
Abstract
The main objective of this chapter is to offer to practitioners, researchers and all interested parties a brief categorized catalog of existing lightweight symmetric primitives with their main cryptographic features, ultimate hardware performance, and existing security analysis, so they can easily compare the ciphers or choose some of them according to their needs. Certain security evaluation issues have been addressed as well. In particular, the reason behind why modern lightweight block cipher designs have in the last decade overwhelmingly dominated stream cipher design is analyzed in terms of security against tradeoff attacks. It turns out that it is possible to design stream ciphers having much smaller internal states.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


1 Introduction
Lightweight cryptography aims to deploy cryptographic algorithms in resource-constrained devices such as embedded systems, RFID devices and sensor networks. The cryptographic community has done a significant amount of work in this area, including design, implementation and cryptanalysis of new lightweight cryptographic algorithms, together with efficient implementation of conventional cryptography algorithms in constrained environments (see the Lightweight Cryptography Lounge,Footnote 1 [89, 260, 391]). Most recent cryptographic competitions such as NIST’s SHA-3 Cryptographic Hash Algorithm CompetitionFootnote 2 and eSTREAM projectFootnote 3 (with the Profile 2) had requirements that support implementations for highly constrained devices. Additionally, NIST currently is working on a special callFootnote 4 to create a portfolio of lightweight algorithms through an open standardization process.
The lightweightness of a given cryptographic algorithm can be obtained in two ways, by optimized implementations with respect to different constraints or by dedicated designs which use smaller key sizes, smaller internal states, smaller building blocks, simpler rounds, simpler key schedules, etc. There are several relevant metrics for assessing lightweight algorithms, such as power and energy consumption, latency, throughput and resource requirements [404]. Power and energy consumption are important for devices that are battery-oriented or energy harvesting. Latency is the time taken to perform a given task, and is important for applications where fast response time is necessary (e.g., Advanced Driver Assistance Systems), while throughput can be defined as the rate at which the plaintext is processed per time unit, and is measured in Bps.
Resource requirements are expressed differently in hardware and software implementations. In the hardware case, they are described as gate area, expressed by logic blocks for FPGAs or by Gate Equivalents (GEs) for ASIC implementations. However, these measures highly depend on the particular technology, so it is not possible to do a fair and relevant comparison of the lightweight algorithm implementations exactly across different technologies. In the software case, resource requirements are described as number of registers, RAM and ROM consumption in bytes. ROM consumption corresponds in fact with the code size.
Hardware implementations are suitable for highly constrained devices. For example, on the low end, low-cost passive RFID tags may have a total of 1000–10,000 gates, with only 200–2000 budgeted for security purposes [309]. Software implementations are suitable for less constrained devices, and they are optimized for throughput and energy consumption.
Some design choices related to dedicated lightweight cryptographic algorithms have influences on the security margins. For example, smaller key sizes such as 80 bits or 96 bits are in conflict with the current NIST minimum key size requirement of 112 bits. Smaller block and output sizes in some algorithms may lead to plaintext recovery or codebook attacks. Simpler key schedules may enable different attacks using related keys, weak keys, etc. Smaller internal state (IS) and digest sizes in hash functions may lead to collision attacks. Simpler rounds sometimes means that more iterations are required to achieve security.
The main objective of this chapter is to offer to practitioners, researchers and all interested parties a short categorized catalog of existing symmetric lightweight primitives with their main features, some details about known software and hardware performance, and existing security analysis, to enable selection according to specific needs. These cryptographic primitives can be categorized into five areas: block and stream ciphers, hash functions, message authentication codes, and authenticated encryption schemes. As a consequence of the simplicity which provides lightweightness, the security evaluation of lightweight stream ciphers appears as an issue of top importance, and so a number of illustrative elements relevant for cryptanalysis of lightweight encryption techniques have been pointed out as well.
It can easily be observed that (see Sect. 2.2) almost all of the recently designed lightweight ciphers are block ciphers. The requirement for unnecessarily large internal states results in extra hardware area cost which definitely hinders designing ultralightweight stream ciphers. We analyze the arguments behind this criterion and propose to loosen it by justifying the security analysis in Sect. 2.3. We believe this adoption will promote the design and even the analysis of lightweight stream ciphers.
2 Catalog of Lightweight Cryptographic Primitives
The catalog of lightweight cryptographic primitives is divided in five categories: block and stream ciphers, hash functions, message authentication codes, and authenticated encryption schemes.
2.1 Block Ciphers
Block ciphers encrypt one block of plaintext bits at a time, to a block of ciphertext bits, through multiple rounds, and using a secret key. Each round is a sequence of several simple transformations, which provide confusion and diffusion [522]. In each round, a round key is used, which is derived from the secret key using a key schedule algorithm. According to the algorithm structure, block ciphers can be divided into several types:
-
Substitution Permutation Network (SPN)—each round consists of substitution (S-) and permutation (P-) boxes. Usually, S-boxes are non-linear transformations and provide confusion, while P-boxes are linear and provide diffusion.
-
Feistel Network (Feistel)—divides the input block into two halves, L i and R i, and in each round, the output block is (L i+1, R i+1) = (R i, L i ⊕ F(R i, K i+1)), where F is the round-function (introduced by H. Feistel [209]).
-
Add-Rotate-XOR (ARX)—only three operations are used: modular addition, rotation and XOR.
-
Generalized Feistel Network (GFN)—divides the input block into n parts, and each round consists of a round-function layer and a block-permutation layer, which usually is a cyclic shift. If the round-function is applied only to one part, we speak about Type-1, and if it is applied on the n∕2 parts, we speak about Type-2 GFN. If there is an additional linear layer between the two layers, we speak about Extended GFN [78].
-
LFSR-based—in the round function they use one or more Linear Feedback Shift Registers (LFSRs) in combination with non-linear functions.
-
LS-design—each round combines linear diffusion L-boxes with non-linear bitslice S-boxes, and they are aimed at efficient masked implementations against side-channel analysis [247].
-
XLS-design—a variation of the LS-design, that uses the additional ShiftColumns operation, and Super S-boxes [306].
There are also tweakable block ciphers, which in addition to the key and the message have a third input named tweak, and they must be secure even if the attacker is able to control the tweak input. Each tweakable block cipher can be seen as a family of permutations in which each (key, tweak) pair selects one permutation.
The standard block cipher approach can be made lightweight by using smaller key sizes (e.g., 80 or 96 bits), smaller block sizes (e.g., 64 bits), smaller or special building blocks (e.g., 4-bit S-boxes, no S-boxes at all, or recursive diffusion layers), simpler key schedules (e.g., selecting a key schedule where bits from the master key are selected as round keys), smaller hardware implementation, involutive encryption, etc. AES-128 belongs in this group also, because there are ASIC implementations of it with an area of just 2400 GE[426] on 0.18 μm technology, but it cannot be applied in every scenario. In Table 2.1, we give a summary of the known lightweight block ciphers, sorted in alphabetical order, with their type, key and block size in bits, number of rounds, used technology and number of GEs if known, and we give the best known attacks in Table 2.2. KASUMI used in UMTS, GSM, and GPRS mobile communications systems, 3-Way and MANTIS are considered insecure. Additionally, CLEFIA and PRESENT are part of the ISO-29192-2 standard, while HIGHT, MISTY1 and AES are part of the ISO/IEC 18033-3:2010 standard.
For fair and consistent evaluation and comparison of software implementations of lightweight block and stream ciphers, one can use a free and open-source benchmarking framework FELICS (Fair Evaluation of Lightweight Cryptographic Systems) [182]. Currently, the assessment can be done on three widely used microcontrollers: 8-bit AVR, 16-bit MSP and 32-bit ARM, and extracted metrics are the execution time, RAM consumption and binary code size, from which one single value “Figure Of Merit” (FOM) is calculated. Table 2.3 presents some details about software performance of some lightweight block ciphers with the current best FELICS results for encryption of 128 bytes of data in CBC mode (scenario 1 in [182]), sorted according to the FoM measure, where the lowest result is the best.
2.2 Stream Ciphers
Stream ciphers encrypt small portions of data (one or several bits) at a time. By using a secret key, they generate a pseudorandom keystream, which is then combined with the plaintext bits to produce the ciphertext bits. Very often the combining function is bitwise XORing, and in that case we speak about binary additive stream ciphers. The basic security rule for stream ciphers is not to encrypt two different messages with the same pair of key/IV. So, stream ciphers usually have a large keystream period, and a different key and/or IV should be used after the period elapses. Each stream cipher usually has an initialization phase with some number of rounds (or clock-cycles), followed by an encryption phase. A fast initialization phase makes a given cipher suitable for encrypting many short messages, while when several large messages need to be encrypted, stream ciphers with a fast encryption phase are more appropriate.
The standard stream cipher approach can be made lightweight by using: smaller key sizes (e.g., 80 bits), smaller IV/nonce sizes (e.g., 64 bits), a smaller internal state (e.g., 80 or 100 bits), simpler key schedules, a smaller hardware implementation, etc. Table 2.4 lists the known lightweight stream ciphers in alphabetical order, with their main parameters and details about hardware implementation, and Table 2.5 provides the best known attacks. One can notice that all eSTREAM Profile 2 candidates that were not selected as finalists are not in the table. Also, according to the hardware implementations, ZUC, ChaCha and Salsa20 cannot really be considered as lightweight. While Lizard uses 120 bit keys, its designers claim only 80-bit security against key-recovery attacks. A5/1 used in GSM protocol, E0 used in Bluetooth, A2U2, and Sprout are considered insecure.
