
Abstract
Biological plausibility is an essential constraint for any viable model of semantic memory. Yet, we have only the most rudimentary understanding of how the human brain conducts abstract symbolic transformations that underlie word and object meaning. Neuroscience has evolved a sophisticated arsenal of techniques for elucidating the architecture of conceptual representation. Nevertheless, theoretical convergence remains elusive. Here we describe several contrastive approaches to the organization of semantic knowledge, and in turn we offer our own perspective on two recurring questions in semantic memory research: (1) to what extent are conceptual representations mediated by sensorimotor knowledge (i.e., to what degree is semantic memory embodied)? (2) How might an embodied semantic system represent abstract concepts such as modularity, symbol, or proposition? To address these questions, we review the merits of sensorimotor (i.e., embodied) and amodal (i.e., disembodied) semantic theories and address the neurobiological constraints underlying each. We conclude that the shortcomings of both perspectives in their extreme forms necessitate a hybrid middle ground. We accordingly propose the Dynamic Multilevel Reactivation Framework—an integrative model predicated upon flexible interplay between sensorimotor and amodal symbolic representations mediated by multiple cortical hubs. We discuss applications of the dynamic multilevel reactivation framework to abstract and concrete concept representation and describe how a multidimensional conceptual topography based on emotion, sensation, and magnitude can successfully frame a semantic space containing meanings for both abstract and concrete words. The consideration of ‘abstract conceptual features’ does not diminish the role of logical and/or executive processing in activating, manipulating and using information stored in conceptual representations. Rather, it proposes that the materials upon which these processes operate necessarily combine pure sensorimotor information and higher-order cognitive dimensions involved in symbolic representation.
Similar content being viewed by others


Introduction
We rely on semantic memory to understand words, interact with objects, and flexibly assimilate new information. This form of human memory is accordingly essential for navigating our most fundamental interactions with the world. Our empirical understanding of semantic memory has recently undergone radical revision. Biological plausibility has emerged as an essential constraint for models of conceptual representation, which have historically been rooted in philosophy and cognitive linguistics. Although we now enjoy unprecedented empirical power to elucidate the cognitive and neural architecture of semantic memory, a consensus on semantic organization remains paradoxically elusive. Our aims here are to discuss several factors perpetuating theoretical discord and to present our own perspective on two of the most commonly recurring and controversial topics in the study of semantic memory:
-
(1)
Embodied vs. disembodied cognition: the extent to which semantic knowledge is grounded by perception, action, and somatic states and the necessity for symbolic transformations of sensorimotor detail.
-
(2)
Abstractness: the manner in which the brain represents concepts such as proposition and symbol that are not clearly grounded within perception, action, or somatic states.
How embodied is the semantic system?
Neurologically constrained theories of semantic memory tend to fall along a spectrum defined by their central anatomical organizing principle. Fully distributed models have historically been strongly associated with embodied cognition in that they have no central point(s) of convergence and involve dispersion of perceptual and motor and features across modal association cortices (Allport, 1985; Gage & Hickok, 2005; Meteyard, Rodriguez, Bahrami, Vigliocco, & Cuadrado, 2012; Pulvermüller, Moseley, Egorova, Shebani, & Boulenger, 2014; Pulvermüller, 2013).Footnote 1 In contrast, hub views are more commonly regarded as disembodied in that they propose local semantic binding sites that perform abstract symbolic transformations of sensorimotor knowledge (Lambon Ralph, Sage, Jones, & Mayberry, 2010; Patterson, Nestor, & Rogers, 2007; Rogers et al. 2004). We discuss potential strengths and weakness of these perspectives below.
Fully distributed models
Fully distributed models operate under the assumption that the brain decomposes object concepts into discrete sets of features stored in sensorimotor brain regions (e.g., premotor cortex for action, auditory cortex for environmental sounds) (Gallese & Lakoff, 2005; but see Martin, 2007). Repeated exposure to a correlated set of semantic features facilitates Hebbian learning through which anatomically remote representations become functionally coupled. Under this view, object concepts reflect neural co-activation of features gradually instantiated through feature covariance (e.g., handles and sharp edges often co-occur). This feature-based approach has been widely invoked when modeling patterns of performance within semantic domains (e.g., abstract vs. concrete word recognition differences, semantic categorization) and patient populations (e.g., Alzheimer’s Disease) (Cree, McNorgan, & McRae, 2006; Cree & McRae, 2003; Farah & McClelland, 1991; Gonnerman, Andersen, Devlin, Kempler, & Seidenberg, 1997). For example, one might intuitively imagine how the semantic features of a banana decompose and disperse across relevant association cortices (Crutch & Warrington, 2003; Samson & Pillon, 2003).
The compositional assumption of distributed models has been criticized widely, however, on grounds that semantic features have emergent properties (Jackendoff, 1987). In a linear mathematical system, for example, one can reasonably assume that the input (e.g., 2 + 2) yields a predictable output through simple addition. The classical view of concepts was premised on the assumption that semantic features combine in a linear manner (e.g., yellow + sweet + pleasant odor = BANANA). This assumption has since proven untenable in the face of phenomena such as fuzzy category boundaries, typicality effects, and the resistance of abstract words to conventional binary feature listing approaches (for refutation and alternatives see Murphy, 2002). Thus, it is unclear how an embodied semantic system composed exclusively of distributed sensorimotor regions is capable of performing the nonlinear operations critically necessary for imbuing semantic feature binding with its characteristic emergent properties. Lambon Ralph (2014b) recently employed the metaphor of a recipe describing this paradox, arguing that the mere presence of flour, butter, vanilla, and sugar do not ensure the presence of a cake. Similarly, the representation of concepts requires that the semantic system perform combinatorial, operations upon constituent features: sensorimotor information alone is incapable of fully representing conceptual information.
Abstract concepts such as proposition and symbol pose another problem for fully distributed semantic theories: how could such concepts be tied to sensorimotor information? One prominent solution, Dual Coding Theory, holds that language and percepts constitute two parallel semantic systems: abstract concepts are exclusively verbally coded through linguistic associations, whereas concrete concepts share dual linguistic and perceptual codes (Paivio, 2013). A more radical view essentially denies that abstract concepts exist at all and that all words are ultimately grounded in somatic states linked to perception, emotion, and introspection (for variants of grounding in abstract words see Barsalou, 2009; Borghi, Capirci, Gianfreda, & Volterra, 2014; Gallese & Lakoff, 2005; Kousta, Vigliocco, Vinson, Andrews, & Del Campo, 2011; Vigliocco et al. 2014).
Finally, patient-based dissociations present a final challenge for fully distributed models. A distributed semantic network affords great redundancy and resilience to brain injury. This organizing principle predicts that only the most catastrophic bilateral brain injuries should produce global semantic impairments. Yet, this is clearly not the case. Warrington’s (1975) foundational case series first detailed the selective impairment of semantic memory in what is now known as semantic dementia or semantic variant primary progressive aphasia (svPPA). Many subsequent investigations into the nature of the linguistic and conceptual impairments incurred in semantic dementia have generally demonstrated a profile of a multimodal semantic impairment linked to bilateral cerebral atrophy, impacting a relatively circumscribed portion of the temporal lobes (Acosta-Cabronero et al. 2011). The combination of pathology and impairment incurred in semantic dementia suggest the presence of one or more semantic nexus points. This network principle is antithetical to fully distributed theories but central to the amodal hub approach, to which we now turn.
Amodal hub models
Proponents of amodal semantic theories argue that concepts undergo complex transformations from high fidelity sensorimotor to symbolic representational formats (Fairhall & Caramazza, 2013). Hub proponents in particular hold that this shift from embodied to disembodied representation occurs within one or more convergence zones (Binder, Desai, Graves, & Conant, 2009; Damasio & Damasio, 1994). Numerous cognitive functions have been ascribed to hubs, including crossmodal integration, pattern association, cognitive abstraction, computations of similarity relations, and symbol formation. An amodal semantic system is capable of accommodating many aspects of cognitive abstraction (e.g., category induction, generalization to new exemplars), and the hub assumption also fits well with the ubiquitous semantic impairments that emerge in the context of temporal lobe atrophy in semantic dementia (Caine, Breen, & Patterson, 2009; Lambon Ralph, Mcclelland, Patterson, Galton, & Hodges, 2001; Lambon Ralph & Patterson, 2008; Rogers et al. 2006).
