
Abstract
We propose a novel Coupled Hidden Markov Model to detect epileptic seizures in multichannel electroencephalography (EEG) data. Our model defines a network of seizure propagation paths to capture both the temporal and spatial evolution of epileptic activity. To address the intractability introduced by the coupled interactions, we derive a variational inference procedure to efficiently infer the seizure evolution from spectral patterns in the EEG data. We validate our model on EEG aquired under clinical conditions in the Epilepsy Monitoring Unit of the Johns Hopkins Hospital. Using 5-fold cross validation, we demonstrate that our model outperforms three baseline approaches which rely on a classical detection framework. Our model also demonstrates the potential to localize seizure onset zones in focal epilepsy.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others
1 Introduction
Epilepsy is a heterogenous neurological disorder characterized by recurring and unprovoked seizures [1]. It is estimated that 20–40% of epilepsy patients are medically refractory and do not respond to drug therapy. Alternative therapies for these patients crucially depend on being able to detect epileptic activity in the brain. The most common modality used for seizure detection is multichannel electroencephalography (EEG) acquired on the scalp. The clinical standard for seizure detection involves visual inspection of the EEG data, which is time consuming and requires extensive training. In this work, we develop an automated seizure detection procedure for clinically acquired multichannel EEG recordings.
There is a vast body of literature on epileptic seizure detection from a variety of viewpoints. The nonlinearity of EEG signals has inspired the application of techniques from chaos theory such as approximate entropy and Lyapunov exponents as in [2, 3], respectively. Alternatively, wavelet and other time-frequency based features seek to capture the non-stationarity of the EEG signal as in [4]. These features are fed into standard classification algorithms to detect seizure activity. A fundamental limitation of the methods in [2, 3] is that they are trained on a single channel of EEG data and fail to generalize in practice. Multichannel strategies such as those in [4,5,6,7] rely heavily on prior seizure recordings to train patient specific detectors, which are often unavailable.
Unlike prior work, our approach explicitly models the spatial dynamics of a seizure through the brain over time. We build on existing work in Hidden Markov Models (HMMs) [7], adopting a Coupled HMM (CHMM) [8] to model interchannel dependencies. Specifically, the likelihood that an EEG channel will transition into a seizure state will increase if neighboring channels are in a seizure state. This coupling renders exact inference intractable. Therefore we develop a variational Expectation Maximization (EM) algorithm for our framework.
We evaluate our algorithm using 90 scalp EEG recordings from 15 epilepsy patients acquired in the Epilepsy Monitoring Unit (EMU) of the Johns Hopkins Hospital. These recordings contain up to 10 min of baseline activity before and after a seizure and have not been screened for artifacts. We compare our CHMM to classifiers evaluated on a framewise and channelwise basis. Our algorithm outperforms these baselines and demonstrates efficacy in classifying seizure intervals. Our algorithm provides localization information that could be useful for determining the seizure onset location in cases of focal epilepsy.
2 Generative Model of Seizure Propagation
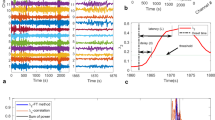
We adopt a Bayesian framework for seizure detection. The latent variables \(\mathbf {X}\) denote the seizure or non-seizure states. \(\mathbf {Y}\) corresponds to observed data feature vectors computed from EEG channels as shown in Fig. 1(a). The random variable \(X^t_i\) denotes the latent state of EEG channel i at time t. We assume three possible states: pre-seizure baseline (\(X^t_i = 0\)), seizure propagation (\(X^t_i = 1\)), and post-seizure baseline (\(X^t_i = 2\)). The corresponding observed “emission” feature vectors \(Y^t_i\) are continuous statistics computed from time window t of the EEG channel i. For convenience, we also define the ensemble variables \(\mathbf {X}^t \triangleq \left[ X^t_1, \dots , X^t_N \right] ^T\) where N is the number of electrodes. Given the EEG observations, our goal is to infer the latent seizure state for each chain at all times.
2.1 Model Formulation and Inference
Figure 1(b) shows the coupling between electrodes of the 10/20 international system [9]. We define the aunts \(au(\cdot )\) of a given node as the set of electrodes connected to it in Fig. 1(b). The joint distribution of \(\mathbf {X}\) and \(\mathbf {Y}\) factorizes into transition priors that depend on both a channel’s own previous state and those of its aunts \(P(X^t_i \mid \mathbf {X}^{t-1}_{au(i) \bigcup i})\), and emission likelihoods \(P(Y^t_i \mid X^t_i)\) as in Eq. (1). For simplicity we assume that all recordings begin in a non-seizure state \((X^0_i=0 \forall i)\).
