
Abstract
Matrix learning, multiple-view learning, Universum learning, and local learning are four hot spots of present research. Matrix learning aims to design feasible machines to process matrix patterns directly. Multiple-view learning takes pattern information from multiple aspects, i.e., multiple-view information into account. Universum learning can reflect priori knowledge about application domain and improve classification performances. A good local learning approach is important to the finding of local structures and pattern information. Our previous proposed learning machine, double-fold localized multiple matrix learning machine is a one with multiple-view information, local structures, and matrix learning. But this machine does not take Universum learning into account. Thus, this paper proposes a double-fold localized multiple matrix learning machine with Universum (Uni-DLMMLM) so as to improve the performance of a learning machine. Experimental results have validated that Uni-DLMMLM (1) makes full use of the domain knowledge of whole data distribution as well as inherits the advantages of matrix learning; (2) combines Universum learning with matrix learning so as to capture more global knowledge; (3) has a good ability to process different kinds of data sets; (4) has a superior classification performance and leads to a low empirical generation risk bound.















Similar content being viewed by others
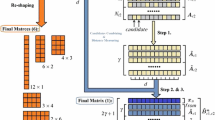
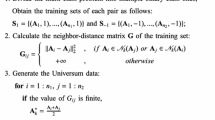

Notes
References
Duda RO, Hart PE, Stork DG (2001) Pattern classification. Wiley-Interscience Press, New York
Vapnik VN (1998) Statistical learning theory. Wiley-Interscience Press, New York
Wang H, Ahuja N (2005) Rank-r approximation of tensors using image-as-matrix representation. IEEE Comp Soc Conf Comp Vision Patt Recogn 2:346–353
Yang J, Zhang D, Frangi AF, Yang J (2004) Two-dimensional PCA: a new approach to appearance-based face representation and recognition. IEEE Trans Patt Anal Mach Intell 26(1):131–137
Li M, Yuan B (2005) 2D-LDA: a novel statistical linear discriminant analysis for image matrix. Patt Recogn Lett 26(5):527–532
Chen SC, Wang Z, Tian YJ (2007) Matrix-pattern-oriented ho-kashyap classifier with regularization learning. Patt Recogn 40(5):1533–1543
Ye JP (2005) Generalized low rank approximations of matrices. Mach Learn 61(1):167–191
Chen SC, Zhu Y, Zhang D, Yang JY (2005) Feature extraction approaches based on matrix pattern: Mat-PCA and Mat-FLDA. Patt Recogn Lett 26(8):1157–1167
Wang Z, Chen SC (2007) New least squares support vector machines based on matrix patterns. Neural Process Lett 26(1):41–56
Yan Y, Wang Q, Ni G, Pan Z, Kong R (2012) One-class support vector machines based on matrix patterns. Int Conf Inform Cyber Comp Eng pp 223–231
Tang Y, Yan PK, Yuan Y, Li XL (2011) Single-image super-resolution via local learning. Int J Mach Learn Cyber 2(1):15–23
Wang Z, Zhu CM, Gao DQ, Chen SC (2013) Three-fold structured classifier design based on matrix pattern. Patt Recogn 46(6):1532–1555
Sen D, Gupta N, Pal SK (2013) Incorporating local image structure in normalized cut based graph partitioning for grouping of pixels. Inform Sci 248:214–238
Yeung DS, Chan PPK, Ng WWY, Lin CM, Liu JNK (2012) Dynamic fusion method using localized generalization error model. Inform Sci 217:1–20
Yeung DS, Chan PPK, Ng WWY (2009) Radial Basis Function network learning using localized generalization error bound. Inform Sci 179(19):3127–3199
Wang Z, Xu J, Gao DQ, Fu Y (2013) Multiple empirical kernel learning based on local information. Neural Comp Appl 23:2113–2120
Wang Z, Chen SC, Gao DQ (2011) A novel multi-view learning developed from single-view patterns. Patt Recogn 44(10–11):2395–2413
Wang Z, Xu J, Chen SC, Gao DQ (2012) Regularized multi-view machine based on response surface technique. Neurocomputing 97:201–213