Despite the clear explanatory power of the hub approach, this perspective has its own unique set of shortcomings. Foremost, the neurobiological mechanisms by which hubs perform propositional transformations remain essentially a black box (Kandel, 2006). We must currently take it on faith that the language of thought involves a form of mental calculus that operates over abstract symbols: we have only the most rudimentary understanding of how the brain extracts and manipulates symbols (Deacon, 1998; Louwerse, 2011). Deacon (1998) argued that the co-evolution of language and brain (particularly the prefrontal cortex) has uniquely equipped Homo sapiens for symbolic cognition. However, the mechanism by which symbols are assigned and the neural representation of the symbols themselves remain far less specified than the neural dynamics of hierarchical processing within the early visual and auditory systems.
Another common objection to amodal hub theories arises from the symbol grounding problem (Harnad, 1990). Embodied cognitive systems ground the meanings of words and objects through direct mapping to physical objects, introspective states, and event schemas. In contrast, a disembodied semantic system is comprised of symbols and propositions, all of which are ultimately abstracted away from physical referents. For a firsthand example of the grounding problem, consider a recent dialogue between the first author (who has never been to Australia) and an Australian family friend. Q: What’s Sydney like? A: It’s a lot like Melbourne. The circularity of defining an unknown (SYDNEY) via another unknown (MELBOURNE) is the crux of the grounding problem (for a related anecdote see Shapiro, 2008). The Sydney-Melbourne conundrum is amplified within large-scale amodal semantic approaches such as latent semantic analysis (LSA) where the meanings of words (amodal symbols) are derived exclusively through implicit associations and co-occurrence statistics with other symbols (Landauer & Dumais, 1997)—a situation compared to learning a foreign language by studying a dictionary written in that language (Searle, 1980).
The trajectory of normal language acquisition offers a clear solution to the grounding problem faced by LSA and other amodal models. Zwaan (2008) notes that there are numerous modes of extracting meaning from associations and co-occurrence data in our environment. An attentive and curious infant learns co-occurrence relationships about visual stimuli, sounds, and emotional experiences in their immediate environment (e.g., teddy bears, blankets, and pacifiers are pleasant things that occur in my crib). Simultaneously, the same pre-linguistic infant is bombarded with explicit labels for these objects. This early stage of language acquisition is heavily reliant upon referential learning (Golinkoff, Mervis, & Hirsh-Pasek, 1994), wherein infants link arbitrary phonological symbols to the immediate objects in their environment, often through a combination of explicit instruction and exaggerated demonstration (Juhasz, 2005; Reilly, Chrysikou, & Ramey, 2007). Thus, our earliest learned words are often acquired through language-referent pairings that provide a perceptual grounding mechanism for more complex, later-learned modes of language and conceptual acquisition.
LSA is a model of semantic space based on extracting concepts through relationships between words. LSA is, however, agnostic to earlier forms of language-referent learning that might ground a core lexicon in perception and action. One appealing hypothesis is that the earliest learned words constitute a set of concrete primitives (e.g., SAD) from which we later expand to learn abstract concepts (e.g., MELANCHOLY) (Barsalou, 2008; Crutch & Warrington, 2005; see also the symbol interdependency hypothesis of Louwerse, 2011).
Online reconstruction of semantic representations
Reconstruction, filtering, and post-interpretive processing are well-accepted phenomena in episodic memory research. One compelling source of evidence for similar reconstructive processes in semantic memory involves variability in patterns of cortical activation when the same object concept is accessed through different modalities and task cues (Kiefer & Martens, 2010; Willems & Casasanto, 2011). For example, Van Dam and colleagues (2012) used a go/no-go paradigm where participants made judgments of objects naturally imbued with action and color salience (e.g., a tennis ball). Participants responded to either visual attributes of a word (e.g., “Is this object a green color?”) or an action property for the same word (e.g., “Is this word associated with a foot action?”). Probes of action properties selectively engaged motor cortex, whereas color probes did not activate the same regions. Similar contextual variability is also apparent in patterns of cortical functional connectivity. Using the same go/no-go paradigm, Van Dam and colleagues (2012) reported that probes of action properties strengthened connectivity between a putative hub region (posterior superior temporal sulcus) and motor cortex. That is, probes for action properties (e.g., “Is this word associated with a foot action?”) resulted in stronger functional coupling between superior temporal sulcus and motor cortex than probes for color properties (see also Hoenig, Sim, Bochev, Herrnberger, & Kiefer, 2008).
The role of flexible semantic reconstruction is also supported through studies of polysemy and metaphor. Hauk and colleagues (2004) previously demonstrated engagement of somatotopic regions of motor cortex corresponding to words with high motor effector salience (e.g., kick, pick, lick) in a lexical decision task (though see Postle et al. 2008). Raposo and colleagues (2009) note that polysemy and metaphor offer significant challenges for the somatoptic representation hypothesis (Louwerse & Jeuniaux, 2008, 2010; Mahon, 2014). That is, a word such as kick assumes a different sense in the context of phrases such as kick the football vs. kick the bucket. In their functional magnetic resonance imaging (fMRI) work, Raposo and colleagues (2009) demonstrated that the critical verb, kick, activates motor cortex only under congruent sentential contexts, a finding that challenges the notion that semantic representations are fixed. One unique possibility regarding ultra-rapid engagement of the motor complex for kick, pick, lick verbs is that these words reflect a small subset of the lexicon that enjoys privileged access to the sensorimotor system un-distilled through hubs. Coslett and colleagues (2002) proposed the relevant hypothesis that knowledge of body parts constitutes a dissociable subdomain within semantic memory. It is possible that this class of effector-specific verbs such as kick and pick engage this putative subdomain. Another possibility is that the earliest learned verbs are more strongly associatively linked to the motor system than later acquired verbs. In contrast, it is difficult to envision how many of the verbs within this manuscript (e.g., premised, engaged, modified, facilitate) could evoke a similar pattern of somatotopic engagement.
Representational pluralism: hybrid, multilevel approaches to conceptual knowledge
Dove (2009) argued that the shortcomings of hub and distributed theories necessitate a class of hybrid theories that integrate both embodied and disembodied components (see also Kemmerer, 2015; Zwaan, 2014). There currently exist a range of hybrid semantic models that are well equipped to handle this challenge. These models differ historically in the constraints of how they achieve the goal of representational pluralism, either through a unitary semantic system (i.e., words and percepts converge upon an amodal semantic store) or the coordinated activity of multiple semantic systems (i.e., language and sensorimotor semantics constitute parallel channels). In this section we review several hybrid, multi-level semantic frameworks.
The convergence zone framework
The convergence zone framework is a prominent example of a hybrid approach that relies on reciprocal activity between local cortical hubs interacting with a distributed sensorimotor network (Damasio & Damasio, 1994). Damasio argued that semantic representations within hubs are unrefined and that these underspecified representations are enriched via retroactivation, through which the sensorimotor system is re-engaged through motor enactment and simulation processes (Barsalou, 1999; Pecher, Zeelenberg, & Barsalou, 2004). Upon this view, local hubs are activated both during object perception and during semantic memory retrieval. During the early stages of perception, first-order convergence zones bind time-locked activity in early sensorimotor cortices. Next, second-order convergence zones combine activity yoked from first-order convergence zones. This pattern of hierarchical conjunctive processing continues until all relevant perceptual information is bound into a coherent representation. A key feature of this theory is that convergence zones do not contain the integrated representation itself. Instead, these brain regions act as pointers or pattern associators to activation patterns within lower order cortical cell assemblies. Damasio (1989) argued that such retroactivation processes are integral for enriching “unrefined” representations. Simmons and Barsalou (2003) and Barsalou and colleagues (2003) extended this idea, arguing that the degree and specificity of enrichment processes are moderated by contextual demands. During semantic retrieval, the process reverses: top-down information guides activation of higher order convergence zones, which guide activation of lower-order convergence zones, which in turn coordinate time-locked activation of early sensorimotor cortices (Meyer & Damasio, 2009).
