
Abstract
We investigate the effect of ballot order on the outcomes of California city council and school board elections. Candidates listed first win office between four and five percentage points more often than expected absent order effects. This first candidate advantage is larger in races with more candidates and for higher quality candidates. The first candidate advantage is similar across contexts: the magnitude of the effect is not statistically distinguishable in city council and in school board elections, in races with and without an open seat, and in races consolidated and not consolidated with statewide general elections. Standard satisficing models cannot fully explain ballot order effects in our dataset of multi-winner elections.



Similar content being viewed by others

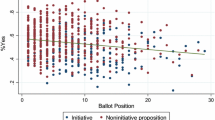

Notes
Miller and Krosnick (1998) criticize most of the 28 papers on ballot order effects that they survey for using non-random variation in candidates’ positions that is potentially correlated with pre-existing difference in the support for candidates.
For example, Ho and Imai’s (2008) model of costly sequential ballot search results in voters that endogenously satisfice because the expected benefit of evaluating the next candidate on the ballot is smaller than the cognitive cost of doing so.
Alphabetical ordering is problematic for identifying the causal effect of ballot order on electoral outcomes because candidates with certain last names may also be likely to receive more votes than others (Miller and Krosnick 1998).
In contrast, the ordering of candidates is rotated across assembly districts in elections for federal and state offices.
These races are non-partisan. Previous work generally finds larger ballot order effects in non-partisan races, although Meredith and Salant (2007) find that the first candidate advantage is similar in partisan and non-partisan Ohio city council elections.
We verified that candidates’ constructed ballot positions matched the actual ballot positions in San Bernardino County’s Statement of the Votes 97% of the time. Inconsistencies mostly resulted from errors in the CEDA data about which portion of the name constituted the last name.
We observe 8,348 competitive city council, community college, and school district races. We partition those races according to “types”, where two races are of the same type if the number of candidates competing for office and the number of winners are identical in both (e.g. in both races seven candidates compete for two spots). We restrict attention to election types in which there are 75 or more races for estimation purposes. In the 502 excluded elections, we find that candidates listed first win 8.2 percentage points (s.e. 2.5 percentage points) more races than expected absent order effects.
There is some overlap here because candidate listed second in two candidate elections are also listed last.
We first calculate the absolute value of the difference between the actual number of incumbents in each ballot position and the expected number of incumbents in each ballot position if incumbents were uniformly distributed across ballot positions. We then compare this actual value to 1,000 simulated values generated by randomly assigning incumbents to ballot positions. We find that the actual value falls in the 48th percentile of the simulated distribution, which is consistent with the alphabetical lottery approximating the random assignment of candidates to ballot positions.
Because the effect of order on the probability of winning office varies by election type, \( {\theta }_{p} \) is defined conditional on the observed percentages of election types.
In an election with an even number (N) of candidates, the median ballot position is defined as N/2 + 1.
Vote share is defined as the number of votes received by a candidate multiplied by the number of winners in the race divided by the total number of votes cast in the race.
This normalization accounts for the fact that an additional vote received by the first candidate comes at the expense of a candidate listed in another ballot position. We account for this mechanical relationship in vote totals across positions by multiplying the difference between the votes shares of candidates listed first and candidates not listed first by (N − 1)/N (e.g., 4/5 * 2.85 = 2.28).
Elections with two candidates and one winner are excluded from this analysis because the effects are symmetric by construction. That is, the difference between the 90th percentile vote shares in the first and second ballot positions is also the difference between the 10th percentile vote shares in the first and second ballot position.
Note that the differences we observe with respect to the number of candidates cannot necessarily be interpreted causally because other features of a race may also both affect the magnitude of order effects and be related to the number of candidates in the race.
This example also highlights the difficulty of inferring the distribution of votes cast without observing individual ballot data. If we observe that 100 ballots were not cast in a 2-winner election, it could result from 50 voters not casting either of their votes or 100 voters not casting one of their votes.
It is estimated that the cost of ballot rotation in the 1994 Alaska primary and general elections was $64,024 (see Sonneman v. State of Alaska, 969 P 2d 632), which is about $137 per precinct. In California, for example, there are more than 24,000 precincts.
