
Abstract
The iconicity of a Chinese character, or the degree to which it looks like the concept that it represents, has been suggested as affecting the learning and processing of the character. However, previous studies have not provided good empirical information on the iconicity of specific characters. To fill this gap, 40 U.S. adults with no knowledge of Chinese were given an English word or short phrase together with two Chinese characters and were asked which character matched the meaning of the English word. The right and wrong answers had the same number of strokes, and different wrong answers were used for different participants. We examined all 213 simple-structure Chinese characters that occur in textbooks for elementary school children. The overall percentage of correct responses was 53.6%, slightly but significantly higher than would be expected by chance. Using a false discovery rate procedure, we found that 15 of the 213 characters were guessed at a level higher than chance. The proportion of correct responses to each character, which can be taken as an indicator of its degree of iconicity, should be useful to researchers studying Chinese character reading and writing. The full database, showing the proportion of correct guesses and other psycholinguistic variables for each character, can be downloaded from http://brm.psychonomic-journals.org/content/supplemental.
Similar content being viewed by others


In most modern writing systems, the shapes of symbols are not related to the sounds or meanings that they represent. For example, the English word “horse” looks nothing like a horse, so that a reader must know the links between the letters and the sounds for which they stand in order to interpret the word. In Chinese, however, at least some characters may be iconic, in that they look somewhat like what they represent. A number of researchers, as discussed below, have suggested that the iconicity of a Chinese character affects the way in which it is learned and used. However, most studies to date have not been based on empirically derived estimates of iconicity. In the present study, we provide such estimates for 213 characters by determining the extent to which people who do not know Chinese can choose the correct character when given its meaning. The information provided here will be useful in research on the learning and use of Chinese characters.
Before describing our study, it is important to provide some background information about Chinese writing. Many Chinese characters originated from pictures of objects, and as time went by, the characters became more stylized and less pictorial. For example, as Fig. 1 shows, the ancient character for “horse” was recognizable as a picture of an animal. The modern character in the simplified Chinese orthography that has been used since the 1950s in Mainland China, 马 (ma3 in the pinyin Romanization system), is no longer very pictorial. Given that the modern descendants of the early pictographs are so stylized, it is questionable how many pictorial cues remain and how easily they can be used. DeFrancis (1989) claimed that only 1% of Chinese characters contain obvious pictorial cues to their meanings, and Shu, Chen, Anderson, Wu, and Xuan (2003) reported that 8% of characters that appear in the textbooks used by Chinese elementary school students in Beijing and in a number of other areas are pictographs, conveying their meanings through pictorial resemblances to their objects. However, the classification of characters in these studies was not based on empirical data about the degree to which people could recover the meaning from the visual form.

Evolution of several Chinese characters, showing how the characters changed from their earliest known forms to the versions used today in mainland People’s Republic of China
Obtaining objective information about the iconicity of Chinese characters is important for studies that attempt to determine whether users of Chinese treat iconic characters differently from noniconic characters. Chan, Leung, Luo, and Lee (2007) reported faster processing and higher accuracy in a stroke-counting task for characters that they judged to be iconic than for characters that they judged not to be iconic. These researchers, as well as Nguy, Allard, and Bryden (1980), reported data pointing to differences in brain processing for iconic and noniconic characters. However, the groups of characters in these studies were not selected on the basis of empirical estimates of iconicity, making the results difficult to interpret.
Data on iconicity are also important for testing the idea that iconic characters are easier for children to learn than noniconic characters. Shu et al. (2003) suggested that the order in which characters are taught in Chinese elementary schools may have been shaped by a tendency for more iconic characters to be easier to learn. Specifically, these researchers reported that the proportion of pictorial characters decreased from .24 for characters taught in Grade 1 to .07 for characters introduced in Grade 2, and that the proportion became even lower for characters introduced in higher grades. However, Shu et al. did not classify characters on the basis of empirical evidence about the degree to which their visual forms reflected their meanings.