Damasio (1989) initially proposed that the neuroanatomical localization of convergence zones is mediated both by the modality of information being processed and its position within the hierarchy (see also Sporns, Honey, & Ko 2007 for related distinctions between provincial vs. connector hubs). Recent work within the constraints of the convergence zone theory has utilized multivariate pattern analysis (MVPA) during fMRI of semantic processing to localize potential binding sites, most notably within the posterior superior temporal cortex (Mann, Kaplan, Damasio, & Meyer, 2012). The convergence zone principle has been invoked to explain numerous cognitive and linguistic phenomena including proper noun deficits, mirror processing impairments, “grandmother neurons”, and contextual integration effects supporting the retroactivation of introspective mental states that support abstract concepts (Damasio, 1989; Meyer & Damasio, 2009).
The hub and spoke model
Patterson, Lambon Ralph, Rogers, and colleagues modified the original convergence zone framework into today’s dominant hybrid approach known as the Hub and Spoke Model of Semantic Cognition (Binney, Embleton, Jefferies, Parker, & Lambon Ralph, 2010; Lambon Ralph et al. 2010; Lambon Ralph, 2014a; Patterson et al. 2007). The hub and spoke model proposes dynamic interactivity between a series of modality-specific spokes linked to hubs that are situated bilaterally in the anterior temporal lobes (ATLs). Under this approach, hubs perform amodal transformations that facilitate cognitive abstraction by computing similarity relations between objects (Rogers et al. 2004). The hub and spoke model has vast explanatory power for abstract concepts and effects of graceful degradation incurred in dementia. Yet, much remains to be learned about the cognitive and neural mechanisms underlying this model architecture. In particular, the contribution of sensorimotor simulation in the online reconstruction of object concepts remains underspecified. Other unresolved issues regard whether language acts as an ancillary verbal spoke and more generally how language is integrated within the model (see the “words” node in the model of Patterson et al. 2007).
When considering how hub and spoke models answer the call for pluralism, one point worth noting is that there may be a discrepancy between the structural and functional architecture of such models. That is, although the existing computational implementations of the hub units are architecturally amodal (e.g., Rogers et al. 2004), learning-induced attractor states in the trained model are likely to include hub units, some of which are functionally amodal but some of which are tuned to specific modalities (see also Crutch & Warrington, 2011). Recent studies of temporal lobe connectivity support the notion of progressive, hierarchical convergence of modality-specific information (e.g., auditory + visual detail) across the temporal cortices. For example, disparate features A, B, C, D gradually cohere into AB and CD, ultimately forming a coherent object unit, ABCD. The precise anatomy of this convergence process and whether it is graded or discrete remains debated. Hub and spoke proponents have most recently placed the endpoint of this feature binding process and the subsequent computational operations within the anterior fusiform gyrus (Binney, Parker, & Lambon Ralph, 2012; but see Tyler et al. 2004).
The dynamic multilevel reactivation framework
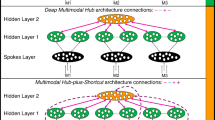
We recently proposed a complementary, more explicitly multi-level semantic architecture that specifies the nature of hub-spoke interactivity, an approach we term the Dynamic Multilevel Reactivation Framework (Reilly & Peelle, 2008; Reilly et al. 2014). Our model hypothesizes that semantic memory is subserved by a series of hubs that re-engage sensorimotor spokes during online reconstruction of object concepts. Figure 1 illustrates a simple schematic of how the hub and spoke systems interact. The hub system is composed of both low- and high-order hubs. Low-order hubs (e.g., angular gyrus, posterior middle temporal gyrus) have high node centrality and massive reciprocal connectivity with sensorimotor regions. As such, low order hubs are especially suited for heteromodal feature binding (Bonner, Peelle, Cook, & Grossman, 2013). This hypothesis is in line with proposals that regions of the angular gyrus play a critical role in establishing combinatorial semantic relationships between congruent concepts (e.g., red apple vs fast blueberry) (Bonner et al. 2013; Graves, Binder, & Seidenberg, 2013; Price, Bonner, Peelle, & Grossman, 2015). Recent structural connectivity studies using tractography have also demonstrated powerful coupling between these putative low order (angular gyrus) and high order (temporal pole) hubs during both verbal and non-verbal tasks, such as reading a sentence describing an event and viewing a picture of the same event (Jouen et al. 2014).

A multi-level, multi-hub semantic model. Hypothetical schematic of three, quasi-modular sensorimotor spoke systems (e.g., vision, audition, motor) bounded by dotted lines. Provincial hubs (within each module) feed a series of low-order connector hubs (e.g., angular gyrus, posterior middle temporal gyrus). These low-order hubs facilitate heteromodal feature convergence through binding, pattern recognition, and pattern completion. This coarsely bound information then streams to high-order hubs in the anterior temporal lobes that conduct nonlinear, symbolic transformations
Activity within low-order hubs can be characterized as heteromodal in that sensory features are bound within these regions (for a discussion of “first order” sensorimotor integration processes within the angular gyrus see Seghier, 2013). We hypothesize that high-order hubs situated primarily within the anterolateral temporal lobes conduct symbolic transformations upon these bound representations. During this transformation process, conceptual knowledge is abstracted from its sensorimotor roots via a series of successive processing stages whereby perceptual and linguistic knowledge ultimately converge (sensory ⇒ heteromodal ⇒ amodal). Under this view, amodal representations are unrefined and require enrichment through sensorimotor simulations. Impoverished stimulus conditions (e.g., non-canonical situations, atypical exemplars, fragmentary input) and complex task demands drive such enactment processes that are carried out through the spoke system.Footnote 2 This view emphasizes the dynamic nature of concepts and the fact that the degree of sensorimotor reactivation required for a particular concept depends on the unique demands of the task at hand.
Our view is that hubs form the core of the semantic system, whereas sensorimotor spokes act as a supporting halo. Task demands and depth of processing modulate interactivity between these two components, and this interactivity is mediated by a cognitive control system (see also Corbett, Jefferies, & Lambon Ralph, 2011; Jefferies, Patterson, & Lambon Ralph, 2008). Support for this perspective includes a recent voxel-based lesion symptom mapping study, correlating stroke-related left hemisphere cortical damage in aphasia with selective deficits in generating the names of manipulable objects (Reilly et al. 2014). In this work, we examined patients with extensive left inferior frontal lobe damage impacting Broca’s area and adjacent regions of the motor complex (ventral premotor and motor cortex). A strongly embodied view predicts that damage to regions of the motor cortex that mediate skilled motor movements of the dominant (right) hand would compromise both the ability to execute actions and also the ability to covertly simulate their corresponding motor plans.
We examined patient performance and lesion correlates for generating exemplars of manipulable categories (e.g., “name a hand tool”) relative to non-manipulable categories (e.g., “name a mountain range”). Lesion mapping revealed no correlation between integrity of the motor cortex and performance on generating manipulable exemplars—a trend that is consistent with prior studies of tool naming among patients with profound limb praxis impairment (e.g., apraxia) (Negri et al. 2007; Rosci, Chiesa, Laiacona, & Capitani, 2003). Among the patients we investigated, integrity of the angular gyrus (a hub) and MT/V5+ (a visual spoke projection implicated in motion perception) predicted impairment.