Zhu CM, Wang Z, Gao DQ, Feng X (2015) Double-fold localized multiple matrixized learning machine. Inform Sci 295:196–220
Xu C, Tao DC, Xu C (2015) Multi-view intact space learning. IEEE Trans Patt Anal Mach Intell 37(12):2531–2544
Luo Y, Tao DC, Wen YG, Ramamohanarao K, Xu C (2015) Tensor canonical correlation analysis for multi-view dimension reduction. IEEE Trans Know Data Eng 27(11):3111–3124
Zhang LF, Zhang Q, Zhang LP, Tao DC, Huang X, Du B (2015) Ensemble manifold regularized sparse low-rank approximation for multiview feature embedding. Patt Recogn 48(10):3102–3112
Vapnik V, Kotz S (1982) Estimation of dependences based on empirical data. Springer
Cherkassky V, Dai WY (2009) Empirical Study of the Universum SVM learning for high-dimensional data. Lect Notes Comp Sci 5768:932–941
Liu DL, Tian YJ, Bie RF, Shi Y (2014) Self-Universum support vector machine. Person Ubiquitous Comp 18:1813–1819
Chen S, Zhang CS (2009) Selecting informative universum sample for semi-supervised learning. Int Jont Conf Art Intell pp 1016–1021
Zhang D, Wang J, Si L (2001) Document clustering with universum. Int Conf Res Dev Inform Retr pp 873–882
Peng B, Qian G, Ma YQ (2008) View-invariant pose recognition using multilinear analysis and the universum. Adv Visual Comp 5359:581–591
Shen C, Wang P, Shen F, Wang H (2012) Uboost: boosting with the universum. IEEE Trans Patt Anal Mach Intell 34(4):825–832
Chen XH, Chen SC, Xue H (2012) Universum linear discriminant analysis. Electr Lett 48(22):1407–1409
Wang Z, Zhu YJ, Liu WW, Chen ZH, Gao DQ (2014) Multi-view learning with universum. Know Based Syst 70:376–391
Leski J (2003) Ho-kashyap classifier with generalization control. Patt Recogn Lett 24(14):2281–2290
Blake CL, Newman DJ, Hettich S, Merz CJ (2012) UCI repository of machine learning databases
Wang N, Wang J, Yeung DY (2013) Online robust non-negative dictionary learning for visual tracking. Int Conf Comp Vision
Wang N, Yeung DY (2013) Learning a deep compact image representation for visual tracking. Neural Inform Process Syst
Milgram J, Cheriet M, Sabourin R (2013) “One Against One” or “One Against All”: Which one is better for handwriting recognition with SVMs?. In: Tenth International Workshop on Frontiers in Handwriting Recognition
Debnath R, Takahide N, Takahashi H (2004) A decision based one-against-one method for multi-class support vector machine. Patt Anal Appl 7(2):164–175
Hsu CW, Lin CJ (2002) A comparison of methods for multiclass support vector machines. IEEE Trans Neural Networks 13(2):415–425
Cortes C, Vapnik V (1995) Support vector machine. Mach Learn 20(3):273–297
Cawley GC, Talbot NLC (2010) On over-fitting in model selection and subsequent selection bias in performance evaluation. J Mach Learn Res 11:2079–2107
Bartlett P, Boucheron S, Lugosi G (2002) Model selection and error estimation. Mach Learn 48:85–113
Koltchinskii V (2001) Rademacher penalties and structural risk minimization. IEEE Trans Inform Theory 47(5):1902–1914
Koltchinskii V, Panchenko D (2000) Rademacher processes and bounding the risk of function learning. High Dimens Probab II:443–459
Mendelson S (2002) Rademacher averages and phase transitions in glivenko-cantelli classes. IEEE Trans Inform Theory 48(1):251–263
Wang Z, Zhu CM, Niu ZX, Gao DQ, Feng X (2014) Multi-kernel classification machine with reduced complexity. Know Based Syst 65:83–95
Demsar J (2006) Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res 7:1–30
Acknowledgments
This work was supported by Shanghai Natural Science Foundation under grant number 16ZR1414500, and the author would like to thank their supports.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
To minimize Eq. (5), we adopt a two-step alternating optimization algorithm. Further, for convenience and simplification, we use \(\mathcal {Q}(i,p)=\varphi _{i}g^p(A_i^p)-1-b_i^p\) and \(\mathcal {Q^{*}}(j,p)=g^p({A_j^{*}}^p)-1-{b_j^{*}}^p\) to denote some parts of Eq. (5). Now the details of this algorithm is given below.
