
Abstract
The time course of attention is a major characteristic on which different types of attention diverge. In addition to explicit goals and salient stimuli, spatial attention is influenced by past experience. In contextual cueing, behaviorally relevant stimuli are more quickly found when they appear in a spatial context that has previously been encountered than when they appear in a new context. In this study, we investigated the time that it takes for contextual cueing to develop following the onset of search layout cues. In three experiments, participants searched for a T target in an array of Ls. Each array was consistently associated with a single target location. In a testing phase, we manipulated the stimulus onset asynchrony (SOA) between the repeated spatial layout and the search display. Contextual cueing was equivalent for a wide range of SOAs between 0 and 1,000 ms. The lack of an increase in contextual cueing with increasing cue durations suggests that as an implicit learning mechanism, contextual cueing cannot be effectively used until search begins.
Similar content being viewed by others

The modern world presents us with a myriad of sensory inputs, only a subset of which are behaviorally relevant. Selective attention depends partially on one’s previous experience. For example, in studies on contextual cueing, participants become faster searching for a target on displays that occasionally repeat (Chun & Jiang, 1998). Several neurophysiological studies have investigated the time course of contextual cueing, demonstrating relatively rapid emergence of the cueing effect. However, these findings have not been corroborated in behavioral work. The goal of the present study was to characterize the time course of contextual cueing in behavior.
In an intracranial electroencephalography (EEG) study, Olson, Chun, and Allison (2001) observed a significantly greater N210 wave (in V1/V2) approximately 200 ms after viewing of a previously encountered display rather than a new display. Similarly, scalp event-related potential (ERP) studies have reported a significantly greater N2pc component for repeated than for unrepeated displays approximately 200 ms after display onset (Johnson, Woodman, Braun, & Luck, 2007; Schankin & Schubö, 2009). Because N2pc is an index of spatial attention (Luck & Hillyard, 1994), these differences suggest that contextual cueing affects spatial attention relatively early. Earlier time differences were observed with magnetoencephalography (MEG). In one MEG study, participants were presented with repeated search layouts, some with consistent and others with random target locations. After search onset, greater gamma activity occurred 100–300 ms earlier in the consistent than in the random condition (Chaumon, Drouet, & Tallon-Baudry, 2008). Predictable search layouts appear to affect brain activity shortly after search onset.
Does the early time course that has been observed with ERPs and MEG translate into an early behavioral gain? This question has not been directly examined, although several studies have spoken to it indirectly. Peterson and Kramer (2001) recorded eye movements while participants conducted the standard T/L search task. The researchers found a small but significant increase in the probability that the first saccade would go to the target on repeated displays. These data might suggest that contextual cueing affects behavior as early as the first saccade. However, in Peterson and Kramer’s task, the search layout was presented, in the form of placeholders, for 1,000 ms before the search items were presented. It is possible that contextual cueing may have developed during this time.
Two behavioral studies have suggested a slow time course of contextual cueing. Kunar, Flusberg, and Wolfe (2008) used visual search slope, which relates response times (RTs) to the number of search items, as a signature of attentional guidance. The researchers found that search slopes were shallower in the repeated than in the unrepeated condition, but only when the overall search took longer. The slope benefit was greater on displays with a more complex background that slowed search RTs. In addition, previewing the search display with placeholders sometimes led to a greater slope reduction.
In a separate study, Kunar, Flusberg, Horowitz, and Wolfe (2007) presented results that are inconsistent with an early onset of the contextual-cueing effect. In this study, they manipulated the number of search items and measured the search slopes for the repeated and unrepeated conditions. Nine variations of the experiment all failed to find an improvement in search slopes for repeated over unrepeated displays. Kunar et al. (2007) proposed that contextual cueing reflects late, response-level enhancement.