Additional evidence for the Dynamic Multilevel Reactivation Framework comes from a recent fMRI study among healthy young adults (n = 18) (J.R., A.C., & R.J. Binney, in preparation). In this study, participants learned a series of novel tools and animals via animated videos where the target item moved in an eccentric path and manner and made animal-like or tool-like noises while a narrator announced their names. We trained participants to 100 % naming accuracy and 1 week later scanned participants while they named both the novel objects and a set of familiar tools and animals. The critical experimental manipulation was that participants named each item from exposure to only one of its constituent modality specific features (e.g., visual form or environmental sound) during three separate modality-blocked runs. We reasoned that hub organization would be supported if a conjunction analysis revealed a common core intrinsic to all modalities. In contrast, a fully distributed approach would be supported by a lack of overlapping regions and if one feature in isolation (e.g., sound) activates a distributed representation encompassing the other features (i.e., visual form). We found support for the multiple hub-based perspective as illustrated in Fig. 1. A conjunction analysis [(Audfamiliar – Audnovel) ∩ (Visualfamiliar – Visualnovel) demonstrated that naming a familiar item from its visual form and naming the same items from their associated sound (e.g., a dog barking) engaged a common network of both high-order hubs (anterior temporal lobe) and low-order hubs (posterior middle temporal gyrus) (Fig. 2).

A functional magnetic resonance imaging (fMRI) conjunction analysis of naming from sound and visual form. The renderings above reflect a conjunction analysis conducted in SPM8 (Wellcome Trust Centre for Neuroimaging) as 18 participants covertly named a series of familiar relative to novel concepts. The conjunctions above represent “common” activation when naming objects from only their sound or visual form [(AUDfamiliar – AUDnovel) ∪ (VISfamiliar – VISnovel)]
Using PET and a different cognitive subtraction method [Toolsvisual + Animalsvisual ∩ Toolsauditory + Toolsvisual], Tranel and colleagues (2005) identified a modality neutral region of the inferior temporal lobe that was commonly activated when naming from the sounds and visual forms produced both by animals and tools (relative to scrambled sound and visual baselines). Tranel and colleagues were specifically interested in the role of this brain region in lexical retrieval, serving as an intermediary link between conceptual processing within the ATLs and post-lexical form encoding processes. In our analyses, we found a different distribution of more superior and anterior temporal lobe activity. This discrepancy is most likely due to the conjunction method we employed [i.e., familiar – novel], which effectively subtracted off the effects of lexical retrieval and subsequent post-lexical processes, focusing instead on areas commonly activated for the semantic features of familiar concepts. These differences highlight the inherent complexities involved in parsing the variance of semantic structure from a multifactorial linguistic task such as naming.
The challenge of abstract words
The empirical base for most theories of conceptual knowledge is based largely upon experimentation with concrete concepts. The question of how abstract concepts are represented in the brain presents particular challenges to a number of these accounts. Investigations of abstract concept knowledge, and the representational differences between abstract and concrete concepts, have approached the topic from a variety of perspectives. Some accounts focus on discrepancies in the amount of information available for concrete words relative to abstract words, including having more semantic features (Plaut & Shallice, 1993), superior ease of predication (Jones, 1985), and more facile access to contextual information (Schwanenflugel & Shoben, 1983). Other accounts focus on qualitative differences such as the claim that abstract words are more dependent upon associative than perceptual or similarity-based information, whereas concrete concepts show the reverse tendency, an approach framed within the qualitatively different representations (QDR) hypothesis (Crutch & Warrington, 2005). A further category of studies has addressed similarities and differences in the neural substrates of abstract and concrete concepts, such as patient studies (Bonner et al. 2009; Loiselle, Rouleau, Nguyen, & Dubeau, 2012), fMRI (Binder et al. 2005; Wang, Conder, Blitzer, & Shinkareva, 2010), electrophysiological investigations (Barber, Otten, Kousta, & Vigliocco, 2013), and transcranial magnetic stimulation (Pobric, Lambon Ralph, & Jefferies, 2009).
Some studies have combined multiple perspectives. For example, on a synonym judgment task in which the quantity of relevant contextual information was varied, Hoffman et al. (2014) found greater activation of anterior temporal lobes in the presence of relevant information (consistent with a role in representing conceptual knowledge) and inferior prefrontal cortex in the presence of irrelevant information (where appropriate aspects of meaning have to be selected, consistent with a semantic control function). Similarly, dual coding theory (Paivio, 2014) can be regarded as combining quantitative perspectives (greater representational strength for concrete items) and qualitative perspectives (verbal and visual information). Several other recent pluralistic models of abstract-concrete concept representation in the tradition of the dual coding theory have also been recently proposed, including the words as social tools (WAT) hypothesis (Borghi, Scorolli, Caligiore, Baldassarre, & Tummolini, 2013) and the language as situated simulation (LASS) model (Barsalou, Santos, Simmons, & Wilson, 2008). Dove (2014) is an especially strong proponent of the perspective that language acts as an embodied mode of thought, yielding a parallel and augmentative workspace for sensorimotor conceptual processing. Perhaps the closest theory to date to an account incorporating quantitative, qualitative and neural perspectives is Shallice and Cooper’s (2013) hypothesis that abstract concepts rely on modal logic for abstracting over events, applying modal operators recursively, or representing hypothetical events. Shallice and Cooper propose that these processes give rise to semantic associations between abstract concepts and depend critically upon the left lateral inferior frontal cortices.
One critical step toward elucidating abstract concepts is to develop a positive operational definition for the construct of abstractness. This necessarily involves looking beyond the sensorimotor channels traditionally implicated in the acquisition and representation of concrete concepts and considering a host of additional brain systems that may influence the formation of conceptual knowledge (Crutch, Troche, Reilly, & Ridgway, 2013; Troche, Crutch, & Reilly, 2014). For example, consider the role of magnitude information in concepts such as AMOUNT and LENGTH, the role of time in concepts such as MOMENT or HISTORY (Crutch et al. 2013), and the importance of emotion information in the representation of abstract terms more generally (Gallese & Lakoff, 2005; Kousta et al. 2011; Vigliocco et al. 2014; Vigliocco, Vinson, Lewis, & Garrett, 2004; Westbury et al. 2013).
Many previous empirical studies of word concreteness have isolated the tails of the concreteness spectrum, examining performance discrepancies for highly concrete words (e.g., beach) relative to highly abstract words (e.g., preponderance) (Binder, Westbury, & McKiernan, 2005; Crutch, Ridha, & Warrington, 2006; Pexman, Hargreaves, Edwards, Henry, & Goodyear, 2007; Reilly & Kean, 2007). Based on the ubiquity of this approach, one might logically conclude that concreteness is a fixed categorical distinction and that all concepts lend themselves to the binary distinction of abstract or concrete; however, this is not the case. Many words resist dichotomous categorization as either concrete or abstract. Our position is that the graded nature of concreteness thwarts multiple semantics approaches that require discrete processing mechanisms for abstract and concrete concepts. A more plausible and parsimonious alternative involves modeling the meanings of all words irrespective of their concreteness within a single high-dimensional semantic space. We hypothesize that numerous cognitive dimensions bound this space, including color, odor, motion, sound, emotion, social interaction, morality, time, space, quantity, polarity (i.e., positive/negative feelings), and valence. A key component of our approach is that every word has measureable salience within each of these domains and that all of the domains considered together constitute a topographic space where word meanings are distributed. In recent work, we have termed this the abstract conceptual feature (ACF) approach (Crutch et al. 2013).
We recently subjected ratings for hundreds of individual abstract and concrete English nouns to a hierarchical cluster analysis using the ACF approach (Troche et al. 2014). Our first step was to pursue dimensionality reduction upon the original set of 12 cognitive domains (e.g., valence, arousal, ease-of-teaching, sensation, etc.). The factor analysis revealed three latent variables corresponding roughly to sensation, emotion, and magnitude. These variables define a three-dimensional space upon which any word’s meaning might be plotted using Euclidean distance measurements. Figure 3 shows the distribution of a larger set of 750 English nouns spanning the concreteness spectrum within a high dimensional semantic space characterized by 14 cognitive dimensions.