Rabbit | [98] | 128 | 64 | 513 | 128 | 271 | 4+4 | 0.18 | 3800 |
RAKAPOSHI | [148] | 128 | 192 | 320 | 1 | 264 | 448 | − | − |
Salsa20 | [80] | 256 | 64 | 512 | 512 | 273 | 20 | 0.18 | 9970 [270] |
SNOW 3G | [204] | 128 | 128 | 576 | 32 | 32 | − | − | |
Sprout | [27] | 80 | 70 | 89 | 1 | 240 | 320 | 0.18 | 813 |
Trivium | [127] | 80 | 80 | 288 | 1 | 264 | 1152 | 0.35 | 749 [409] |
Quavium | [555] | 80 | 80 | 288 | 1 | 264 | 1152 | − | 3496 estimated |
WG-8 | [207] | 80 | 80 | 160 | 1 | 2160 | 40 | 0.065 | 1786 [587] |
ZUC (v 1.6) | [205] | 128 | 128 | 560 | 32 | 32 | 0.065 | 12,500 [378] |
Additionally, Enocoro and Trivium are part of the ISO/IEC 29192-3:2012 standard, and Rabbit is part of ISO/IEC 18033-4:2011. SNOW 3G was chosen for the 3GPP encryption algorithms UEA2 and UIA2, while ZUC was chosen for the 3GPP algorithms 128-EEA3 and 128-EIA3. The profile 2 eSTREAM portfolio includes Grain v1, MICKEY 2.0 and Trivium. There is an IETF implementation of the ChaCha20, published in RFC 7539, with 96-bit nonce and maximum message length up to 232 − 1B that can be safely encrypted with the same key/nonce, as a modification.
2.3 Hash Functions
A hash function is any function that maps a variable length input message into a fixed length output. The output is usually called a hashcode, message digest, hash value or hash result. Cryptographic hash functions must be preimage (one-way), second preimage and collision resistant.
Usually the message is first padded and then divided into blocks of fixed length. The most common method is to iterate over a so-called compression function, that takes two fixed size inputs, a message block and a chaining value, and produces the next chaining value. This is known as a Merkle-Damgård (MD) construction. The sponge construction is based on fixed-length unkeyed permutation (P-Sponge) or random function (T-Sponge), that operates on b bits, where b = r + c. b is called the width, r is called the rate (the size of the message block) and the value c the capacity. The capacity determines the security level of the given hash function. There is also a JH-like sponge in which the message block is injected twice.
The main problem of using conventional hash functions in constrained environments is their large internal state. SHA-3 uses a 1600 bit IS, and its most compact hardware implementation needs 5522 GE [471] on 0.13 μm technology. On the other hand, SHA-256 has a smaller IS (256 bit), but one of its smaller hardware implementations uses 10,868 GE [211] on 0.35 μm technology.
Lightweight hash functions can have smaller internal state and digest sizes (for applications where collision resistance is not required), better performance on short messages, small hardware implementations, etc. In some cases, for example tag-based applications, there is a need only for the one-way property. Also, most tag protocols require hashing of small messages, usually much less than 256 bits.
Tables 2.6 and 2.7 list the cryptographic and implementation properties of the known lightweight hash functions. ARMADILLO is considered insecure. Lesamnta-LW, PHOTON, and SPONGENT are part of the ISO/IEC 29192-5:2016 standard.
2.4 Message Authentication Codes
A message authentication code (MAC) protects the integrity and authenticity of a given message, by generating a tag from the message and a secret key. MAC schemes can be constructed from block ciphers (e.g., CBC-MAC (part of the ISO/IEC 9797-1:1999 standard) or OCB-MAC [504]), from cryptographic hash functions (e.g., HMAC (RFC 2104)), etc. Three lightweight security architectures have been proposed for wireless sensor networks: TinySec [316], MiniSec [382] and SenSec[370]. TinySec and MiniSec recommend CBC-MAC and the patented OCB-MAC, while SenSec recommends XCBC-MAC, for which there is an existential forgery attack [238], and all suggest the use of 32-bit tags. 32-bit security is not enough—the recommended size is at least 64 bits.
Design choices for lightweight MACs include shorter tag sizes, simpler key schedules, small hardware and/or software implementations, better performance on very short messages, no use of nonces, and generation from lightweight block ciphers and hash functions. Some lightweight MACs are listed in Table 2.8, and the best known attacks against these MACs are provided in Table 2.9.
2.5 Authenticated Encryption Schemes
Authenticated encryption (AE) schemes combine the functions of ciphers and MACs in one primitive, so they provide confidentiality, integrity, and authentication of a given message. Besides the plaintext and the secret key, they usually accept variable length Associated Data (AEAD schemes), a public nonce, and an optional secret nonce. AD is a part of a message that should be authenticated, but not encrypted.
Lightweight authenticated encryption schemes are presented in Table 2.10, and the best known attacks against these schemes are provided in Table 2.11. Sablier and SCREAM/iSCREAM are considered insecure. The hardware implementation is given with encryption/authentication and decryption/verification functionalities.
3 Illustrative Issues in Security Evaluation of Certain Encryption Schemes
As a consequence of the simplicity which makes them lightweight, the security evaluation of lightweight encryption schemes arises as an issue of top importance. However, constraints on chapter space limit our discussion of the security evaluation. Consequently, this section shows only a number of illustrative issues relevant for the cryptanalysis of lightweight encryption techniques. In the first part, a generic approach for security evaluation is discussed, and in the second an advanced dedicated approach is pointed out.
3.1 Reconsidering TMD Tradeoff Attacks for Lightweight Stream Cipher Designs
We can simply divide the tradeoff attacks against ciphers into two groups, key recovery attacks and internal state recovery attacks. The first tradeoff attack against symmetric ciphers was introduced by Hellman [268] to illustrate that the key length of DES was indeed too short. Hellman prepared several tables containing DES keys. In general, the tradeoff curve is TM 2 = N 2 where T is the time complexity and M is the memory complexity. N is the cardinality of the key space. Here, the data complexity D = 1 since only one chosen plaintext is used to define a one way function which produces the (reduction of the) ciphertext of the chosen plaintext for a given key. Then, the tables are prepared during the precomputation phase. In practice, one generally considers the point T = M = N 2∕3 on the curve since the overall complexity also becomes N 2∕3. The precomputation phase costs roughly O(N) encryptions. This is a generic attack which is applicable to any block cipher. Therefore, we can say that the security level diminishes to 2k∕3-bit security during the online phase of the Hellman tradeoff attack where k is the key length of a block cipher. However, one must pay a cost equivalent to exhaustive search to prepare the tables during the precomputation phase.
Stream ciphers also suffer from the same affliction by tradeoff attacks in that their keys can be recovered with an effort of 22k∕3 for each of them during the online phase. Stream ciphers consist of two parts. The initialization part uses an IV and a key to produce a seed value S 0. Then, S 0 is used to produce the keystream sequence through a keystream generator. While a state update function updates the internal states S i, an output function produces the keystream bits (or words) z i. It is possible to define a one way function from the key to the first k bits of the keystream sequence by choosing an IV value and fixing it. This is similar to the case of tradeoff attacks on block ciphers with a chosen plaintext. However, the attack may only be mounted on a decryption mechanism since it may not be possible to choose the IV during the encryption. Then, by preparing the Hellman tables, one can recover a key in 22k∕3 encryptions using 22k∕3 memory. The precomputation is 2k. This is similar to the Hellman attack. Therefore, stream ciphers are prone to tradeoff attacks as with block ciphers in the key recovery case.
The other category of tradeoff attacks is aimed at recovering internal states of stream ciphers, rather than keys. Babbage [47] and Golić [236], independently, introduced another type of tradeoff curve DM = N to recover an internal state. One can pick out the point D = M = N 1∕2 to get an overall complexity of N 1∕2. Then, storing \(\sqrt {N}\) internal states with their outputs (keystream parts with an appropriate length), one can recover a keystream used during encryption/decryption if it is loaded in the table. We need roughly \(\sqrt {N}\) data to ensure a remarkable success rate. So, it is conventionally adopted that \(\sqrt {N}\) should be larger than 2k as a security criterion just to ensure that the internal state recovery attack through tradeoff is slower than the exhaustive search. This simply means that the internal state size should be at least twice as large as the key size. This extremely strict criterion has played a very crucial role in raising extra difficulties in designing lightweight stream ciphers.
Another highly effective tradeoff attack for internal state recovery is the Biryukov-Shamir attack [91]. This simply makes use of Hellman tables. But, instead of recovering just one specific internal state, it is enough to recover only one of D internal states. Then, preparing just one Hellman table is an optimum solution and the table can contain N∕D states. So, the precomputation phase is around O(N∕D) and the tradeoff curve is TM 2 D 2 = N 2 where D is bounded above by \(\sqrt {T}\) since the number of internal states contained in just one table is limited to avoid merging of collisions. We can pick out the point on the curve where time and memory are equal and maximize the data, namely T = M = N 1∕2 and D = N 1∕4. We need N 1∕2 to be larger than 2k if we want the online phase of the attack to be slower than an exhaustive search. This again simply implies that the internal state size should be at least twice as large as the key size.
The condition on the size of the internal states of stream ciphers makes designing ultralightweight stream ciphers too difficult. Indeed, there are several ultralightweight (say less than 1000 GE) block ciphers recently designed, such as PRESENT [101], LED [252], KTANTAN [126], Piccolo [526], and SIMON/SPECK [65], whereas there are almost no modern stream ciphers with hardware area cost less than 1000 GE.
The security margin for state recovery attacks through tradeoff techniques is k bits, whereas it is much less, 2k∕3 bits, for the key recovery attacks, although any information about the key is assumed to be more sensitive than any information about the internal states. One can produce any internal state once the key is recovered. However, recovery of an internal state may reveal only one session of the encryption/decryption with the corresponding IV . Hence, it seems that the more sensitive data are, contradictorily, protected less against tradeoff attacks!
The security level of tradeoff attacks to recover internal states should be the same as the security level of tradeoff attacks to recover keys, just to be fair. So, the online phase of a tradeoff attack should be at least 22k∕3 instead of 2k. Similarly, the precomputation should be not faster than exhaustive search. In this case, D = M = N 1∕2 ≥ 22k∕3 for the Babbage-Golić attack. Then, N should be at least 24k∕3. The same bound is valid for Biryukov-Shamir attack since the smallest overall complexity is attained when T = M = N 1∕2.