Previous studies have provided information about various properties of Chinese characters, including their semantic and phonetic regularity, frequency, concreteness, familiarity, and age of acquisition. Normative data for these and other characteristics have been collected, often on the basis of judgments by native speakers of Chinese, and these data have been published in several reports (Hao, Shu, Xing, & Li, 2008; Liu, Shu, & Li, 2007; Rickard Liow, Tng, & Lee, 1999; Shu et al., 2003). These databases are useful to the many researchers studying Chinese, but they do not include information about the degree to which characters look like their referents. It is questionable whether Chinese adults could provide valid information about this matter if they were asked to rate iconicity, for they may be influenced by the knowledge that they often have of the characters’ earlier forms. Thus, the few studies that have attempted to provide quantitative information about iconicity have used other methods.
Luk and Bialystok (2005) asked Canadian university students who did not know Chinese to guess the meanings of 20 characters by choosing between two photographs of objects. Luk and Bialystok selected for their study 10 characters that they considered to be iconic and 10 characters that they did not consider to be iconic. Participants chose the correct photograph significantly more than half of the time for all but one of the characters that the researchers considered to be iconic, and participants performed at the level of chance on all but one of the characters that the researchers considered not to be iconic. The results suggested that some Chinese characters retain a degree of iconicity and that researchers’ intuitions about iconicity are often, but not always, accurate. Bialystok and Luk (2007) then used four of the characters from their earlier study in a study that was designed to assess children’s knowledge that the meaning of a character is conveyed by the character itself and not by a picture that happens to be adjacent to the character. Bialystok and Luk reported some evidence that children achieve such knowledge more easily for iconic than for noniconic characters. However, the small number of characters tested in Luk and Bialystok’s guessability study limits the value of that study for other researchers who are interested in selecting iconic and noniconic characters. Another potential weakness of the Luk and Bialystok study stems from its use of photographs. Different photographs of an object might differ in their similarity to the character, such that, for example, a towel pictured hanging from a rack may look more like the character for towel, 巾 jin1, than a picture of a towel crumpled on the floor. The use of photographs thus introduced a potential for bias, as Luk and Bialystok themselves noted. Such problems may be exacerbated by the fact that all participants saw the same distractor photograph for a given character.
Koriat and Levy (1979) reported another attempt to empirically determine the guessability of a small number of Chinese characters. Israeli teenagers and adults who did not know Chinese were asked to determine which character in a pair, such as 好 (hao3) and 坏 (huai4), meant “good” and which meant “bad.” Koriat and Levy reported that the mean proportion of correct responses over the 42 tested pairs was 54.6%, slightly but significantly higher than the 50.0% expected by chance. The data for individual pairs were not reported, however, meaning that the results cannot be used by researchers who are interesting in choosing more and less iconic characters.
In the present study, we attempted to provide information about the iconicity of Chinese characters that will be useful to researchers. We examined the guessability of all 213 simple-structure characters that are required to be explicitly taught to Chinese students in Grades 1–6 according to a set of textbooks used in Beijing and other regions. We chose this set of characters, in part, because Shu et al. (2003) reported data on many of their characteristics. Simple-structure characters are those, such as 马 ma3 “horse,” that can appear both on their own and as components of complex or compound characters such as 妈 ma1 “mother.” Because simple-structure characters are the building blocks of many characters, they are a good place to begin in testing the iconicity of Chinese characters. U.S. university students who did not know Chinese were presented with an English word or short phrase together with two Chinese characters and were asked which character best matched the English word. For example, a participant might be given the word “horse” and asked whether it corresponded to 马 or 水. The wrong answer, 水 shui3 (“water”) in this example, was similar in visual complexity to the correct answer, in that it contained the same number of strokes, three. We matched for stroke count because of the possibility that people might select visually complex characters for concepts that seem to be difficult or complex. By matching in this way, we hoped to ensure that correct guesses would reflect an arrangement of strokes that corresponds in some way to the depicted concept. Our methodology did not involve the use of photographs, and the wrong answers were—to the extent possible given the above constraints—different for different participants. If the visual form of a character contained clues to its meaning, participants should perform above the level expected by random guessing, 50%. The proportion of correct guesses for a character could serve as an indicator of the character’s iconicity.
Method
Participants
A group of 40 students from Washington University in St. Louis (32 female, 8 male; mean age = 19 years, SD = 0.93, range 18–22 years) contributed data and received course credit for their participation. We screened potential participants using a questionnaire in which they were asked whether they had ever learned to read or write any Chinese characters, either in formal situations or informally—for example, from friends or waiters in Chinese restaurants. We eliminated potential participants who reported having any knowledge of Chinese characters.