A high-dimensional topography for word meaning. a Heatmap depicting Likert-scale ratings gleaned from 328 participants. Each of the 750 horizontal rows reflects one English noun, ordered on the y-axis from the most abstract to the most concrete using the Medical Research Council (MRC) Psycholinguistic database norms (Coltheart, 1981). The x-axis reflects 14 discrete cognitive dimensions aggregated by their relatedness via factor analysis (Troche et al. 2014). b Correlogram reflecting relations between the numerous predictors for the same 750 words depicted in a
We tested the validity of these distance metrics as markers of semantic relatedness in a number of ways. In one study, we demonstrated recently that ACF distance metrics outperformed latent semantic analysis distance metrics analysis in predicting comprehension performance (accuracy) of a patient with global aphasia on a series of spoken word to written word matching tests of verbal comprehension (Crutch et al. 2013). The higher error rate observed when identifying targets presented within word pairs with low ACF distances (semantically related) as compared with high ACF distances (semantically unrelated) indicates that the high-dimensional space generated from ACF control ratings approximates the organization of abstract conceptual space. ACF ratings of polarity (positivity/negativity) have also been used to explain superior comprehension of antonyms relative to synonyms or other non-antonymous associates in three further global aphasic patients (Crutch et al. 2012), suggesting that polarity is a critical semantic attribute of abstract words (see also Westbury et al. 2013).
One clear advantage of the ACF approach and related high-dimensional approaches (Moffat, Siakaluk, Sidhu, & Pexman, 2015; Westbury et al. 2013; Zdrazilova & Pexman, 2013) is that their models dispense with the artificial dichotomy of abstract vs concrete. That is, meanings of all words (abstract and concrete) can be modeled within a single semantic space. The ACF approach does not imply that abstract words constitute merely a list of features, or that modal logic machinery (Shallice and Cooper, 2013) or semantic control processes (Hoffman et al. 2014) are unnecessary. Rather, the assertion is that at least some of the information on which such processes operate share parallels with compositional, feature-based approaches to concrete concepts. For example, the meaning of an abstract concept such as TRUST can potentially be decomposed into a high-dimensional space factoring a range of variables (e.g., arousal, perceptual salience, emotion) analogous to the method of decomposing concrete concepts into a perceptual feature space.
The high-dimensional topography approach to concept representation fits well within the Dynamic Multilevel Reactivation Framework, which predicts that many sources of modality-specific information about concepts converge and are then bound into a single, coherent representation. In turn, this coarsely bound representation is subjected to symbolic transformation. The numerous cognitive dimensions that bound the ACF approach act as the putative spokes within this framework. One feature of this approach that distinguishes it from many other models (e.g., Dual Coding Theory) is that it is a unitary semantics model (for alternate unitary approaches see also Andrews, Vigliocco, & Vinson, 2009; Caramazza, Hillis, Rapp, & Romani, 1990; Vigliocco et al. 2004). That is, the perceptual and linguistic systems ultimately converge upon a single semantic store.
Concluding remarks
Biological plausibility and theoretical necessity impose essential constraints on models of semantic representation. Amodal semantic models continue to feature prominently in the study of concept representation despite significant limitations in our understanding of the neural mechanisms that underlie symbolic transformations (for a mechanistic discussion of symbolic implementation within neural networks see Knoblauch, 2008). Embodied cognition in its pure form dispenses with symbols altogether by linking semantic memory directly to somatic states and perception. Thus, one might argue from a symbol standpoint that embodied cognition currently holds on anatomical plausibility advantage. Yet, fully distributed sensorimotor representations can only take us so far: challenges posed by abstract concepts, linear semantic feature decomposition, and patient-based dissociations (e.g., semantic dementia) call for something more.
We have described the distinction between embodied vs. disembodied cognition as closely aligned with the anatomical principle of distributed vs. hub organization. An anonymous reviewer raised the question of whether this characterization is entirely justified, and whether it is possible to implement a distributed architecture for amodal hubs. Indeed, the Dynamic Multilevel Reactivation Framework reflects such architecture premised upon the coordination of multiple distributed hubs. Sporns (2012) and Sporns and colleagues (2007) have argued that there are several distinct variants of hubs (e.g., provincial vs connector) and that the hub-spoke architecture is replicated at numerous levels within the cortical processing hierarchy.
Perhaps the most compelling advantage of multilevel models, including the Dynamic Multilevel Reactivation Framework, is their capacity to incorporate both embodied and disembodied perspectives. Within this approach, hubs assume a starring role, flanked by a supporting cast composed of spokes conveying not only sensorimotor and emotional information but also contributions from a host of other dimensions. We have also described a potential grounding solution whereby the meanings of abstract and concrete words cluster within a unitary, high-dimensional space. As with any incipient theory, the hard empirical support for both approaches awaits.
Notes
The primary distinction we make is between distributed models, which rely on sensorimotor information to represent concepts, and amodal representations, which do not. A further distinction regards whether representations reside in primary sensorimotor cortices or secondary association areas (i.e., embodied = primary sensory cortex). Although this distinction is critical for some approaches to embodied cognition (e.g., Gallese & Lakoff, 2005, see also Martin, 2007) our claims are not framed in terms of this hard dichotomy.
For a recent discussion of the necessary role of sensorimotor simulations in semantic memory see Mahon (2014), who addresses the issue of necessary versus epiphenomenal engagement of the sensorimotor system in conceptual knowledge. Mahon raises the parallel cognitive domain of speech perception, wherein phonological input implicitly triggers corresponding orthography through cascaded activation. Few would argue that these cascaded effects to orthography are a necessary condition for processing phonology. One unanswered challenge for embodied cognition is to demonstrate that the observed activation of sensorimotor systems does not occur through a similar resonance mechanism. For a recent empirical treatment of this issue using rTMS in verb processing, see Papeo et al (2014).
References
Acosta-Cabronero, J., Patterson, K., Fryer, T. D., Hodges, J. R., Pengas, G., Williams, G. B., & Nestor, P. J. (2011). Atrophy, hypometabolism and white matter abnormalities in semantic dementia tell a coherent story. Brain, 134(7), 2025–2035. doi:10.1093/brain/awr119
Allport, D. A. (1985). Distributed memory, modular subsystems and dysphasia. In S. K. Newman & R. Epstein (Eds.), Current perspectives in dysphasia (pp. 207–244). Edinburgh: Churchill Livingstone.
Andrews, M., Vigliocco, G., & Vinson, D. (2009). Integrating experiential and distributional data to learn semantic representations. Psychological Review, 116(3), 463–498. doi:10.1037/a0016261
Barber, H. A., Otten, L. J., Kousta, S. T., & Vigliocco, G. (2013). Concreteness in word processing: ERP and behavioral effects in a lexical decision task. Brain and Language, 125(1), 47–53. doi:10.1016/j.bandl.2013.01.005
Barsalou, L. W. (1999). Perceptual symbol systems. Behavioral and Brain Sciences, 22(4), 577–660.
Barsalou, L. W. (2008). Grounded cognition. Annual Review of Psychology, 59, 617–645.
Barsalou, L. W. (2009). Simulation, situated conceptualization, and prediction. Transactions of the Royal Society B, 364, 1281–1289. doi:10.1098/rstb.2008.0319
Barsalou, L. W., Santos, A., Simmons, W. K., & Wilson, C. D. (2008). Language and simulation in conceptual processing. In M. de Vega, A. M. Glenberg, & A. C. Graesser (Eds.), Symbols and embodiment: Debates on meaning and cognition (pp. 245–284). Oxford, UK: Oxford University Press.
Barsalou, L. W., Simmons, W. K., Barbey, A. K., & Wilson, C. D. (2003). Grounding conceptual knowledge in modality-specific systems. Trends in Cognitive Sciences, 7(2), 84–91.
Binder, J. R., Desai, R. H., Graves, W. W., & Conant, L. L. (2009). Where is the semantic system? A critical review and meta-analysis of 120 functional neuroimaging studies. Cerebral Cortex, 19(12), 2767–2796. doi:10.1093/cercor/bhp055
Binder, J. R., Westbury, C., & McKiernan, K. (2005). Distinct brain systems for processing abstract and concrete concepts. Journal of Cognitive Neuroscience, 17(6), 905–917.