The precomputation phase of the Biryukov-Shamir attack is roughly N∕D; which is simply N 3∕4 when D = N 1∕4. So, the precomputation phase is more than 2k. This means that it is slower than an exhaustive search. On the other hand, the precomputation phase of the Babbage-Golić attack is M, and hence if the data is restricted to at most 2k∕3 for each key we have M ≥ 2k and hence the precomputation phase will be slower than an exhaustive search.
It seems it is enough to take the internal state size as at least 4k∕3, not at least 2k, for security against tradeoff attacks. This simply implies that it is possible to design lightweight stream ciphers with much smaller internal states. However, it is an open question how to design stream ciphers with very small internal states. The security is generally based on the largeness of the states.
3.2 Guess-and-Determine Based Cryptanalysis Employing Dedicated TMD-TO
This section presents an illustrative framework for cryptanalysis employing guess-and-determine and time-memory-data trade-off (TMD-TO) methods using the results of security evaluations of the lightweight stream ciphers Grain-v1, Grain-128 and LILI-128, reported in [415, 416], and [417], respectively.
3.2.1 Generic Approach
Certain stream ciphers can be attacked by employing the following approach: (1) Assuming the availability of a sufficiently long sample for recovering an internal state, we develop a dedicated TMD-TO attack which allows recovery of the internal state for a certain segment of the available sample. (2) The dedicated TMD-TO attack is developed over a subset of the internal states in which certain parts of the internal state are preset or algebraically recovered based on the considered keystream segment. Assume that the state size is ν and that certain bits (say β) of the internal state are fixed according to a specific pattern. Then, with this information, for the corresponding keystream segment, we try to obtain some more bits (say γ) of the internal state. The final goal is to recover the unknown bits of the internal state δ = ν − β − γ by employing a suitable TMD-TO attack. Accordingly, the cryptanalysis is based on the following framework:
-
preset certain bits of the internal state to a suitable pattern (the all-zeros pattern, for example);
-
for a given m-bit prefix (usually an m-zeros prefix) of the keystream segment, algebraically recover up to m bits of the internal state assuming that the remaining internal state bits are known;
-
recover the assumed bits of the internal state by employing the dedicated TMD-TO attack.
3.2.2 Summary of Cryptanalysis of Grain-v1 Employing Guess-and-Determine and Dedicated TMD-TO Approaches
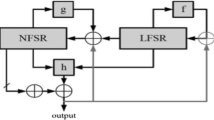
The internal state of Grain-v1 consists of 160 bits corresponding to the employed nonlinear and linear feedback shift registers NFSR and LFSR, respectively. For a given parameter m, let Ω (m) be a subset of all internal states where three m-length segments of all zeros exist which implies that the state generates m consecutive zero outputs. Let the vectors b (i) and s (i) be the states of the NFSR and LFSR, respectively, at the instant i, s (i) = [s i, s i+1, …, s i+79] and b (i) = [b i, b i+1, …, b i+79]. Let u (i) be the internal state of Grain-v1, and accordingly, u (i) = [s (i)||b (i)] = [s i, s i+1, …, s i+79, b i, b i+1, …, b i+79]. For a given parameter m, the set Ω (m) is the set of internal state vectors defined as follows Ω (m) = {u (i)|s i+25−j = 0, s i+64−j = 0, b i+63−j = 0 , j = 0, 1, …, m − 1}. Consequently, the number of internal states belonging to Ω (m) is upper-bounded by 2160−3m.
The internal state recovery is based on the following: Whenever we observe an m-zeros prefix of a keystream segment, we suppose that the segment is generated by an internal state belonging to Ω (m) and we employ a dedicated TMD-TO attack to check the hypothesis. The complexities of this cryptanalysis and a related one are illustrated in Table 2.12.
Notes
- 1.
- 2.
Part 2.B.2, Federal Register Notice (2 November 2007).
- 3.
- 4.
References
3GPP. ETSI (2014-10). Universal Mobile Telecommunications System (UMTS); LTE; 3G Security; Specification of the 3GPP confidentiality and integrity algorithms; Document 2: Kasumi specification (3GPP TS 35.202 version 12.0.0 Release 12), 2014.
Mohamed Ahmed Abdelraheem. Estimating the probabilities of low-weight differential and linear approximations on PRESENT-like ciphers. In Taekyoung Kwon, Mun-Kyu Lee, and Daesung Kwon, editors, ICISC 12: 15th International Conference on Information Security and Cryptology, volume 7839 of Lecture Notes in Computer Science, pages 368–382, Seoul, Korea, November 28–30, 2013. Springer.
Martin Ågren and Martin Hell. Cryptanalysis of the stream cipher bean. In Security of Information and Networks, SIN 2011, Sydney, Australia, November 14–19, 2011, pages 21–28, 2011.
Siavash Ahmadi, Zahra Ahmadian, Javad Mohajeri, and Mohammad Reza Aref. Low-data complexity biclique cryptanalysis of block ciphers with application to piccolo and HIGHT. IEEE Trans. Information Forensics and Security, 9(10):1641–1652, 2014.
Toru Akishita and Harunaga Hiwatari. Very compact hardware implementations of the blockcipher clefia. In Selected Areas in Cryptography, SAC 2011, Ontario, Canada, August 11–12, 2011, pages 278–292, 2011.
Martin R. Albrecht, Benedikt Driessen, Elif Bilge Kavun, Gregor Leander, Christof Paar, and Tolga Yalçin. Block ciphers - focus on the linear layer (feat. PRIDE). In Juan A. Garay and Rosario Gennaro, editors, Advances in Cryptology – CRYPTO 2014, Part I, volume 8616 of Lecture Notes in Computer Science, pages 57–76, Santa Barbara, CA, USA, August 17–21, 2014. Springer.
Riham AlTawy, Raghvendra Rohit, Morgan He, Kalikinkar Mandal, Gangqiang Yang, and Guang Gong. sliscp: Simeck-based permutations for lightweight sponge cryptographic primitives. In Selected Areas in Cryptography, SAC 2017, Ottawa, Canada, August 16–18, 2017, pages 129–150, 2018.
Elena Andreeva, Begül Bilgin, Andrey Bogdanov, Atul Luykx, Bart Mennink, Nicky Mouha, and Kan Yasuda. Ape: Authenticated permutation-based encryption for lightweight cryptography. In Fast Software Encryption, FSE 2014, London, UK, March 3–5, 2014, pages 168–186, 2015.
Ralph Ankele, Subhadeep Banik, Avik Chakraborti, Eik List, Florian Mendel, Siang Meng Sim, and Gaoli Wang. Related-key impossible-differential attack on reduced-round skinny. In Dieter Gollmann, Atsuko Miyaji, and Hiroaki Kikuchi, editors, ACNS 17: 15th International Conference on Applied Cryptography and Network Security, volume 10355 of Lecture Notes in Computer Science, pages 208–228, Kanazawa, Japan, July 10–12, 2017. Springer.
Ralph Ankele and Eik List. Differential cryptanalysis of round-reduced sparx-64/128. Cryptology ePrint Archive, Report 2018/332, 2018. https://eprint.iacr.org/2018/332.
Frederik Armknecht and Vasily Mikhalev. On lightweight stream ciphers with shorter internal states. In Gregor Leander, editor, Fast Software Encryption – FSE 2015, volume 9054 of Lecture Notes in Computer Science, pages 451–470, Istanbul, Turkey, March 8–11, 2015. Springer.
Jean-Philippe Aumasson and Daniel J. Bernstein. SipHash: A fast short-input PRF. In Steven D. Galbraith and Mridul Nandi, editors, Progress in Cryptology - INDOCRYPT 2012: 13th International Conference in Cryptology in India, volume 7668 of Lecture Notes in Computer Science, pages 489–508, Kolkata, India, December 9–12, 2012. Springer.
Jean-Philippe Aumasson, Luca Henzen, Willi Meier, and María Naya-Plasencia. Quark: A lightweight hash. Journal of Cryptology, 26(2):313–339, April 2013.
Jean-Philippe Aumasson, Philipp Jovanovic, and Samuel Neves. Norx8 and norx16: Authenticated encryption for low-end systems. IACR Cryptology ePrint Archive 2015/1154, 2015.
Jean-Philippe Aumasson, Philipp Jovanovic, and Samuel Neves. NORX v3.0. candidate for the CAESAR competition. https://norx.io, 2016.
Jean-Philippe Aumasson, Simon Knellwolf, and Willi Meier. Heavy quark for secure aead. In Directions in Authenticated Ciphers, DIAC 2012, Stockholm, Sweden, July 05–06, 2012, 2012.
Roberto Avanzi. The QARMA block cipher family – almost MDS matrices over rings with zero divisors, nearly symmetric Even-Mansour constructions with non-involutory central rounds, and search heuristics for low-latency S-boxes. Cryptology ePrint Archive, Report 2016/444, 2016. http://eprint.iacr.org/2016/444.
Steve Babbage. Improved “exhaustive search” attacks on stream ciphers. In European Convention on Security and Detection, pages 161–166. IET, May 1995.
Steve Babbage and Matthew Dodd. The MICKEY stream ciphers. In New Stream Cipher Designs - The eSTREAM Finalists, pages 191–209, 2008.
Stéphane Badel, Nilay Dagtekin, Jorge Nakahara, Khaled Ouafi, Nicolas Reffé, Pouyan Sepehrdad, Petr Susil, and Serge Vaudenay. ARMADILLO: A multi-purpose cryptographic primitive dedicated to hardware. In Stefan Mangard and François-Xavier Standaert, editors, Cryptographic Hardware and Embedded Systems – CHES 2010, volume 6225 of Lecture Notes in Computer Science, pages 398–412, Santa Barbara, CA, USA, August 17–20, 2010. Springer.
Subhadeep Banik. Some results on Sprout. In INDOCRYPT 2015, volume 9462 of LNCS, pages 124–139. Springer, 2015.