Materials
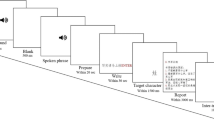
A set of 213 simple-structure characters was drawn from the vocabulary lists in the 12 volumes of the Elementary School Textbooks (Elementary Education Teaching and Research Center, 1996), as tabulated by Shu et al. (2003). These lists of characters reflect those that are required to be taught in Grades 1–6 in Beijing and several other regions, and they include a total of 2,570 distinct characters. All of the characters that we examined had a simple structure, according to Shu et al. and to a Chinese government list of simple-structure characters (Institute of Applied Linguistics Ministry of Education, 2009). These characters constitute a complete list of simple-structure characters taught in elementary schools. Forty-three of the characters that had a simple structure according to the government list were excluded from our study because they are rarely used and are not taught to elementary students. The set of 213 characters was divided into two lists, one with 107 items and the other with 106. To the extent possible, the two lists contained the same number of characters with each stroke count. Each participant saw correct characters from only one list. On each trial, an English word or phrase was presented together with two Chinese characters. One of the characters corresponded to the English word or phrase, and the other character did not. The wrong answer was chosen from the other list, and it contained the same number of strokes as the correct character. In five cases in which exact matching of the stroke count was not possible, the stroke count for the wrong character differed by one from the stroke count for the correct character. Because no character matched with the character for one (一 yi1) in number of strokes, we used 丿(not a full Chinese character) as the wrong answer for it. When more than one wrong answer was available for a given stroke count, different participants received different wrong answers in order to minimize the possibility that correct responses could reflect the idiosyncratic characteristics of a particular wrong choice. Each participant saw each character only once in the experiment.
The testing materials for each participant were presented in a booklet, with one trial on each page. The English word or phrase was typed on the upper center of the page. Below it were the two characters, one on the left and one on the right. The correct answer was on each side approximately half of the time. The items were presented in a different random order for each participant.
Procedure
Participants were tested individually, and 20 participants were assigned to each list of characters. The participants were instructed to guess which of the two characters on each trial corresponded to the meaning of the English word or phrase. They were told that Chinese characters tend to look like what they mean and that they could look for similarity between the appearance of the characters and the meaning in order to answer the questions. After the participant selected a response for each trial, the experimenter told the participant the correct answer. This helped to motivate participants and keep their concentration on the task. The session lasted about 30 min.
Results
Iconicity task performance
The results for each character are shown in the full database, ordered by stroke count. The frequency distribution for the proportions of correct responses was unimodal, with a mean of .536 (SD = .192). The proportion of correct responses was slightly but significantly higher than would be expected by chance, .500 [t(39) = 5.15, p < .001, by subjects; t(212) = 2.71, p = .007, by items; both tests were one-tailed]. Of the 213 items, only 15 showed performance that was significantly higher than would be expected on the basis of chance, according to a one-tailed binomial test with a p level of .05, using a false discovery rate procedure to control for the number of tests (Benjamini & Hochberg, 1995). These potentially iconic characters are listed in Table 1.
The mean proportion of correct responses in our study is similar to that reported by Koriat and Levy (1979), .546, and lower than the .633 reported by Luk and Bialystok (2005). This difference may have arisen because Luk and Bialystok attempted to use equal numbers of iconic and noniconic characters. On the basis of our results, there are many fewer iconic than noniconic characters. The correlation between the proportions of correct responses to a character in our study and in the Luk and Bialystok study, for the 20 characters that were examined in both studies, was significant, .45 (p < .05). Such a correlation could not be computed for the Koriat and Levy study, because those researchers had tested pairs of characters and did not present the data for individual pairs.