References
Alvarez, R. M., Sinclair, B., & Hasen, R. L. (2005). How much is enough? The “ballot order effect” and the use of social science research in election law disputes. Election Law Journal, 5(1), 40–56.
Bendor, J. (2003). Herbert A. Simon: Political scientist. Annual Review of Political Science, 6, 433–471.
Brockington, D. (2003). A low information theory of ballot position effect. Political Behavior, 25(1), 1–27.
Hill, S. (2010). Changing composition and changing allegiance in American elections. Ph.D. Thesis, University of California, Los Angeles.
Ho, D. E., & Imai, K. (2006). Randomization inference with natural experiments: An analysis of ballot effects in the 2003 California recall election. Journal of the American Statistical Association, 101(475), 888–900.
Ho, D. E., & Imai, K. (2008). Estimating casual effects of ballot order from a randomized natural experiment: California alphabet lottery, 1978–2002. Public Opinion Quarterly, 72(2), 216–240.
Hogarth, R. M., & Einhorn, H. J. (1992). Order effects in belief updating: The belief adjustment model. Cognitive Psychology, 24(1), 1–55.
King, A., & Leigh, A. (2009). Are ballot order effects heterogeneous? Social Science Quarterly, 90(1), 71–87.
Koppell, J. G., & Steen, J. A. (2004). The effects of ballot position on election outcomes. Journal of Politics, 66(1), 267–281.
Krosnick, J. A., & Alwin, D. F. (1987). An evaluation of a cognitive theory of response-order effects in survey measurement. Public Opinion Quarterly, 51(2), 201–219.
Krosnick, J. A., Miller, J. M., & Tichy, M. P. (2004). An unrecognized need for ballot reform: The effects of candidate name order on election outcomes. In A. N. Crigler, M. R. Just, & E. J. McCaffery (Eds.), Rethinking the vote: The politics and prospects of American election reform (pp. 51–73). New York: Oxford University Press.
Meredith, M. & Salant Y. (2007). Causes and consequences of ballot order effects. SIEPR Discussion Paper No. 0629.
Miller, J. M., & Krosnick, J. A. (1998). The impact of candidate name order on election outcomes. Public Opinion Quarterly, 62(3), 291–330.
Simon, H. (1955). A behavior model of rational choice. Quarterly Journal of Economics, 69(1), 99–118.
Thompson, A. M. (1993). Appendix: Serial position effects in the psychological literature. In Dunne, B. J., Dobyns, Y. H., & Jahn, R. G. Series position effects in random event generator experiments. Journal of Scientific Exploration, 8(2), 197–215.
Acknowledgments
We thank Jon Bendor, Jonah Berger, Michael Hanmer, Daniel Kessler, Peter Reiss, and seminar participants at MIT, Stanford, and the 2008 American Political Science Association Annual Meeting for comments and suggestions. We also thank Seth Hill for providing us with the individual-level ballot data. Salant acknowledges the financial support of the Stanford Institute for Economic Policy Research, the Leonard W. and Shirley R. Ely Fellowship. Replication data is available at http://www.sas.upenn.edu/~marcmere/replicationdata/BallotOrderReplicationData.zip.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Maximum Likelihood Estimation
We wish to estimate the coefficients λ, δ, γ, and β using maximum likelihood in the model \( {\text{a}}_{{{\text{p}},{\text{j}}}} = \alpha_{{{\text{p}},{\text{t}}({\text{j}})}} + {\text{Inc}}_{{{\text{p}},{\text{j}}}} \lambda_{{{\text{t}}({\text{j}})}} + \varepsilon_{{{\text{p}},{\text{j}}}} \) where \( \alpha_{{{\text{p}},{\text{t}}({\text{j}})}} = \delta_{{{\text{p}},{\text{t}}({\text{j}})}} + {\text{Inc}}_{{{\text{p}},{\text{j}}}} \gamma_{{{\text{p}},{\text{t}}({\text{j}})}} + X_{j} \beta_{{{\text{p}},{\text{t}}({\text{j}})}} \).