Binney, R. J., Embleton, K. V., Jefferies, E., Parker, G. J. M., & Lambon Ralph, M. A. (2010). The ventral and inferolateral aspects of the anterior temporal lobe are crucial in semantic memory: Evidence from a novel direct comparison of distortion-corrected fMRI, rTMS, and semantic dementia. Cerebral Cortex, 20(11), 2728–2738. doi:10.1093/cercor/bhq019
Binney, R. J., Parker, G. J. M., & Lambon Ralph, M. A. (2012). Convergent connectivity and graded specialization in the rostral human temporal lobe as revealed by diffusion-weighted imaging probabilistic tractography. Journal of Cognitive Neuroscience, 24(10), 1998–2014. doi:10.1162/jocn_a_00263
Bonner, M. F., Peelle, J. E., Cook, P. A., & Grossman, M. (2013). Heteromodal conceptual processing in the angular gyrus. NeuroImage, 71, 175–186. doi:10.1016/j.neuroimage.2013.01.006
Bonner, M. F., Vesely, L., Price, C., Farag, C., Avants, B., & Grossman, M. (2009). Reversal of the concreteness effect in semantic dementia. Cognitive Neuropsychology, 26, 568–579.
Borghi, A. M., Capirci, O., Gianfreda, G., & Volterra, V. (2014). The body and the fading away of abstract concepts and words: A sign language analysis. Frontiers in Psychology, 5, 811. doi:10.3389/fpsyg.2014.00811
Borghi, A. M., Scorolli, C., Caligiore, D., Baldassarre, G., & Tummolini, L. (2013). The embodied mind extended: Using words as social tools. Frontiers in Psychology, 4, 214. doi:10.3389/fpsyg.2013.00214
Caine, D., Breen, N., & Patterson, K. (2009). Emergence and progression of “non-semantic” deficits in semantic dementia. Cortex, 45(4), 483–494. doi:10.1016/j.cortex.2007.07.005
Caramazza, A., Hillis, A. E., Rapp, B. C., & Romani, C. (1990). The multiple semantics hypothesis: Multiple confusions? Cognitive Neuropsychology, 7(3), 161–189.
Coltheart, M. (1981). The MRC Psycholinguistic database. Quarterly Journal of Experimental Psychology, 33, 497–505.
Corbett, F., Jefferies, E., & Lambon Ralph, M. A. (2011). Deregulated semantic cognition follows prefrontal and temporo-parietal damage: Evidence from the impact of task constraint on nonverbal object use. Journal of Cognitive Neuroscience, 23(5), 1125–1135. doi:10.1162/jocn.2010.21539
Coslett, H. B., Saffran, E. M., & Schwoebel, J. (2002). Knowledge of the human body: a distinct semantic domain. Neurology, 59(3), 357–363.
Cree, G. S., McNorgan, C., & McRae, K. (2006). Distinctive features hold a privileged status in the computation of word meaning: Implications for theories of semantic memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 32(4), 643–658.
Cree, G. S., & McRae, K. (2003). Analyzing the factors underlying the structure and computation of the meaning of chipmunk, cherry, chisel, cheese, and cello (and many other such concrete nouns). Journal of Experimental Psychology: General, 132(2), 163–201.
Crutch, S. J., Ridha, B. H., & Warrington, E. K. (2006). The different frameworks underlying abstract and concrete knowledge: Evidence from a bilingual patient with a semantic refractory access dysphasia. Neurocase, 12(3), 151–163.
Crutch, S. J., Troche, J., Reilly, J., & Ridgway, G. R. (2013). Abstract conceptual feature ratings: The role of emotion, magnitude, and other cognitive domains in the organization of abstract conceptual knowledge. Frontiers in Human Neuroscience, 7, 186. doi:10.3389/fnhum.2013.00186
Crutch, S. J., & Warrington, E. K. (2003). The selective impairment of fruit and vegetable knowledge: A multiple processing channels account of fine-grain category specificity. Cognitive Neuropsychology, 20(3–6), 355–372.
Crutch, S. J., & Warrington, E. K. (2005). Abstract and concrete concepts have structurally different representational frameworks. Brain, 128(3), 615–627.
Crutch, S. J., & Warrington, E. K. (2011). Different patterns of spoken and written word comprehension deficit in aphasic stroke patients. Cognitive Neuropsychology, 28(6), 414–434. doi:10.1080/02643294.2012.673481
Crutch, S. J., Williams, P., Ridgway, G. R., & Borgenicht, L. (2012). The role of polarity in antonym and synonym conceptual knowledge: Evidence from stroke aphasia and multidimensional ratings of abstract words. Neuropsychologia, 50(11), 2636–2644.
Damasio, A. R. (1989). Time-locked multiregional retroactivation: A systems-level proposal for the neuralsubstrates of recall and recognition. Cognition, 33(1–2), 25–62.
Damasio, A. R., & Damasio, H. (1994). Cortical systems for retrieval of concrete knowledge: The convergence zone framework. In C. Koch & J. L. Davis (Eds.), Large-scale neuronal theories of the brain (pp. 61–74). Cambridge, MA: The MIT Press.
Deacon, T. W. (1998). The symbolic species. New York, NY: Norten.
Dove, G. (2009). Beyond perceptual symbols: A call for representational pluralism. Cognition, 110(3), 412–431. doi:10.1016/j.cognition.2008.11.016
Dove, G. (2014). Thinking in words: Language as an embodied medium of thought. Topics in Cognitive Science, 6, 371–389. doi:10.1111/tops.12102
Fairhall, S. L., & Caramazza, A. (2013). Brain regions that represent amodal conceptual knowledge. Journal of Neuroscience, 33(25), 10552–10558. doi:10.1523/jneurosci. 0051-13.2013
Farah, M. J., & McClelland, J. L. (1991). A computational model of semantic memory impairment: Modality specificity and emergent category specificity. Journal of Experimental Psychology: General, 120(4), 339–357.
Gage, N., & Hickok, G. (2005). Multiregional cell assemblies, temporal binding and the representation of conceptual knowledge in cortex: A modern theory by a “classical” neurologist, Carl Wernicke. Cortex, 41(6), 823–832.
Gallese, V., & Lakoff, G. (2005). The brain’s concepts: The role of the sensory-motor system in conceptual knowledge. Cognitive Neuropsychology, 22(3), 455–479. doi:10.1080/02643290442000310
Golinkoff, R. M., Mervis, C. B., & Hirsh-Pasek, K. (1994). Early object labels: The case for a developmental lexical principles framework. Journal of Child Language, 21(1), 122–155. doi:10.1017/S0305000900008692
Gonnerman, L. M., Andersen, E. S., Devlin, J. T., Kempler, D., & Seidenberg, M. S. (1997). Double dissociation of semantic categories in Alzheimer’s disease. Brain and Language, 57(2), 254–279.
Graves, W. W., Binder, J. R., & Seidenberg, M. S. (2013). Noun-noun combination: Meaningfulness ratings and lexical statistics for 2,160 word pairs. Behavior Research Methods, 45(2), 463–469. doi:10.3758/s13428-012-0256-3
Harnad, S. (1990). The symbol grounding problem. Physica D: Nonlinear Phenomena, 42(1–3), 335–346. doi:10.1016/0167-2789(90)90087-6
Hauk, O., Johnsrude, I., & Pulvermüller, F. (2004). Somatotopic representation of action words in human motor and premotor cortex. Neuron, 41, 207–301.
Hoenig, K., Sim, E. J., Bochev, V., Herrnberger, B., & Kiefer, M. (2008). Conceptual flexibility in the human brain: Dynamic recruitment of semantic maps from visual, motor, and motion-related areas. Journal of Cognitive Neuroscience, 20(10), 1799–1814.