In sum, significant discrepancies have been observed between neurophysiological indices and indirect behavioral estimates of the time course of contextual cueing. Intracranial EEG, scalp ERP, and MEG studies have shown that neural activity reflecting spatial attention diverges as early as 100–200 ms between the repeated and unrepeated displays. However, indirect behavioral evidence has suggested that repeated layouts do not immediately benefit visual search. Unfortunately, none of the previous behavioral studies directly measured the time course of contextual cueing. The interval between the onset of the premask placeholders and the search items was constant in most cases (Geyer, Zehetleitner, & Müller, 2010; Ogawa & Kumada, 2008; Peterson & Kramer, 2001). Kunar et al. (2008) found that previews ranging from 400 to 1,200 ms improved search speeds. However, even the shortest preview duration—400 ms—was longer than the time course estimated from ERP/MEG studies.
The present study was designed to provide a behavioral measure of the time course of contextual cueing. In these experiments, we manipulated the stimulus onset asynchrony (SOA) between the spatial cue and the search target. Our logic is similar to that in Müller and Rabbitt’s (1989) classic study charting the time course of endogenous and exogenous attention. When the search context validly predicts the target’s location, RTs should decrease as SOA increases, until the SOA matches the time required for attention deployment. After that point, RTs should level off.
In Experiment 1, placeholders occupied the locations of the search items. After a variable SOA ranging from 100 to 1,000 ms, the placeholders changed into search items. Experiment 2 was a replication of Experiment 1, except that each trial started with the search items for a short time, before search was interrupted by the placeholders for 100 to 1,000 ms. Experiment 3 included an SOA of 0 ms so that we could examine the earliest time period of contextual cueing. If cueing takes t ms to develop, then cueing should be small at SOAs shorter than t, increase as SOA lengthens, and level off as the SOA exceeds t.
An important assumption of our design is that repeated spatial layouts act as contextual cues. This assumption has been present in nearly all published studies on contextual cueing. Chun and Jiang (1998) proposed that learning changes the attentional weights on a spatial map, known as a “context map.” After learning, the target location within the map has a greater attentional weight than do other locations. Subsequent studies have generally adopted this theoretical framework (e.g., Geyer et al., 2010; Peterson & Kramer, 2001). Furthermore, the “layout as cue” assumption is supported by the successful use of premask placeholders to increase the robustness of contextual cueing (Geyer et al., 2010; Kunar et al., 2008; Ogawa & Kumada, 2008; Peterson & Kramer, 2001).
However, the “layout as cue” assumption may not be an accurate description of contextual cueing, which appears to be task-dependent: Layouts learned during visual search do not aid performance on a change detection task (Jiang & Song, 2005). If contextual cueing depends on engaging in visual search, it may not be triggered by placeholders that do not support active visual search.
Experiment 1
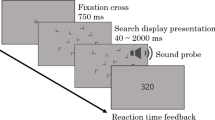
Participants in this experiment conducted a T/L visual search task. In the training phase, they were exposed to displays that repeated 20 times. In the testing phase, they searched for targets in the previously repeated displays as well as in new displays. Prior to presentation of the search items, premask placeholders consisting of all segments in the T and L stimuli were presented. These placeholders occupied the locations of the search items, providing a preview of the search layout. After a variable SOA, the placeholders offset to reveal either a T or an L (Fig. 1). The shortest SOA that led to optimal contextual cueing would provide a behavioral index of its time course.

A search trial used in Experiment 1. The premask placeholders lasted 100, 200, 500, or 1,000 ms
Method
Participants
A group of 18 students (13 females, five males) from the University of Minnesota participated for extra credit. They were 18–37 years old (mean age 20.2 years). All of the participants had normal or corrected-to-normal visual acuity.
Materials
The participants were tested individually in a room with normal interior lighting. They sat approximately 57 cm away from a 19-in. CRT monitor (1,024 × 768 pixels; 75 Hz). The experiment was programmed with the Psychophysics Toolbox (Brainard, 1997; Pelli, 1997), implemented in MATLAB (www.mathworks.com). All items were white on a black background.
Task
On each trial, the participants viewed a fixation point at the center of the screen. Then, 500 ms later, a premask display of 12 placeholders appeared for a variable duration (100, 200, 500, or 1,000 ms). Subsequently, segments of the placeholders disappeared to reveal the search items. The search display contained one T (rotated 90° clockwise or counterclockwise) and 11 Ls (rotated 0°, 90°, 180°, or 270°). The 12 items were randomly placed in a 10 × 10 invisible matrix that subtended 20° × 20°. Three items were always present in each quadrant. The participants’ task was to find the T and to report its orientation by pressing an arrow key as quickly and accurately as possible. The items remained on the display until a response was made. Three rising tones (300 ms) followed a correct response, while a buzz (200 ms) and a timeout (2,000 ms) followed an incorrect response. The next trial commenced 300 ms later. RTs were calculated from the onset of the search display to the response.