Subhadeep Banik, Andrey Bogdanov, Takanori Isobe, Kyoji Shibutani, Harunaga Hiwatari, Toru Akishita, and Francesco Regazzoni. Midori: A block cipher for low energy. In Tetsu Iwata and Jung Hee Cheon, editors, Advances in Cryptology – ASIACRYPT 2015, Part II, volume 9453 of Lecture Notes in Computer Science, pages 411–436, Auckland, New Zealand, November 30 – December 3, 2015. Springer.
Subhadeep Banik, Takanori Isobe, Tingting Cui, and Jian Guo. Some cryptanalytic results on Lizard. IACR Transactions on Symmetric Cryptology, 2017(4):82–98, 2017.
Subhadeep Banik, Takanori Isobe, and Masakatu Morii. On design of robust lightweight stream cipher with short internal state. IEICE Transactions, 101-A(1):99–109, 2018.
Gaurav Bansod, Abhijit Patil, and Narayan Pisharoty. Granule: An ultra lightweight cipher design for embedded security. IACR Cryptology ePrint Archive 2018/600, 2018.
Achiya Bar-On, Itai Dinur, Orr Dunkelman, Virginie Lallemand, Nathan Keller, and Boaz Tsaban. Cryptanalysis of SP networks with partial non-linear layers. In Elisabeth Oswald and Marc Fischlin, editors, Advances in Cryptology – EUROCRYPT 2015, Part I, volume 9056 of Lecture Notes in Computer Science, pages 315–342, Sofia, Bulgaria, April 26–30, 2015. Springer.
Achiya Bar-On and Nathan Keller. A 270 attack on the full MISTY1. In Matthew Robshaw and Jonathan Katz, editors, Advances in Cryptology – CRYPTO 2016, Part I, volume 9814 of Lecture Notes in Computer Science, pages 435–456, Santa Barbara, CA, USA, August 14–18, 2016. Springer.
Adnan Baysal and Sühap Sahin. Roadrunner: A small and fast bitslice block cipher for low cost 8-bit processors. In Lightweight Cryptography for Security and Privacy - 4th International Workshop, LightSec 2015, Bochum, Germany, September 10–11, 2015, Revised Selected Papers, pages 58–76, 2015.
Ray Beaulieu, Douglas Shors, Jason Smith, Stefan Treatman-Clark, Bryan Weeks, and Louis Wingers. The simon and speck lightweight block ciphers. In Proceedings of the 52Nd Annual Design Automation Conference, DAC ’15, pages 175:1–175:6, New York, NY, USA, 2015. ACM.
Christof Beierle, Jérémy Jean, Stefan Kölbl, Gregor Leander, Amir Moradi, Thomas Peyrin, Yu Sasaki, Pascal Sasdrich, and Siang Meng Sim. The SKINNY family of block ciphers and its low-latency variant MANTIS. In Matthew Robshaw and Jonathan Katz, editors, Advances in Cryptology – CRYPTO 2016, Part II, volume 9815 of Lecture Notes in Computer Science, pages 123–153, Santa Barbara, CA, USA, August 14–18, 2016. Springer.
Thierry P. Berger, Joffrey D’Hayer, Kevin Marquet, Marine Minier, and Gaël Thomas. The GLUON family: A lightweight hash function family based on FCSRs. In Aikaterini Mitrokotsa and Serge Vaudenay, editors, AFRICACRYPT 12: 5th International Conference on Cryptology in Africa, volume 7374 of Lecture Notes in Computer Science, pages 306–323, Ifrance, Morocco, July 10–12, 2012. Springer.
Thierry P. Berger, Julien Francq, Marine Minier, and Gaël Thomas. Extended generalized feistel networks using matrix representation to propose a new lightweight block cipher: Lilliput. IEEE Trans. Computers, 65(7):2074–2089, 2016.
Daniel J. Bernstein. Chacha, a variant of salsa20. In Workshop Record of SASC, volume 8, 2008.
Daniel J. Bernstein. The Salsa20 family of stream ciphers. In New Stream Cipher Designs - The eSTREAM Finalists, pages 84–97, 2008.
Guido Bertoni, Joan Daemen, Michaël Peeters, Gilles Van Assche, and Ronny Van Keer. Caesar submission: Ketje v2. candidate for the caesar competition. http://ketje.noekeon.org/, 2016.
Begül Bilgin, Andrey Bogdanov, Miroslav Knežević, Florian Mendel, and Qingju Wang. Fides: Lightweight authenticated cipher with side-channel resistance for constrained hardware. In Guido Bertoni and Jean-Sébastien Coron, editors, Cryptographic Hardware and Embedded Systems – CHES 2013, volume 8086 of Lecture Notes in Computer Science, pages 142–158, Santa Barbara, CA, USA, August 20–23, 2013. Springer.
Alex Biryukov and Eyal Kushilevitz. Improved cryptanalysis of RC5. In Kaisa Nyberg, editor, Advances in Cryptology – EUROCRYPT’98, volume 1403 of Lecture Notes in Computer Science, pages 85–99, Espoo, Finland, May 31 – June 4, 1998. Springer.
Alex Biryukov and Leo Perrin. State of the art in lightweight symmetric cryptography. Cryptology ePrint Archive, Report 2017/511, 2017. http://eprint.iacr.org/2017/511.
Alex Biryukov, Deike Priemuth-Schmid, and Bin Zhang. Multiset collision attacks on reduced-round SNOW 3G and SNOW 3G (+). In Jianying Zhou and Moti Yung, editors, ACNS 10: 8th International Conference on Applied Cryptography and Network Security, volume 6123 of Lecture Notes in Computer Science, pages 139–153, Beijing, China, June 22–25, 2010. Springer.
Alex Biryukov and Adi Shamir. Cryptanalytic time/memory/data tradeoffs for stream ciphers. In Tatsuaki Okamoto, editor, Advances in Cryptology – ASIACRYPT 2000, volume 1976 of Lecture Notes in Computer Science, pages 1–13, Kyoto, Japan, December 3–7, 2000. Springer.
Alex Biryukov, Adi Shamir, and David A. Wagner. Real time cryptanalysis of a5/1 on a pc. In Fast Software Encryption, FSE 2000, New York, NY, USA, April 10–12, 2000, pages 1–18, 2001.
Céline Blondeau and Benoît Gérard. Differential Cryptanalysis of PUFFIN and PUFFIN2, 11 2011.
BluetoothTM. Bluetooth specification, version 5.0, 2016.
Martin Boesgaard, Mette Vesterager, Thomas Pedersen, Jesper Christiansen, and Ove Scavenius. Rabbit: A new high-performance stream cipher. In Thomas Johansson, editor, Fast Software Encryption – FSE 2003, volume 2887 of Lecture Notes in Computer Science, pages 307–329, Lund, Sweden, February 24–26, 2003. Springer.
Andrey Bogdanov, Miroslav Knežević, Gregor Leander, Deniz Toz, Kerem Varici, and Ingrid Verbauwhede. Spongent: A lightweight hash function. In Bart Preneel and Tsuyoshi Takagi, editors, Cryptographic Hardware and Embedded Systems – CHES 2011, volume 6917 of Lecture Notes in Computer Science, pages 312–325, Nara, Japan, September 28 – October 1, 2011. Springer.
Andrey Bogdanov, Lars R. Knudsen, Gregor Leander, Christof Paar, Axel Poschmann, Matthew J. B. Robshaw, Yannick Seurin, and C. Vikkelsoe. PRESENT: An ultra-lightweight block cipher. In Pascal Paillier and Ingrid Verbauwhede, editors, Cryptographic Hardware and Embedded Systems – CHES 2007, volume 4727 of Lecture Notes in Computer Science, pages 450–466, Vienna, Austria, September 10–13, 2007. Springer.
Andrey Bogdanov, Gregor Leander, Christof Paar, Axel Poschmann, Matthew J. B. Robshaw, and Yannick Seurin. Hash functions and RFID tags: Mind the gap. In Elisabeth Oswald and Pankaj Rohatgi, editors, Cryptographic Hardware and Embedded Systems – CHES 2008, volume 5154 of Lecture Notes in Computer Science, pages 283–299, Washington, D.C., USA, August 10–13, 2008. Springer.
Andrey Bogdanov, Florian Mendel, Francesco Regazzoni, Vincent Rijmen, and Elmar Tischhauser. ALE: AES-based lightweight authenticated encryption. In Shiho Moriai, editor, Fast Software Encryption – FSE 2013, volume 8424 of Lecture Notes in Computer Science, pages 447–466, Singapore, March 11–13, 2014. Springer.
Andrey Bogdanov and Christian Rechberger. A 3-subset meet-in-the-middle attack: Cryptanalysis of the lightweight block cipher KTANTAN. In Alex Biryukov, Guang Gong, and Douglas R. Stinson, editors, SAC 2010: 17th Annual International Workshop on Selected Areas in Cryptography, volume 6544 of Lecture Notes in Computer Science, pages 229–240, Waterloo, Ontario, Canada, August 12–13, 2011. Springer.
Julia Borghoff, Anne Canteaut, Tim Güneysu, Elif Bilge Kavun, Miroslav Knežević, Lars R. Knudsen, Gregor Leander, Ventzislav Nikov, Christof Paar, Christian Rechberger, Peter Rombouts, Søren S. Thomsen, and Tolga Yalçin. PRINCE - A low-latency block cipher for pervasive computing applications - extended abstract. In Xiaoyun Wang and Kazue Sako, editors, Advances in Cryptology – ASIACRYPT 2012, volume 7658 of Lecture Notes in Computer Science, pages 208–225, Beijing, China, December 2–6, 2012. Springer.
Christina Boura, María Naya-Plasencia, and Valentin Suder. Scrutinizing and improving impossible differential attacks: Applications to CLEFIA, Camellia, LBlock and Simon. In Palash Sarkar and Tetsu Iwata, editors, Advances in Cryptology – ASIACRYPT 2014, Part I, volume 8873 of Lecture Notes in Computer Science, pages 179–199, Kaoshiung, Taiwan, R.O.C., December 7–11, 2014. Springer.
