTATS 2010, PMLR, vol. 9, pp. 249–256. PMLR (2010)
Kingma, D., Ba, J.: Adam: a method for stochastic optimization. arXiv:1412.6980 (2014)
Acknowledgements
The research leading to these results has received funding from Libyan Ministry of Higher Education and Research. The authors would like to thank Dr Jonathan Harris, Dr Matthew Davenport, and Dr Martin Smith for their help setting up the project.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Ebsim, R., Naqvi, J., Cootes, T.F. (2019). Automatic Detection of Wrist Fractures From Posteroanterior and Lateral Radiographs: A Deep Learning-Based Approach. In: Vrtovec, T., Yao, J., Zheng, G., Pozo, J. (eds) Computational Methods and Clinical Applications in Musculoskeletal Imaging. MSKI 2018. Lecture Notes in Computer Science(), vol 11404. Springer, Cham. https://doi.org/10.1007/978-3-030-11166-3_10
Download citation
DOI: https://doi.org/10.1007/978-3-030-11166-3_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-11165-6
Online ISBN: 978-3-030-11166-3
eBook Packages: Computer ScienceComputer Science (R0)