Design
After ten trials of practice, participants completed a training phase and a testing phase. The training and testing phases were conducted consecutively without an obvious break.
Training phase (old displays)
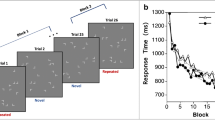
The training phase contained 20 blocks of 32 trials each. The SOA between the placeholder and the search displays was chosen randomly on each trial (100, 200, 500, or 1,000 ms). The participants were shown 32 search displays in each block. These displays had unique spatial layouts and target locations. The target appeared in each visual quadrant eight times across the 32 displays. For the next block, the same displays were shown once again in a random order. Across 20 blocks, participants searched the same 32 displays 20 times. Each time that a display repeated, the locations of all items repeated. However, the orientations of the target and distractors were randomized.
Testing phase (old and new displays)
The testing phase contained 256 trials, with a break every 32 trials. A total of 64 unique spatial layouts were used for the testing phase. Each display was shown four times, once for each of the four SOAs. Half of the spatial layouts had been used during the training phase (“old” displays), and the other half were newly generated for the testing phase (“new” displays), with the constraint that the same target locations from the old displays were used in the new displays. SOA was fully crossed with display type (old or new), producing eight conditions in the testing phase. Trials were presented in a random order.
Results
Accuracy was 98.5 % in the training phase and was unaffected by SOA, p > .05. Accuracy was 98.3 % in the testing phase and was unaffected by display type, SOA, or their interaction, all ps > .05. In the RT analysis, we removed incorrect trials, as well as trials with RTs longer than 10,000 ms or shorter than 250 ms.
Training phase (Fig. 2 left)
Due to the small number of trials per SOA, we pooled the data from all SOAs. RTs improved significantly as the experiment progressed, resulting in a significant main effect of block, F(19, 323) = 5.77, p < .001, η p 2 = .25.

Results from Experiment 1. (Left) Training data. The error bars show ±1 SE of the means across participants. (Right) Testing data. The error bars show ±1 SE of the response time difference between the new and old conditions
Testing phase (Fig. 2 right)
RTs were significantly faster in the old than in the new condition, demonstrating contextual cueing, F(1, 17) = 16.81, p < .001, η p 2 = .50. RTs were significantly affected by SOA, F(3, 51) = 3.37, p = .025, η p 2 = .17: They were faster at an SOA of 200 ms than at one of 500 ms. Surprisingly, display type (old or new) and SOA did not interact, F < 1, suggesting that contextual cueing did not increase in the range of SOAs tested in Experiment 1 (100–1,000 ms).
Experiment 2
Why did contextual cueing fail to increase when the interval between the repeated spatial layout and the target increased? One possibility was that participants failed to attend to the placeholders.Footnote 1 To increase the likelihood that participants would attend to the spatial layouts as soon as they were shown, in Experiment 2 all trials started with the T and L search displays (Fig. 3). However, shortly afterward, before the target was found, all of the items turned into the premask placeholders. After a variable SOA, the placeholders turned into Ts and Ls once again. The initial display was identical to the final display. In addition, participants could not predict the duration of the intermediate placeholders. They were therefore likely to attend to the spatial layout at the start of a trial.

Illustration of a trial used in Experiment 2. All initial and final search displays were identical
Method
Participants
A group of 16 new participants (ten females, six males) were tested. They were 18–31 years old (average age 20.3 years).
Design and procedure
On all trials, the search items started out as Ts and Ls for 200 ms before turning into the premask placeholders. After 100, 200, 500, or 1,000 ms, the premasks turned back into Ts and Ls (Fig. 3). RTs were calculated from the onset of the final search display to the keypress response. Except for the addition of the initial search display, Experiment 2 was identical to Experiment 1.