Assume that the εp,j’s are drawn from a logistic distribution. Then the probability that the candidate in position p is the most attractive candidate in race j is \( \Pr_{j} (p = 1) = \frac{{\exp (\alpha_{{{\text{p}},{\text{t}}({\text{j}})}} + {\text{Inc}}_{{{\text{p}},{\text{j}}}} \lambda_{{{\text{t}}({\text{j}})}} ) }}{{\sum\nolimits_{i} {\exp (\alpha_{{{\text{i}},{\text{t}}({\text{j}})}} + {\text{Inc}}_{{{\text{i}},{\text{j}}}} \lambda_{{{\text{t}}({\text{j}})}} )} }} \). Similarly, the probability that the candidate in position p is the second most attractive candidate given that the candidate in position p′ is the most attractive candidate is \( \Pr_{j} (p = 2|p^{\prime} = 1) = \frac{{\exp (\alpha_{{{\text{p}},{\text{t}}({\text{j}})}} + {\text{Inc}}_{{{\text{p}},{\text{j}}}} \lambda_{{{\text{t}}({\text{j}})}} )}}{{\sum\nolimits_{{i \ne p^{\prime}}} {\exp (\alpha_{{{\text{i}},{\text{t}}({\text{j}})}} + {\text{Inc}}_{{{\text{i}},{\text{j}}}} \lambda_{{{\text{t}}({\text{j}})}} )} }} \). Finally, the probability that the candidate in position p is the third most attractive candidate given that the candidates in positions p′ and p″ are the two most attractive candidates is \( \Pr_{j} (p = 3|p^{\prime}, \, p^{\prime\prime} = 1,2) = \frac{{\exp (\alpha_{{{\text{p}},{\text{t}}({\text{j}})}} + {\text{Inc}}_{{{\text{p}},{\text{j}}}} \lambda_{{{\text{t}}({\text{j}})}} )}}{{\sum\nolimits_{{i \ne p^{\prime},p^{\prime\prime}}} {\exp (\alpha_{{{\text{i}},{\text{t}}({\text{j}})}} + {\text{Inc}}_{{{\text{i}},{\text{j}}}} \lambda_{{{\text{t}}({\text{j}})}} )} }} \).
Let Yj = [Y1,j,…, YNj,j] denote the vector of observed outcomes in race j where Yi,j = 1 if the candidate in position i wins office and Yi,j = 0 otherwise. We construct the likelihood function L(δ, λ, γ, β|Yj) as follows.
In a one winner race, \( {\text{L}}(\delta ,\lambda ,\gamma ,\beta |{\text{Y}}_{\text{j}} ) = \prod\nolimits_{i = 1}^{{N_{j} }} {Pr_{j} (i = 1)^{{Y_{i,j} }} } \) is the likelihood that the winning candidate is the most attractive candidate. In a two-winner race, L(δ, λ, γ, β|Yj) is the likelihood that the two winning candidates are the two most attractive candidates. By the definition of conditional probability, the probability that the candidates in position p and p′ are the most attractive and second most attractive candidates respectively in race j, \( Pr_{j} (p = 1,p^{\prime} = 2) \), is equal to \( Pr_{j} (p^{\prime} = 2|p = 1)Pr_{j} (p = 1) \). Thus, \( {\text{L}}(\delta ,\lambda ,\gamma ,\beta |Y_{j} ) = \prod\nolimits_{i = 1}^{{N_{j} - 1}} {\prod\nolimits_{{i^{\prime} = i + 1}}^{{N_{j} }} {(Pr_{j} (i = 1)Pr_{j} (i^{\prime} = 2|i = 1) + Pr_{j} (i^{\prime} = 2)Pr_{j} (i = 1|i = 2))}^{{Y_{i,j} Y_{{i^{\prime},j}} }} } \). Similarly, in a three-winner race, L(δ, λ, γ, β|Yj) is the likelihood that the three winning candidates are the three most attractive candidates. Again by the definition of conditional probability \( Pr_{j} (p = 1,p^{\prime} = 2,p^{\prime\prime} = 3) \) is equal to \( Pr_{j} (p^{\prime\prime} = 3|p^{\prime} = 2,p = 1)Pr_{j} (p^{\prime} = 2|p = 1)Pr_{j} (p = 1) \). Thus,
We solve for our parameter estimates \( \hat{\delta },\hat{\lambda },\hat{\gamma },\;{\text{and}}\;\hat{\beta } \) by finding the values that maximize \( \prod\nolimits_{j = 1}^{T} {L\left( {\delta ,\lambda ,\gamma ,\beta |Y_{j} } \right)} \).