Christophe De Cannière, Orr Dunkelman, and Miroslav Knežević. KATAN and KTANTAN - a family of small and efficient hardware-oriented block ciphers. In Christophe Clavier and Kris Gaj, editors, Cryptographic Hardware and Embedded Systems – CHES 2009, volume 5747 of Lecture Notes in Computer Science, pages 272–288, Lausanne, Switzerland, September 6–9, 2009. Springer.
Christophe De Cannière and Bart Preneel. Trivium. In New Stream Cipher Designs - The eSTREAM Finalists, pages 244–266, 2008.
Anne Canteaut, Thomas Fuhr, Henri Gilbert, María Naya-Plasencia, and Jean-René Reinhard. Multiple differential cryptanalysis of round-reduced PRINCE. In Carlos Cid and Christian Rechberger, editors, Fast Software Encryption – FSE 2014, volume 8540 of Lecture Notes in Computer Science, pages 591–610, London, UK, March 3–5, 2015. Springer.
Anne Canteaut, Virginie Lallemand, and María Naya-Plasencia. Related-key attack on full-round PICARO. In Orr Dunkelman and Liam Keliher, editors, SAC 2015: 22nd Annual International Workshop on Selected Areas in Cryptography, volume 9566 of Lecture Notes in Computer Science, pages 86–101, Sackville, NB, Canada, August 12–14, 2016. Springer.
Avik Chakraborti, Anupam Chattopadhyay, Muhammad Hassan, and Mridul Nandi. TriviA: A fast and secure authenticated encryption scheme. In Tim Güneysu and Helena Handschuh, editors, Cryptographic Hardware and Embedded Systems – CHES 2015, volume 9293 of Lecture Notes in Computer Science, pages 330–353, Saint-Malo, France, September 13–16, 2015. Springer.
Arka Rai Choudhuri and Subhamoy Maitra. Significantly improved multi-bit differentials for reduced round Salsa and ChaCha. IACR Transactions on Symmetric Cryptology, 2016(2):261–287, 2016. http://tosc.iacr.org/index.php/ToSC/article/view/574.
Jiali Choy, Huihui Yap, Khoongming Khoo, Jian Guo, Thomas Peyrin, Axel Poschmann, and Chik How Tan. SPN-hash: Improving the provable resistance against differential collision attacks. In Aikaterini Mitrokotsa and Serge Vaudenay, editors, AFRICACRYPT 12: 5th International Conference on Cryptology in Africa, volume 7374 of Lecture Notes in Computer Science, pages 270–286, Ifrance, Morocco, July 10–12, 2012. Springer.
Carlos Cid, Shinsaku Kiyomoto, and Jun Kurihara. The rakaposhi stream cipher. In Information and Communications Security, ICICS 2009, Beijing, China, December 14–17, 2009, pages 32–46, 2009.
Nicolas T. Courtois. An improved differential attack on full GOST. In The New Codebreakers - Essays Dedicated to David Kahn on the Occasion of His 85th Birthday, pages 282–303, 2016.
Joan Daemen, René Govaerts, and Joos Vandewalle. A new approach to block cipher design. In Ross J. Anderson, editor, Fast Software Encryption – FSE’93, volume 809 of Lecture Notes in Computer Science, pages 18–32, Cambridge, UK, December 9–11, 1994. Springer.
Joan Daemen, Michaël Peeters, Gilles Van Assche, and Vincent Rijmen. Nessie proposal: NOEKEON, 2000. http://gro.noekeon.org/.
Joan Daemen and Vincent Rijmen. The Design of Rijndael: AES - The Advanced Encryption Standard. Springer-Verlag, 2002.
Yibin Dai and Shaozhen Chen. Cryptanalysis of full PRIDE block cipher. Science China Information Sciences, 60(5):052108, Sep 2016.
Sourav Das and Dipanwita Roy Chowdhury. Car30: a new scalable stream cipher with rule 30. Cryptography and Communications, 5(2):137–162, 2013.
Mathieu David, Damith Chinthana Ranasinghe, and Torben Bjerregaard Larsen. A2U2: A stream cipher for printed electronics RFID tags. 2011 IEEE International Conference on RFID, pages 176–183, 2011.
Lin Ding and Jie Guan. Cryptanalysis of mickey family of stream ciphers. Security and Communication Networks, 6(8):936–941, 2013.
Lin Ding, Chenhui Jin, Jie Guan, and Qiuyan Wang. Cryptanalysis of lightweight wg-8 stream cipher. IEEE Transactions on Information Forensics and Security, 9(4):645–652, 2014.
Daniel Dinu, Léo Perrin, Aleksei Udovenko, Vesselin Velichkov, Johann Großschädl, and Alex Biryukov. Design strategies for ARX with provable bounds: Sparx and LAX. In Jung Hee Cheon and Tsuyoshi Takagi, editors, Advances in Cryptology – ASIACRYPT 2016, Part I, volume 10031 of Lecture Notes in Computer Science, pages 484–513, Hanoi, Vietnam, December 4–8, 2016. Springer.
Dumitru-Daniel Dinu, Alex Biryukov, Johann Großschädl, Dmitry Khovra-Tovich, Yann Le Corre, and Léo Perrin. FELICS – fair evaluation of lightweight cryptographic systems. In NIST Workshop on Lightweight Cryptography 2015. National Institute of Standards and Technology (NIST), 2015.
Itai Dinur and Jérémy Jean. Cryptanalysis of fides. In Fast Software Encryption, FSE 2014, London, UK, March 3–5, 2014, pages 224–240, 2015.
Christoph Dobraunig, Maria Eichlseder, Daniel Kales, and Florian Mendel. Practical key-recovery attack on mantis5. IACR Trans. Symmetric Cryptol., 2016(2):248–260, 2017.
Christoph Dobraunig, Maria Eichlseder, Florian Mendel, and Martin Schläffer. Ascon v1.2. candidate for the CAESAR competition. http://ascon.iaik.tugraz.at/, 2016.
Orr Dunkelman, Nathan Keller, and Adi Shamir. A practical-time related-key attack on the kasumi cryptosystem used in gsm and 3g telephony. In Advances in Cryptology CRYPTO 2010, Santa Barbara, California, USA, August 15–19, 2010, pages 393–410, 2010.
Daniel W. Engels, Markku-Juhani O. Saarinen, Peter Schweitzer, and Eric M. Smith. The hummingbird-2 lightweight authenticated encryption algorithm. In RFID. Security and Privacy - 7th International Workshop, RFIDSec 2011, Amherst, USA, June 26–28, 2011, Revised Selected Papers, pages 19–31, 2011.
ETSI/SAGE. Specification of the 3gpp confidentiality and integrity algorithms uea2 & uia2. document 2: Snow 3g specification. technical report, etsi/sage, 2006.
ETSI/SAGE. Specification of the 3gpp confidentiality and integrity algorithms 128-eea3 & 128-eia3. document 2: Zuc specification, version 1.6, 2011.
Xinxin Fan, Kalikinkar Mandal, and Guang Gong. Wg-8: A lightweight stream cipher for resource-constrained smart devices. In Quality, Reliability, Security and Robustness in Heterogeneous Networks, Qshine 2013, Greader Noida, India, January 11–12, 2013, Revised Selected Papers, pages 617–632, 2013.
Horst Feistel. Cryptography and computer privacy. Scientific American, 228(5):15–23, 1973.
Martin Feldhofer and Christian Rechberger. A case against currently used hash functions in rfid protocols. In On the Move to Meaningful Internet Systems, OTM 2006, Montpellier, France, October 29 - November 3, 2006, pages 372–381, 2006.
Xiutao Feng and Fan Zhang. A practical state recovery attack on the stream cipher sablier v1. IACR Cryptology ePrint Archive 2014/245, 2014.
Niels Ferguson, Doug Whiting, Bruce Schneier, John Kelsey, Stefan Lucks, and Tadayoshi Kohno. Helix: Fast encryption and authentication in a single cryptographic primitive. In Thomas Johansson, editor, Fast Software Encryption – FSE 2003, volume 2887 of Lecture Notes in Computer Science, pages 330–346, Lund, Sweden, February 24–26, 2003. Springer.
Ximing Fu, Xiaoyun Wang, Xiaoyang Dong, and Willi Meier. A key-recovery attack on 855-round trivium. Cryptology ePrint Archive, Report 2018/198, 2018. https://eprint.iacr.org/2018/198.
Benoît Gérard, Vincent Grosso, María Naya-Plasencia, and François-Xavier Standaert. Block ciphers that are easier to mask: How far can we go? In Guido Bertoni and Jean-Sébastien Coron, editors, Cryptographic Hardware and Embedded Systems – CHES 2013, volume 8086 of Lecture Notes in Computer Science, pages 383–399, Santa Barbara, CA, USA, August 20–23, 2013. Springer.
Vahid Amin Ghafari and Honggang Hu. Fruit-80: A secure ultra-lightweight stream cipher for constrained environments. Entropy, 20(3):180, 2018.
Jovan Dj. Golic. Cryptanalysis of alleged A5 stream cipher. In Walter Fumy, editor, Advances in Cryptology – EUROCRYPT’97, volume 1233 of Lecture Notes in Computer Science, pages 239–255, Konstanz, Germany, May 11–15, 1997. Springer.
Zheng Gong, Pieter H. Hartel, Svetla Nikova, Shaohua Tang, and Bo Zhu. Tulp: A family of lightweight message authentication codes for body sensor networks. J. Comput. Sci. Technol., 29(1):53–68, 2014.
Zheng Gong, Svetla Nikova, and Yee Wei Law. KLEIN: A new family of lightweight block ciphers. In RFID. Security and Privacy - 7th International Workshop, RFIDSec 2011, Amherst, USA, June 26–28, 2011, Revised Selected Papers, pages 1–18, 2011.
T. Good and M. Benaissa. Hardware performance of estream phase-iii stream cipher candidates. In In SASC 2008, pages 163–174, 2008.
Hannes Gross, Erich Wenger, Christoph Dobraunig, and Christoph Ehrenhfer. Ascon hardware implementations and side-channel evaluation. Microprocessors and Microsystems, 22(1):1–10, 2016.