Hoffman, P., Binney, R. J., & Lambon Ralph, M. A. (2014). Differing contributions of inferior prefrontal and anterior temporal cortex to concrete and abstract conceptual knowledge. Cortex, 63(c), 250–266. doi:10.1016/j.cortex.2014.09.001
Jackendoff, R. (1987). On beyond zebra: The relation of linguistic and visual information. Cognition, 26(2), 89–114. doi:10.1016/0010-0277(87)90026-6
Jefferies, E., Patterson, K., & Lambon Ralph, M. A. (2008). Deficits of knowledge versus executive control in semantic cognition: Insights from cued naming. Neuropsychologia, 46, 649–658. doi:10.1016/j.neuropsychologia.2007.09.007
Jones, G. V. (1985). Deep dyslexia, imageability, and ease of predication. Brain and Language, 24(1), 1–19. doi:10.1016/0093-934x(85)90094-x
Jouen, A. L., Ellmore, T. M., Madden, C. J., Pallier, C., Dominey, P. F., & Ventre-Dominey, J. (2014). Beyond the word and image: Characteristics of a common meaning system for language and vision revealed by functional and structural imaging. NeuroImage. doi:10.1016/j.neuroimage.2014.11.024
Juhasz, B. J. (2005). Age-of-acquisition effects in word and picture identification. Psychological Bulletin, 131(5), 684–712.
Kandel, E. (2006). In search of memory. New York, NY: Norton.
Kemmerer, D. (2015). Are the motor features of verb meanings represented in the precentral motor cortices? Yes, but within the context of a flexible, multilevel architecture for conceptual knowledge. Psychonomic Bulletin and Review. doi:10.3758/s13423-014-0784-1
Kiefer, M., & Martens, U. (2010). Attentional sensitization of unconscious cognition: Task sets modulate subsequent masked semantic priming. Journal of Experimental Psychology. General, 139(3), 464–489. doi:10.1037/a0019561
Knoblauch, A. (2008). Symbols and embodiment from the perspective of a neural modeler. In Symbols and embodiment: Debates on meaning and cognition. New York, NY: Oxford University Press.
Kousta, S.-T. T., Vigliocco, G., Vinson, D. P., Andrews, M., & Del Campo, E. (2011). The representation of abstract words: Why emotion matters. Journal of Experimental Psychology. General, 140(1), 14–34. doi:10.1037/a0021446
Lambon Ralph, M. A. (2014a). Neurocognitive insights on conceptual knowledge and its breakdown. Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences, 369(1634), 20120392. doi:10.1098/rstb.2012.0392
Lambon Ralph, M. A. (2014b). Personal communication. 19 June 2015. Philadelphia, PA.
Lambon Ralph, M. A., Mcclelland, J. L., Patterson, K., Galton, C. J., & Hodges, J. R. (2001). No right to speak? The relationship between object naming and semantic impairment: Neuropsychological evidence and a computational model. Journal of Cognitive Neuroscience, 13(3), 341–356.
Lambon Ralph, M. A., & Patterson, K. (2008). Generalization and differentiation in semantic memory: Insights from semantic dementia. Annals of the New York Academy of Sciences, 1124, 61–76. doi:10.1196/annals.1440.006
Lambon Ralph, M. A., Sage, K., Jones, R. W., & Mayberry, E. J. (2010). Coherent concepts are computed in the anterior temporal lobes. Proceedings of the National Academy of Sciences of the United States of America, 107(6), 2717–2722. doi:10.1073/pnas.0907307107
Landauer, T. K., & Dumais, S. T. (1997). Solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychological Review, 104, 211–240.
Loiselle, M., Rouleau, I., Nguyen, D., & Dubeau, F. (2012). Comprehension of concrete and abstract words in patients with selective anterior temporal lobe resection and in patients with selective amygdalo-hippocampectomy. Neuropsychologia, 50(5), 630–639.
Louwerse, M. M. (2011). Symbol interdependency in symbolic and embodied cognition. Topics in Cognitive Science, 3(2), 273–302. doi:10.1111/j.1756-8765.2010.01106.x
Louwerse, M. M., & Jeuniaux, P. (2008). Language comprehension is both embodied and symbolic. In M. de Vega, A. M. Glenberg, & A. C. Graesser (Eds.), Symbols and embodiment: Debates on meaning and cognition (pp. 309–326). Oxford, UK: Oxford University Press.
Louwerse, M. M., & Jeuniaux, P. (2010). The linguistic and embodied nature of conceptual processing. Cognition, 114(1), 96–104. doi:10.1016/j.cognition.2009.09.002
Mahon, B. Z. (2014). What is embodied about cognition? Language, Cognition and Neuroscience, 30(4), 420–429. doi:10.1080/23273798.2014.987791
Mann, K., Kaplan, J. T., Damasio, A., & Meyer, K. (2012). Sight and sound converge to form modality-invariant representations in temporoparietal cortex. Journal of Neuroscience, 32(47), 16629–16636. doi:10.1523/JNEUROSCI.2342-12.2012
Martin, A. (2007). The representation of object concepts in the brain. Annual Review of Psychology, 58, 25–45. doi:10.1146/annurev.psych.57.102904.190143
Meteyard, L., Rodriguez, S., Bahrami, B., Vigliocco, G., & Cuadrado, S. R. (2012). Coming of age: A review of embodiment and the neuroscience of semantics. Cortex, 48(7), 788–804. doi:10.1016/j.cortex.2010.11.002
Meyer, K., & Damasio, A. (2009). Convergence and divergence in a neural architecture for recognition and memory. Trends in Neurosciences, 32(7), 376–382.
Moffat, M., Siakaluk, P. D., Sidhu, D. M., & Pexman, P. M. (2015). Situated conceptualization and semantic processing: Effects of emotional experience and context availability in semantic categorization and naming tasks. Psychonomic Bulletin & Review, 22(2), 408–419. doi:10.3758/s13423-014-0696-0
Murphy, G. L. (2002). The big book of concepts. Cambridge, MA: MIT Press.
Negri, G. A. L., Rumiati, R. I., Zadini, A., Ukmar, M., Mahon, B. Z., & Caramazza, A. (2007). What is the role of motor simulation in action and object recognition? Evidence from apraxia. Cognitive Neuropsychology, 24(8), 795–816. doi:10.1080/02643290701707412
Paivio, A. (2013). Dual coding theory, word abstractness, and emotion: A critical review of Kousta et al. (2011). Journal of Experimental Psychology. General, 142(1), 282–287. doi:10.1037/a0027004
Paivio, A. (2014). Intelligence, dual coding theory, and the brain. Intelligence, 47, 141–158. doi:10.1016/j.intell.2014.09.002
Papeo, L., Lingnau, A., Agosta, S., Pascual-Leone, A., Battelli, L., & Caramazza, A. (2014). The origin of word-related motor activity. Cerebral Cortex. doi:10.1093/cercor/bht423
Patterson, K., Nestor, P. J., & Rogers, T. T. (2007). Where do you know what you know? The representation of semantic knowledge in the human brain. Nature Reviews Neuroscience, 8(12), 976–987.
Pecher, D., Zeelenberg, R., & Barsalou, L. W. (2004). Sensorimotor simulations underlie conceptual representations: Modality-specific effects of prior activation. Psychonomic Bulletin & Review, 11(1), 164–167.
Pexman, P. M., Hargreaves, I. S., Edwards, J. D., Henry, L. C., & Goodyear, B. G. (2007). Neural correlates of concreteness in semantic categorization. Journal of Cognitive Neuroscience, 19(8), 1407–1419. doi:10.1162/jocn.2007.19.8.1407
Plaut, D. C., & Shallice, T. (1993). Deep dyslexia: A case study of connectionist neuropsychology. Cognitive Neuropsychology, 10(5), 377–500. doi:10.1080/02643299308253469
Pobric, G., Lambon Ralph, M. A., & Jefferies, E. (2009). The role of the anterior temporal lobes in the comprehension of concrete and abstract words: rTMS evidence. Cortex, 45(9), 1104–1110.
Postle, N., McMahon, K. L., Meredith, M., & de Zubicaray, G. I. (2008). Action word mearning representations in cytoarchitectonically defined primary and premotor cortices. NeuroImage, 43, 634–644.