Appendix 2: Constructing Counterfactuals
We illustrate how the Maximum Likelihood estimates are used to construct implied treatment effects in races with one winner and three candidates. Let Cp,p′,j be the counterfactual probability that the candidate who is actually listed in position p wins office in race j were he listed in position p’. Given the observed incumbency status of the three candidates, Inc1,j, Inc2,j, and Inc3,j and race-level covariates, X j , the counterfactual probability of winning of the candidate actually listed in position 1 in race j where he listed in position 1 is \( {\text{C}}_{{ 1, 1,{\text{j}}}} = \frac{{{ \exp }(\widehat{{{\updelta}}}_{{1,{\text{t}}\left( {\text{j}} \right)}} + {\text{Inc}}_{{1,{\text{j}}}} (\widehat{{{\uplambda}}}_{{{\text{t}}\left( {\text{j}} \right)}} + \widehat{{{\upgamma}}}_{{1,{\text{t}}\left( {\text{j}} \right)}} ) + {\text{X}}_{\text{j}} \widehat{{{\upbeta}}}_{{1,{\text{t}}\left( {\text{j}} \right)}} )}}{{\exp \left( {\widehat{{{\updelta}}}_{{1,{\text{t}}\left( {\text{j}} \right)}} + {\text{Inc}}_{{1,{\text{j}}}} \left( {\widehat{{{\uplambda}}}_{{{\text{t}}\left( {\text{j}} \right)}} + \widehat{{{\upgamma}}}_{{1,{\text{t}}\left( {\text{j}} \right)}} } \right) + {\text{X}}_{\text{j}} \widehat{{{\upbeta}}}_{{1,{\text{t}}\left( {\text{j}} \right)}} } \right) + \exp \left( {\widehat{{{\updelta}}}_{{2,{\text{t}}\left( {\text{j}} \right)}} + {\text{Inc}}_{{2,{\text{j}}}} \left( {\widehat{{{\uplambda}}}_{{{\text{t}}\left( {\text{j}} \right)}} + \widehat{{{\upgamma}}}_{{2,{\text{t}}\left( {\text{j}} \right)}} } \right) + {\text{X}}_{\text{j}} \widehat{{{\upbeta}}}_{{2,{\text{t}}\left( {\text{j}} \right)}} } \right) + \exp \left( {{\text{Inc}}_{{3,{\text{j}}}} \widehat{{{\uplambda}}}_{{{\text{t}}\left( {\text{j}} \right)}} } \right)}} \).
If we rotate the candidate actually listed first to the second position, the candidate actually listed second to the third position, and the candidate actually listed third to the first position, then \( {\text{C}}_{{ 1, 2,{\text{j}}}} = \frac{{{ \exp }(\widehat{{{\updelta}}}_{{2,{\text{t}}\left( {\text{j}} \right)}} + {\text{Inc}}_{{1,{\text{j}}}} (\widehat{{{\uplambda}}}_{{{\text{t}}\left( {\text{j}} \right)}} + \widehat{{{\upgamma}}}_{{2,{\text{t}}\left( {\text{j}} \right)}} ) + {\text{X}}_{\text{j}} \widehat{{{\upbeta}}}_{{2,{\text{t}}\left( {\text{j}} \right)}} )}}{{\exp \left( {\widehat{{{\updelta}}}_{{1,{\text{t}}\left( {\text{j}} \right)}} + {\text{Inc}}_{{3,{\text{j}}}} \left( {\widehat{{{\uplambda}}}_{{{\text{t}}\left( {\text{j}} \right)}} + \widehat{{{\upgamma}}}_{{1,{\text{t}}\left( {\text{j}} \right)}} } \right) + {\text{X}}_{\text{j}} \widehat{{{\upbeta}}}_{{1,{\text{t}}\left( {\text{j}} \right)}} } \right) + \exp \left( {\widehat{{{\updelta}}}_{{2,{\text{t}}\left( {\text{j}} \right)}} + {\text{Inc}}_{{1,{\text{j}}}} \left( {\widehat{{{\uplambda}}}_{{{\text{t}}\left( {\text{j}} \right)}} + \widehat{{{\upgamma}}}_{{2,{\text{t}}\left( {\text{j}} \right)}} } \right) + {\text{X}}_{\text{j}} \widehat{{{\upbeta}}}_{{2,{\text{t}}\left( {\text{j}} \right)}} } \right) + \exp \left( {{\text{Inc}}_{{2,{\text{j}}}} \widehat{{{\uplambda}}}_{{{\text{t}}\left( {\text{j}} \right)}} } \right)}}. \)