Vincent Grosso, Gaëtan Leurent, François-Xavier Standaert, Kerem Varici, Françcois Durvaux, Lubos Gaspar, and Stéphanie Kerckhof. SCREAM & iSCREAM, side-channel resistant authenticated encryption with masking. submission to the caesar competition, 2014.
Vincent Grosso, Gaëtan Leurent, François-Xavier Standaert, and Kerem Varici. LS-designs: Bitslice encryption for efficient masked software implementations. In Carlos Cid and Christian Rechberger, editors, Fast Software Encryption – FSE 2014, volume 8540 of Lecture Notes in Computer Science, pages 18–37, London, UK, March 3–5, 2015. Springer.
Jian Guo, Jérémy Jean, Ivica Nikolic, Kexin Qiao, Yu Sasaki, and Siang Meng Sim. Invariant subspace attack against Midori64 and the resistance criteria for S-box designs. IACR Transactions on Symmetric Cryptology, 2016(1):33–56, 2016. http://tosc.iacr.org/index.php/ToSC/article/view/534.
Jian Guo, Thomas Peyrin, and Axel Poschmann. The PHOTON family of lightweight hash functions. In Phillip Rogaway, editor, Advances in Cryptology – CRYPTO 2011, volume 6841 of Lecture Notes in Computer Science, pages 222–239, Santa Barbara, CA, USA, August 14–18, 2011. Springer.
Jian Guo, Thomas Peyrin, Axel Poschmann, and Matthew J. B. Robshaw. The LED block cipher. In Bart Preneel and Tsuyoshi Takagi, editors, Cryptographic Hardware and Embedded Systems – CHES 2011, volume 6917 of Lecture Notes in Computer Science, pages 326–341, Nara, Japan, September 28 – October 1, 2011. Springer.
Matthias Hamann, Matthias Krause, and Willi Meier. LIZARD – A lightweight stream cipher for power-constrained devices. IACR Transactions on Symmetric Cryptology, 2017(1):45–79, 2017.
George Hatzivasilis, Konstantinos Fysarakis, Ioannis Papaefstathiou, and Charalampos Manifavas. A review of lightweight block ciphers. J. Cryptographic Engineering, 8(2):141–184, 2018.
Martin Hell, Thomas Johansson, Er Maximov, and Willi Meier. A stream cipher proposal: Grain-128. In 2006 IEEE International Symposium on Information Theory, pages 1614–1618, July 2006.
Martin Hell, Thomas Johansson, and Willi Meier. Grain: a stream cipher for constrained environments. IJWMC, 2(1):86–93, 2007.
Martin E. Hellman. A cryptanalytic time-memory trade-off. IEEE Trans. Information Theory, 26(4):401–406, 1980.
Luca Henzen, Flavio Carbognani, Norbert Felber, and Wolfgang Fichtner. Vlsi hardware evaluation of the stream ciphers salsa20 and chacha, and the compression function rumba. In 2nd International Conference on Signals, Circuits and Systems, SCS 2008, Monastir, Tunisia, November 7–9, 2008, pages 1–5, 2008.
Shoichi Hirose, Kota Ideguchi, Hidenori Kuwakado, Toru Owada, Bart Preneel, and Hirotaka Yoshida. A lightweight 256-bit hash function for hardware and low-end devices: Lesamnta-LW. In Kyung Hyune Rhee and DaeHun Nyang, editors, ICISC 10: 13th International Conference on Information Security and Cryptology, volume 6829 of Lecture Notes in Computer Science, pages 151–168, Seoul, Korea, December 1–3, 2011. Springer.
Deukjo Hong, Jung-Keun Lee, Dong-Chan Kim, Daesung Kwon, Kwon Ho Ryu, and Dong-Geon Lee. LEA: A 128-bit block cipher for fast encryption on common processors. In Yongdae Kim, Heejo Lee, and Adrian Perrig, editors, WISA 13: 14th International Workshop on Information Security Applications, volume 8267 of Lecture Notes in Computer Science, pages 3–27, Jeju Island, Korea, August 19–21, 2014. Springer.
Deukjo Hong, Jaechul Sung, Seokhie Hong, Jongin Lim, Sangjin Lee, Bon-Seok Koo, Changhoon Lee, Donghoon Chang, Jesang Lee, Kitae Jeong, Hyun Kim, Jongsung Kim, and Seongtaek Chee. HIGHT: A new block cipher suitable for low-resource device. In Louis Goubin and Mitsuru Matsui, editors, Cryptographic Hardware and Embedded Systems – CHES 2006, volume 4249 of Lecture Notes in Computer Science, pages 46–59, Yokohama, Japan, October 10–13, 2006. Springer.
Takanori Isobe, Toshihiro Ohigashi, and Masakatu Morii. Slide cryptanalysis of lightweight stream cipher rakaposhi. In Advances in Information and Computer Security, IWSEC 2012, Fukuoka, Japan, November 7–9, 2012, pages 138–155, 2012.
Maryam Izadi, Babak Sadeghiyan, Seyed Saeed Sadeghian, and Hossein Arabnezhad Khanooki. MIBS: A new lightweight block cipher. In Juan A. Garay, Atsuko Miyaji, and Akira Otsuka, editors, CANS 09: 8th International Conference on Cryptology and Network Security, volume 5888 of Lecture Notes in Computer Science, pages 334–348, Kanazawa, Japan, December 12–14, 2009. Springer.
Goce Jakimoski and Samant Khajuria. ASC-1: An authenticated encryption stream cipher. In Ali Miri and Serge Vaudenay, editors, SAC 2011: 18th Annual International Workshop on Selected Areas in Cryptography, volume 7118 of Lecture Notes in Computer Science, pages 356–372, Toronto, Ontario, Canada, August 11–12, 2012. Springer.
Jérémy Jean, Ivica Nikolić, and Thomas Peyrin. Joltik v1. submission to the caesar competition, 2014.
Anthony Journault, François-Xavier Standaert, and Kerem Varici. Improving the security and efficiency of block ciphers based on ls-designs. Des. Codes Cryptography, 82(1–2):495–509, 2017.
Ari Juels and Stephen A Weis. Authenticating pervasive devices with human protocols. In Advances in Cryptology–CRYPTO 2005, pages 293–308. Springer, 2005.
Pascal Junod. On the complexity of matsuis attack. In Selected Areas in Cryptography, SAC 2001 Toronto, Ontario, Canada, August 1617, 2001, pages 199–211, 2001.
Ferhat Karakoç, Hüseyin Demirci, and A. Emre Harmanci. Itubee: A software oriented lightweight block cipher. In Lightweight Cryptography for Security and Privacy - Second International Workshop, LightSec 2013, Gebze, Turkey, May 6–7, 2013, Revised Selected Papers, pages 16–27, 2013.
Chris Karlof, Naveen Sastry, and David Wagner. Tinysec: A link layer security architecture for wireless sensor networks. In Embedded networked sensor systems, SenSys04, Baltimore, USA, November 03–05, 2004, pages 162–175, 2004.
Pierre Karpman and Benjamin Grégoire. The Littlun S-box and the fly block cipher. Lightweight Cryptography Workshop, October 17–18 2016, NIST, 2016.
John Kelsey, Bruce Schneier, and David A. Wagner. Related-key cryptanalysis of 3-way, biham-des, cast, des-x, newdes, rc2, and tea. In Information and Communication Security, First International Conference, ICICS’97, Beijing, China, November 11–14, 1997, pages 233–246, 1997.
Dmitry Khovratovich and Christian Rechberger. The local attack: Cryptanalysis of the authenticated encryption scheme ale. In Selected Areas in Cryptography, SAC 2013, Burnaby, Canada, August 14–16, 2013, pages 174–184, 2013.
Aleksandar Kircanski and Amr M. Youssef. Differential fault analysis of rabbit. In Selected Areas in Cryptography, SAC 2009, Calgary, Alberta, Canada, August 13–14, 2009, pages 197–214, 2009.
Lars R. Knudsen, Gregor Leander, Axel Poschmann, and Matthew J. B. Robshaw. PRINTcipher: A block cipher for IC-printing. In Stefan Mangard and François-Xavier Standaert, editors, Cryptographic Hardware and Embedded Systems – CHES 2010, volume 6225 of Lecture Notes in Computer Science, pages 16–32, Santa Barbara, CA, USA, August 17–20, 2010. Springer.
Lars R. Knudsen and Havard Raddum. On Noekeon, 2001.
Takuma Koyama, Yu Sasaki, and Noboru Kunihiro. Multi-differential cryptanalysis on reduced DM-PRESENT-80: Collisions and other differential properties. In Taekyoung Kwon, Mun-Kyu Lee, and Daesung Kwon, editors, ICISC 12: 15th International Conference on Information Security and Cryptology, volume 7839 of Lecture Notes in Computer Science, pages 352–367, Seoul, Korea, November 28–30, 2013. Springer.
Naveen Kumar, Shrikant Ojha, Kritika Jain, and Sangeeta Lal. Bean: a lightweight stream cipher. In Security of Information and Networks, SIN 09, Famagusta, North Cyprus, October 06–10, 2009, pages 168–171, 2009.
Jingjing Lan, Jun Zhou, and Xin Liu. An area-efficient implementation of a message authentication code (mac) algorithm for cryptographic systems. In TENCON 1016, Singapore, Singapore, November 22–25, 2016, pages 601–617, 2016.
Gregor Leander, Mohamed Ahmed Abdelraheem, Hoda AlKhzaimi, and Erik Zenner. A cryptanalysis of PRINTcipher: The invariant subspace attack. In Phillip Rogaway, editor, Advances in Cryptology – CRYPTO 2011, volume 6841 of Lecture Notes in Computer Science, pages 206–221, Santa Barbara, CA, USA, August 14–18, 2011. Springer.
Gregor Leander, Brice Minaud, and Sondre Rønjom. A generic approach to invariant subspace attacks: Cryptanalysis of robin, iSCREAM and Zorro. In Elisabeth Oswald and Marc Fischlin, editors, Advances in Cryptology – EUROCRYPT 2015, Part I, volume 9056 of Lecture Notes in Computer Science, pages 254–283, Sofia, Bulgaria, April 26–30, 2015. Springer.