Correlations and regressions
Correlation and regression analyses were carried out to determine how the guessability of a character related to its other characteristics and to the order in which it is taught in Chinese schools. We ranked the 213 characters according to the lesson in which they are introduced in the textbooks studied by Shu et al. (2003). Thus, the 5 characters introduced in the first lesson of the first book all received a rank of 3, considering them as tied, and characters introduced in later sessions received higher ranks. This is a finer-grained measure than the grade level at which a character is introduced, the measure used by Shu et al. Another variable of interest was the frequency of the character. This was measured as occurrences per million in the Dictionary of Chinese Character Information (1988), in which books and other written materials were sampled from various fields and from 192 newspapers and magazines. The number of strokes in the character was also examined. We used log transformations for frequency and stroke count in order to normalize the distributions. The final variable of interest was the picturability of the concept. Some concepts are intrinsically easier than others to depict in a picture, and one might expect that participants would perform above the level of chance primarily for such characters. To judge picturability, 31 students from the Washington University participant pool who did not participate in the main experiment were shown the English translations used in that experiment. They were asked to rate each translation on a 7-point scale to indicate the extent to which the concept could be expressed easily in a simple black-on-white line drawing or diagram. To introduce the task, several examples were given. Cigarette was given as an example of a concept that people might consider to be highly picturable, running as a concept that might be considered medium in picturability, and patience as a concept that many people would find difficult to express in a simple picture. Participants were asked to give their own impressions of the items, and the order of the items was randomized for each participant. The values for each character on picturability and the other measures are shown in the online supplemental materials.
Table 2 shows the mean values of each variable and the correlations among them. As expected, there was a significant correlation between the proportion of correct guesses for a character and its rated picturability. In addition, the order of teaching correlated significantly with frequency, number of strokes, and picturability rating. These correlations indicate that characters that are taught earlier in schools tend to be used more frequently and to be visually simpler, as reported by Shu et al. (2003). In addition, concepts that are easily picturable tend to be taught earlier in schools. The significant negative correlation between frequency and picturability appears to reflect the fact that the grammatical particles included in the study, which are in general highly frequent, were rated as not very picturable.
The correlation between order of teaching and the proportion of correct guesses was not significant, but it was in the direction that more guessable characters tended to be taught earlier. As a stronger test of the notion that characters whose meanings are easy to guess from their visual forms are taught earlier in school, we carried out a linear regression analysis to predict the sequence in which characters are introduced in textbooks. Frequency, number of strokes, picturability, and proportion of correct guesses were all included as predictors. The results of the regression, which are displayed in Table 3, show that frequency, number of strokes, and picturability made significant and independent contributions to the order of teaching. Taken together, these variables accounted for 38.6% of the variance. The proportion of correct guesses, an indicator of iconicity, did not significantly predict when the characters are taught. Given a degree of bimodality in the picturability ratings, we repeated the analysis using a median split on this variable. The pattern of significant and nonsignificant effects remained the same.
Discussion
Our study was designed to provide information about the guessability of simple-structure Chinese characters, an indicator of their iconicity. The results suggested that only a small degree of iconicity remains in these characters. Of the 213 simple-structure characters tested here, which include all such characters taught in elementary school, U.S. adults who did not know Chinese could guess the correct character 53.6% of the time when presented with an English word or phrase and asked which of two possible characters corresponded to it. This was slightly but significantly greater than the 50% expected by chance. Of the 213 characters in our study, only 15 (7%) showed performance that was significantly above the chance level according to a procedure that controlled for the number of statistical tests. Whereas these 15 characters appear to be truly iconic, the large majority of simple-structure characters are not. This is true even though most simple characters of modern Chinese derive from ancient Chinese pictographs that were easily seen as picturing objects. However, over centuries of use, the characters have become more stylized, such that relatively few still clearly represent the objects that they denote via structural similarity. For example, the character 见 jian4 (“to see”), which originated from a recognizable picture of a person clearly showing the eyes (see Fig. 1), appears to have lost its visual similarity to the concept that it represents. The participants in our study were at chance, 50%, in guessing that this character corresponded to “to see.” In contrast, the character 雨 yu3 “rain” seems to have retained a degree of iconicity, in that participants performed significantly above chance with this character (85% correct).
Some characters had low rates of correct responses, and performance on three of them was significantly lower than chance using the same procedures that we used to test for above-chance performance. In two of these cases, 曲 qu3 “curve” and 垂 chui2 “droop,” the many straight lines in the characters do not appear to fit well with the meanings. The effect was not due to the features of the distractors, because the distractors varied across different participants.
A surprising finding, at first glance, is that performance on 一 yi1 “one” and 二 er4 “two” (65% and 70%, respectively) was not better than it was. Recall, though, that the distractors had the same number of strokes as the correct answers. As compared to other characters with two strokes, for example, 二 does not unambiguously denote the concept “two.” Especially when 一, 二, and 三 san1 “three” were not presented as target characters in the same set, it was not easy to detect the appearent iconic regularity in them.