Note that the observed emissions are conditionally independent given the latent states. Below, we detail the model formulation and inference algorithm.

(a) Graphical model depicting a three chain CHMM. Observed nodes are shaded gray, while latent nodes are shown in white. (b) EEG channels in the 10/20 international system [9], cross hemispheric (red) and neighboring (blue) channel connections. A seizure propagates from the red, to the orange, and finally yellow shaded electrodes.
Coupled State Transitions. The distribution over state vectors \(\mathbf {X}^t\) forms a first order Markov chain. This distribution further factorizes into products of transition distributions of individual chains \(P(\mathbf {X}^t \mid \mathbf {X}^{t-1} ) = \prod _{i=1}^N P(X^t_i \mid \mathbf {X}^{t-1}_{au(i) \bigcup i } )\). We encode these chainwise transition probabilities using time inhomogenous transition matrices as shown in Eq. (2). This structure ensures each channel begins in a non-seizure baseline state, transitions into an active seizure state, and transitions into a post-seizure state.
The transition matrix \(A^t_i\) is governed by neighboring and contralateral EEG channels to capture the main modes of seizure propagation, as shown in Fig. 1(b). Let \(\eta ^t_i\) be the number of aunts in the seizure state in the previous timestep. We model the transition probabilities into and out of the seizure state via logistic regression functions of \(\eta ^t_i\) as shown in Eq. (3). Parameters \(\lbrace \rho _0, \phi _0 \rbrace \) control the base onset and offset rates while \(\lbrace \rho _1, \phi _1 \rbrace \) control the effects of a channel’s aunts.
Emission Likelihood. We use a Gaussian Mixture Model (GMM) to describe the emissions \(Y^t_i\) of each chain. Let \(C^t_i\) be the mixture from which \(Y^t_i\) was generated. Let \(\pi ^k_{ij}\) be the prior probability of mixture component j when \(X^t_i = k\) for \(k=0,1,2\). The joint distribution over \(Y^t_i\) and \(C^t_i\) can be expressed as follows
Effectively, the emission distributions for all observed variables share the same mean parameters \(\mu _{ij}\) and covariance parameters \(\varSigma _{ij}\), but use different mixture weights based on the latent seizure state k. We tie weights for both pre- and post-seizure states, i.e. \(\pi _{ij}^0 = \pi _{ij}^2\) for all channels i and mixture components j. The data likelihood \(P(Y^t_i \mid X^t_i)\) can be computed by marginalizing over j.
Approximate Inference Using Variational EM. Exact inference for the CHMM is intractable due to the coupled state transitions. Therefore we develop a structured variational algorithm [10], in which we approximate the posterior distribution over \(\mathbf {X}\) as a set of N independent HMM chains:
As seen in Eq. (5), each approximating chain includes a normalizing constant \(Z_{Q_i}\), a transition term \(T^t_i(X^t_i \mid X^{t-1}_i)\), and an emission term \(E^t_i(X^t_i)\).
The transition distribution \(T^t_i(X^t_i \mid X^{t-1}_i)\) is encoded by a state transition matrix \(\tilde{A}^t_i\) which mimics the structure of Eq. (2). Here \(\tilde{g}^t_i\) and \(\tilde{h}^t_i\) are variational transition parameters analagous to the original transition parameters \(g^t_i\) and \(h^t_i\).
In contrast to Eq. (6), the emission distribution \(E^t_i(X^t_i)\) weighs the contribution of the observed data \(Y^t_i\) through variational parameters \(\tilde{l}^t_{i0}\) and \(\tilde{l}^t_{i1}\). Thus \(E^t_i(X^t_i=0, 2) = \tilde{l}^t_{i0}\) and \(E^t_i(X^t_i = 1) = \tilde{l}^t_{i1}\).
We learn variational parameters for each chain by minimizing the free energy of the approximation. We perform this minimization by decoupling the free energy into expectations over a single channel and expectations over the remaining channels. The index “\(-i\)” in Eq. (7) denotes the set of channels excluding i.
Notice that the last line of Eq. (7) does not depend on the parameters of chain i, allowing a natural fixed point iteration over the parameters of a single chain while holding all other chains constant. This minimization fixes the variational parameters \(\tilde{l}^t_i\) equal to the GMM likelihood of the observed data:
The updates for the variational transition parameters form logistic regressions based on the expected value of the original activations.