Results
Accuracy was 98.6 % in the training phase and was unaffected by SOA, p > .05. Accuracy in the testing phase was 98.7 % and was unaffected by display type, SOA, or their interaction, all p values > .05.
Training phase (Fig. 4 left)
RTs improved as the experiment progressed, resulting in a significant main effect of block, F(19, 285) = 6.88, p < .001, η p 2 = .31. RTs in Experiment 2 were 182 ms faster than those of Experiment 1. Although this difference did not reach significance (p < .08), the savings matched the duration of the initial search display. This finding is reminiscent of the rapid-resumption effect, in which search rapidly resumes after a brief interruption (Lleras, Rensink, & Enns, 2005). It was likely that participants attended to the search layout from the start of a trial.

Testing phase (Fig. 4 right)
RTs were significantly faster in the old than in the new condition, revealing contextual cueing, F(1, 15) = 25.33, p < .001, η p 2 = .63. The main effect of SOA was not significant, F < 1. Although display type did interact with SOA, F(3, 45) = 3.34, p < .027, η p 2 = .18, contextual cueing was smaller, not larger, at longer SOAs. Cueing was significant at the shorter SOAs (all ps < .02), but not at an SOA of 1,000 ms (p > .30). Because contextual cueing did not increase with SOA, Experiment 2 suggests that the spatial layout of placeholders, on its own, is not useful for contextual cueing.
Experiment 3
Experiments 1–2 showed that prolonging the preview of repeated spatial layouts did not enhance contextual cueing. One explanation for these surprising results is that contextual cueing developed rapidly and reached its maximum by 100 ms, the shortest SOA tested in Experiments 1–2. Although this possibility is unlikely, given the previous ERP/MEG studies, we conducted Experiment 3 to include an SOA of 0 ms. A second possibility for the lack of an SOA effect was the inclusion of premask placeholders during training, since these placeholders may have discouraged participants from using the spatial context. To enhance the robustness of contextual cueing in the training phase, in Experiment 3 we used a conventional training phase without premask placeholders. The placeholders were introduced only in the testing phase.
Method
Participants
A group of 16 new participants (ten females, six males) completed this experiment. They were 18–23 years old (mean age 19.5 years).
Design and procedure
This experiment was the same as Experiment 1, except for the following changes. First, we removed the premask placeholders from the training phase. Second, in the testing phase, we included a 0-ms SOA condition. The SOA was 0, 200, 500, or 1,000 ms between the premask placeholders and the search display. When the SOA was 0, the placeholders were not shown; the trial started with the T/L items visible.
Results
Accuracy was 98.8 % in the training phase. In the testing phase, accuracy was 98.7 % and was unaffected by display type (old or new), SOA, or their interaction, all p values > .05.
Training phase (Fig. 5 left)
RTs improved as the experiment progressed, resulting in a significant main effect of block, F(19, 285) = 17.76, p < .001, η p 2 = .54.

Testing phase (Fig. 5 right)
RTs were faster for old than for new displays, demonstrating contextual cueing, F(1, 15) = 32.53, p < .001, η p 2 = .68. In addition, we found a significant main effect of SOA, as RTs were slower with a 0-ms than with a 1,000-ms SOA, F(3, 45) = 3.48, p < .023, η p 2 = .19. Critically, display type (old or new) and SOA did not interact, F(3, 45) = 1.32, p > .28; the size of contextual cueing at an SOA of 0 ms was just as large as that at longer SOAs.
General discussion
In this study, we examined the time course of contextual cueing by varying the SOA between the repeated spatial context and the search target. Three experiments demonstrated that lengthening the interval between the contextual cue (repeated spatial layout) and the search target failed to increase contextual cueing. These experiments suggest that a repeated spatial layout is insufficient for triggering contextual cueing.
Premask placeholders have been used in previous contextual-cueing studies. Peterson and Kramer (2001) discussed the possibility that contextual cueing may have started while the placeholders were in view, although this could not be determined from their data. Geyer et al. (2010) and Ogawa and Kumada (2008) used placeholders to enhance contextual cueing. In both studies, however, the search task involved feature search, which may rely primarily on the global layout for cueing. Kunar et al. (2008) used the T/L search task and concluded that placeholders enhanced contextual cueing. However, the benefit affected slope but did not change the overall size of contextual cueing.