A positive feature of our methodology is that no photographs were used that could have biased participants’ responses. Some such biases were noted by Luk and Bialystok (2005), as when the participants in their study consistently chose the wrong photograph for the character for “tooth” because that photograph had some structural similarity with the character. Another positive feature of our methodology is that the correct and incorrect characters on each trial had the same number of strokes. This means that it would be difficult for participants to use the strategy of choosing a visually complex character to represent a difficult or abstract meaning. When participants performed reliably above the level of chance, therefore, the arrangement of the strokes must have been responsible.
The significant correlation that we found between the proportion of correct responses and the rated picturability of the corresponding word or phrase helps to validate our results. The picturability rating can be seen as tapping the degree to which a character representing a particular word or idea could be iconic. We would expect that only concepts that could in theory be picturable, such as those for concrete objects, would have the potential to be written with characters that resemble the objects. Further validating our measure is the significant correlation between our results and those of Luk and Bialystok (2005) for the characters that were presented in both studies. The modest size of the correlation may reflect the previously noted weaknesses in the procedure of that earlier study, including the use of photographs and the fact that the same wrong option was used for each participant.
Our findings on the guessability of characters should be useful in studies of reading and writing acquisition in Chinese, particularly as we present data on characters that are taught in Chinese elementary schools. Here we used the data for one such purpose—to determine whether characters whose meanings are easy to guess from their shapes tend to be taught earlier to Chinese children than do characters for which this is not the case. Bialystok and Luk (2007) suggested that, when a character looks like what it represents, Chinese 4-year-olds are better able to understand that the meaning of a character is conveyed by the character itself and not by an adjacent picture. Along similar lines, the data of Shu et al. (2003) suggested that the order in which characters are taught in Chinese elementary schools may have been shaped by a tendency for more iconic characters to be easier to learn. Specifically, Shu et al. reported that the proportion of pictorial characters was higher among characters taught in early grades than among characters taught in later grades. However, as mentioned earlier, Shu et al. did not classify characters on the basis of empirical evidence about the degree to which their meanings could be recovered from their forms. Nor did they determine whether the apparent link that they observed between order of teaching and iconicity could be due to other variables, such as the visual complexity of the characters or their frequency of use. According to the analyses reported here, which used our empirically derived estimates of iconicity based on guessability, iconicity does not contribute to the order of teaching once other factors are statistically taken into account. This does not mean that it is not useful to link characters with objects or to describe the evolution of characters to children (Wu, Anderson, Li, Chen, & Meng, 2002). However, the present results suggest that, for most simple-structure characters, children will not spontaneously notice a link between the arrangement of strokes and the features of the concept that the character represents.
Empirical estimates of iconicity will be helpful not only in studies of the learning of Chinese characters but also in studies of character processing by skilled readers and writers. As mentioned previously, several investigators have suggested differences in performance and in brain processing for iconic versus noniconic characters (Chan et al., 2007; Nguy et al., 1980). However, strong conclusions cannot be drawn, because the iconic and noniconic characters in these studies were not selected on the basis of empirical data.
Although the present study has provided information about a larger sample of characters than in previous studies, several limitations remain. First, we examined only simple-structure characters. Many Chinese characters are compounds, and such characters were not examined here. Second, we studied simplified Chinese characters. We did not examine the traditional Chinese characters that are currently used in Hong Kong, Taiwan, and certain other Chinese-speaking regions. Indeed, 50 of the characters in the present set are written differently in traditional Chinese. For the benefit of researchers carrying out studies in regions that use traditional Chinese characters, it would be important to test those characters. Another potential limitation of our study is that stroke count is only a rough indicator of visual complexity. In future studies, it may be possible to use finer-grained measures when matching correct and incorrect responses for visual complexity.
Despite the limitations of our study, the data collected here should be useful to researchers studying Chinese. This information, together with other information that is available about Chinese characters (Hao et al., 2008; Liu et al., 2007; Rickard Liow et al., 1999; Shu et al., 2003), can help researchers to choose stimuli and to design methodologically sound studies. Moreover, our finding that the overall iconicity of simple-structure Chinese characters is fairly low supports the idea (DeFrancis, 1989; Hall, 1986; Perfetti & Dunlap, 2008) that Chinese is not as pictorial as is popularly thought. Some simple-structure characters have visual forms that suggest their meanings, but such characters are in the minority.