Price, A. R., Bonner, M. F., Peelle, J. E., & Grossman, M. (2015). Converging evidence for the neuroanatomic basis of combinatorial semantics in the angular gyrus. Journal of Neuroscience, 35(7), 3276–3284. doi:10.1523/JNEUROSCI. 3446-14.2015
Pulvermüller, F. (2013). Semantic embodiment, disembodiment or misembodiment? In search of meaning in modules and neuron circuits. Brain and Language, 127(1), 86–103. doi:10.1016/j.bandl.2013.05.015
Pulvermüller, F., Moseley, R. L., Egorova, N., Shebani, Z., & Boulenger, V. (2014). Motor cognition-motor semantics: Action perception theory of cognition and communication. Neuropsychologia, 55, 71–84. doi:10.1016/j.neuropsychologia.2013.12.002
Raposo, A., Moss, H. E., Stamatakis, E. A., & Tyler, L. K. (2009). Modulation of motor and premotor cortices by actions, action words and action sentences. Neuropsychologia, 47(2), 388–396. doi:10.1016/j.neuropsychologia.2008.09.017
Reilly, J., Chrysikou, E. G., & Ramey, C. H. (2007). Support for hybrid models of the age of acquisition of English nouns. Psychonomic Bulletin & Review, 14(6), 1164–1170.
Reilly, J., Harnish, S., Garcia, A., Hung, J., Rodriguez, A. D., & Crosson, B. (2014). Lesion symptom mapping of manipulable object naming in nonfluent aphasia: Can a brain be both embodied and disembodied? Cognitive Neuropsychology, 31(4), 287–312. doi:10.1080/02643294.2014.914022
Reilly, J., & Kean, J. (2007). Formal distinctiveness of high- and low-imageability nouns: Analyses and theoretical implications. Cognitive Science, 31(1), 157–168. doi:10.1080/03640210709336988
Reilly, J., & Peelle, J. E. (2008). Effects of semantic impairment on language processing in semantic dementia. Seminars in Speech and Language, 29, 32–43.
Rogers, T. T., Hocking, J., Noppeney, U., Mechelli, A., Gorno-Tempini, M. L., Patterson, K., & Price, C. J. (2006). Anterior temporal cortex and semantic memory: Reconciling findings from neuropsychology and functional imaging. Cognitive, Affective, & Behavioral Neuroscience, 6(3), 201–213.
Rogers, T. T., Lambon Ralph, M. A., Garrard, P., Bozeat, S., McClelland, J. L., Hodges, J. R., & Patterson, K. (2004). Structure and deterioration of semantic memory: A neuropsychological and computational investigation. Psychological Review, 111(1), 205–235.
Rosci, C., Chiesa, V., Laiacona, M., & Capitani, E. (2003). Apraxia is not associated to a disproportionate naming impairment for manipulable objects. Brain and Cognition, 53(2), 412–415. doi:10.1016/s0278-2626(03)00156-8
Samson, D., & Pillon, A. (2003). A case of impaired knowledge for fruit and vegetables. Cognitive Neuropsychology, 20(3–6), 373–400.
Schwanenflugel, P. J., & Shoben, E. J. (1983). Differential context effects in the comprehension of abstract and concrete verbal materials. Journal of Experimental Psychology: Learning, Memory, and Cognition, 9(1), 82–102.
Searle, J. (1980). Minds, brains, and programs. Behavioral and Brain Sciences, 3(3), 417–457.
Seghier, M. (2013). The angular gyrus: Multiple functions and multiple subdivisions. The Neuroscientist, 19(1), 43–61. doi:10.1177/1073858412440596
Shallice, T., & Cooper, R. P. (2013). Is there a semantic system for abstract words? Frontiers in Human Neuroscience, 7(175). doi:10.3389/fnhum.2013.00175
Shapiro, L. (2008). Symbolism, embodied cognition, and the broader debate. In Symbols and embodiment: Debates on meaning and cognition (pp. 57–74). New York, NY: Oxford University Press.
Simmons, K., & Barsalou, L. (2003). The similarity-in-topography principle: Reconciling theories of conceptual deficits. Cognitive Neuropsychology, 20, 451–486.
Sporns, O. (2012). From simple graphs to the connectome: Networks in neuroimaging. NeuroImage, 62(2), 881–886. doi:10.1016/j.neuroimage.2011.08.085
Sporns, O., Honey, C. J., & Ko, R. (2007). Identification and classification of hubs in brain networks. PLoS ONE, 10(2), e1049. doi:10.1371/journal.pone.0001049
Tranel, D., Grabowski, T. J., Lyon, J., & Damasio, H. (2005). Naming the same entities from visual or from auditory stimulation engages similar regions of left inferotemporal cortices. Journal of Cognitive Neuroscience, 17(8), 1293–1305. doi:10.1162/0898929055002508
Troche, J., Crutch, S. J., & Reilly, J. (2014). Clustering, hierarchical organization, and the topography of abstract and concrete nouns. Frontiers in Psychology, 5, 360. doi:10.3389/fpsyg.2014.00360
Tyler, L. K., Stamatakis, E. A., Bright, P., Acres, K., Abdallah, S., Rodd, J. M., & Moss, H. E. (2004). Processing objects at different levels of specificity. Journal of Cognitive Neuroscience, 16(3), 351–362. doi:10.1162/089892904322926692
Van Dam, W. O., van Dijk, M., Bekkering, H., & Rueschemeyer, S. A. (2012). Flexibility in embodied lexical-semantic representations. Human Brain Mapping, 33(10), 2322–2333. doi:10.1002/hbm.21365
Vigliocco, G., Kousta, S.-T., Della Rosa, P. A., Vinson, D. P., Tettamanti, M., Devlin, J. T., & Cappa, S. F. (2014). The neural representation of abstract words: The role of emotion. Cerebral Cortex (New York, N.Y.: 1991), 24(7), 1767–1777. doi:10.1093/cercor/bht025
Vigliocco, G., Vinson, D. P., Lewis, W., & Garrett, M. F. (2004). Representing the meanings of object and action words: the featural and unitary semantic space hypothesis. Cognitive Psychology, 48(4), 422–488. doi:10.1016/j.cogpsych.2003.09.001
Wang, J., Conder, J. A., Blitzer, D. N., & Shinkareva, S. V. (2010). Neural representation of abstract and concrete concepts: A meta-analysis of neuroimaging studies. Human Brain Mapping, 31(10), 1459–1468. doi:10.1002/hbm.20950
Warrington, E. K. (1975). The selective impairment of semantic memory. Quarterly Journal of Experimental Psychology, 27(4), 635–657.
Westbury, C. F., Shaoul, C., Hollis, G., Smithson, L., Briesemesiter, B. B., Hofmann, M. J., & Jacobs, A. M. (2013). Now you see it, now you don’t: On emotion, context, and the algorithmic prediction of human imageability judgments. Frontiers in Psychology, 4, 991.
Willems, R. M., & Casasanto, D. (2011). Flexibility in embodied language understanding. Frontiers in Psychology, 2, 116. doi:10.3389/fpsyg.2011.00116
Zdrazilova, L., & Pexman, P. M. (2013). Grasping the invisible: Semantic processing of abstract words. Psychonomic Bulletin & Review, 20(6), 1312–1318. doi:10.3758/s13423-013-0452-x
Zwaan, R. A. (2008). Experiential traces and mental simulations in language comprehension. In M. de Vega, A. M. Glenberg, & A. C. Graesser (Eds.), Symbols and embodiment: Debates on meaning and cognition (pp. 165–180). New York, NY: Oxford University Press.
Zwaan, R. A. (2014). Embodiment and language comprehension: Reframing the discussion. Trends in Cognitive Sciences, 18(5), 229–234. doi:10.1016/j.tics.2014.02.008
Acknowledgments
This work was supported by US Public Health Service Grants R01DC013063 (to J.R.), T32AG020499 (to A.G.) and by Alzheimer’s Research UK Senior Research Fellowships, ESRC/NIHR (ES/K006711/1) and EPSRC (EP/M006093/1) (to S.C.).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Reilly, J., Peelle, J.E., Garcia, A. et al. Linking somatic and symbolic representation in semantic memory: the dynamic multilevel reactivation framework. Psychon Bull Rev 23, 1002–1014 (2016). https://doi.org/10.3758/s13423-015-0824-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-015-0824-5