Why did previewing repeated layouts fail to enhance contextual cueing? The first possibility is that contextual cueing occurs at a postsearch stage. Kunar et al. (2007) argued that contextual cueing does not affect the search process; instead, it affects decisional and response processes that occur after the target is found. Although this view is compatible with our data, it has difficulty explaining previous eyetracking and ERP/MEG data in which repeated displays were associated with significantly fewer eye movements before the target was found (Peterson & Kramer, 2001; Tseng & Li, 2004; Zhao et al., 2012). In addition, the N2pc component of the ERP is greater for old than for new displays (Johnson et al., 2007; Schankin & Schubö, 2009). This component is known to index spatial attention rather than postperceptual decision and response (Luck & Hillyard, 1994).
The second possibility is that contextual cueing does affect search, but that the effective cue comes from the spatially local context (Brady & Chun, 2007). Previous studies have shown that distractors closer to the target play a more important role in cueing than do distractors farther away from the target Olson & Chun (2002). In fact, repeating the locations just of items in the target’s quadrant produces as much contextual cueing as does repeating the entire display (Brady & Chun, 2007). According to Brady and Chun, when the search target is found, only the adjacent locations are attended and incorporated into learning. Effective contextual cueing therefore depends on the detection of local context around the target. In our experiments, the premask placeholders occupied the same locations as the search array. The placeholder display therefore contained all information about the spatial properties of the search array, including the global layout and the local context. To account for our data, one must assume that the use of placeholders prevented participants from detecting the relevant local context. In other words, the actual process of search through distractors to find a target is crucial for contextual cueing. The utility of a context map, whether global or local, is contingent on search.
The task dependence of contextual cueing (Jiang & Song, 2005) may explain the discrepancy between EEG/MEG studies and the present study. The EEG/MEG signals were obtained during active search, allowing contextual cueing to develop. In contrast, in our study, the time course was estimated by examining the impact of the placeholder cue; placeholders did not permit visual search, so a cueing benefit could not develop, no matter the duration of the cue.
The lack of an SOA effect in our study stands in contrast to previous studies that have used explicit cues to influence attention. Kunar, Flusberg, and Wolfe (2006) found that when the target’s location was consistently associated with a specific background color, increasing the interval between the background and the search items led to greater cueing. Brockmole and Henderson (2006) found that when the target’s location was consistently associated with a natural scene, cueing increased with an increasing number of saccades. In unpublished data, we found that increasing the SOA between a predictive natural scene and a target location strengthened scene-based contextual cueing. A critical difference between the present study and these previous findings was the nature of contextual cueing: Layout-based contextual cueing is implicit, whereas background colors and natural scenes provide explicit cues for attention. As an implicit learning mechanism, layout-based contextual cueing may not be revealed in the absence of the visual search process.
How quickly is spatial attention deployed in contextual cueing? Our answer is as follows. When contextual cueing is based on implicit learning, it cannot start until visual search is actively engaged. When search is engaged, the time course of contextual cueing is probabilistic: On trials in which search approaches the target’s location early on, contextual cueing occurs rapidly, but on other trials, contextual cueing emerges only after the local context has been found.
Notes
We thank James Brockmole for this suggestion.
References
Brady, T. F., & Chun, M. M. (2007). Spatial constraints on learning in visual search: Modeling contextual cuing. Journal of Experimental Psychology. Human Perception and Performance, 33, 795–815. doi:10.1037/0096-1523.33.4.798
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10, 433–436. doi:10.1163/156856897X00357
Brockmole, J. R., & Henderson, J. M. (2006). Recognition and attention guidance during contextual cueing in real-world scenes: Evidence from eye movements. Quarterly Journal of Experimental Psychology, 59, 1177–1187.
Chaumon, M., Drouet, V., & Tallon-Baudry, C. (2008). Unconscious associative memory affects visual processing before 100 ms. Journal of Vision, 8(3), 10. doi:10.1167/8.3.10. 1–10.