References
Benjamini, Y., & Hochberg, Y. (1995). Controlling the false discovery rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society: Series B, 57, 289–300.
Bialystok, E., & Luk, G. (2007). The universality of symbolic representation for reading in Asian and alphabetic languages. Bilingualism: Language and Cognition, 10, 121–129. doi:10.1017/S136672890700288X
Chan, C. C. H., Leung, A. W. S., Luo, Y., & Lee, T. M. C. (2007). How do figure-like orthographs modulate visual processing of Chinese words? Cognitive Neuroscience and Neuropsychology, 18, 757–761. doi:10.1097/WNR.0b013e3280ebb45f
DeFrancis, J. (1989). Visible speech: The diverse oneness of writing systems. Honolulu, HI: University of Hawaii Press.
Dictionary of Chinese character information. (1988). Beijing, China: Science Publishers.
Teaching, E. E., Center, R., Education, B., & Institute, S. (1996). Elementary school textbooks. Beijing, China: Beijing Publishers.
Hall, P. (1986). Written symbols: East and West. Semiotica, 58, 101–106. doi:10.1515/semi.1986.58.1-2.101
Hao, M., Shu, H., Xing, A., & Li, P. (2008). Early vocabulary inventory for Mandarin Chinese. Behavior Research Methods, 40, 728–733. doi:10.3758/BRM.40.3.728
Institute of Applied Linguistics Ministry of Education. (2009). Specification of the uundecomposable characters commonly used in the Modern Chinese. Available at www.china-language.gov.cn/9/2009_9_27/1_9_4351_0_1254018637067.html
Koriat, A., & Levy, I. (1979). Figural symbolism in Chinese ideographs. Journal of Psycholinguistic Research, 8, 353–365. doi:10.1007/BF01067139
Liu, Y., Shu, H., & Li, P. (2007). Word naming and psycholinguistic norms: Chinese. Behavior Research Methods, 39, 192–198. doi:10.3758/BF03193147
Luk, G., & Bialystok, E. (2005). How iconic are Chinese characters? Bilingualism: Language and Cognition, 8, 79–83. doi:10.1017/S1366728904002081
Nguy, T. V. H., Allard, F. A., & Bryden, M. P. (1980). Laterality effects for Chinese characters: Differences between pictorial and nonpictorial characters. Canadian Journal of Psychology, 34, 270–273. doi:10.1037/h0081057
Perfetti, C. A., & Dunlap, S. (2008). Learning to read: General principles and writing system variations. In K. Koda & A. Zehler (Eds.), Learning to read across languages (pp. 13–38). Mahwah, NJ: Erlbaum.
Rickard Liow, S. J., Tng, S. K., & Lee, C. L. (1999). Chinese characters: Semantic and phonetic regularity norms for China, Singapore, and Taiwan. Behavior Research Methods, Instruments, & Computers, 31, 155–177. doi:10.3758/BF03207706
Shu, H., Chen, X., Anderson, R. C., Wu, N., & Xuan, Y. (2003). Properties of school Chinese: Implications for learning to read. Child Development, 74, 27–47. doi:10.1111/1467-8624.00519
Wu, X., Anderson, R. C., Li, W., Chen, X., & Meng, X. (2002). Morphological instruction and teacher training. In W. Li, J. S. Gaffney, & J. L. Packard (Eds.), Chinese children’s reading acquisition: Theoretical and pedagogical issues (pp. 157–173). Norwell, MA: Kluwer.
Author Note
W.X. is now at Institute of Child Study, University of Toronto. Some of these results were presented at the meeting of the Society for the Scientific Study of Reading, St. Pete Beach, Florida, July 2011. We thank Nicole Rosales for her help with data collection, and Gigi Luk and Ellen Bialystok for sharing their original data.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Esm 1
(XLSX 24.9 kb)
Rights and permissions
About this article
Cite this article
Xiao, W., Treiman, R. Iconicity of simple Chinese characters. Behav Res 44, 954–960 (2012). https://doi.org/10.3758/s13428-012-0191-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-012-0191-3