First, we fix each \(\eta _q(A_i^q)\), and then the gradients of Eq. (5) with respect to \({u^p}, {\tilde{v}^p}\), \(v_0^p\), \({b^p}\), and \({b^{*}}^p\) are given below.
where
\(I_{N\times 1}\) is an identity matrix with the size of \(N\times 1\) and \(I^{*}_{L\times 1}\) is an identity matrix with the size of \(L\times 1\)
Then we make \(\frac{\partial {L}}{\partial {u^p}}\), \(\frac{\partial {L}}{\partial {\tilde{v}^p}}\), and \(\frac{\partial {L}}{\partial {v_0^p}}\) be zeros to get the results of the parameters \(u^p\), \(\tilde{v}^p\), and \(v_0^p\) below.
Here, U(i), W(i), \(U(j)^{*}\), and \(W(j)^{*}\) are used to simplify Eqs. (21) and (22), namely,
Then we let
and
then at k-th iteration, the error vector with p-th matrix, i.e., \(e^{p}(k)\) and \({e^{*}}^{p}(k)\) can be computed by Eqs. (30) and (31).
The margin \(b^p\) and \({b^{*}}^p\) are given below.
where \(b^{p}(1)\ge 0 _{N\times 1}\) and \({b^{*}}^{p}(1)\ge 0 _{N\times 1}\). The learning rates are \(0<\rho <1\) and \(0<\rho ^{*}<1\). \({D^{*}}^p(k)\), \({b^{*}}^{p}(k)\), \(D^p(k)\), \(b^{p}(k)\), \(u^{p}(k)\), \(\tilde{v}^p(k)\), and \(v_0^{p}(k)\) represent the values of \({D^{*}}^p\), \({b^{*}}^{p}\), \(D^p\), \(b^{p}\), \(u^{p}\), \(\tilde{v}^p\), and \(v_0^{p}\) at k-th iteration, respectively. For ones of Universum patterns, they have the same meaning.
Second, we fix each \(u^p\), \(\tilde{v}^p\), \(v_0^{p}\), \(b^p\), \({b^{*}}^{p}\) and calculate the gradients of Eq. (5) with respect to \(h_{q1}\), \(h_{q2}\), and \(h_{q0}\) are given below. Here \(p=1,2,\ldots ,M\) and \(q=1,2,\ldots ,M\).
where \(s=0,1,2\). To simplify this equation, we give some other equations below.
and
Then, we need to update the parameters of \(\eta _q(A_i^q)\) after k-th iteration, i.e.,
Here, \(\mu\) is the attenuation coefficient which is a constant in each iteration and \(h_{qs}^{(k)}\) represents the \(h_{qs}\) at k-th iteration. In order to compute \(\frac{\partial {L}}{\partial {h_{qs}^{(k)}}}\), we replace \(h_{qs}\) in Eqs. (34)–(46) with \(h_{qs}^{(k)}\). Finally, we update the \({u^p}\), \(\tilde{v}^p\), \(v_0^{p}\), \({b^p}\), \({{b^{*}}^p}\), \(h_{q1}\), \(h_{q2}\), and \(h_{q0}\), then we can compute Eq. (5). In practice, the termination criterion is given in the following equation.
where L(k) represents the value of Eq. (5) at k-th iteration and \(\parallel {.}\parallel _2\) still represents the 2-norm operation.
If Eq. (48) is satisfied, we can stop the procedure and get the optimal parameters.
Rights and permissions
About this article

Cite this article
Zhu, C. Double-fold localized multiple matrix learning machine with Universum. Pattern Anal Applic 20, 1091–1118 (2017). https://doi.org/10.1007/s10044-016-0548-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10044-016-0548-9