Chun, M. M., & Jiang, Y. (1998). Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 36, 28–71. doi:10.1006/cogp.1998.0681
Geyer, T., Zehetleitner, M., & Müller, H. J. (2010). Contextual cueing of pop-out visual search: When context guides the deployment of attention. Journal of Vision, 10(5), 20. doi:10.1167/10.5.20. 1–11.
Jiang, Y., & Song, J. (2005). Spatial context learning in visual search and change detection. Perception & Psychophysics, 67, 1128–1139.
Johnson, J. S., Woodman, G. F., Braun, E., & Luck, S. J. (2007). Implicit memory influences the allocation of attention in visual cortex. Psychonomic Bulletin & Review, 14, 834–839.
Kunar, M. A., Flusberg, S., Horowitz, T. S., & Wolfe, J. M. (2007). Does contextual cuing guide the deployment of attention? Journal of Experimental Psychology. Human Perception and Performance, 33, 816–828. doi:10.1037/0096-1523.33.4.816
Kunar, M. A., Flusberg, S. J., & Wolfe, J. M. (2006). Contextual cuing by global features. Perception & Psychophysics, 68, 1204–1216.
Kunar, M. A., Flusberg, S. J., & Wolfe, J. M. (2008). Time to guide: Evidence for delayed attentional guidance in contextual cueing. Visual Cognition, 16, 804–825. doi:10.1080/13506280701751224
Lleras, A., Rensink, R. A., & Enns, J. T. (2005). Rapid resumption of interrupted visual search. New insights on the interaction between vision and memory. Psychological Science, 16, 684–688.
Luck, S. J., & Hillyard, S. A. (1994). Spatial filtering during visual search: Evidence from human electrophysiology. Journal of Experimental Psychology. Human Perception and Performance, 20, 1000–1014. doi:10.1037/0096-1523.20.5.1000
Müller, H. J., & Rabbitt, P. M. (1989). Reflexive and voluntary orienting of visual attention: Time course of activation and resistance to interruption. Journal of Experimental Psychology. Human Perception and Performance, 15, 315–330. doi:10.1037/0096-1523.15.2.315
Ogawa, H., & Kumada, T. (2008). The encoding process of nonconfigural information in contextual cuing. Perception & Psychophysics, 70, 329–336. doi:10.3758/PP.70.2.329
Olson, I. R., Chun, M. M., & Allison, T. (2001). Contextual guidance of attention: Human intracranial event-related potential evidence for feedback modulation in anatomically early, temporally late stages of visual processing. Brain, 124, 1417–1425.
Olson, I. R., & Chun, M. M. (2002). Perceptual constraints on implicit learning of spatial context. Visual Cognition, 9, 273–302.
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10, 437–442. doi:10.1163/156856897X00366
Peterson, M. S., & Kramer, A. F. (2001). Attentional guidance of the eyes by contextual information and abrupt onsets. Perception & Psychophysics, 63, 1239–1249. doi:10.3758/BF03194537
Schankin, A., & Schubö, A. (2009). Cognitive processes facilitated by contextual cueing: Evidence from event-related brain potentials. Psychophysiology, 46, 668–679. doi:10.1111/j.1469-8986.2009.00807.x
Tseng, Y.-C., & Li, C.-S. R. (2004). Oculomotor correlates of context-guided learning in visual search. Perception & Psychophysics, 66, 1363–1378. doi:10.3758/BF03195004
Zhao, G., Liu, Q., Jiao, J., Zhou, P. L., Li, H., & Sun, H.-J. (2012). Dual-state modulation of the contextual cueing effect: Evidence from eye movement recordings. Journal of Vision, 12(6), 11. doi:10.1167/12.6.11. 1–13.
Author note
We thank James Brockmole and Melina Kunar for comments on an earlier draft of the article. Thanks to Gail Rosenbaum, Chris Capistrano, Julia Cistera, Chelsea Herzig, Jie Hua Ong, and Josh Tisdell for help with the data collection.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Jiang, Y.V., Sigstad, H.M. & Swallow, K.M. The time course of attentional deployment in contextual cueing. Psychon Bull Rev 20, 282–288 (2013). https://doi.org/10.3758/s13423-012-0338-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-012-0338-3