Gregor Leander, Christof Paar, Axel Poschmann, and Kai Schramm. New lightweight DES variants. In Alex Biryukov, editor, Fast Software Encryption – FSE 2007, volume 4593 of Lecture Notes in Computer Science, pages 196–210, Luxembourg, Luxembourg, March 26–28, 2007. Springer.
Gaëtan Leurent. Differential forgery attack against lac. In Selected Areas in Cryptography, SAC 2015, Sackville, Canada, August 12–14, 2015, pages 217–224, 2016.
Gaëtan Leurent. Improved differential-linear cryptanalysis of 7-round chaskey with partitioning. In Marc Fischlin and Jean-Sébastien Coron, editors, Advances in Cryptology – EUROCRYPT 2016, Part I, volume 9665 of Lecture Notes in Computer Science, pages 344–371, Vienna, Austria, May 8–12, 2016. Springer.
T. Li, H. Wu, X. Wang, and F. Bao. Sensec design. i 2 r sensor network flagship project (snfp: security part): Technical report-tr v1.0, 2005.
Zheng Li, Xiaoyang Dong, and Xiaoyun Wang. Conditional cube attack on round-reduced ascon. IACR Trans. Symmetric Cryptol., 2017(1):175–202, 2017.
Chae Hoon Lim and Tymur Korkishko. mCrypton - a lightweight block cipher for security of low-cost RFID tags and sensors. In Jooseok Song, Taekyoung Kwon, and Moti Yung, editors, WISA 05: 6th International Workshop on Information Security Applications, volume 3786 of Lecture Notes in Computer Science, pages 243–258, Jeju Island, Korea, August 22–24, 2006. Springer.
Li Lin, Wenling Wu, and Yafei Zheng. Automatic search for key-bridging technique: Applications to LBlock and TWINE. In Thomas Peyrin, editor, Fast Software Encryption – FSE 2016, volume 9783 of Lecture Notes in Computer Science, pages 247–267, Bochum, Germany, March 20–23, 2016. Springer.
Zongbin Liu, Qinglong Zhang, Cunqing Ma, Changting Li, and Jiwu Jing. Hpaz: a high-throughput pipeline architecture of zuc in hardware. In Design, Automation & Test in Europe, DATE 2016, Dresden, Germany, March 14–18, 2016, pages 269–272, 2016.
Jiqiang Lu. Related-key rectangle attack on 36 rounds of the XTEA block cipher. Int. J. Inf. Sec., 8(1):1–11, 2009.
Yi Lu, Willi Meier, and Serge Vaudenay. The conditional correlation attack: a practical attack on bluetooth encryption. In Advances in Cryptology CRYPTO 2005, Santa Barbara, California, USA, August 14–18, 2005, pages 97–117, 2005.
Mark Luk, Ghita Mezzour, Adrian Perrig, and Virgil Gligor. Minisec: A secure sensor network communication architecture. In 6th International Symposium on Information Processing in Sensor Networks, IPSN 2007, Cambridge, MA, USA, April 25–27, 2007, pages 479–488, 2007.
Atul Luykx, Bart Preneel, Elmar Tischhauser, and Kan Yasuda. A MAC mode for lightweight block ciphers. In Thomas Peyrin, editor, Fast Software Encryption – FSE 2016, volume 9783 of Lecture Notes in Computer Science, pages 43–59, Bochum, Germany, March 20–23, 2016. Springer.
Zhen Ma, Tian Tian, and Wen-Feng Qi. Internal state recovery of Grain v1 employing guess-and-determine attack. IET Information Security, 11(6):363–368, 2017.
Hamid Mala, Mohammad Dakhilalian, and Mohsen Shakiba. Cryptanalysis of mcrypton - A lightweight block cipher for security of RFID tags and sensors. Int. J. Communication Systems, 25(4):415–426, 2012.
Charalampos Manifavas, George Hatzivasilis, Konstantinos Fysarakis, and Yannis Papaefstathiou. A survey of lightweight stream ciphers for embedded systems. Security and Communication Networks, 9(10):1226–1246, 2016.
Mitsuru Matsui. New block encryption algorithm MISTY. In Eli Biham, editor, Fast Software Encryption – FSE’97, volume 1267 of Lecture Notes in Computer Science, pages 54–68, Haifa, Israel, January 20–22, 1997. Springer.
Kerry A. McKay, Larry Bassham, Meltem Sönmez Turan, and Nicky Mouha. Nistir 8114 - report on lightweight cryptography, 2016.
Nele Mentens, Jan Genoe, Bart Preneel, and Ingrid Verbauwhede. A low-cost implementation of Trivium. In SASC 2008, pages 197–204, 2008.
Miodrag J. Mihaljevic, Sugata Gangopadhyay, Goutam Paul, and Hideki Imai. Generic cryptographic weakness of k-normal boolean functions in certain stream ciphers and cryptanalysis of grain-128. Periodica Mathematica Hungarica, 65(2):205–227, 2012.
Miodrag J. Mihaljevic, Sugata Gangopadhyay, Goutam Paul, and Hideki Imai. Internal state recovery of grain-v1 employing normality order of the filter function. IET Information Security, 6(2):55–64, 2012.
Miodrag J. Mihaljevic, Sugata Gangopadhyay, Goutam Paul, and Hideki Imai. Internal state recovery of keystream generator LILI-128 based on a novel weakness of the employed boolean function. Inf. Process. Lett., 112(21):805–810, 2012.
Vasily Mikhalev, Frederik Armknecht, and Christian Müller. On ciphers that continuously access the non-volatile key. IACR Transactions on Symmetric Cryptology, 2016(2):52–79, 2016. http://tosc.iacr.org/index.php/ToSC/article/view/565.
Vasily Mikhalev, Frederik Armknecht, and Christian Müller. On ciphers that continuously access the non-volatile key. IACR Transactions on Symmetric Cryptology, 2016(2):52–79, 2017.
Amir Moradi, Axel Poschmann, San Ling, Christof Paar, and Huaxiong Wang. Pushing the limits: A very compact and a threshold implementation of AES. In Kenneth G. Paterson, editor, Advances in Cryptology – EUROCRYPT 2011, volume 6632 of Lecture Notes in Computer Science, pages 69–88, Tallinn, Estonia, May 15–19, 2011. Springer.
Nicky Mouha, Bart Mennink, Anthony Van Herrewege, Dai Watanabe, Bart Preneel, and Ingrid Verbauwhede. Chaskey: An efficient MAC algorithm for 32-bit microcontrollers. In Antoine Joux and Amr M. Youssef, editors, SAC 2014: 21st Annual International Workshop on Selected Areas in Cryptography, volume 8781 of Lecture Notes in Computer Science, pages 306–323, Montreal, QC, Canada, August 14–15, 2014. Springer.
Frédéric Muller. Differential attacks against the helix stream cipher. In Fast Software Encryption,FSE 2004, Delhi, India, February 5–7 , 2004, pages 94–108, 2004.
Mara Naya-Plasencia and Thomas Peyrin. Practical cryptanalysis of armadillo2. In Fast Software Encryption,FSE 2012, Washington, DC, USA, March 19–21, 2012, pages 146–162, 2012.
Roger M. Needham and David J. Wheeler. Tea extensions. Technical report, Computer Laboratory, University of Cambridge, 1997.
Ivica Nikolic, Lei Wang, and Shuang Wu. Cryptanalysis of round-reduced ∖mathttled. In Fast Software Encryption - 20th International Workshop, FSE 2013, Singapore, March 11–13, 2013. Revised Selected Papers, pages 112–129, 2013.
Léo Perrin and Dmitry Khovratovich. Collision spectrum, entropy loss, T-sponges, and cryptanalysis of GLUON-64. In Carlos Cid and Christian Rechberger, editors, Fast Software Encryption – FSE 2014, volume 8540 of Lecture Notes in Computer Science, pages 82–103, London, UK, March 3–5, 2015. Springer.
Petter Pessl and Michael Hutter. Pushing the limits of sha-3 hardware implementations to fit on rfid. In Cryptographic Hardware and Embedded Systems, CHES 2013, Santa Barbara, CA, USA, August 20–23, 2013, pages 126–141, 2013.
Raphael C.-W. Phan and Adi Shamir. Improved related-key attacks on desx and desx+ . Cryptologia, 32(1):13–22, 2008.
Gilles Piret, Thomas Roche, and Claude Carlet. PICARO - a block cipher allowing efficient higher-order side-channel resistance. In Feng Bao, Pierangela Samarati, and Jianying Zhou, editors, ACNS 12: 10th International Conference on Applied Cryptography and Network Security, volume 7341 of Lecture Notes in Computer Science, pages 311–328, Singapore, June 26–29, 2012. Springer.
Axel Poschmann, San Ling, and Huaxiong Wang. 256 bit standardized crypto for 650 GE - GOST revisited. In Stefan Mangard and François-Xavier Standaert, editors, Cryptographic Hardware and Embedded Systems – CHES 2010, volume 6225 of Lecture Notes in Computer Science, pages 219–233, Santa Barbara, CA, USA, August 17–20, 2010. Springer.
Lingyue Qin, Huaifeng Chen, and Xiaoyun Wang. Linear hull attack on round-reduced simeck with dynamic key-guessing techniques. In Joseph K. Liu and Ron Steinfeld, editors, ACISP 16: 21st Australasian Conference on Information Security and Privacy, Part II, volume 9723 of Lecture Notes in Computer Science, pages 409–424, Melbourne, VIC, Australia, July 4–6, 2016. Springer.
Shahram Rasoolzadeh, Zahra Ahmadian, Mahmoud Salmasizadeh, and Mohammad Reza Aref. An improved truncated differential cryptanalysis of KLEIN. Tatra Mountains Mathematical Publications, 67:135–147, 2017.