Once the variational parameters have been computed, the approximating distribution takes the form of an HMM where the \(\tilde{l}\) parameters capture the likelihood of the data under each latent state. We can use the forward-backward algorithm [10] to compute the expected latent states \(E_Q[X^t_i]\), the expected state transitions, and the expected number of aunts in the seizure state \(E_Q[\eta ^t_i]\).
Learning the Model Parameters. We use the expected values of the latent states and mixture components to update the transition parameters \(\lbrace \rho _{i}, \phi _{i} \rbrace \) and the emission parameters \(\lbrace \mu _{ij}, \varSigma _{ij}, \pi ^k_{ij} \rbrace \). Let \(\tau ^t_i(j, k)\) be the expectation that channel i at time t is in state k with mixture j, we can update the emission parameters according to the soft counts of the occurrence of each mixture.
The update for the transition parameters \(\lbrace \rho _i, \phi _i \rbrace \) takes the form of a weighted logistic regression. We regress the expected \(\eta ^t_i\) onto the expected transitions for each chain and use Newton’s method to find the optimal transition parameters.
Implementation Details. We initialize our model by training the GMM emission distributions based on the expert annotations of seizure intervals. 3 emission mixtures resulted in a reasonable compromise between sensitivity and specificity. Transition parameters \(\rho _0\), \(\rho _1\), \(\phi _0\), and \(\phi _1\) were initialized to −7, 2, −3, and 0, respectively. This corresponds to expected seizures every 13 min lasting 15 s, channels turning on with a 7 fold increase per aunt node, and no cross channel influence for offset. Our EM proceedure is performed in an unsupervised fashion without further use of the labels. Model parameters are updated during the M-step of the EM algorithm. During inference, channels are updated sequentially until the scaled difference in \(\mathcal {FE}\) converges to less than \(10^{-4}\).
2.2 Baseline Comparison
We compare our model to three alternative classification schemes. The first approach is to train a logistic regression function to distinguish between baseline and seizure intervals based on a linear combination of the EEG features. The second approach uses kernel support vector machines (SVMs) to learn a possibly nonlinear decision boundary in the EEG feature space that maximally separates the baseline and seizure conditions. Here we rely on a polynomial kernel. SVM classifiers have been used extensively for seizure detection [2, 5, 6]. Finally we consider a GMM hypothesis testing scenario. This method trains GMMs for seizure and non-seizure states and classifies based on the ratio of the likelihoods under each GMM, roughly equating to our model with no transition prior.
3 Experimental Results
3.1 Data and Preprocessing
Our EEG data was recorded as part of routine clinical evaluation in the EMU of the Johns Hopkins Hospital. Our dataset consists of 90 seizures recordings from 15 patients with as much as 10 min of baseline before and after the seizure. Recordings were sampled at 200 Hz. We rely on expert clinical annotations denoting the seizure onset and offset to validate the performance of each method.
For preprocessing, each EEG channel was bandpass filtered through sequential application of fourth order Butterworth high and low pass filters at 1.6 Hz and 50 Hz respectively. This filtering mirrored clinical preprocessing practice for removing DC trends and high frequency components with no clinical relevance. In addition, a second order notch filter with \(Q=20\) was applied at 60 Hz to the EEG recordings to remove any remaining effect of the power supply.
We considered two emission features for analysis computed from channels in common reference: the sum of spectral coefficients in brain wave frequency bands and the log line length. Features were computed on windows of 1 s with 250 ms overlap. For spectral features, a short time Fourier transform was taken after the application of a Tukey window with shape parameter 0.25. The magnitudes of the STFT coefficients corresponding to frequencies in the theta (1–4 Hz), delta (4–8 Hz), alpha (8–13 Hz), and beta (13–30 Hz) bands were summed and the logarithm was taken, resulting in a length four feature vector. The log line length was computed as the logarithm of the sum of the absolute difference between successive samples i.e. given a signal s of length T, \(\log L = \log \left( \sum _{i=0}^{T-1} |s(i+1) - s(i) |\right) \).
3.2 Seizure Detection Performance
We use a 5 fold cross validation strategy for evaluation. Four folds were used to train each model and detection was evaluated on the held-out fold. Each recording was randomly assigned to a fold independently of patient. For our model, the training phase was used to learn the emission and transition parameters. Table 1 summarizes the performance for each classifier based on the average accuracy of the testing fold. The sensitivity (TPR) and specificity (TNR) denote the prediction accuracy for seizure and non-seizure frames, respectively, computed across all channels. For the probabilistic classifiers (i.e. logistic regression, GMM, and CHMM), these rates are weighted by the posterior confidence of the classifier.