Finally, if we rotate the candidates so that the candidate actually listed first is listed third, the candidate actually listed second is listed first, and the candidate actually listed third is listed second, then \( {\text{C}}_{{ 1, 3,{\text{j}}}} = \frac{{{ \exp }({\text{Inc}}_{{1,{\text{j}}}} \widehat{{{\uplambda}}}_{{{\text{t}}\left( {\text{j}} \right)}} )}}{{\exp \left( {\widehat{{{\updelta}}}_{{1,{\text{t}}\left( {\text{j}} \right)}} + {\text{Inc}}_{{2,{\text{j}}}} \left( {\widehat{{{\uplambda}}}_{{{\text{t}}\left( {\text{j}} \right)}} + \widehat{{{\upgamma}}}_{{1,{\text{t}}\left( {\text{j}} \right)}} } \right) + {\text{X}}_{\text{j}} \widehat{{{\upbeta}}}_{{1,{\text{t}}\left( {\text{j}} \right)}} } \right) + \exp \left( {\widehat{{{\updelta}}}_{{2,{\text{t}}\left( {\text{j}} \right)}} + {\text{Inc}}_{{3,{\text{j}}}} \left( {\widehat{{{\uplambda}}}_{{{\text{t}}\left( {\text{j}} \right)}} + \widehat{{{\upgamma}}}_{{2,{\text{t}}\left( {\text{j}} \right)}} } \right) + {\text{X}}_{\text{j}} \widehat{{{\upbeta}}}_{{2,{\text{t}}\left( {\text{j}} \right)}} } \right) + \exp \left( {{\text{Inc}}_{{1,{\text{j}}}} \widehat{{{\uplambda}}}_{{{\text{t}}\left( {\text{j}} \right)}} } \right)}}. \)
Similar counterfactual probabilities can be constructed for the candidates actually listed in position 2 and position 3 in race j. The estimated treatment effect of being listed first for the candidate actually listed in position p in race j is defined as \( {\text{C}}_{{{\text{p}}, 1,{\text{j}}}} - ({\text{C}}_{{{\text{p}}, 1,{\text{j}}}} + {\text{C}}_{{{\text{p}}, 2,{\text{j}}}} + {\text{C}}_{{{\text{p}}, 3,{\text{j}}}} )/ 3 \).
Appendix 3: Satisficing with a Single Vote
Consider elections with N candidates in which the qualities X1, …, X N of the candidates located in positions 1, …, N are random variables distributed i.i.d. with c.d.f. F(). A representative satisficing voter evaluates the candidates according to the ballot order and chooses the first candidate with quality above his aspiration threshold C. If no candidate is above C, then the voter selects the highest-quality candidate. The probability of choosing the first candidate in this model is:
Similarly, the probabilities of selecting the second and third candidates are:
This implies that the expected difference in the number of winners from the first and second ballot positions is P(1st) − P(2nd) = (1 − F(C))2, while the expected difference in the number of winners from the second and third ballot positions is P(2nd) − P(3rd) = F(C)(1 − F(C))2.
Figure 3 indicates that P(1st) − P(2nd) = 0.069 in elections with two or more winners and losers, and thus F(C) is about 0.74. This implies that the expected difference in the number of winners between the second and third ballot positions should be about three quarters of the difference between the first and second positions. As Fig. 3 indicates, however, the actual difference between the second and third is only one-fifth of the difference between the first and second candidates. Thus, the difference between the first and second candidates is larger than expected even if voters are satisificing with a single vote.
Rights and permissions
About this article
Cite this article
Meredith, M., Salant, Y. On the Causes and Consequences of Ballot Order Effects. Polit Behav 35, 175–197 (2013). https://doi.org/10.1007/s11109-011-9189-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11109-011-9189-2