Ronald L. Rivest. The RC5 encryption algorithm. In Bart Preneel, editor, Fast Software Encryption – FSE’94, volume 1008 of Lecture Notes in Computer Science, pages 86–96, Leuven, Belgium, December 14–16, 1995. Springer.
Phillip Rogaway, Mihir Bellare, and John Black. Ocb: A block-cipher mode of operation for efficient authenticated encryption. ACM Transactions on Information and System Security, 6(3):365–403, 2003.
Karmakar Sandip, Mukhopadhyay Debdeep, and Roy Chowdhury Dipanwita. Cavium strengthening trivium stream cipher using cellular automata. Journal of Cellular Automata, 7(2):179–197, 2012.
Yu Sasaki and Yosuke Todo. New differential bounds and division property of Lilliput: Block cipher with extended generalized Feistel network. In Roberto Avanzi and Howard M. Heys, editors, SAC 2016: 23rd Annual International Workshop on Selected Areas in Cryptography, volume 10532 of Lecture Notes in Computer Science, pages 264–283, St. John’s, NL, Canada, August 10–12, 2016. Springer.
Mohammad Hossein Faghihi Sereshgi, Mohammad Dakhilalian, and Mohsen Shakiba. Biclique cryptanalysis of MIBS-80 and PRESENT-80 block ciphers. Security and Communication Networks, 9(1):27–33, 2016.
Jinyong Shan, Lei Hu, Ling Song, Siwei Sun, and Xiaoshuang Ma. Related-key differential attack on round reduced RECTANGLE-80. Cryptology ePrint Archive, Report 2014/986, 2014. http://eprint.iacr.org/2014/986.
Claude Shannon. Communication theory of secrecy systems. Bell System Technical Journal, 28(4):656–715, 1949.
Zhenqing Shi, Xiutao Feng, Dengguo Feng, and Chuankun Wu. A real-time key recovery attack on the lightweight stream cipher a2u2. In Cryptology and Network Security, CANS 2012, Darmstadt, Germany, December 12-14, 2012, pages 12–22, 2012.
Zhenqing Shi, Bin Zhang, and Dengguo Feng. Practical-time related-key attack on hummingbird-2. IET Information Security, 9(6):321–327, 2015.
Kyoji Shibutani, Takanori Isobe, Harunaga Hiwatari, Atsushi Mitsuda, Toru Akishita, and Taizo Shirai. Piccolo: An ultra-lightweight blockcipher. In Bart Preneel and Tsuyoshi Takagi, editors, Cryptographic Hardware and Embedded Systems – CHES 2011, volume 6917 of Lecture Notes in Computer Science, pages 342–357, Nara, Japan, September 28 – October 1, 2011. Springer.
Taizo Shirai, Kyoji Shibutani, Toru Akishita, Shiho Moriai, and Tetsu Iwata. The 128-bit blockcipher CLEFIA (extended abstract). In Alex Biryukov, editor, Fast Software Encryption – FSE 2007, volume 4593 of Lecture Notes in Computer Science, pages 181–195, Luxembourg, Luxembourg, March 26–28, 2007. Springer.
Siang Meng Sim and Lei Wang. Practical forgery attacks on scream and iscream. http://www1.spms.ntu.edu.sg/~syllab/m/images/b/b3/ForgeryAttackonSCREAM.pdf.
Ling Song, Zhangjie Huang, and Qianqian Yang. Automatic differential analysis of ARX block ciphers with application to SPECK and LEA. In Joseph K. Liu and Ron Steinfeld, editors, ACISP 16: 21st Australasian Conference on Information Security and Privacy, Part II, volume 9723 of Lecture Notes in Computer Science, pages 379–394, Melbourne, VIC, Australia, July 4–6, 2016. Springer.
François-Xavier Standaert, Gilles Piret, Gaël Rouvroy, Jean-Jacques Quisquater, and Jean-Didier Legat. ICEBERG: An involutional cipher efficient for block encryption in reconfigurable hardware. In Bimal K. Roy and Willi Meier, editors, Fast Software Encryption – FSE 2004, volume 3017 of Lecture Notes in Computer Science, pages 279–299, New Delhi, India, February 5–7, 2004. Springer.
François-Xavier Standaert, Gilles Piret, Neil Gershenfeld, and Jean-Jacques Quisquater. SEA: A scalable encryption algorithm for small embedded applications. In Smart Card Research and Advanced Applications, 7th IFIP WG 8.8/11.2 International Conference, CARDIS 2006, Tarragona, Spain, April 19-21, 2006, Proceedings, pages 222–236, 2006.
Yue Sun, Meiqin Wang, Shujia Jiang, and Qiumei Sun. Differential cryptanalysis of reduced-round ICEBERG. In Aikaterini Mitrokotsa and Serge Vaudenay, editors, AFRICACRYPT 12: 5th International Conference on Cryptology in Africa, volume 7374 of Lecture Notes in Computer Science, pages 155–171, Ifrance, Morocco, July 10–12, 2012. Springer.
Tomoyasu Suzaki, Kazuhiko Minematsu, Sumio Morioka, and Eita Kobayashi. TWINE: A lightweight, versatile block cipher. In ECRYPT Workshop on Lightweight Cryptography, pages 146–169, 2011.
Biaoshuai Tao and Hongjun Wu. Improving the biclique cryptanalysis of aes. In Information Security and Privacy, ACISP 2015, Brisbane, Australia, June 29 - July 1, 2015, pages 39–56, 2015.
Yun Tian, Gongliang Chen, and Jianhua Li. Quavium - a new stream cipher inspired by trivium. Journal of Computers, 7(5):1278–1283, 2012.
Cheng Wang and Howard M. Heys. An ultra compact block cipher for serialized architecture implementations. In Proceedings of the 22nd Canadian Conference on Electrical and Computer Engineering, CCECE 2009, 3-6 May 2009, Delta St. John’s Hotel and Conference Centre, St. John’s, Newfoundland, Canada, pages 1085–1090, 2009.
Dai Watanabe, Kota Ideguchi, Jun Kitahara, Kenichiro Muto, Hiroki Furuichi, and Toshinobu Kaneko. Enocoro-80: A hardware oriented stream cipher. In Proceedings of the The Third International Conference on Availability, Reliability and Security, ARES 2008, March 4-7, 2008, Technical University of Catalonia, Barcelona , Spain, pages 1294–1300, 2008.
Dai Watanabe, Kazuto Okamoto, and Toshinobu Kaneko. A hardware-oriented light weight pseudo-random number generator enocoro-128v2. In SCIS 2010, 3D1-3, (2010). In Japanese, 2010.
Hongjun Wu. Acorn: A lighweight authenticated cipher (v3). Candidate for the CAESAR Competition, 2016.
Wenling Wu, Shuang Wu, Lei Zhang, Jian Zou, and Le Dong. Lhash: A lightweight hash function. In Information Security and Cryptology - 9th International Conference, Inscrypt 2013, Guangzhou, China, November 27-30, 2013, Revised Selected Papers, pages 291–308, 2013.
Wenling Wu and Lei Zhang. LBlock: A lightweight block cipher. In Javier Lopez and Gene Tsudik, editors, ACNS 11: 9th International Conference on Applied Cryptography and Network Security, volume 6715 of Lecture Notes in Computer Science, pages 327–344, Nerja, Spain, June 7–10, 2011. Springer.
Minm Xie, Jingjing Li, and Yuechuan Zang. Related-key impossible differential cryptanalysis of lblock. Chinese Journal of Electronics, 26(1):35–41, 2017.
Dai Yamamoto, Kouichi Itoh, and Jun Yajima. A very compact hardware implementation of the kasumi block cipher. In 4th IFIP WG 11.2 International Workshop WISTP 2010, Passau, Germany, April 12-14, 2010, pages 293–307, 2010.
Gangqiang Yang, Xinxin Fan, Mark Aagaard, and Guang Gong. Design space exploration of the lightweight stream cipher wg-8 for fpgas and asics. In Workshop on Embedded Systems Security, WESS’13, Article No. 8, Montreal, Quebec, Canada, September 29 - October 04, 2013, 2013.
Gangqiang Yang, Bo Zhu, Valentin Suder, Mark D. Aagaard, and Guang Gong. The simeck family of lightweight block ciphers. In Tim Güneysu and Helena Handschuh, editors, Cryptographic Hardware and Embedded Systems – CHES 2015, volume 9293 of Lecture Notes in Computer Science, pages 307–329, Saint-Malo, France, September 13–16, 2015. Springer.
Bin Zhang, Zhenqing Shi, Chao Xu, Yuan Yao, and Zhenqi Li. Sablier v1. Candidate for the CAESAR Competition, 2014.
Bin Zhang, Chao Xu, and Willi Meier. Fast near collision attack on the Grain v1 stream cipher. In Jesper Buus Nielsen and Vincent Rijmen, editors, Advances in Cryptology – EUROCRYPT 2018, Part II, volume 10821 of Lecture Notes in Computer Science, pages 771–802, Tel Aviv, Israel, April 29 – May 3, 2018. Springer.
Lei Zhang, Wenling Wu, Yanfeng Wang, Shengbao Wu, and Jian Zhang. LAC: A lightweight authenticated encryption cipher. Candidate for the CAESAR Competition, 2014.
WenTao Zhang, ZhenZhen Bao, DongDai Lin, Vincent Rijmen, BoHan Yang, and Ingrid Verbauwhede. Rectangle: a bit-slice lightweight block cipher suitable for multiple platforms. Science China Information Sciences, 58(12):1–15, 2015.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2021 The Author(s)
About this chapter

Cite this chapter
Mileva, A., Dimitrova, V., Kara, O., Mihaljević, M.J. (2021). Catalog and Illustrative Examples of Lightweight Cryptographic Primitives. In: Avoine, G., Hernandez-Castro, J. (eds) Security of Ubiquitous Computing Systems. Springer, Cham. https://doi.org/10.1007/978-3-030-10591-4_2
Download citation
DOI: https://doi.org/10.1007/978-3-030-10591-4_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-10590-7
Online ISBN: 978-3-030-10591-4
eBook Packages: Computer ScienceComputer Science (R0)