Detection results for the CHMM. Top row: Estimated posterior probability of the latent seizure state for two epilepsy patients. White corresponds to pre- and post-seizure baseline while violet indicates seizure states. EEG channels corresponding to 10/20 system [9] channel locations are on the y axis. The expert identified seizure region is denoted by the dashed black lines. (a) shows the models ability to accurately classify seizures across the whole brain and (b) shows the outward spread of a right temporal lobe seizure. Bottom row: temporal evolution of the seizure depicted in (b).

Detection results on Patient 1 for the three baseline methods. These algorithms place much lower posterior confidence in seizure intervals than the CHMM.
The transition prior allows our CHMM to place more confidence in contiguous regions exhibiting seizure-like activity. Figure 2(a) shows an example of our classifier correctly classifying the majority of the seizure across all channels. However, this confidence comes with a reduction in specificity, as the classifier tends to associate post-seizure spectral artifacts with seizure as shown in Fig. 2(b). In future work we will investigate feature selection methods to combat this issue. Figure 2(c) shows the evolution of a focal right temporal seizure, which indicates our model’s potential to localize epileptic activity on the scalp. This localization is highly relevant to clinical management of epilepsy.
Due to the heterogeneity of seizure presentations across patients, our baselines fail to perform well as shown in Fig. 3. The logistic regression and GMM correctly classify portions of seizure intervals but lack consistency. The GMM exhibits more confidence in classifying seizures than its probabilistic linear counterpart. The SVM performs poorly due to the inseperability of the EEG features in our noisy clinical dataset.
4 Conclusion
We have presented a novel method for epileptic seizure detection based on a CHMM model. At a high level, we directly model seizure spreading by allowing the state of neighboring and symmetric EEG channels to influence the transition probabilities for a given channel. We have validated our approach on clinical EEG data from 15 unique patients. Our model outperforms three baseline approaches which perform classification on a framewise basis. By incorporating a transition prior that includes spatial and temporal contiguity to seizure regions we are able to better classify seizure intervals within EEG recordings.
References
Miller, J.W., Goodkin, H.P.: Epilepsy. Wiley, Hoboken (2014)
Acharya, U.R., et al.: Automated diagnosis of epileptic EEG using entropies. Biomed. Signal Process. Control. 7(4), 401–408 (2012)
Güler, N.F., et al.: Recurrent neural networks employing Lyapunov exponents for EEG signals classification. Expert. Syst. Appl. 29(3), 506–514 (2005)
Zandi, A.S., et al.: Automated real-time epileptic seizure detection in scalp EEG recordings using an algorithm based on wavelet packet transform. IEEE Trans. Biomed. Eng. 57(7), 1639–1651 (2010)
Hunyadi, B., et al.: Incorporating structural information from the multichannel EEG improves patient-specific seizure detection. Clin. Neurophysiol. 123(12), 2352–2361 (2012)
Shoeb, A.H., Guttag, J.V.: Application of machine learning to epileptic seizure detection. In: International Conference on Machine Learning, pp. 975–982 (2010)
Baldassano, S., et al.: A novel seizure detection algorithm informed by hidden Markov model event states. J. Neural Eng. 13(3), 036011 (2016)
Brand, M., Oliver, N., Pentland, A.: Coupled hidden Markov models for complex action recognition. In: Proceedings of the 1997 IEEE Computer Society Conference on Computer vision and pattern recognition, pp. 994–999. IEEE (1997)
Jurcak, V., et al.: 10/20, 10/10, and 10/5 systems revisited: their validity as relative head-surface-based positioning systems. Neuroimage 34(4), 1600–1611 (2007)
Murphy, K.P.: Machine Learning: A Probabilistic Perspective. The MIT Press, Cambridge (2012)
Acknowledgments
This work was supported by a Johns Hopkins Medical Institute Synergy Award (Joint PI: Venkataraman/Johnson).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Craley, J., Johnson, E., Venkataraman, A. (2018). A Novel Method for Epileptic Seizure Detection Using Coupled Hidden Markov Models. In: Frangi, A., Schnabel, J., Davatzikos, C., Alberola-López, C., Fichtinger, G. (eds) Medical Image Computing and Computer Assisted Intervention – MICCAI 2018. MICCAI 2018. Lecture Notes in Computer Science(), vol 11072. Springer, Cham. https://doi.org/10.1007/978-3-030-00931-1_55
Download citation
DOI: https://doi.org/10.1007/978-3-030-00931-1_55
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-00930-4
Online ISBN: 978-3-030-00931-1
eBook Packages: Computer ScienceComputer Science (R0)